本页面介绍了如何为 GKE 推理网关执行增量发布操作,以逐步部署推理基础设施的新版本。此网关使您可以对推理基础设施执行安全且受控的更新。您可以更新节点、基本模型和 LoRA 适配器,同时尽可能减少服务中断。此页面还提供了有关流量分配和回滚的指南,以确保实现可靠部署。
本页面适用于想要为 GKE 推理网关执行发布操作的 GKE 身份和账号管理员及开发者。
支持以下应用场景:
更新节点发布
节点更新可将推理工作负载安全地迁移到新的节点硬件或加速器配置。此过程以受控方式进行,不会中断模型服务。使用节点更新可在硬件升级、驱动程序更新或安全问题解决过程中最大限度地减少服务中断。
创建新的
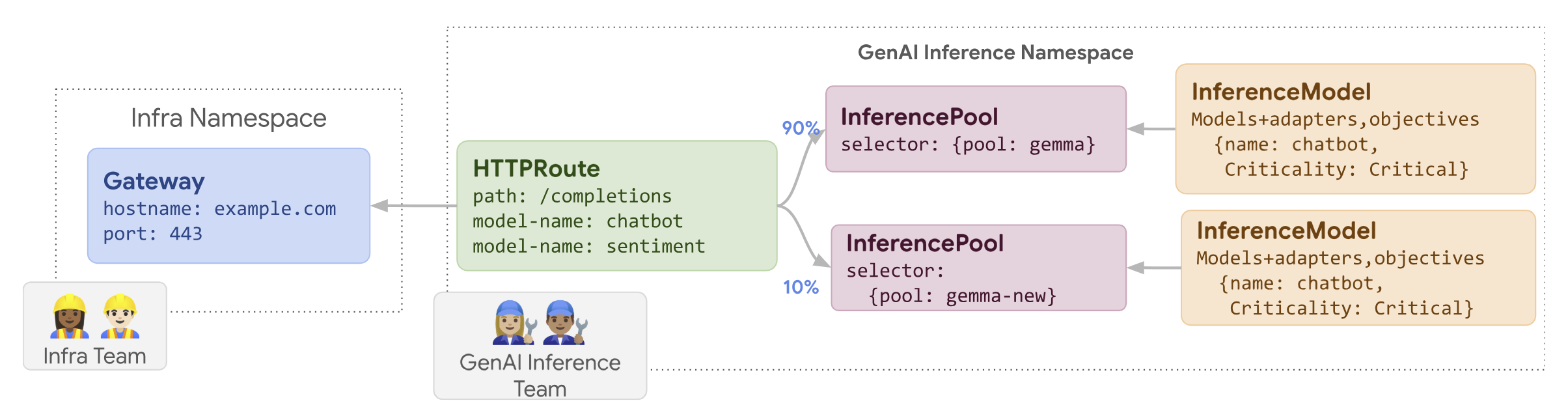
InferencePool:部署使用更新后的节点或硬件规范配置的InferencePool。使用
HTTPRoute分配流量:配置HTTPRoute以在现有和新的InferencePool资源之间分配流量。使用backendRefs中的weight字段管理定向到新节点的流量百分比。保持一致的
InferenceObjective:保留现有的InferenceObjective配置,以确保在两种节点配置间保持一致的模型行为。保留原始资源:在发布期间保持原始
InferencePool和节点处于活动状态,以便在需要时进行回滚。
例如,您可以创建一个名为 llm-new 的新 InferencePool。使用与现有 llm InferencePool 相同的模型配置来配置此池。在集群中的一组新节点上部署此池。使用 HTTPRoute 对象在原始 llm 和新的 llm-new InferencePool 之间分配流量。此技术可让您以增量方式更新模型节点。
下图展示了 GKE 推理网关如何执行节点更新发布。
如需执行节点更新发布,请按以下步骤操作:
将以下示例清单保存为
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10将示例清单应用于集群:
kubectl apply -f routes-to-llm.yaml
原始 llm InferencePool 接收大部分流量,而 llm-new InferencePool 接收剩余流量。逐步增加 llm-new InferencePool 的流量权重,以完成节点更新发布。
发布基本模型
基本模型更新会分阶段发布到新的基本 LLM,同时保留与现有 LoRA 适配器的兼容性。您可以使用基本模型更新发布来升级到改进的模型架构,或解决特定于模型的问题。
如需发布基本模型更新,请执行以下操作:
- 部署新基础设施:创建新节点和新
InferencePool并使用您选择的新基本模型进行配置。 - 配置流量分配:使用
HTTPRoute在现有InferencePool(使用旧的基本模型)和新InferencePool(使用新的基本模型)之间分配流量。backendRefs weight字段用于控制分配给每个池的流量百分比。 - 保持
InferenceObjective完整性:使InferenceObjective配置保持不变。这样可确保系统在两个基本模型版本间始终如一地应用相同的 LoRA 适配器。 - 保留回滚功能:在发布期间保留原始节点和
InferencePool,以便在必要时进行回滚。
您创建一个名为 llm-pool-version-2 的新 InferencePool。此池会在一组新节点上部署新版本的基本模型。通过配置 HTTPRoute(如提供的示例所示),您可以在原始 llm-pool 和 llm-pool-version-2 之间逐步分配流量。这使您可以控制集群中的基本模型更新。
如需执行基本模型更新发布,请按以下步骤操作:
将以下示例清单保存为
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10将示例清单应用于集群:
kubectl apply -f routes-to-llm.yaml
原始 llm-pool InferencePool 接收大部分流量,而 llm-pool-version-2 InferencePool 接收剩余流量。逐步增加 llm-pool-version-2 InferencePool 的流量权重,以完成基本模型更新发布。