Qu'est-ce que la segmentation de base de données ?
La segmentation de base de données est une stratégie permettant de résoudre les problèmes d'évolutivité dans les applications qui contiennent une énorme quantité de données. Elle consiste à diviser un grand ensemble de données logique en parties plus petites et plus faciles à gérer, appelées "segments". Chaque segment est stocké sur une instance de serveur de base de données distincte, ce qui permet de répartir efficacement les données et la charge de travail sur plusieurs machines.
La segmentation est une méthode essentielle pour le scaling horizontal. Au lieu de mettre à niveau un seul serveur avec plus de CPU ou de RAM (scaling vertical), ce qui finit par atteindre ses limites, la segmentation vous permet d'ajouter des serveurs standards à votre cluster. Les applications peuvent ainsi gérer une croissance quasi infinie du volume de données et du trafic utilisateur.

La segmentation est un moyen efficace d'effectuer un scaling horizontal. Il s'agit de l'une des trois stratégies courantes de scaling horizontal :
- Instances répliquées avec accès en lecture : cette approche consiste à créer des copies de la base de données principale pour gérer le trafic en lecture seule, ce qui réduit la charge sur le serveur principal.
- Segmentation : cette approche répartit les données et le trafic d'écriture sur plusieurs serveurs indépendants.
- Bases de données distribuées : des produits comme Spanner gèrent de façon native la distribution et le scaling au sein du moteur de base de données lui-même, ce qui évite d'avoir à effectuer une segmentation manuelle.
Comment fonctionne la segmentation de base de données ?
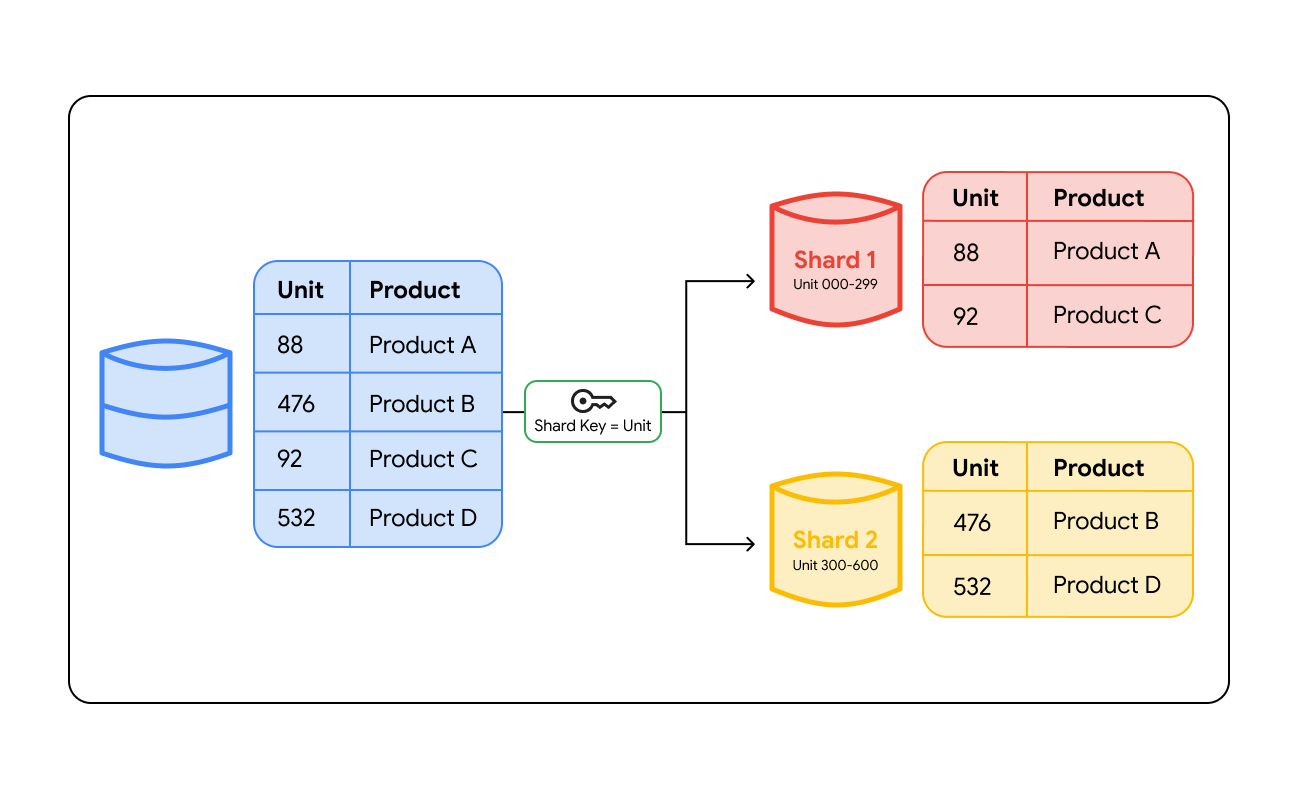
La segmentation d'une base de données consiste à regrouper les données en fonction d'une valeur spécifique appelée "clé de segmentation". Une clé de segmentation est une colonne de votre base de données, comme un ID utilisateur, une région client ou un numéro de commande, qui détermine le serveur sur lequel une ligne de données spécifique sera stockée. Lorsque des données sont écrites dans la base de données, le système examine cette clé pour déterminer où elles doivent être placées.
