¿Qué es el particionamiento de bases de datos?
La fragmentación de bases de datos es una estrategia que se usa para resolver problemas de escalabilidad en aplicaciones que tienen una gran cantidad de datos. Consiste en dividir un solo conjunto de datos lógico de gran tamaño en partes más pequeñas y fáciles de gestionar llamadas "fragmentos". Cada fragmento se almacena en una instancia de servidor de base de datos independiente, lo que permite distribuir eficazmente los datos y la carga de trabajo entre varias máquinas.
La fragmentación es un método clave para el escalado horizontal. En lugar de actualizar un solo servidor con más CPU o RAM (escalado vertical), que acaba alcanzando un límite de hardware, la fragmentación te permite añadir más servidores básicos a tu clúster. Esto permite que las aplicaciones gestionen un crecimiento casi infinito del volumen de datos y del tráfico de usuarios.

Aunque la fragmentación es una forma eficaz de escalar horizontalmente, es una de las tres estrategias de escalado horizontal más comunes:
- Réplicas de lectura: se trata de crear copias de la base de datos principal para gestionar el tráfico de solo lectura, de forma que se reduzca la carga del servidor principal.
- Fragmentación: se distribuyen los datos y el tráfico de escritura en varios servidores independientes.
- Bases de datos distribuidas: productos como Spanner gestionan de forma nativa la distribución y el escalado en el propio motor de la base de datos, por lo que no es necesario hacer la fragmentación manualmente.
¿Cómo funciona el particionamiento de bases de datos?
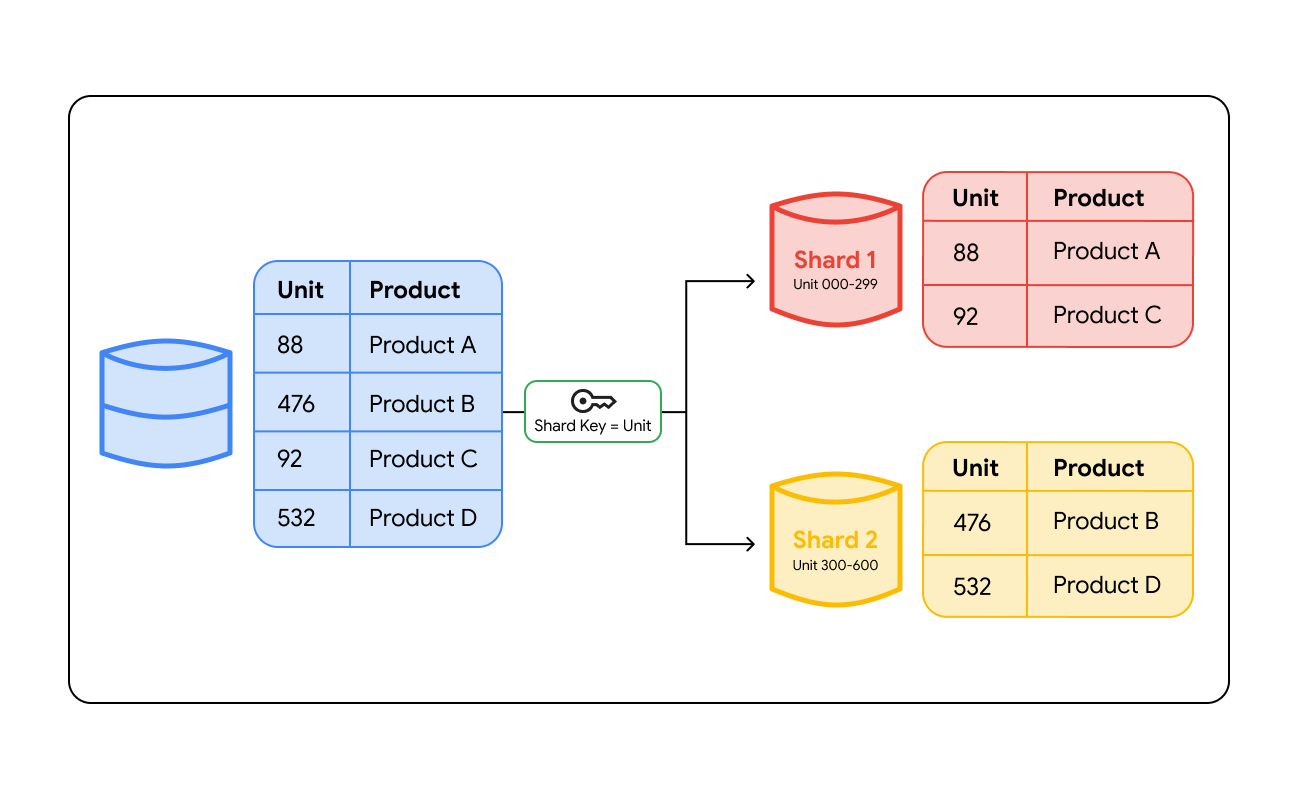
La fragmentación de bases de datos funciona agrupando los datos según un valor específico denominado "clave de fragmentación". Una clave de fragmentación es una columna de tu base de datos, como un ID de usuario, una región de cliente o un número de pedido, que determina qué servidor almacenará una fila de datos concreta. Cuando se escriben datos en la base de datos, el sistema consulta esta clave para decidir dónde deben almacenarse.
