Che cos'è lo sharding del database?
Lo sharding del database è una strategia utilizzata per risolvere i problemi di scalabilità nelle applicazioni che hanno una quantità massiccia di dati. Implica la suddivisione di un singolo set di dati logico di grandi dimensioni in parti più piccole e più gestibili chiamate shard. Ogni shard viene archiviato su un'istanza di server di database separata, distribuendo in modo efficace i dati e il workload su più macchine.
Lo sharding è un metodo chiave per la scalabilità orizzontale (scale out). Invece di eseguire l'upgrade di un singolo server con più CPU o RAM (scalabilità verticale), che alla fine raggiunge un limite hardware, lo sharding consente di aggiungere più server di base al cluster. Ciò consente alle applicazioni di gestire una crescita quasi infinita del volume di dati e del traffico utenti.

Sebbene lo sharding sia un modo efficace per fare lo scale out, è una delle tre strategie comuni di scalabilità orizzontale:
- Repliche di lettura: si tratta di creare copie del database principale per gestire il traffico di sola lettura, riducendo il carico sul server principale
- Sharding: distribuisce sia i dati che il traffico di scrittura su più server indipendenti
- Database distribuiti: prodotti come Spanner gestiscono in modo nativo la distribuzione e la scalabilità all'interno del motore del database stesso, eliminando la necessità di sharding manuale
Come funziona lo sharding del database?
Lo sharding del database funziona raggruppando i dati in base a un valore specifico chiamato chiave di shard. Una chiave di shard è una colonna nel database, ad esempio un ID utente, una regione cliente o un numero di ordine, che determina quale server memorizzerà una riga di dati specifica. Quando i dati vengono scritti nel database, il sistema esamina questa chiave per decidere dove devono essere inseriti.
Per trovare i dati in un secondo momento, il sistema deve instradare la query nella posizione corretta. Questo routing avviene in due modi principali:
- Layer di routing: le architetture di sharding possono utilizzare un bilanciatore del carico intelligente o un layer proxy dedicato. Quando un'applicazione invia una query, il layer di routing controlla la chiave di shard, calcola quale shard contiene i dati e indirizza il traffico a quel server.
- Logica lato applicazione: in alcuni casi, come nei giochi multiplayer o nelle app in tempo reale ad alte prestazioni, il codice dell'applicazione stessa contiene la logica di sharding. Il codice calcola la posizione corretta dello shard prima ancora di inviare la richiesta, il che può ridurre la latenza rimuovendo un hop di rete aggiuntivo.