Pour retrouver les données ultérieurement, le système doit acheminer la requête vers l'emplacement approprié. Le routage s'effectue de deux manières principales :
- Couche de routage : les architectures de segmentation peuvent utiliser un équilibreur de charge intelligent ou une couche proxy dédiée. Lorsqu'une application envoie une requête, la couche de routage vérifie la clé de segmentation, détermine quel segment contient ces données et dirige le trafic vers ce serveur.
- Logique côté application : dans certains cas, comme pour les jeux multijoueurs ou les applications en temps réel hautes performances, le code de l'application lui-même contient la logique de segmentation. Le code calcule l'emplacement correct du segment avant même d'envoyer la requête, ce qui peut réduire la latence en supprimant un saut de réseau supplémentaire.
En ciblant uniquement le segment pertinent, la base de données répond plus rapidement aux requêtes et gère des milliers de requêtes simultanées sans ralentir.
Méthodes de segmentation courantes
Chaque application nécessite une logique différente pour diviser les données. La méthode choisie détermine la façon dont la couche de routage trouve vos données.
Segmentation basée sur des clés (segmentation par hachage)
Cette méthode utilise une formule mathématique (une fonction de hachage) sur la clé de segmentation pour attribuer les données. Par exemple, le système peut calculer l'ID utilisateur (mod 4) pour attribuer un utilisateur à l'un des quatre serveurs.
Bien que les fonctions de hachage contribuent à répartir les données de manière cohérente, elles ne garantissent une distribution uniforme que si la clé de segmentation présente une cardinalité élevée et un faible biais de fréquence. Si vous choisissez une clé de segmentation avec une valeur courante, comme un nom de famille ("Smith" apparaît 1 000 fois plus souvent que "Pyne"), la fonction de hachage enverra chaque enregistrement "Smith" au même segment. Cela crée un "segment chaud" malgré l'utilisation d'une formule mathématique.
L'ajout de nouveaux serveurs est également complexe avec cette méthode, car la formule change, ce qui vous oblige souvent à "resegmenter" ou à déplacer vos données sur le nouveau cluster de serveurs.
Segmentation par plage
Les données sont attribuées en fonction de plages de valeurs. Par exemple, vous pouvez placer les ID utilisateur 1 à 1 000 sur le serveur A et les ID utilisateur 1 001 à 2 000 sur le serveur B. Cette méthode est très intuitive et idéale pour les requêtes qui doivent lire une séquence de données (requêtes de plage). L'inconvénient est que cela crée des "points chauds" : si tous vos nouveaux utilisateurs sont affectés au serveur B, ce serveur effectuera tout le travail tandis que le serveur A restera inactif.
Segmentation basée sur des répertoires
Cette stratégie utilise un tableau de conversion (un répertoire) qui indique exactement quel segment contient quelles données. Elle offre une flexibilité maximale, car vous pouvez déplacer des données entre les segments sans modifier de formule. Cependant, ce tableau de conversion devient un goulot d'étranglement : chaque requête doit d'abord consulter le répertoire, ce qui ajoute de la latence. En cas de défaillance du répertoire, toute la base de données devient inaccessible.