Para encontrar los datos más adelante, el sistema debe dirigir la consulta a la ubicación correcta. Este enrutamiento se produce de dos formas principales:
- Capa de enrutamiento: las arquitecturas de fragmentación pueden usar un balanceador de carga inteligente o una capa de proxy dedicada. Cuando una aplicación envía una consulta, la capa de enrutamiento comprueba la clave de fragmentación, calcula qué fragmento contiene esos datos y dirige el tráfico a ese servidor.
- Lógica del lado de la aplicación: en algunos casos, como en los juegos multijugador o en las aplicaciones de alto rendimiento en tiempo real, el código de la aplicación contiene la lógica de fragmentación. El código calcula la ubicación del fragmento correcto antes de enviar la solicitud, lo que puede reducir la latencia al eliminar un salto de red adicional.
Al dirigirse solo al fragmento pertinente, la base de datos responde a las consultas más rápido y gestiona miles de solicitudes simultáneas sin ralentizarse.
Métodos de partición más comunes
Cada aplicación requiere una lógica diferente para dividir los datos. El método que elijas determinará cómo encuentra tus datos la "capa de enrutamiento".
Fragmentación basada en claves (fragmentación por hash)
Este método usa una fórmula matemática (una función hash) en la clave de fragmento para asignar datos. Por ejemplo, el sistema podría calcular el ID de usuario (módulo 4) para asignar un usuario a uno de los cuatro servidores.
Aunque las funciones hash ayudan a distribuir los datos de forma uniforme, solo aseguran una distribución uniforme si la clave de fragmentación tiene una cardinalidad alta y una baja desviación de frecuencia. Si eliges una clave de partición con un valor común, como "Apellido", donde "Pérez" aparece 1000 veces más que "García", la función hash enviará todos los registros de "Pérez" al mismo fragmento. Esto crea un "fragmento caliente" a pesar de usar una fórmula matemática.
Añadir nuevos servidores también es difícil con este método, ya que la fórmula cambia, lo que a menudo requiere que "vuelvas a fragmentar" o que muevas tus datos a través del nuevo clúster de servidores.
Fragmentación por rangos
Los datos se asignan en función de intervalos de valores. Por ejemplo, puedes colocar los IDs de usuario del 1 al 1000 en el servidor A y los del 1001 al 2000 en el servidor B. Es muy intuitivo y resulta ideal para las consultas que necesitan leer una secuencia de datos (consultas de rango). La desventaja es que se crean "puntos calientes": si todos los usuarios nuevos se asignan al servidor B, este hará todo el trabajo mientras que el servidor A se mantiene inactivo.
Fragmentación basada en directorios
Esta estrategia usa una tabla de consulta (un directorio) que registra exactamente qué fragmento contiene qué datos. Ofrece la mayor flexibilidad, ya que puedes mover datos entre fragmentos sin cambiar una fórmula. Sin embargo, esta tabla de consulta se convierte en un cuello de botella, ya que cada consulta debe comprobar primero el directorio, lo que añade latencia. Si el directorio falla, toda la base de datos se vuelve inaccesible.
