Was ist Datenbank-Fragmentierung?
Datenbankfragmentierung ist eine Strategie, um Skalierbarkeitsprobleme in Anwendungen mit riesigen Datenmengen zu lösen. Dabei wird ein einzelnes, großes logisches Dataset in kleinere, besser zu verwaltende Teile, sogenannte Shards, aufgeteilt. Jeder Shard wird auf einer separaten Datenbankserverinstanz gespeichert, wodurch die Daten und die Arbeitslast effektiv auf mehrere Maschinen verteilt werden.
Fragmentierung ist eine wichtige Methode für die horizontale Skalierung (Scale-out). Anstatt einen einzelnen Server mit mehr CPU oder RAM aufzurüsten (vertikale Skalierung), was irgendwann an die Hardwaregrenzen stößt, können Sie mit Fragmentierung Ihrem Cluster weitere Standardserver hinzufügen. So können Anwendungen ein nahezu unbegrenztes Wachstum des Datenvolumens und des Nutzerverkehrs bewältigen.

Fragmentierung ist eine leistungsstarke Methode zur horizontalen Skalierung, aber es gibt noch zwei weitere gängige Strategien:
- Lesereplikate: Hierbei werden Kopien der primären Datenbank erstellt, um schreibgeschützten Traffic zu verarbeiten. Dadurch wird die Belastung des Hauptservers reduziert.
- Fragmentierung: Hier werden sowohl Daten als auch Schreibtraffic auf mehrere unabhängige Server verteilt.
- Verteilte Datenbanken: Produkte wie Cloud Spanner verwalten die Verteilung und Skalierung nativ in der Datenbank-Engine selbst, sodass keine manuelle Fragmentierung erforderlich ist.
Wie funktioniert Datenbank-Fragmentierung?
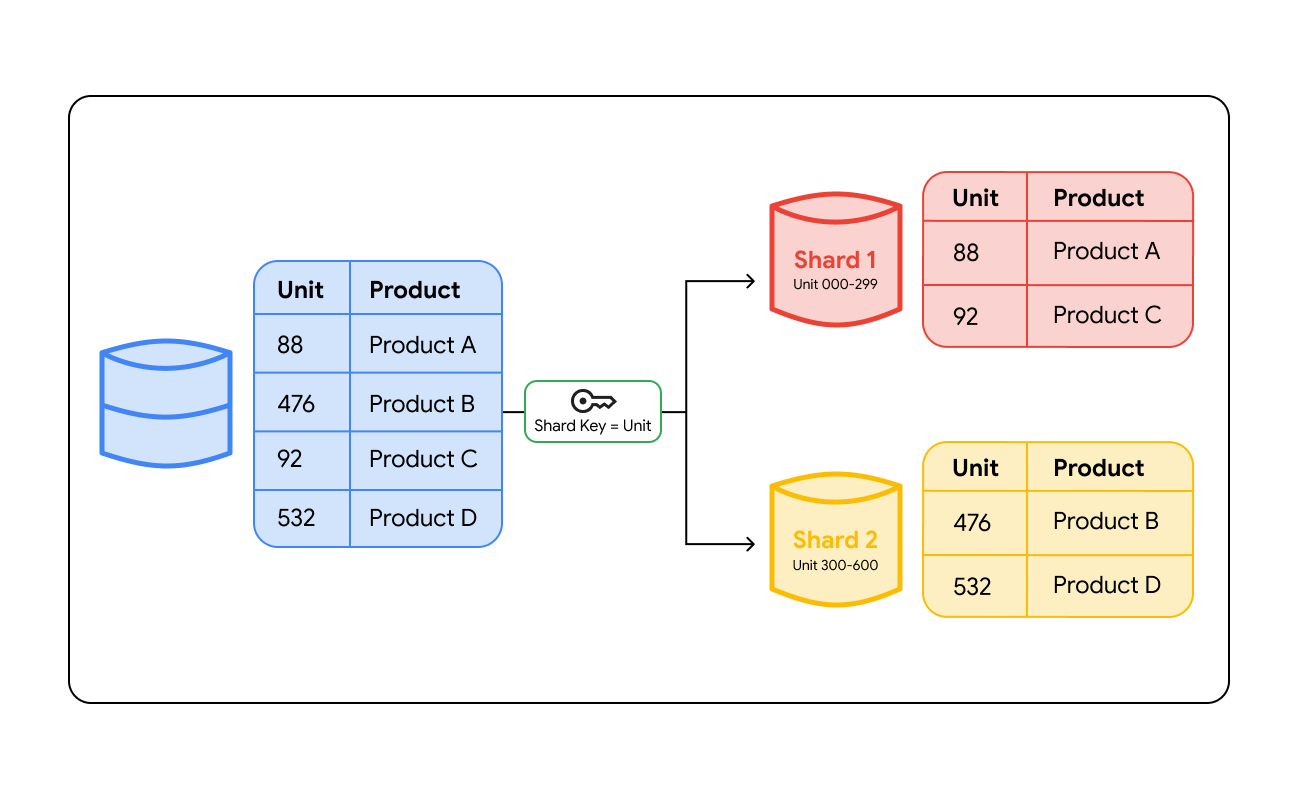
Bei der Datenbankfragmentierung werden Daten anhand eines bestimmten Werts, des Shard-Schlüssels, gruppiert. Ein Shard-Schlüssel ist eine Spalte in Ihrer Datenbank, z. B. eine Nutzer-ID, eine Kundenregion oder eine Bestellnummer, die bestimmt, auf welchem Server eine bestimmte Datenzeile gespeichert wird. Wenn Daten in die Datenbank geschrieben werden, wird anhand dieses Schlüssels entschieden, wo die Daten hingehören.
Um die Daten später zu finden, muss das System die Abfrage an den richtigen Ort weiterleiten. Das Routing erfolgt auf zwei Arten:
