Apa itu sharding database?
Sharding database adalah strategi yang digunakan untuk mengatasi masalah skalabilitas dalam aplikasi yang memiliki data dalam jumlah besar. Sharding database melibatkan pemisahan satu set data logis yang besar menjadi bagian-bagian yang lebih kecil dan lebih mudah dikelola yang disebut shard. Setiap shard disimpan di instance server database terpisah, sehingga secara efektif menyebarkan data dan workload ke beberapa mesin.
Sharding adalah metode utama untuk penskalaan horizontal (penyebaran skala). Alih-alih mengupgrade satu server dengan lebih banyak CPU atau RAM (penskalaan vertikal), yang pada akhirnya akan mencapai batas hardware, sharding memungkinkan Anda menambahkan lebih banyak server komoditas ke cluster Anda. Hal ini memungkinkan aplikasi menangani pertumbuhan volume data dan traffic pengguna yang hampir tak terbatas.

Meskipun sharding adalah cara yang efektif untuk melakukan penyebaran skala, sharding adalah salah satu dari tiga strategi penskalaan horizontal yang umum:
- Replika baca: Hal ini melibatkan pembuatan salinan database utama untuk menangani traffic hanya baca, yang mengurangi beban pada server utama
- Sharding: Mendistribusikan data dan traffic tulis ke beberapa server independen
- Database terdistribusi: Produk seperti Spanner secara native menangani distribusi dan penskalaan dalam mesin database itu sendiri, sehingga tidak perlu sharding manual
Bagaimana cara kerja sharding database?
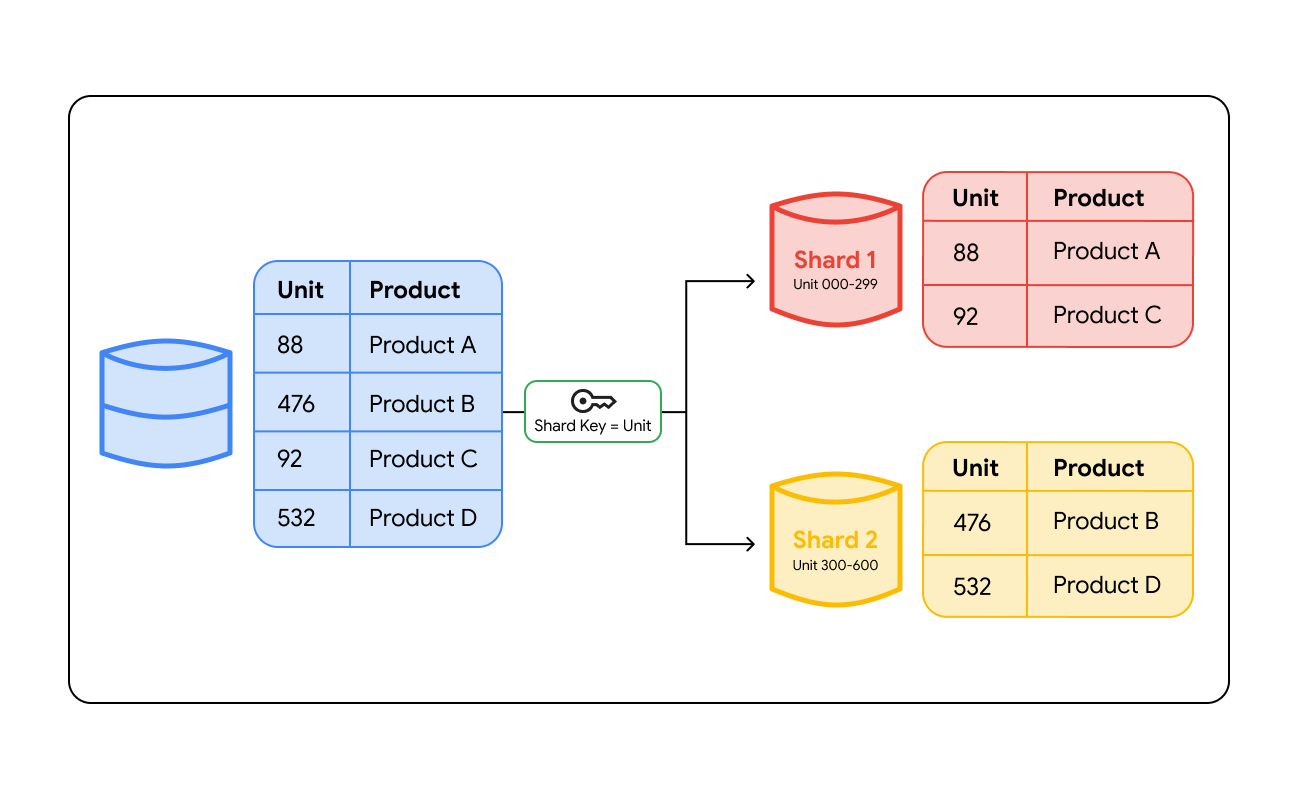
Sharding database bekerja dengan mengelompokkan data berdasarkan nilai tertentu yang disebut kunci shard. Kunci shard adalah kolom dalam database Anda, seperti ID Pengguna, Region Pelanggan, atau Nomor Pesanan, yang menentukan server mana yang akan menyimpan baris data tertentu. Saat data ditulis ke database, sistem akan melihat kunci ini untuk memutuskan lokasi data tersebut.