Poiché prende di mira solo lo shard pertinente, il database risponde alle query più velocemente e gestisce migliaia di richieste simultanee senza rallentare.
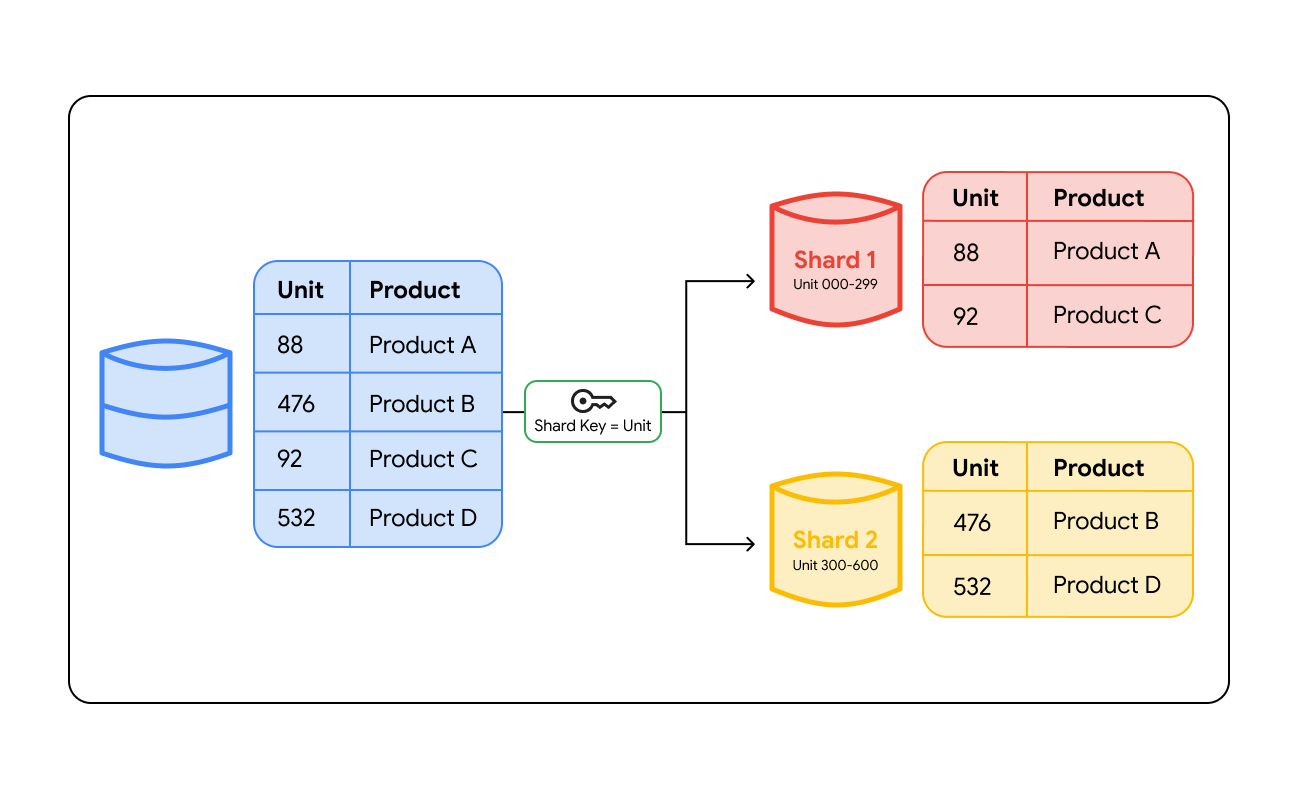
Metodi di sharding comuni
Applicazioni diverse richiedono logiche diverse per la suddivisione dei dati. Il metodo scelto determina il modo in cui il "livello di routing" trova i tuoi dati.
Sharding basato su chiave (hash sharding)
Questo metodo utilizza una formula matematica (una funzione hash) sulla chiave di shard per assegnare i dati. Ad esempio, il sistema potrebbe calcolare l'ID utente (mod 4) per assegnare un utente a uno dei 4 server.
Sebbene le funzioni hash aiutino a distribuire i dati in modo coerente, garantiscono una distribuzione uniforme solo se la chiave di shard ha una cardinalità elevata e una bassa asimmetria di frequenza. Se scegli una chiave di shard con un valore comune, ad esempio "Cognome" in cui "Rossi" compare 1000 volte più di "Bianchi", la funzione hash invierà ogni record "Rossi" allo stesso shard. In questo modo viene creato un "hot shard" nonostante l'uso di una formula matematica.
L'aggiunta di nuovi server è difficile con questo metodo perché la formula cambia, il che spesso richiede di "ricondividere" o spostare i dati nel nuovo cluster di server.
Sharding basato su intervallo
I dati vengono assegnati in base a intervalli di valori. Ad esempio, potresti inserire gli ID utente 1-1000 sul server A e 1001-2000 sul server B. È molto intuitivo e ottimo per le query che devono leggere una sequenza di dati (query di intervallo). Lo svantaggio è la creazione di "hotspot": se tutti i nuovi utenti vengono assegnati al server B, questo server svolgerà tutto il lavoro mentre il server A rimarrà inattivo.
Sharding basato su directory
Questa strategia utilizza una tabella di ricerca (una directory) che tiene traccia di quale shard contiene quali dati. Offre la massima flessibilità perché puoi spostare i dati tra gli shard senza modificare una formula. Tuttavia, questa tabella di ricerca diventa un collo di bottiglia: ogni query deve controllare prima la directory, aggiungendo latenza. Se la directory non funziona, l'intero database diventa inaccessibile.
Sharding geografico
Lo sharding geografico assegna i dati a server specifici in base alla posizione fisica di un utente. Ad esempio, i dati degli utenti in Francia vengono archiviati su server nell'UE, mentre gli utenti statunitensi si trovano su server in Nord America. Ciò riduce significativamente la latenza (velocità) per gli utenti e aiuta le aziende a rispettare le leggi sulla residenza dei dati come il GDPR.