- Routingebene: Fragmentierungsarchitekturen können einen intelligenten Load Balancer oder eine dedizierte Proxyschicht verwenden. Wenn eine Anwendung eine Abfrage sendet, prüft die Routingebene den Shard-Schlüssel, berechnet, welcher Shard die Daten enthält, und leitet den Traffic an diesen Server weiter.
- Anwendungsseitige Logik: In einigen Fällen, z. B. bei Mehrspieler-Games oder leistungsstarken Echtzeit-Apps, enthält der Anwendungscode selbst die Fragmentierungslogik. Der Code berechnet den richtigen Shard-Standort, bevor er die Anfrage sendet. Dadurch kann die Latenz reduziert werden, da ein zusätzlicher Netzwerk-Hop entfällt.
Da nur das relevante Fragment angesprochen wird, beantwortet die Datenbank Anfragen schneller und verarbeitet Tausende gleichzeitiger Anfragen, ohne langsamer zu werden.
Gängige Fragmentierungsmethoden
Für verschiedene Anwendungen ist unterschiedliche Logik zum Aufteilen von Daten erforderlich. Die gewählte Methode bestimmt, wie die „Routingebene“ Ihre Daten findet.
Schlüsselbasierte Fragmentierung (Hash-Sharding)
Bei dieser Methode wird eine mathematische Formel (eine Hash-Funktion) auf den Shard-Schlüssel angewendet, um Daten zuzuweisen. Das System kann beispielsweise die Nutzer-ID (mod 4) berechnen, um einen Nutzer einem von vier Servern zuzuweisen.
Hash-Funktionen sorgen zwar für eine konsistente Verteilung der Daten, aber nur dann, wenn der Shard-Schlüssel eine hohe Kardinalität und eine geringe Häufigkeitsschiefe aufweist. Wenn Sie einen Shard-Schlüssel mit einem häufigen Wert auswählen, z. B. „Nachname“, wobei „Smith“ 1.000-mal häufiger vorkommt als „Pyne“, sendet die Hash-Funktion jeden „Smith“-Datensatz an denselben Shard. So entsteht trotz der Verwendung einer mathematischen Formel ein „Hot Shard“.
Auch das Hinzufügen neuer Server ist mit dieser Methode schwierig, da sich die Formel ändert. Oft müssen Sie Ihre Daten neu aufteilen oder in den neuen Servercluster verschieben.