Untuk menemukan data nanti, sistem harus merutekan kueri ke lokasi yang benar. Perutean ini terjadi dalam dua cara utama:
- Lapisan perutean: Arsitektur sharding dapat menggunakan load balancer cerdas atau lapisan proxy khusus. Saat aplikasi mengirimkan kueri, lapisan perutean akan memeriksa kunci shard, menghitung shard mana yang menyimpan data tersebut, dan mengarahkan traffic ke server tersebut.
- Logika sisi aplikasi: Dalam beberapa kasus, seperti dalam game multiplayer atau aplikasi real-time berperforma tinggi, kode aplikasi itu sendiri berisi logika sharding. Kode ini menghitung lokasi shard yang benar sebelum mengirimkan permintaan, sehingga dapat mengurangi latensi dengan menghilangkan hop jaringan tambahan.
Dengan menargetkan hanya shard yang relevan, database menjawab kueri lebih cepat dan menangani ribuan permintaan serentak tanpa melambat.
Metode sharding umum
Aplikasi yang berbeda memerlukan logika yang berbeda untuk membagi data. Metode yang Anda pilih menentukan cara "lapisan perutean" menemukan data Anda.
Sharding berbasis kunci (sharding hash)
Metode ini menggunakan rumus matematika (fungsi hash) pada kunci shard untuk menetapkan data. Misalnya, sistem dapat menghitung ID Pengguna (mod 4) untuk menetapkan pengguna ke 1 dari 4 server.
Meskipun membantu mendistribusikan data secara konsisten, fungsi hash hanya memastikan distribusi yang merata jika kunci shard memiliki kardinalitas tinggi dan kemiringan frekuensi rendah. Jika Anda memilih kunci shard dengan nilai umum, seperti "Nama Belakang" yang "Smith"-nya muncul 1.000 kali lebih banyak daripada "Pyne", fungsi hash akan mengirim setiap kumpulan data "Smith" ke shard yang sama. Hal ini akan membuat "hot shard" meskipun menggunakan rumus matematika.
Menambahkan server baru juga sulit dilakukan dengan metode ini karena formulanya berubah, yang sering kali mengharuskan Anda untuk "melakukan sharding ulang" atau memindahkan data Anda ke cluster server baru.
Sharding berbasis rentang
Data ditetapkan berdasarkan rentang nilai. Misalnya, Anda dapat menempatkan ID Pengguna 1–1.000 di Server A dan 1.001–2.000 di Server B. Hal ini sangat intuitif dan bagus untuk kueri yang perlu membaca urutan data (kueri rentang). Kelemahannya adalah "hot spot"—jika semua pengguna baru Anda ditetapkan ke Server B, server tersebut akan melakukan semua pekerjaan sementara Server A tidak digunakan.
Sharding berbasis direktori
Strategi ini menggunakan tabel pemeta (direktori) yang melacak dengan tepat shard mana yang menyimpan data apa. Strategi tersebut menawarkan fleksibilitas terbesar karena Anda dapat memindahkan data antar-shard tanpa mengubah formula. Namun, tabel pemeta ini menjadi bottleneck; setiap kueri harus memeriksa direktori terlebih dahulu, sehingga menambah latensi. Jika direktori gagal, seluruh database menjadi tidak dapat diakses.
Sharding geografis
Geo sharding menetapkan data ke server tertentu berdasarkan lokasi fisik pengguna. Misalnya, data untuk pengguna di Prancis disimpan di server di Uni Eropa, sedangkan pengguna AS disimpan di server di Amerika Utara. Hal ini secara signifikan mengurangi latensi (kecepatan) bagi pengguna dan membantu perusahaan mematuhi hukum residensi data seperti GDPR.