Sharding verticale
A volte chiamata partizionamento funzionale, questa tecnica prevede la suddivisione dei dati per funzionalità anziché per riga. Ad esempio, potresti posizionare tutte le tabelle "Profilo utente" sul server A e tutte le tabelle "Caricamento foto" sul server B. Sebbene ciò organizzi i dati in modo logico, è funzionalmente simile a un'architettura di dati per microservizi e non risolve il problema se una funzionalità specifica (come Foto) diventa troppo grande per un singolo server.
Come ottimizzare lo sharding del database per una distribuzione uniforme dei dati
La scelta della chiave di shard corretta è la decisione più critica nello sharding. Una chiave errata può portare a una distribuzione dei dati non uniforme (hot spot), mentre una chiave corretta può garantire che tutti i server funzionino allo stesso modo. Per ottimizzare questo aspetto, devi considerare tre fattori:
- Cardinalità: si riferisce al numero di valori univoci che una chiave può avere. È necessario utilizzare una chiave con cardinalità elevata (come un ID utente) e non con cardinalità bassa (come "Genere" o "Stato"), in modo che i dati possano essere suddivisi in molti piccoli blocchi.
- Frequenza: devi evitare le chiavi in cui un valore specifico viene visualizzato troppo spesso. Ad esempio, se esegui lo sharding per "Città" e l'80% dei tuoi utenti vive a New York, lo shard "New York" sarà sovraccarico.
- Modifica monotonica: evita le chiavi che aumentano strettamente nel tempo, come un timestamp o un ID a incremento automatico. Se esegui lo sharding per data, tutte le nuove scritture di dati andranno allo shard "Oggi", creando un hotspot di scrittura mentre gli shard più vecchi rimangono inattivi.
Termini per lo sharding chiave
Sebbene questi termini vengano spesso usati insieme nella progettazione di sistemi, risolvono problemi diversi.
Sharding
Lo sharding è un tipo specifico di partizionamento orizzontale in cui le parti di dati vengono distribuite su server completamente diversi. In questo modo si risolvono sia i limiti di capacità hardware (archiviazione) sia i colli di bottiglia della velocità effettiva di scrittura, poiché server diversi possono elaborare le scritture contemporaneamente.
- Sharding manuale: in un ambiente di sharding manuale, lo sviluppatore o l'amministratore del database è responsabile della definizione delle chiavi di sharding, della creazione dell'infrastruttura per ogni shard e della scrittura della logica per il routing delle query. In questo modo, puoi controllare in modo granulare dove risiedono esattamente i dati. Tuttavia, richiede una manutenzione significativa. Se uno shard diventa troppo grande, devi eseguire manualmente il "resharding" dei dati, che comporta lo spostamento di milioni di righe su nuovi server cercando di ridurre al minimo i tempi di inattività dell'applicazione.
- Sharding automatico: lo sharding automatico, spesso presente nei database NoSQL come Bigtable o nei database SQL distribuiti come Spanner, gestisce la distribuzione di dati e traffico in modo automatico. Il sistema monitora le dimensioni dei dati e il carico su ciascun server. Se uno shard specifico diventa un "hot spot" o cresce troppo, il motore del database lo suddivide automaticamente e sposta i dati su un server meno congestionato. Ciò riduce il carico operativo sul tuo team e contribuisce a garantire prestazioni coerenti man mano che l'applicazione viene scalata.
Partizionamento
Il partizionamento prevede la suddivisione di una tabella di grandi dimensioni in parti più piccole e gestibili (come la suddivisione di una tabella di log per mese), mantenendole però sulla stessa istanza del server. Questo risolve i problemi di archiviazione semplificando l'archiviazione o l'eliminazione di dati obsoleti senza influire sul resto della tabella. Tuttavia, non risolve i problemi del server. Poiché tutte le partizioni risiedono ancora su una singola macchina, continuano a condividere la stessa CPU e la stessa RAM, il che significa che il partizionamento non può essere d'aiuto se il server raggiunge i suoi limiti di prestazioni.