Fragmentación geográfica
La fragmentación geográfica asigna datos a servidores específicos en función de la ubicación física de un usuario. Por ejemplo, los datos de los usuarios de Francia se almacenan en servidores de la UE, mientras que los de los usuarios de EE. UU. se almacenan en servidores de Norteamérica. Esto reduce significativamente la latencia (velocidad) para los usuarios y ayuda a las empresas a cumplir las leyes de residencia de datos, como el RGPD.
Fragmentación vertical
A veces se denomina partición funcional y consiste en dividir los datos por función en lugar de por fila. Por ejemplo, puedes colocar todas las tablas "Perfil de usuario" en el servidor A y todas las tablas "Subida de fotos" en el servidor B. Aunque esto organiza los datos de forma lógica, es funcionalmente similar a una arquitectura de datos de microservicios y no resuelve el problema si una función específica (como Fotos) crece demasiado para un solo servidor.
Cómo optimizar la fragmentación de bases de datos para distribuir los datos de forma uniforme
Elegir la clave de fragmentación adecuada es la decisión más importante en la fragmentación. Una clave incorrecta puede provocar una distribución desigual de los datos (puntos calientes), mientras que una clave correcta puede asegurar que todos los servidores funcionen por igual. Para optimizar esto, debes tener en cuenta tres factores:
- Cardinalidad: se refiere al número de valores únicos que puede tener una clave. Necesitas una clave con alta cardinalidad (como un ID de usuario), no con baja cardinalidad (como "Sexo" o "Estado"), para que los datos se puedan dividir en muchos fragmentos pequeños.
- Frecuencia: debes evitar las claves en las que un valor específico aparezca con demasiada frecuencia. Por ejemplo, si haces el fragmento por "Ciudad" y el 80 % de tus usuarios viven en Nueva York, el fragmento "Nueva York" estará sobrecargado.
- Cambio monotónico: evita las claves que aumentan estrictamente con el tiempo, como una marca de tiempo o un ID de incremento automático. Si haces fragmentos por fecha, todas las escrituras de datos nuevos irán al fragmento "Hoy", lo que creará un punto de acceso de escritura mientras que los fragmentos más antiguos permanecerán inactivos.
Términos clave sobre la fragmentación
Aunque estos términos se suelen usar juntos en el diseño de sistemas, resuelven problemas diferentes.
Fragmentación
La fragmentación es un tipo específico de partición horizontal en la que los fragmentos de datos se distribuyen en servidores completamente diferentes. De esta forma, se resuelven tanto los límites de capacidad de hardware (almacenamiento) como los cuellos de botella de rendimiento de escritura, ya que diferentes servidores pueden procesar escrituras simultáneamente.
- Fragmentación manual: en un entorno de fragmentación manual, el desarrollador o el administrador de la base de datos es el responsable de definir las claves de fragmentación, crear la infraestructura de cada fragmento y escribir la lógica para enrutar las consultas. Esto te permite controlar al detalle dónde se almacenan los datos. Sin embargo, esto requiere un mantenimiento considerable. Si un fragmento se hace demasiado grande, debes volver a fragmentar los datos manualmente, lo que implica mover millones de filas a nuevos servidores intentando minimizar el periodo de inactividad de la aplicación.
- Fragmentación automática: la fragmentación automática, que suele encontrarse en bases de datos NoSQL como Bigtable o en bases de datos SQL distribuidas como Spanner, gestiona la distribución de datos y tráfico automáticamente. El sistema monitoriza el tamaño de los datos y la carga de cada servidor. Si un fragmento específico se convierte en un "punto caliente" o crece demasiado, el motor de la base de datos lo divide automáticamente y mueve los datos a un servidor menos congestionado. De esta forma, se reduce la carga operativa de tu equipo y se asegura un rendimiento uniforme a medida que tu aplicación se escala.
Particiones
La creación de particiones consiste en dividir una tabla grande en partes más pequeñas y fáciles de gestionar (por ejemplo, dividir una tabla de registros por meses), pero manteniéndolas en la misma instancia de servidor. Esto resuelve los problemas de almacenamiento, ya que facilita el archivado o la eliminación de datos antiguos sin que afecte al resto de la tabla. Sin embargo, no soluciona los problemas del servidor. Como todas las particiones siguen residiendo en una sola máquina, siguen compartiendo la misma CPU y RAM, lo que significa que la partición no puede ayudar si el servidor alcanza sus límites de rendimiento.