Bereichsbasierte Fragmentierung
Daten werden anhand von Wertebereichen zugewiesen. Sie könnten beispielsweise die Nutzer-IDs 1–1.000 auf Server A und 1.001–2.000 auf Server B platzieren. Das ist sehr intuitiv und eignet sich hervorragend für Abfragen, bei denen eine Datenfolge gelesen werden muss (Bereichsabfragen). Der Nachteil sind „Hotspots“: Wenn alle neuen Nutzer Server B zugewiesen werden, erledigt dieser Server die ganze Arbeit, während Server A untätig ist.
Verzeichnisbasierte Fragmentierung
Bei dieser Strategie wird eine Lookup-Tabelle (ein Verzeichnis) verwendet, in der genau festgehalten wird, welcher Shard welche Daten enthält. Diese Option bietet die größte Flexibilität, da Sie Daten zwischen Shards verschieben können, ohne eine Formel zu ändern. Diese Nachschlagetabelle wird jedoch zum Engpass, da jede Abfrage zuerst das Verzeichnis prüfen muss, was die Latenz erhöht. Wenn das Verzeichnis ausfällt, ist die gesamte Datenbank nicht mehr zugänglich.
Geografische Fragmentierung
Beim Geo-Sharding werden Daten bestimmten Servern zugewiesen, basierend auf dem physischen Standort des Nutzers. So werden beispielsweise Daten von Nutzern in Frankreich auf Servern in der EU gespeichert, während für Nutzer in den USA Server in Nordamerika verwendet werden. Dadurch wird die Latenz (Geschwindigkeit) für Nutzer deutlich reduziert und Unternehmen können Gesetze zur Datenresidenz wie die DSGVO einhalten.
Vertikale Fragmentierung
Bei dieser Methode, die auch als funktionale Partitionierung bezeichnet wird, werden Daten nach Merkmalen und nicht nach Zeilen aufgeteilt. Sie könnten zum Beispiel alle Tabellen mit Nutzerprofilen auf Server A und alle Tabellen mit hochgeladenen Fotos auf Server B platzieren. Das organisiert die Daten zwar logisch, ist aber funktional ähnlich wie eine Microservices-Datenarchitektur und löst das Problem nicht, wenn ein bestimmtes Feature (wie Fotos) zu groß für einen einzelnen Server wird.
Datenbank-Fragmentierung für eine gleichmäßige Datenverteilung optimieren
Die Wahl des richtigen Shard-Schlüssels ist die wichtigste Entscheidung bei der Fragmentierung. Ein schlechter Schlüssel kann zu einer ungleichmäßigen Datenverteilung (Hotspots) führen, während ein guter Schlüssel dafür sorgt, dass alle Server gleichmäßig ausgelastet sind. Dazu müssen Sie drei Faktoren berücksichtigen:
- Kardinalität: Dies bezieht sich auf die Anzahl der eindeutigen Werte, die ein Schlüssel haben kann. Sie benötigen einen Schlüssel mit hoher Kardinalität (wie eine Nutzer-ID) und nicht mit niedriger Kardinalität (wie „Geschlecht“ oder „Bundesland“), damit die Daten in viele kleine Blöcke aufgeteilt werden können.
- Häufigkeit: Vermeiden Sie Schlüssel, bei denen ein bestimmter Wert zu oft vorkommt. Wenn Sie beispielsweise nach „Stadt“ aufteilen und 80 % Ihrer Nutzer in New York leben, wird der „New York“-Shard überlastet.
- Monotone Änderung: Vermeiden Sie Schlüssel, die im Laufe der Zeit streng zunehmen, wie ein Zeitstempel oder eine automatisch inkrementierende ID. Wenn Sie nach Datum partitionieren, werden alle neuen Daten in die Partition „Heute“ geschrieben, wodurch ein Schreib-Hotspot entsteht, während ältere Partitionen im Leerlauf sind.
Wichtige Begriffe zur Fragmentierung
Diese Begriffe werden im Systemdesign oft zusammen verwendet, sie lösen aber unterschiedliche Probleme.
Fragmentierung
Fragmentierung ist eine spezielle Art der horizontalen Partitionierung, bei der die Datenstücke auf völlig unterschiedliche Server verteilt werden. So werden sowohl die Hardwarekapazitätsgrenzen (Speicher) als auch die Engpässe beim Schreibdurchsatz gelöst, da verschiedene Server Schreibvorgänge gleichzeitig verarbeiten können.