Sharding vertikal
Terkadang disebut partisi fungsional, hal ini melibatkan pemisahan data berdasarkan fitur, bukan berdasarkan baris. Misalnya, Anda dapat menempatkan semua tabel "Profil Pengguna" di Server A dan semua tabel "Upload Foto" di Server B. Meskipun data diatur secara logis, secara fungsional, arsitektur ini mirip dengan arsitektur data microservice dan tidak menyelesaikan masalah jika satu fitur tertentu (seperti Foto) tumbuh terlalu besar untuk satu server.
Cara mengoptimalkan sharding database untuk distribusi data yang merata
Memilih kunci shard yang tepat adalah keputusan terpenting dalam sharding. Kunci yang buruk dapat menyebabkan distribusi data yang tidak merata (hot spot), sedangkan kunci yang baik dapat memastikan semua server bekerja secara merata. Untuk mengoptimalkannya, Anda harus melihat tiga faktor:
- Kardinalitas: Ini mengacu pada jumlah nilai unik yang dapat dimiliki sebuah kunci. Anda menginginkan kunci dengan kardinalitas tinggi (seperti ID Pengguna), bukan kardinalitas rendah (seperti "Jenis Kelamin" atau "Negara Bagian"), sehingga data dapat dibagi menjadi banyak potongan kecil.
- Frekuensi: Anda harus menghindari kunci yang memiliki satu nilai spesifik yang terlalu sering muncul. Misalnya, jika Anda melakukan sharding berdasarkan "Kota" dan 80% pengguna Anda tinggal di New York, shard "New York" akan kelebihan beban.
- Perubahan monoton: Hindari kunci yang meningkat secara ketat dari waktu ke waktu, seperti Stempel Waktu atau ID yang bertambah otomatis. Jika Anda melakukan sharding berdasarkan tanggal, semua penulisan data baru akan masuk ke shard "Hari Ini", sehingga membuat hotspot penulisan sementara shard yang lebih lama tidak aktif.
Istilah penting terkait sharding
Meskipun sering digunakan bersamaan dalam desain sistem, istilah ini menyelesaikan masalah yang berbeda.
Sharding
Sharding adalah jenis partisi horizontal tertentu yang mendistribusikan potongan data ke server yang sama sekali berbeda. Hal ini mengatasi batas kapasitas hardware (penyimpanan) dan bottleneck throughput tulis, karena server yang berbeda dapat memproses penulisan secara bersamaan.
- Sharding manual: Dalam lingkungan sharding manual, developer atau administrator database bertanggung jawab untuk menentukan kunci shard, membuat infrastruktur untuk setiap shard, dan menulis logika untuk merutekan kueri. Hal ini memberi Anda kontrol terperinci atas lokasi penyimpanan data. Namun, hal ini memerlukan pemeliharaan yang signifikan. Jika satu shard menjadi terlalu besar, Anda harus "melakukan sharding ulang" data secara manual, yang melibatkan pemindahan jutaan baris ke server baru sambil mencoba meminimalkan waktu non-operasional aplikasi.
- Sharding otomatis: Sharding otomatis, yang sering ditemukan di database NoSQL seperti Bigtable atau database SQL terdistribusi seperti Spanner, menangani distribusi data dan traffic secara otomatis. Sistem memantau ukuran data dan beban di setiap server. Jika shard tertentu menjadi "hot spot" atau tumbuh terlalu besar, mesin database akan otomatis membagi shard dan memindahkan data ke server yang tidak terlalu padat. Hal ini mengurangi beban operasional pada tim Anda dan membantu memastikan performa yang konsisten seiring dengan penskalaan aplikasi Anda.
Membuat partisi
Partisi melibatkan pembagian tabel besar menjadi bagian-bagian yang lebih kecil dan mudah dikelola (seperti membagi tabel log per bulan) tetapi tetap berada di instance server yang sama. Hal ini menyelesaikan masalah penyimpanan dengan mempermudah pengarsipan atau penghapusan data lama tanpa memengaruhi tabel lainnya. Namun, hal ini tidak menyelesaikan masalah server. Karena semua partisi masih berada di satu mesin, partisi tersebut terus berbagi CPU dan RAM yang sama, yang berarti partisi tidak dapat membantu jika server mencapai batas performanya.