Replicación
La replicación es el proceso de copiar toda la base de datos en varios servidores. Esta puede ser una buena opción para la disponibilidad de lectura, ya que si un servidor falla, otro puede tomar el relevo. Sin embargo, no ayuda a escalar las escrituras, ya que cada dato escrito debe copiarse en cada réplica, lo que limita la velocidad de escritura a la capacidad de una sola máquina.
Igualmente importante es que la mayoría de los modelos de replicación solo permiten un editor (el nodo principal) a la vez. Si intentas permitir que varios servidores acepten escrituras simultáneamente, corres el riesgo de que se produzcan conflictos de escritura, en los que dos servidores intentan actualizar el mismo registro con información diferente. Resolver estos conflictos es técnicamente difícil y puede provocar la pérdida o la incoherencia de los datos si no se gestionan mediante un sistema distribuido sofisticado.
Bases de datos distribuidas
Una base de datos distribuida, como Spanner, ofrece las ventajas de la fragmentación sin la sobrecarga manual. Estos sistemas están diseñados para funcionar en un clúster de máquinas desde el principio. Se encargan automáticamente de la distribución, el reequilibrio y la replicación de los datos de forma transparente. Algunos de estos sistemas tienen varios escritores y gestionan automáticamente los conflictos de escritura. Esto te permite escalar horizontalmente sin perder la coherencia de una base de datos relacional tradicional.
Consulta la siguiente tabla para entender las diferencias entre estos conceptos básicos de las bases de datos.
Función | Fragmentación | Particiones | Replicación | Base de datos distribuida |
Objetivo principal | Escalado de escritura y almacenamiento masivos | Gestionabilidad y mantenimiento | Alta disponibilidad y escalado de lectura | Escalado mundial automatizado |
Ubicación de los datos | Diferentes fragmentos de datos en distintos servidores | Diferentes fragmentos de datos en el mismo servidor | Copias de los mismos datos en varios servidores | Gestionada en un clúster |
Rendimiento de escritura | Gran mejora (las escrituras se producen en paralelo) | Mejora menor (índices más bajos) | Sin mejora (las escrituras tienen lugar en todas las copias) | Gran mejora |
Complejidad | Alta | Media | Baja | Baja (gestionada) |
Función
Fragmentación
Particiones
Replicación
Base de datos distribuida
Objetivo principal
Escalado de escritura y almacenamiento masivos
Gestionabilidad y mantenimiento
Alta disponibilidad y escalado de lectura
Escalado mundial automatizado
Ubicación de los datos
Diferentes fragmentos de datos en distintos servidores
Diferentes fragmentos de datos en el mismo servidor
Copias de los mismos datos en varios servidores
Gestionada en un clúster
Rendimiento de escritura
Gran mejora (las escrituras se producen en paralelo)
Mejora menor (índices más bajos)
Sin mejora (las escrituras tienen lugar en todas las copias)
Gran mejora
Complejidad
Alta
Media
Baja
Baja (gestionada)
Ventajas de la fragmentación de bases de datos
El particionamiento suele ser la única solución viable para las aplicaciones que gestionan terabytes de datos o millones de transacciones por segundo.
Escalado horizontal
Escalado horizontal
El particionamiento permite una escalabilidad casi infinita añadiendo servidores estándar a un clúster. De esta forma, se evita el "impuesto del hardware" de las aplicaciones antiguas que se escalan verticalmente. Sin el particionamiento, a menudo te ves obligado a comprar hardware especializado y caro que alcanza un límite de rendimiento. El particionamiento permite que la base de datos crezca junto con tu empresa usando máquinas más asequibles y de uso general
Rendimiento de las consultas mejorado
Rendimiento de las consultas mejorado
El particionamiento acelera las consultas individuales porque cada servidor busca en un conjunto de datos más pequeño. En lugar de buscar en un índice de 100 millones de filas, una consulta solo tendría que buscar en un fragmento con 1 millón de filas. Además, como los datos están en distintas máquinas, puedes ejecutar varias consultas en paralelo, lo que aumenta enormemente el rendimiento total de la aplicación.