Replica
La replica è il processo di copia dell'intero database su più server. Può essere una buona scelta per la disponibilità di lettura: se un server non funziona, un altro può subentrare. Tuttavia, non aiuta con la scalabilità della scrittura perché ogni dato scritto deve essere copiato in ogni replica, limitando la velocità di scrittura alla capacità di una singola macchina.
Altrettanto importante è il fatto che la maggior parte dei modelli di replica consente un solo "writer" (scrittore, ovvero il nodo primario) alla volta. Se tenti di consentire a più server di accettare scritture contemporaneamente, rischi conflitti di scrittura, in cui due server tentano di aggiornare lo stesso record con informazioni diverse. La risoluzione di questi conflitti è tecnicamente difficile e può portare alla perdita o all'incoerenza dei dati se non viene gestita da un sistema distribuito sofisticato.
Database distribuiti
Un database distribuito, come Spanner, offre i vantaggi dello sharding senza il sovraccarico manuale. Questi sistemi sono progettati per essere distribuiti su un cluster di macchine fin dall'inizio. Gestiscono automaticamente la distribuzione, il ribilanciamento e la replica dei dati in modo trasparente. Alcuni di questi sistemi hanno più writer e gestiscono automaticamente i conflitti di scrittura. Ciò consente di scalare orizzontalmente mantenendo la coerenza di un database relazionale tradizionale.
Utilizza la tabella seguente per comprendere le differenze tra questi concetti di base del database.
Funzionalità | Sharding | Partizionamento | Replica | Database distribuito |
Obiettivo principale | Archiviazione e scalabilità di scrittura massiccia | Gestibilità e manutenzione | Alta affidabilità e scalabilità di lettura | Scalabilità globale automatizzata |
Località dei dati | Diversi blocchi di dati su server diversi | Diversi chunk di dati sullo stesso server | Copie degli stessi dati su più server | Gestito in un cluster |
Prestazioni di scrittura | Miglioramento elevato (le scritture avvengono in parallelo) | Miglioramento minore (indici più piccoli) | Nessun miglioramento (le scritture devono andare a tutte le copie) | Miglioramento elevato |
complessità | Elevata | Media | Bassa | Bassa (gestita) |
Funzionalità
Sharding
Partizionamento
Replica
Database distribuito
Obiettivo principale
Archiviazione e scalabilità di scrittura massiccia
Gestibilità e manutenzione
Alta affidabilità e scalabilità di lettura
Scalabilità globale automatizzata
Località dei dati
Diversi blocchi di dati su server diversi
Diversi chunk di dati sullo stesso server
Copie degli stessi dati su più server
Gestito in un cluster
Prestazioni di scrittura
Miglioramento elevato (le scritture avvengono in parallelo)
Miglioramento minore (indici più piccoli)
Nessun miglioramento (le scritture devono andare a tutte le copie)
Miglioramento elevato
complessità
Elevata
Media
Bassa
Bassa (gestita)
Vantaggi dello sharding del database
Lo sharding può spesso essere l'unica soluzione praticabile per le applicazioni che gestiscono terabyte di dati o milioni di transazioni al secondo.
Scalabilità orizzontale
Scalabilità orizzontale
Lo sharding consente una scalabilità quasi infinita aggiungendo server standard a un cluster. In questo modo si evita la "tassa dell'hardware" delle applicazioni legacy con scalabilità verticale. Senza lo sharding, spesso sei costretto ad acquistare hardware costoso e specializzato che raggiunge un limite di prestazioni. Lo sharding consente al database di crescere insieme alla tua attività utilizzando macchine più convenienti e di base
Prestazioni delle query migliorate
Prestazioni delle query migliorate
Lo sharding velocizza le singole query perché ogni server cerca in un set di dati più piccolo. Invece di cercare in un indice di 100 milioni di righe, una query potrebbe dover cercare solo in uno shard con 1 milione di righe. Inoltre, poiché i dati si trovano su macchine diverse, puoi eseguire più query in parallelo, aumentando notevolmente la velocità effettiva totale dell'applicazione.