Segmentation géographique
La segmentation géographique attribue les données à des serveurs spécifiques en fonction de la position géographique de l'utilisateur. Par exemple, les données des utilisateurs en France sont stockées sur des serveurs situés dans l'UE, tandis que celles des utilisateurs aux États-Unis sont stockées sur des serveurs situés en Amérique du Nord. Cela réduit considérablement la latence (vitesse) pour les utilisateurs et aide les entreprises à respecter les lois sur la résidence des données, comme le RGPD.
Segmentation verticale
Parfois appelé "partitionnement fonctionnel", il consiste à répartir les données par caractéristique plutôt que par ligne. Par exemple, vous pouvez placer toutes les tables "Profil utilisateur" sur le serveur A et toutes les tables "Importation de photos" sur le serveur B. Bien que cette approche organise les données de manière logique, elle est fonctionnellement semblable à une architecture de données de microservices et ne résout pas le problème si une fonctionnalité spécifique (comme Photos) devient trop volumineuse pour un seul serveur.
Optimiser la segmentation de base de données pour une répartition uniforme des données
Choisir la clé de segmentation appropriée est la décision la plus importante à prendre lors du processus de segmentation. Une mauvaise clé peut entraîner une répartition inégale des données (points chauds), tandis qu'une bonne clé peut garantir que tous les serveurs fonctionnent de manière égale. Pour optimiser ce processus, vous devez examiner trois facteurs :
- Cardinalité : il s'agit du nombre de valeurs uniques qu'une clé peut avoir. Vous devez choisir une clé à cardinalité élevée (comme un ID utilisateur) plutôt qu'à cardinalité faible (comme "Genre" ou "État"), afin que les données puissent être divisées en de nombreux petits fragments.
- Fréquence : vous devez éviter les clés dans lesquelles une valeur spécifique apparaît trop souvent. Par exemple, si vous effectuez une segmentation par ville et que 80 % de vos utilisateurs vivent à New York, le segment "New York" sera surchargé.
- Modification monotone : évitez les clés qui augmentent strictement dans le temps, comme un code temporel ou un ID à incrémentation automatique. Si vous effectuez la segmentation par date, toutes les nouvelles écritures de données seront dirigées vers le segment "Aujourd'hui", ce qui créera un point chaud d'écriture, tandis que les segments plus anciens resteront inactifs.
Termes clés du partitionnement
Bien que ces termes soient souvent utilisés ensemble dans la conception de systèmes, ils permettent de résoudre des problèmes différents.
Partition
La segmentation est un type spécifique de partitionnement horizontal dans lequel les éléments de données sont répartis sur des serveurs complètement différents. Elle permet de résoudre les problèmes de limites de capacité matérielle (stockage) et les goulots d'étranglement liés au débit d'écriture, car différents serveurs peuvent traiter les écritures simultanément.
- Segmentation manuelle : dans un environnement de segmentation manuelle, le développeur ou l'administrateur de base de données est chargé de définir les clés de segmentation, de créer l'infrastructure pour chaque segment et d'écrire la logique d'acheminement des requêtes. Vous pouvez ainsi contrôler précisément l'emplacement des données. Toutefois, cela nécessite une maintenance importante. Si un segment devient trop volumineux, vous devez "resegmenter" manuellement les données, ce qui implique de déplacer des millions de lignes vers de nouveaux serveurs tout en essayant de minimiser les temps d'arrêt de l'application.
- Segmentation automatique : la segmentation automatique, souvent présente dans les bases de données NoSQL comme Bigtable ou les bases de données SQL distribuées comme Spanner, gère la distribution des données et du trafic de manière automatique. Le système surveille la taille des données et la charge sur chaque serveur. Si un segment spécifique devient un "point chaud" ou devient trop volumineux, le moteur de base de données le divise automatiquement et déplace les données vers un serveur moins encombré. Cela réduit la charge opérationnelle de votre équipe et contribue à assurer des performances constantes à mesure que votre application évolue.
Partitionnement
Le partitionnement consiste à diviser une grande table en parties plus petites et plus faciles à gérer (par exemple, en divisant une table de journaux par mois), tout en les conservant sur la même instance de serveur. Il permet de résoudre les problèmes de stockage en facilitant l'archivage ou la suppression des anciennes données sans affecter le reste de la table. Cependant, il ne résout pas les problèmes de serveur. Comme l'ensemble des partitions résident toujours sur une seule machine, elles continuent de partager le même processeur et la même RAM. Le partitionnement n'est donc pas utile si le serveur atteint ses limites de performances.