Replikasi
Replikasi adalah proses penyalinan seluruh database ke beberapa server. Opsi ini dapat menjadi pilihan yang baik untuk ketersediaan baca; jika satu server gagal, server lain dapat mengambil alih. Namun, hal ini tidak membantu penskalaan tulis karena setiap bagian data yang ditulis harus disalin ke setiap replika, sehingga membatasi kecepatan tulis ke kapasitas satu mesin.
Yang tak kalah penting, sebagian besar model replikasi hanya mengizinkan satu "penulis" (node utama) dalam satu waktu. Jika Anda mencoba mengizinkan beberapa server menerima penulisan secara bersamaan, Anda berisiko mengalami konflik penulisan, yang mana dua server mencoba mengupdate kumpulan data yang sama dengan informasi yang berbeda. Menyelesaikan konflik ini secara teknis sulit dan dapat menyebabkan kehilangan data atau inkonsistensi jika tidak ditangani oleh sistem terdistribusi yang canggih.
Database terdistribusi
Database terdistribusi, seperti Spanner, memberikan manfaat sharding tanpa overhead manual. Sistem ini dirancang untuk ditempatkan di seluruh cluster mesin sejak awal. Sistem tersebut secara otomatis menangani distribusi, penyeimbangan ulang, dan replikasi data secara transparan. Beberapa sistem ini memiliki beberapa penulis dan secara otomatis menangani konflik penulisan. Hal ini memungkinkan Anda melakukan penskalaan secara horizontal sekaligus mempertahankan konsistensi database relasional tradisional.
Gunakan tabel di bawah untuk memahami perbedaan antara konsep database inti ini.
Fitur | Sharding | Membuat partisi | Replikasi | Database terdistribusi |
Sasaran utama | Penskalaan dan penyimpanan tulis yang masif | Kemudahan pengelolaan dan pemeliharaan | Ketersediaan tinggi dan penskalaan baca | Penskalaan global otomatis |
Lokasi data | Potongan data yang berbeda di server yang berbeda | Potongan data yang berbeda di server yang sama | Salinan data yang sama di beberapa server | Dikelola di seluruh cluster |
Performa tulis | Peningkatan tinggi (penulisan terjadi secara paralel) | Peningkatan kecil (indeks yang lebih kecil) | Tidak ada peningkatan (operasi tulis harus dilakukan ke semua salinan) | Peningkatan tinggi |
Kompleksitas | Tinggi | Sedang | Rendah | Rendah (terkelola) |
Fitur
Sharding
Membuat partisi
Replikasi
Database terdistribusi
Sasaran utama
Penskalaan dan penyimpanan tulis yang masif
Kemudahan pengelolaan dan pemeliharaan
Ketersediaan tinggi dan penskalaan baca
Penskalaan global otomatis
Lokasi data
Potongan data yang berbeda di server yang berbeda
Potongan data yang berbeda di server yang sama
Salinan data yang sama di beberapa server
Dikelola di seluruh cluster
Performa tulis
Peningkatan tinggi (penulisan terjadi secara paralel)
Peningkatan kecil (indeks yang lebih kecil)
Tidak ada peningkatan (operasi tulis harus dilakukan ke semua salinan)
Peningkatan tinggi
Kompleksitas
Tinggi
Sedang
Rendah
Rendah (terkelola)
Manfaat sharding database
Sharding sering kali menjadi satu-satunya solusi yang paling cocok untuk aplikasi yang menangani data berukuran terabyte atau jutaan transaksi per detik.
Penskalaan horizontal
Penskalaan horizontal
Sharding memungkinkan penskalaan yang hampir tak terbatas dengan menambahkan server standar ke cluster. Hal ini menghindari "pajak hardware" dari aplikasi lama yang diskalakan secara vertikal. Tanpa sharding, Anda sering kali terpaksa membeli hardware khusus yang mahal dan mencapai batas performa. Sharding memungkinkan database berkembang seiring pertumbuhan bisnis Anda menggunakan mesin komoditas yang lebih terjangkau
Peningkatan performa kueri
Peningkatan performa kueri
Sharding mempercepat kueri individual karena setiap server menelusuri set data yang lebih kecil. Alih-alih menelusuri indeks yang berisi 100 juta baris, kueri mungkin hanya perlu menelusuri shard dengan 1 juta baris. Selain itu, karena data berada di mesin yang berbeda, Anda dapat menjalankan beberapa kueri secara paralel, sehingga meningkatkan total throughput aplikasi secara signifikan.
