What is database sharding?
Database sharding is a strategy used to solve scalability issues in applications that have a massive amount of data. It involves splitting a single, large logical dataset into smaller, more manageable parts called shards. Each shard is stored on a separate database server instance, effectively spreading the data, and the workload, across multiple machines.
Sharding is a key method for horizontal scaling (scaling out). Instead of upgrading a single server with more CPU or RAM (vertical scaling), which eventually hits a hardware ceiling, sharding lets you add more commodity servers to your cluster. This allows applications to handle nearly infinite growth in data volume and user traffic.

While sharding is a powerful way to scale out, it’s one of three common horizontal scaling strategies:
- Read replicas: This involves creating copies of the primary database to handle read-only traffic, which reduces the load on the main server
- Sharding: This distributes both data and write traffic across multiple independent servers
- Distributed databases: Products like Spanner natively handle distribution and scaling within the database engine itself, removing the need for manual sharding
How does database sharding work?
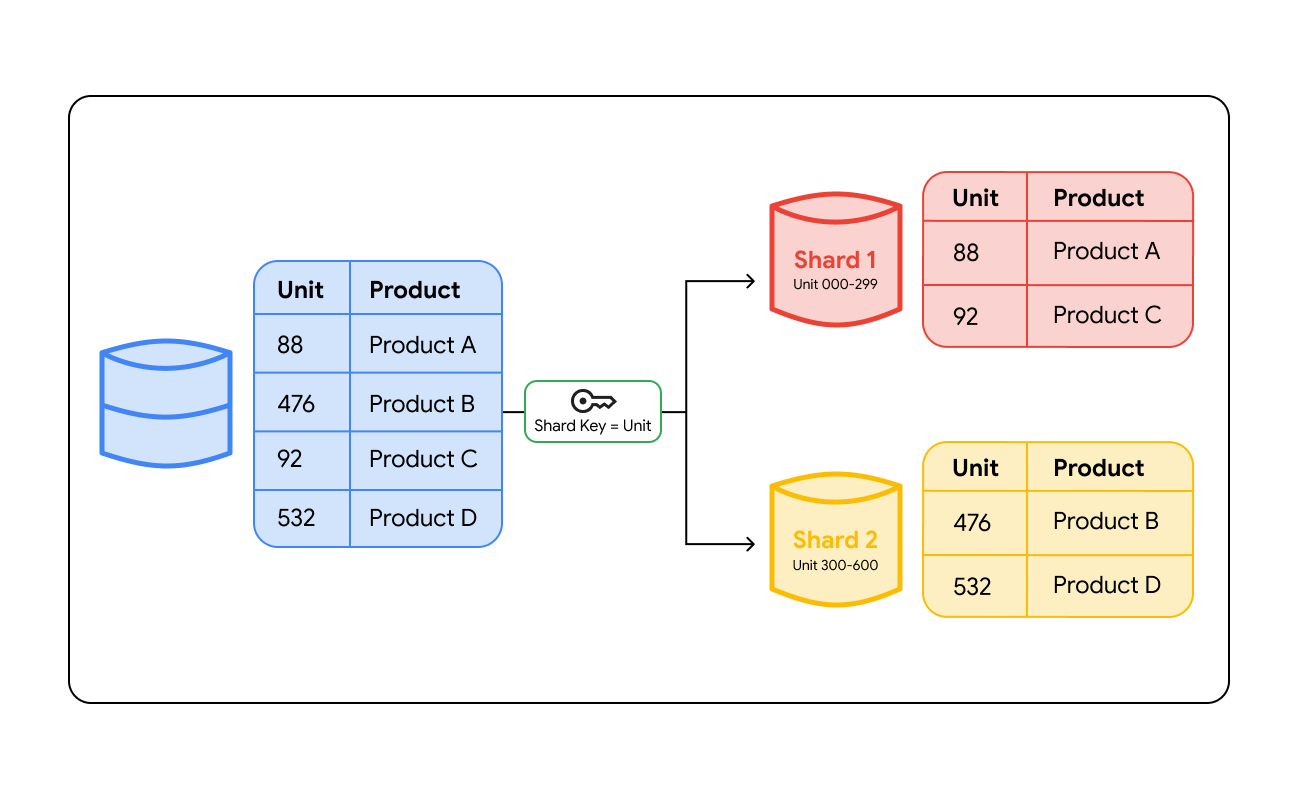
Database sharding works by grouping data based on a specific value called a shard key. A shard key is a column in your database, such as a User ID, Customer Region, or Order Number, that determines which server will store a specific row of data. When data is written to the database, the system looks at this key to decide where the data belongs.
To find the data later, the system must route the query to the correct location. This routing happens in two primary ways:
- Routing layer: Sharding architectures may use a smart load balancer or a dedicated proxy layer. When an application sends a query, the routing layer checks the shard key, calculates which shard holds that data, and directs the traffic to that server.