Réplication
La réplication consiste à copier l'intégralité de la base de données sur plusieurs serveurs. Cette option est intéressante pour la disponibilité en lecture, car si un serveur tombe en panne, un autre peut prendre le relais. Cependant, elle ne contribue pas au scaling pour l'écriture, car toutes les données écrites doivent être copiées sur chaque instance répliquée, ce qui limite la vitesse d'écriture à la capacité d'une seule machine.
Autre point important, la plupart des modèles de réplication n'autorisent qu'un seul nœud d'écriture (le nœud principal) à la fois. Si vous autorisez plusieurs serveurs à accepter des écritures simultanément, vous risquez de rencontrer des conflits d'écriture, où deux serveurs tentent de mettre à jour le même enregistrement avec des informations différentes. La résolution de ces conflits est techniquement difficile et peut entraîner une perte ou une incohérence des données si elle n'est pas gérée par un système distribué sophistiqué.
Bases de données distribuées
Une base de données distribuée, comme Spanner, offre les avantages de la segmentation sans la complexité opérationnelle manuelle. Ces systèmes sont conçus pour fonctionner sur un cluster de machines dès le départ. Ils gèrent automatiquement la distribution, le rééquilibrage et la réplication des données de manière transparente. Certains de ces systèmes disposent de plusieurs nœuds d'écriture et gèrent automatiquement les conflits d'écriture. Vous pouvez ainsi effectuer un scaling horizontal tout en conservant la cohérence d'une base de données relationnelle traditionnelle.
Servez-vous du tableau ci-dessous pour comprendre les différences entre ces concepts de bases de données fondamentaux.
Fonctionnalité | Partition | Partitionnement | Réplication | Base de données distribuée |
Objectif principal | Scaling et stockage des écritures à grande échelle | Facilité de gestion et maintenance | Haute disponibilité et scaling des lectures | Scaling mondial automatique |
Emplacement des données | Différents fragments de données sur plusieurs serveurs | Différents fragments de données sur le même serveur | Copies des mêmes données sur plusieurs serveurs | Géré dans un cluster |
Performances d'écriture | Amélioration significative (les écritures s'effectuent en parallèle) | Amélioration mineure (index plus petits) | Aucune amélioration (les écritures doivent être effectuées sur toutes les copies) | Amélioration significative |
Complexité | Élevée | Moyenne | Faible | Faible (gérée) |
Fonctionnalité
Partition
Partitionnement
Réplication
Base de données distribuée
Objectif principal
Scaling et stockage des écritures à grande échelle
Facilité de gestion et maintenance
Haute disponibilité et scaling des lectures
Scaling mondial automatique
Emplacement des données
Différents fragments de données sur plusieurs serveurs
Différents fragments de données sur le même serveur
Copies des mêmes données sur plusieurs serveurs
Géré dans un cluster
Performances d'écriture
Amélioration significative (les écritures s'effectuent en parallèle)
Amélioration mineure (index plus petits)
Aucune amélioration (les écritures doivent être effectuées sur toutes les copies)
Amélioration significative
Complexité
Élevée
Moyenne
Faible
Faible (gérée)
Avantages de la segmentation de base de données
La segmentation est souvent la seule solution viable pour les applications qui gèrent des téraoctets de données ou des millions de transactions par seconde.
Scaling horizontal
Scaling horizontal
La segmentation permet un scaling quasi infini en ajoutant des serveurs standards à un cluster. Cela permet d'éviter la "taxe matérielle" des anciennes applications à scaling vertical. Sans la segmentation, vous êtes souvent obligé d'acheter du matériel spécialisé coûteux qui atteint un plafond de performances. La segmentation permet à la base de données de se développer en même temps que votre entreprise, en utilisant des machines de base plus abordables.
Amélioration des performances des requêtes
Amélioration des performances des requêtes
La segmentation accélère les requêtes individuelles, car chaque serveur recherche dans un ensemble de données plus petit. Au lieu d'interroger un index comportant 100 millions de lignes, une requête peut se limiter à un segment d'un million de lignes. De plus, comme les données se trouvent sur différentes machines, vous pouvez exécuter plusieurs requêtes en parallèle, ce qui augmente considérablement le débit total de l'application.