Fiabilidad
Fiabilidad
El particionamiento limita el alcance de un fallo. Si falla una partición, solo se verán afectados esos usuarios, mientras que el resto de la aplicación seguirá online. Sin embargo, más servidores implican una mayor carga administrativa. Gestionar las copias de seguridad, la seguridad y los parches en decenas de instancias aumenta la complejidad operativa en comparación con una configuración de un solo servidor.
Retos de la fragmentación
Aunque el particionamiento resuelve los requisitos de escalabilidad masiva, tiene sus pros y sus contras en cuanto a las compensaciones técnicas y operativas. Deberías tener en cuenta estos retos antes de abandonar una arquitectura de una sola instancia.
- Puntos de acceso de datos: incluso con una función hash, el tráfico desigual puede crear "puntos de acceso" en los que un servidor se sobrecarga con un pequeño grupo de usuarios muy activos, mientras que otros fragmentos permanecen infrautilizados.
- Regresión del rendimiento: las consultas que no usan la clave de fragmentación requieren que el sistema "recoja" datos de todos los servidores. De forma similar, las uniones entre fragmentos son computacionalmente costosas porque la aplicación debe extraer y combinar datos de varias ubicaciones físicas.
- Complejidad operativa: gestionar un entorno fragmentado aumenta la dificultad de las tareas rutinarias. Las actualizaciones de esquemas, las copias de seguridad y la recuperación a un momento dado deben coordinarse en varias instancias independientes.
- Coherencia transaccional: muchas arquitecturas fragmentadas tienen problemas para admitir transacciones ACID en diferentes fragmentos. Esto suele obligar a los desarrolladores a gestionar situaciones complejas de "fallo parcial" o a depender de modelos de coherencia retardada.
¿Cómo puede ayudar Google Cloud con el particionamiento de bases de datos?
Google Cloud ofrece soluciones de bases de datos que ahorran el trabajo tedioso del particionamiento manual, lo que te permite centrarte en crear tu aplicación en lugar de gestionar la infraestructura.
 SpannerEs una base de datos totalmente gestionada y distribuida a nivel mundial que ofrece una experiencia sin particionamiento. Fragmenta los datos y equilibra la carga automáticamente en las distintas regiones. Como base de datos multimodelo, admite datos relacionales, de pares clave-valor y de grafos (a través de Spanner Graph) en una sola interfaz. Esto te permite escalar horizontalmente sin perder la coherencia inmediata ni la familiaridad con SQL.
SpannerEs una base de datos totalmente gestionada y distribuida a nivel mundial que ofrece una experiencia sin particionamiento. Fragmenta los datos y equilibra la carga automáticamente en las distintas regiones. Como base de datos multimodelo, admite datos relacionales, de pares clave-valor y de grafos (a través de Spanner Graph) en una sola interfaz. Esto te permite escalar horizontalmente sin perder la coherencia inmediata ni la familiaridad con SQL. CloudSQL y AlloyDBSi prefieres los motores de bases de datos relacionales tradicionales, Google Cloud ofrece instancias gestionadas para PostgreSQL, MySQL y SQL Server. Tanto Cloud SQL como AlloyDB admiten el particionamiento nativo para gestionar tablas grandes en una sola instancia. También puedes crear arquitecturas de particionamiento personalizadas con estas instancias para escalar cargas de trabajo en varias máquinas, mientras que AlloyDB añade rendimiento para los datos exigentes.
CloudSQL y AlloyDBSi prefieres los motores de bases de datos relacionales tradicionales, Google Cloud ofrece instancias gestionadas para PostgreSQL, MySQL y SQL Server. Tanto Cloud SQL como AlloyDB admiten el particionamiento nativo para gestionar tablas grandes en una sola instancia. También puedes crear arquitecturas de particionamiento personalizadas con estas instancias para escalar cargas de trabajo en varias máquinas, mientras que AlloyDB añade rendimiento para los datos exigentes.- BigtableBigtable es ideal para cargas de trabajo NoSQL a gran escala. Se encarga automáticamente de la fragmentación de tablas, gestiona petabytes de datos y millones de solicitudes por segundo para casos prácticos como la personalización y los datos de series temporales.
¿Necesitas ayuda para empezar?
Contactar con VentasColabora con un partner de confianza
Buscar un partnerMás información sobre Spanner
Sigue explorando


