- Application-side logic: In some cases, such as in multi-player games or high-performance real-time apps, the application code itself contains the sharding logic. The code calculates the correct shard location before it even sends the request, which can reduce latency by removing an extra network hop.
By targeting only the relevant shard, the database answers queries faster and handles thousands of concurrent requests without slowing down.
Common sharding methods
Different applications require different logic for splitting data. The method you choose dictates how the "routing layer" finds your data.
Key-based sharding (hash sharding)
This method uses a mathematical formula (a hash function) on the shard key to assign data. For example, the system might calculate User ID (mod 4) to assign a user to 1 of 4 servers.
While hash functions help distribute data consistently, they only ensure an even distribution if the shard key has high cardinality and low frequency skew. If you choose a shard key with a common value, such as a "Last Name" where "Smith" appears 1,000 times more than "Pyne," the hash function will send every "Smith" record to the same shard. This creates a "hot shard" despite the use of a mathematical formula.
Adding new servers is also difficult with this method because the formula changes, which often requires you to "reshard" or move your data across the new server cluster.
Range-based sharding
Data is assigned based on ranges of values. For instance, you might place User IDs 1–1,000 on Server A and 1,001–2,000 on Server B. This is very intuitive and great for queries that need to read a sequence of data (range queries). The downside is "hot spots"—if all your new users are assigned to Server B, that server will do all the work while Server A sits idle.
Directory-based sharding
This strategy uses a lookup table (a directory) that tracks exactly which shard holds which data. It offers the most flexibility because you can move data between shards without changing a formula. However, this lookup table becomes a bottleneck; every query must check the directory first, adding latency. If the directory fails, the entire database becomes inaccessible.
Geo sharding
Geo sharding assigns data to specific servers based on a user's physical location. For example, data for users in France is stored on servers in the EU, while US users are on servers in North America. This significantly reduces latency (speed) for users and helps companies meet data residency laws like GDPR.
Vertical sharding
Sometimes called functional partitioning, this involves splitting data by feature rather than by row. For example, you might place all "User Profile" tables on Server A and all "Photo Upload" tables on Server B. While this organizes data logically, it is functionally similar to a microservices data architecture and doesn't solve the problem if one specific feature (like Photos) grows too large for a single server.
How to optimize database sharding for even data distribution
Choosing the right shard key is the most critical decision in sharding. A bad key can lead to uneven data distribution (hot spots), while a good key can ensure all servers work equally. To optimize this, you must look at three factors:
- Cardinality: This refers to the number of unique values a key can have. You want a key with high cardinality (like a User ID), not low cardinality (like "Gender" or "State"), so the data can be split into many small chunks.
- Frequency: You must avoid keys where one specific value appears too often. For example, if you shard by "City" and 80% of your users live in New York, the "New York" shard will be overloaded.
- Monotonic change: Avoid keys that strictly increase over time, like a Timestamp or an auto-incrementing ID. If you shard by date, all new data writes will go to the "Today" shard, creating a write hotspot while older shards sit idle.
Key sharding terms
While these terms are often used together in system design, they solve different problems.
Sharding
Sharding is a specific type of horizontal partitioning where the data pieces are distributed across completely different servers. This solves both hardware capacity limits (storage) and write throughput bottlenecks, as different servers can process writes simultaneously.
- Manual sharding: In a manual sharding environment, the developer or database administrator is responsible for defining the shard keys, creating the infrastructure for each shard, and writing the logic to route queries. This gives you granular control over exactly where data lives. However, it requires significant maintenance. If one shard becomes too large, you must manually "reshard" the data, which involves moving millions of rows to new servers while trying to minimize application downtime.
- Automatic sharding: Automatic sharding, often found in NoSQL databases like Bigtable or distributed SQL databases like Spanner, handles the distribution of data and traffic automatically. The system monitors the size of data and the load on each server. If a specific shard becomes a "hot spot" or grows too large, the database engine automatically splits the shard and moves data to a less congested server. This reduces the operational burden on your team and helps ensure consistent performance as your application scales.
Partitioning
Partitioning involves splitting a large table into smaller, more manageable pieces (like splitting a log table by month) but keeping them on the same server instance. This solves storage problems by making it easier to archive or delete old data without affecting the rest of the table. However, it does not solve server problems. Because all partitions still reside on a single machine, they continue to share the same CPU and RAM, which means partitioning cannot help if the server hits its performance limits.
Replication
Replication is the process of copying the entire database to multiple servers. This can be a good choice for read availability; if one server fails, another can take over. However, it does not help with write scaling because every piece of data written must be copied to every replica, limiting the write speed to the capacity of a single machine.
Just as importantly, most replication models only allow for one "writer" (the primary node) at a time. If you attempt to allow multiple servers to accept writes simultaneously, you risk write conflicts, where two servers try to update the same record with different information. Resolving these conflicts is technically difficult and can lead to data loss or inconsistency if not handled by a sophisticated distributed system.