Keandalan
Keandalan
Sharding membatasi "potensi dampak kerusakan" dari kegagalan. Jika satu shard gagal, hanya pengguna tersebut yang terpengaruh, sementara bagian aplikasi lainnya tetap online. Namun, semakin banyak server berarti beban administrasi menjadi lebih tinggi. Mengelola cadangan, keamanan, dan patch di puluhan instance meningkatkan kompleksitas operasional dibandingkan dengan penyiapan server tunggal.
Tantangan dalam sharding
Meskipun sharding memenuhi persyaratan skala besar, sharding memperkenalkan trade-off teknis dan operasional yang signifikan. Anda harus mempertimbangkan tantangan ini sebelum beralih dari arsitektur instance tunggal.
- Hotspot data: Bahkan dengan fungsi hash, traffic yang tidak merata dapat membuat "hotspot" yang mana beban satu server menjadi berlebih oleh sekelompok kecil pengguna yang sangat aktif sementara shard lainnya tetap kurang dimanfaatkan.
- Regresi performa: Kueri yang tidak menggunakan kunci shard mengharuskan sistem untuk "scatter-gather" di setiap server. Demikian pula, gabungan lintas shard memerlukan banyak komputasi karena aplikasi harus mengambil dan menggabungkan data dari beberapa lokasi fisik.
- Kompleksitas operasional: Mengelola lingkungan yang di-shard meningkatkan kesulitan tugas rutin. Pembaruan skema, pencadangan, dan pemulihan point-in-time harus dikoordinasikan di beberapa instance independen.
- Konsistensi transaksional: Banyak arsitektur yang di-shard kesulitan mendukung transaksi ACID di berbagai shard. Hal ini sering kali memaksa developer untuk mengelola skenario "kegagalan parsial" yang kompleks atau mengandalkan model konsistensi tertunda.
Bagaimana Google Cloud dapat membantu sharding database
Google Cloud menawarkan solusi database yang menghilangkan tugas berat dari sharding manual, sehingga Anda dapat berfokus pada pembuatan aplikasi, bukan pengelolaan infrastruktur.
 SpannerIni adalah database yang terkelola sepenuhnya dan terdistribusi secara global yang menawarkan pengalaman "tanpa sharding". Spanner secara otomatis melakukan shard data dan menyeimbangkan beban di seluruh region. Sebagai database multi-model, Spanner mendukung data relasional, nilai kunci, dan grafik (melalui Spanner Graph) dalam satu antarmuka. Hal ini memungkinkan Anda melakukan penskalaan secara horizontal sekaligus mempertahankan konsistensi yang kuat dan kemudahan penggunaan SQL.
SpannerIni adalah database yang terkelola sepenuhnya dan terdistribusi secara global yang menawarkan pengalaman "tanpa sharding". Spanner secara otomatis melakukan shard data dan menyeimbangkan beban di seluruh region. Sebagai database multi-model, Spanner mendukung data relasional, nilai kunci, dan grafik (melalui Spanner Graph) dalam satu antarmuka. Hal ini memungkinkan Anda melakukan penskalaan secara horizontal sekaligus mempertahankan konsistensi yang kuat dan kemudahan penggunaan SQL. CloudSQL dan AlloyDBJika Anda lebih menyukai mesin database relasional tradisional, Google Cloud menawarkan instance terkelola untuk PostgreSQL, MySQL, dan SQL Server. Cloud SQL dan AlloyDB mendukung partisi native untuk mengelola tabel besar pada satu instance. Anda juga dapat membangun arsitektur sharding kustom menggunakan instance ini untuk menskalakan workload di beberapa mesin, sementara AlloyDB meningkatkan performa untuk data yang menuntut.
CloudSQL dan AlloyDBJika Anda lebih menyukai mesin database relasional tradisional, Google Cloud menawarkan instance terkelola untuk PostgreSQL, MySQL, dan SQL Server. Cloud SQL dan AlloyDB mendukung partisi native untuk mengelola tabel besar pada satu instance. Anda juga dapat membangun arsitektur sharding kustom menggunakan instance ini untuk menskalakan workload di beberapa mesin, sementara AlloyDB meningkatkan performa untuk data yang menuntut.- BigtableUntuk workload NoSQL berskala besar, Bigtable adalah pilihan yang ideal. Spanner secara otomatis menangani "pemisahan subtabel" (sharding), mengelola petabyte data dan jutaan permintaan per detik untuk kasus penggunaan seperti personalisasi dan data deret waktu.
Perlu bantuan untuk memulai?
Hubungi bagian penjualanBekerja sama dengan partner tepercaya
Temukan partnerPelajari Spanner lebih lanjut
Lanjutkan menjelajah


