- Manuelle Fragmentierung: Bei der manuellen Fragmentierung ist der Entwickler oder Datenbankadministrator für die Definition der Shard-Schlüssel, die Erstellung der Infrastruktur für jeden Shard und das Schreiben der Logik für das Routing von Abfragen verantwortlich. So haben Sie die detaillierte Kontrolle darüber, wo sich die Daten befinden. Allerdings ist ein erheblicher Wartungsaufwand erforderlich. Wenn ein Shard zu groß wird, müssen Sie die Daten manuell neu aufteilen. Dabei werden Millionen von Zeilen auf neue Server verschoben, während die Ausfallzeit der Anwendung möglichst gering gehalten werden soll.
- Automatisches Sharding: Das automatische Sharding, das häufig in NoSQL-Datenbanken wie Bigtable oder verteilten SQL-Datenbanken wie Spanner zu finden ist, übernimmt die Verteilung von Daten und Traffic automatisch. Das System überwacht die Datengröße und die Last auf jedem Server. Wenn ein bestimmter Shard zu einem „Hotspot“ wird oder zu groß wird, teilt die Datenbank-Engine den Shard automatisch auf und verschiebt Daten auf einen weniger ausgelasteten Server. Das entlastet Ihr Team und sorgt für eine gleichbleibende Leistung, wenn Ihre Anwendung skaliert wird.
Partitionierung
Beim Partitionieren wird eine große Tabelle in kleinere, besser verwaltbare Teile aufgeteilt (z. B. eine Protokolltabelle nach Monaten), die aber auf derselben Serverinstanz verbleiben. So lassen sich Speicherprobleme lösen, da alte Daten einfacher archiviert oder gelöscht werden können, ohne dass der Rest der Tabelle beeinträchtigt wird. Serverprobleme werden dadurch jedoch nicht gelöst. Da sich alle Partitionen weiterhin auf einem einzelnen Computer befinden, teilen sie sich weiterhin dieselbe CPU und denselben RAM. Das bedeutet, dass die Partitionierung nicht hilft, wenn der Server an seine Leistungsgrenzen stößt.
Replikation
Bei der Replikation wird die gesamte Datenbank auf mehrere Server kopiert. Dies kann eine gute Wahl für die Leseverfügbarkeit sein. Wenn ein Server ausfällt, kann ein anderer übernehmen. Allerdings hilft sie nicht bei der Schreibskalierung, da jedes geschriebene Datenelement in jedes Replikat kopiert werden muss, wodurch die Schreibgeschwindigkeit auf die Kapazität einer einzelnen Maschine beschränkt wird.
Ebenso wichtig ist, dass die meisten Replikationsmodelle nur einen „Writer“ (den primären Knoten) gleichzeitig zulassen. Wenn Sie versuchen, mehreren Servern gleichzeitig das Akzeptieren von Schreibvorgängen zu erlauben, riskieren Sie Schreibkonflikte, bei denen zwei Server versuchen, denselben Datensatz mit unterschiedlichen Informationen zu aktualisieren. Diese Konflikte zu lösen ist technisch schwierig und kann zu Datenverlust oder Inkonsistenzen führen, wenn sie nicht von einem ausgeklügelten verteilten System gehandhabt werden.
Verteilte Datenbanken
Eine verteilte Datenbank wie Cloud Spanner bietet die Vorteile von Sharding ohne den manuellen Aufwand. Diese Systeme sind von Anfang an für einen Cluster von Maschinen ausgelegt. Sie kümmern sich automatisch und transparent um die Datenverteilung, das Rebalancing und die Replikation. Einige dieser Systeme nutzen mehrere Schreibvorgänge und verarbeiten Schreibkonflikte automatisch. So können Sie horizontal skalieren und gleichzeitig die Konsistenz einer herkömmlichen relationalen Datenbank beibehalten.
In der folgenden Tabelle sind die Unterschiede zwischen diesen grundlegenden Datenbankkonzepten aufgeführt.