Distributed databases
A distributed database, such as Spanner, provides the benefits of sharding without the manual overhead. These systems are designed to sit across a cluster of machines from the start. They automatically handle data distribution, rebalancing, and replication transparently. Some of these systems have multiple writers; and automatically handle write conflicts. This allows you to scale horizontally while maintaining the consistency of a traditional relational database.
Use the table below to understand the differences between these core database concepts.
Feature | Sharding | Partitioning | Replication | Distributed database |
Primary goal | Massive write scaling and storage | Manageability and maintenance | High availability and read scaling | Automated global scaling |
Data location | Different data chunks on different servers | Different data chunks on the same server | Copies of the same data on multiple servers | Managed across a cluster |
Write performance | High improvement (writes happen in parallel) | Minor improvement (smaller indices) | No improvement (writes must go to all copies) | High improvement |
Complexity | High | Medium | Low | Low (managed) |
Feature
Sharding
Partitioning
Replication
Distributed database
Primary goal
Massive write scaling and storage
Manageability and maintenance
High availability and read scaling
Automated global scaling
Data location
Different data chunks on different servers
Different data chunks on the same server
Copies of the same data on multiple servers
Managed across a cluster
Write performance
High improvement (writes happen in parallel)
Minor improvement (smaller indices)
No improvement (writes must go to all copies)
High improvement
Complexity
High
Medium
Low
Low (managed)
Benefits of database sharding
Sharding can often be the only viable solution for applications handling terabytes of data or millions of transactions per second.
Horizontal scaling
Horizontal scaling
Sharding enables nearly infinite scaling by adding standard servers to a cluster. This avoids the "hardware tax" of legacy, vertically-scaling applications. Without sharding, you are often forced to buy expensive, specialized hardware that hits a performance ceiling. Sharding lets the database grow alongside your business using more affordable, commodity machines
Improved query performance
Improved query performance
Sharding speeds up individual queries because each server searches a smaller dataset. Instead of searching an index of 100 million rows, a query might only need to search a shard with 1 million rows. Additionally, because the data is on different machines, you can run multiple queries in parallel, vastly increasing the total throughput of the application.
Reliability
Reliability
Sharding limits the "blast radius" of a failure. If one shard fails, only those users are affected while the rest of the app remains online. However, more servers mean a higher administrative burden. Managing backups, security, and patches across dozens of instances increases operational complexity compared to a single-server setup.
Challenges of sharding
While sharding solves massive scale requirements, it introduces significant technical and operational trade-offs. You should consider these challenges before moving away from a single-instance architecture.
- Data hotspots: Even with a hash function, uneven traffic can create "hotspots" where one server becomes overloaded by a small group of highly active users while other shards remain underutilized.
- Performance regression: Queries that don't use the shard key require the system to "scatter-gather" across every server. Similarly, cross-shard joins are computationally expensive because the application must pull and merge data from multiple physical locations.
- Operational complexity: Managing a sharded environment increases the difficulty of routine tasks. Schema updates, backups, and point-in-time recovery must be coordinated across multiple independent instances.
- Transactional consistency: Many sharded architectures struggle to support ACID transactions across different shards. This often forces developers to manage complex "partial failure" scenarios or rely on eventual consistency models.
How can Google Cloud help with database sharding
Google Cloud offers database solutions that remove the heavy lifting of manual sharding, allowing you to focus on building your application rather than managing infrastructure.
 SpannerThis is a fully managed, globally distributed database that offers a "no-sharding" experience. It automatically shards data and balances load across regions. As a multi-model database, it supports relational, key-value, and graph data (via Spanner Graph) within one interface. This allows you to scale horizontally while maintaining strong consistency and SQL familiarity.
SpannerThis is a fully managed, globally distributed database that offers a "no-sharding" experience. It automatically shards data and balances load across regions. As a multi-model database, it supports relational, key-value, and graph data (via Spanner Graph) within one interface. This allows you to scale horizontally while maintaining strong consistency and SQL familiarity. CloudSQL and AlloyDBIf you prefer traditional relational database engines, Google Cloud offers managed instances for PostgreSQL, MySQL, and SQL Server. Both Cloud SQL and AlloyDB support native partitioning to manage large tables on a single instance. You may also build custom sharding architectures using these instances to scale workloads across multiple machines, while AlloyDB adds performance for demanding data.
CloudSQL and AlloyDBIf you prefer traditional relational database engines, Google Cloud offers managed instances for PostgreSQL, MySQL, and SQL Server. Both Cloud SQL and AlloyDB support native partitioning to manage large tables on a single instance. You may also build custom sharding architectures using these instances to scale workloads across multiple machines, while AlloyDB adds performance for demanding data.- BigtableFor massive-scale NoSQL workloads, Bigtable is ideal. It automatically handles "tablet splitting" (sharding), managing petabytes of data and millions of requests per second for use cases like personalization and time-series data.
Need help getting started?
Contact salesWork with a trusted partner
Find a partnerLearn more about Spanner
Continue browsing


