Fiabilité
Fiabilité
La segmentation limite le "potentiel néfaste" d'une défaillance. Si un segment échoue, seuls les utilisateurs concernés sont affectés, tandis que le reste de l'application reste en ligne. Cependant, plus il y a de serveurs, plus la charge administrative est importante. La gestion des sauvegardes, de la sécurité et des correctifs sur des dizaines d'instances augmente la complexité opérationnelle par rapport à une configuration à serveur unique.
Difficultés liées à la segmentation
Bien que la segmentation réponde aux exigences d'une mise à l'échelle massive, elle introduit des compromis techniques et opérationnels importants. Vous devez tenir compte de ces problématiques avant d'abandonner une architecture à instance unique.
- Hotspotting des données : même avec une fonction de hachage, un trafic inégal peut créer des "hotspots" où un serveur est surchargé par un petit groupe d'utilisateurs très actifs, tandis que d'autres segments restent sous-utilisés.
- Régression des performances : les requêtes qui n'utilisent pas la clé de segmentation obligent le système à effectuer une opération de type "scatter-gather" sur chaque serveur. De même, les jointures entre segments sont coûteuses en ressources de calcul, car l'application doit extraire et fusionner des données provenant de plusieurs emplacements physiques.
- Complexité opérationnelle : la gestion d'un environnement segmenté rend les tâches de routine plus difficiles. Les mises à jour des schémas, les sauvegardes et la récupération à un moment précis doivent être coordonnées sur plusieurs instances indépendantes.
- Cohérence transactionnelle : de nombreuses architectures segmentées ont du mal à prendre en charge les transactions ACID sur différents segments. Cela oblige souvent les développeurs à gérer des scénarios complexes d'"échec partiel" ou à s'appuyer sur des modèles de cohérence à terme.
Comment Google Cloud peut-il aider à segmenter les bases de données ?
Google Cloud propose des solutions de base de données qui vous évitent d'avoir à effectuer manuellement la segmentation, ce qui vous permet de vous concentrer sur la création de votre application plutôt que sur la gestion de l'infrastructure.
 SpannerCette base de données entièrement gérée et distribuée à l'échelle mondiale offre une expérience sans segmentation. Elle segmente automatiquement les données et équilibre la charge entre les régions. En tant que base de données multimodèle, elle prend en charge les données relationnelles, de clé-valeur et de graphes (via Spanner Graph) dans une seule interface. Vous pouvez ainsi effectuer un scaling horizontal tout en conservant une cohérence forte et en utilisant SQL.
SpannerCette base de données entièrement gérée et distribuée à l'échelle mondiale offre une expérience sans segmentation. Elle segmente automatiquement les données et équilibre la charge entre les régions. En tant que base de données multimodèle, elle prend en charge les données relationnelles, de clé-valeur et de graphes (via Spanner Graph) dans une seule interface. Vous pouvez ainsi effectuer un scaling horizontal tout en conservant une cohérence forte et en utilisant SQL. Cloud SQL et AlloyDBSi vous préférez les moteurs de bases de données relationnelles traditionnels, Google Cloud propose des instances gérées pour PostgreSQL, MySQL et SQL Server. Cloud SQL et AlloyDB peuvent gérer de grandes tables sur une seule instance à l'aide du partitionnement natif. Vous pouvez également créer des architectures de segmentation personnalisées à l'aide de ces instances pour faire évoluer les charges de travail sur plusieurs machines, tandis qu'AlloyDB améliore les performances pour les données exigeantes.
Cloud SQL et AlloyDBSi vous préférez les moteurs de bases de données relationnelles traditionnels, Google Cloud propose des instances gérées pour PostgreSQL, MySQL et SQL Server. Cloud SQL et AlloyDB peuvent gérer de grandes tables sur une seule instance à l'aide du partitionnement natif. Vous pouvez également créer des architectures de segmentation personnalisées à l'aide de ces instances pour faire évoluer les charges de travail sur plusieurs machines, tandis qu'AlloyDB améliore les performances pour les données exigeantes.- BigtableBigtable est la solution idéale pour les charges de travail NoSQL à grande échelle. Il gère automatiquement le fractionnement des tables (segmentation), ainsi que des pétaoctets de données et des millions de requêtes par seconde pour des cas d'utilisation tels que la personnalisation et les données de séries temporelles.
Vous avez besoin d'aide pour démarrer ?
Contacter le service commercialFaites appel à un partenaire de confiance
Trouver un partenaireEn savoir plus sur Spanner
Poursuivez vos recherches


