Funktion | Fragmentierung | Partitionierung | Replikation | Verteilte Datenbank |
Hauptziel | Massive Schreibskalierung und Speicherung | Verwaltbarkeit und Wartung | Hohe Verfügbarkeit und Leseskalierung | Automatisierte globale Skalierung |
Speicherort der Daten | Verschiedene Datenblöcke auf verschiedenen Servern | Verschiedene Datenblöcke auf demselben Server | Kopien derselben Daten auf mehreren Servern | Clusterübergreifend verwaltet |
Schreibleistung | Hohe Verbesserung (Schreibvorgänge erfolgen parallel) | Geringe Verbesserung (kleinere Indizes) | Keine Verbesserung (Schreibvorgänge müssen an alle Kopien gesendet werden) | Hohe Verbesserung |
Komplexität | Hoch | Mittel | Niedrig | Niedrig (verwaltet) |
Funktion
Fragmentierung
Partitionierung
Replikation
Verteilte Datenbank
Hauptziel
Massive Schreibskalierung und Speicherung
Verwaltbarkeit und Wartung
Hohe Verfügbarkeit und Leseskalierung
Automatisierte globale Skalierung
Speicherort der Daten
Verschiedene Datenblöcke auf verschiedenen Servern
Verschiedene Datenblöcke auf demselben Server
Kopien derselben Daten auf mehreren Servern
Clusterübergreifend verwaltet
Schreibleistung
Hohe Verbesserung (Schreibvorgänge erfolgen parallel)
Geringe Verbesserung (kleinere Indizes)
Keine Verbesserung (Schreibvorgänge müssen an alle Kopien gesendet werden)
Hohe Verbesserung
Komplexität
Hoch
Mittel
Niedrig
Niedrig (verwaltet)
Vorteile von Datenbank-Fragmentierung
Sharding ist oft die einzige praktikable Lösung für Anwendungen, die Terabytes an Daten oder Millionen von Transaktionen pro Sekunde verarbeiten.
Horizontale Skalierung
Horizontale Skalierung
Durch Sharding lässt sich die Kapazität nahezu unbegrenzt skalieren, indem Standardserver zu einem Cluster hinzugefügt werden. So wird die „Hardwaresteuer“ älterer, vertikal skalierbarer Anwendungen vermieden. Ohne Sharding sind Sie oft gezwungen, teure, spezialisierte Hardware zu kaufen, die eine Leistungsgrenze erreicht. Durch Sharding kann die Datenbank mit Ihrem Unternehmen wachsen, indem kostengünstigere Standardmaschinen verwendet werden.
Verbesserte Abfrageleistung
Verbesserte Abfrageleistung
Sharding beschleunigt einzelne Abfragen, da jeder Server einen kleineren Datensatz durchsucht. Anstatt einen Index mit 100 Millionen Zeilen zu durchsuchen, muss eine Abfrage möglicherweise nur einen Shard mit 1 Million Zeilen durchsuchen. Da die Daten auf verschiedenen Computern gespeichert sind, können Sie außerdem mehrere Abfragen parallel ausführen, wodurch der Gesamtdurchsatz der Anwendung erheblich gesteigert wird.
Zuverlässigkeit
Zuverlässigkeit
Durch Sharding wird das Schadensausmaß begrenzt. Wenn ein Shard ausfällt, sind nur die Nutzer betroffen, die diesem Shard zugeordnet sind. Der Rest der App bleibt online. Mehr Server bedeuten jedoch auch einen höheren Verwaltungsaufwand. Die Verwaltung von Back-ups, Sicherheit und Patches für Dutzende von Instanzen ist komplexer als bei einer Einzelserverkonfiguration.
Herausforderungen bei der Fragmentierung
Sharding erfüllt zwar die Anforderungen an eine massive Skalierung, bringt aber erhebliche technische und betriebliche Kompromisse mit sich. Diese Herausforderungen sollten Sie berücksichtigen, bevor Sie von einer Einzelinstanzarchitektur abweichen.
- Daten-Hotspots: Selbst mit einer Hash-Funktion kann ungleichmäßiger Traffic „Hotspots“ erzeugen, bei denen ein Server durch eine kleine Gruppe sehr aktiver Nutzer überlastet wird, während andere Shards unterausgelastet bleiben.