Affidabilità
Affidabilità
Lo sharding limita il "raggio di impatto" di un errore. Se uno shard non funziona, solo gli utenti interessati ne risentono, mentre il resto dell'app rimane online. Tuttavia, un numero maggiore di server comporta un maggiore carico amministrativo. La gestione di backup, sicurezza e patch su decine di istanze aumenta la complessità operativa rispetto a una configurazione a server singolo.
Sfide dello sharding
Sebbene lo sharding risolva i requisiti di scalabilità massiccia, introduce compromessi tecnici e operativi significativi. Dovresti considerare queste sfide prima di abbandonare un'architettura a istanza singola.
- Hotspot di dati: anche con una funzione hash, il traffico non uniforme può creare "hotspot" in cui un server viene sovraccaricato da un piccolo gruppo di utenti molto attivi, mentre altri shard rimangono sottoutilizzati.
- Regressione delle prestazioni: le query che non utilizzano la chiave di shard richiedono al sistema di eseguire una "scatter-gather" ("raccolta dispersa") su ogni server. Allo stesso modo, i join tra shard sono costosi dal punto di vista computazionale perché l'applicazione deve eseguire il pull e unire i dati da più posizioni fisiche.
- Complessità operativa: la gestione di un ambiente con shard aumenta la difficoltà delle attività di routine. Gli aggiornamenti dello schema, i backup e il recupero point-in-time devono essere coordinati su più istanze indipendenti.
- Coerenza transazionale: molte architetture con sharding faticano a supportare le transazioni ACID su diversi shard. Questo spesso costringe gli sviluppatori a gestire scenari complessi di "errore parziale" o ad affidarsi a modelli di coerenza finale.
In che modo Google Cloud può aiutare con lo sharding del database
Google Cloud offre soluzioni di database che eliminano il lavoro pesante dello sharding manuale, consentendoti di concentrarti sulla creazione della tua applicazione anziché sulla gestione dell'infrastruttura.
 SpannerSi tratta di un database completamente gestito e distribuito a livello globale che offre un'esperienza "no-sharding". Esegue automaticamente lo sharding dei dati e bilancia il carico tra le regioni. In quanto database multimodello, supporta dati relazionali, chiave-valore e grafici (tramite Spanner Graph) all'interno di un'unica interfaccia. Ciò consente di scalare orizzontalmente mantenendo una elevata coerenza e la familiarità con SQL.
SpannerSi tratta di un database completamente gestito e distribuito a livello globale che offre un'esperienza "no-sharding". Esegue automaticamente lo sharding dei dati e bilancia il carico tra le regioni. In quanto database multimodello, supporta dati relazionali, chiave-valore e grafici (tramite Spanner Graph) all'interno di un'unica interfaccia. Ciò consente di scalare orizzontalmente mantenendo una elevata coerenza e la familiarità con SQL. Cloud SQL e AlloyDBSe preferisci i motori di database relazionali tradizionali, Google Cloud offre istanze gestite per PostgreSQL, MySQL e SQL Server. Sia Cloud SQL che AlloyDB supportano il partizionamento nativo per gestire tabelle di grandi dimensioni su una singola istanza. Puoi anche creare architetture di sharding personalizzate utilizzando queste istanze per scalare i workload su più macchine, mentre AlloyDB aggiunge prestazioni per i dati più impegnativi.
Cloud SQL e AlloyDBSe preferisci i motori di database relazionali tradizionali, Google Cloud offre istanze gestite per PostgreSQL, MySQL e SQL Server. Sia Cloud SQL che AlloyDB supportano il partizionamento nativo per gestire tabelle di grandi dimensioni su una singola istanza. Puoi anche creare architetture di sharding personalizzate utilizzando queste istanze per scalare i workload su più macchine, mentre AlloyDB aggiunge prestazioni per i dati più impegnativi.- BigtablePer workload NoSQL su vasta scala, Bigtable è la soluzione ideale. Gestisce automaticamente la "suddivisione dei tablet" (sharding), gestendo petabyte di dati e milioni di richieste al secondo per casi d'uso come la personalizzazione e i dati di serie temporali.
Hai bisogno di aiuto per iniziare?
Contatta il team di venditaCollabora con un partner di fiducia
Trova un partnerScopri di più su Spanner
Continua la navigazione


