- Leistungsregression: Bei Abfragen, die den Shard-Schlüssel nicht verwenden, muss das System die Daten auf allen Servern zusammentragen. Auch shardübergreifende Joins sind rechenintensiv, da die Anwendung Daten von mehreren physischen Standorten abrufen und zusammenführen muss.
- Betriebliche Komplexität: Die Verwaltung einer Umgebung mit Sharding erschwert Routineaufgaben. Schemaaktualisierungen, Sicherungen und die Wiederherstellung zu einem bestimmten Zeitpunkt müssen über mehrere unabhängige Instanzen hinweg koordiniert werden.
- Transaktionskonsistenz: Viele Architekturen mit Sharding haben Schwierigkeiten, ACID-Transaktionen über verschiedene Shards hinweg zu unterstützen. Dies zwingt Entwickler oft dazu, komplexe Szenarien mit Teilausfällen zu verwalten oder sich auf Modelle mit eventual consistency zu verlassen.
Wie kann Google Cloud bei der Datenbank-Fragmentierung helfen?
Google Cloud bietet Datenbanklösungen, die das mühsame manuelle Sharding überflüssig machen. So können Sie sich auf die Entwicklung Ihrer Anwendung konzentrieren, anstatt die Infrastruktur zu verwalten.
 SpannerDies ist eine vollständig verwaltete, global verteilte Datenbank, die ohne Fragmentierung auskommt. Die Daten werden automatisch aufgeteilt und die Last wird auf die Regionen verteilt. Als Multimodell-Datenbank unterstützt sie relationale, Schlüssel/Wert-Paar- und Graphdaten (über Spanner Graph) in einer einzigen Schnittstelle. So können Sie horizontal skalieren und gleichzeitig eine strikte Konsistenz und SQL-Vertrautheit beibehalten.
SpannerDies ist eine vollständig verwaltete, global verteilte Datenbank, die ohne Fragmentierung auskommt. Die Daten werden automatisch aufgeteilt und die Last wird auf die Regionen verteilt. Als Multimodell-Datenbank unterstützt sie relationale, Schlüssel/Wert-Paar- und Graphdaten (über Spanner Graph) in einer einzigen Schnittstelle. So können Sie horizontal skalieren und gleichzeitig eine strikte Konsistenz und SQL-Vertrautheit beibehalten. Cloud SQL und AlloyDBWenn Sie herkömmliche relationale Datenbankmodule bevorzugen, bietet Google Cloud verwaltete Instanzen für PostgreSQL, MySQL und SQL Server. Sowohl Cloud SQL als auch AlloyDB unterstützen die native Partitionierung, um große Tabellen auf einer einzelnen Instanz zu verwalten. Sie können mit diesen Instanzen auch benutzerdefinierte Fragmentierungsarchitekturen erstellen, um Arbeitslasten auf mehrere Maschinen zu verteilen, während AlloyDB die Leistung für anspruchsvolle Daten erhöht.
Cloud SQL und AlloyDBWenn Sie herkömmliche relationale Datenbankmodule bevorzugen, bietet Google Cloud verwaltete Instanzen für PostgreSQL, MySQL und SQL Server. Sowohl Cloud SQL als auch AlloyDB unterstützen die native Partitionierung, um große Tabellen auf einer einzelnen Instanz zu verwalten. Sie können mit diesen Instanzen auch benutzerdefinierte Fragmentierungsarchitekturen erstellen, um Arbeitslasten auf mehrere Maschinen zu verteilen, während AlloyDB die Leistung für anspruchsvolle Daten erhöht.- BigtableFür NoSQL-Arbeitslasten im riesigen Maßstab ist Bigtable ideal. Sie handhabt automatisch das „Tablet-Splitting“ (Fragmentierung), verwaltet Petabyte an Daten und Millionen von Anfragen pro Sekunde für Anwendungsfälle wie Personalisierung und Zeitreihendaten.
Benötigen Sie Hilfe beim Einstieg?
Vertrieb kontaktierenMit einem zertifizierten Partner arbeiten
Partner findenWeitere Informationen zu Spanner
Mehr ansehen


















