이 가이드를 시작하기 전에 빠른 시작에서 다룬 Dialogflow 기본 사항을 숙지해야 합니다.
에이전트 만들기
Dialogflow ES 콘솔을 사용하여 'PackageTracker'라는 에이전트를 만듭니다. 만드는 법을 모르겠다면 빠른 시작을 다시 확인하세요.
기존 에이전트로 작업하려는 경우도 가능합니다. 에이전트 설정에서 자동 음성 적응만 사용 설정했는지 확인하면 됩니다. 새 에이전트의 경우에는 이 옵션이 자동으로 사용 설정됩니다.
시퀀스 인식기 항목 만들기
이 에이전트의 핵심 기능은 음성을 통해 영숫자 시퀀스를 이해하는 것입니다. 특히 한 번에 조금씩 문자를 리슨하고, 모든 부속 시퀀스를 하나로 묶어서, 데이터 저장소에서 최종 시퀀스를 검증하도록 에이전트를 설정합니다. 우선 부분 시퀀스를 인식하기 위한 항목 정의로 시작합니다.
정규 표현식 시퀀스 항목 만들기
자동 음성 적응이 'a bee sea' 대신 'ABC'로 리슨할 수 있도록 정규 표현식 항목을 사용하여 시퀀스를 캡처해야 합니다.
이러한 항목은 음성 인식이 한 글자씩 철자를 말하는 시퀀스를 인식할 수 있도록 자동 음성 적응 정규 표현식 항목 가이드를 준수해야 합니다.
부분 시퀀스 항목
최소 3자 이상의 모든 영숫자 시퀀스를 수락하도록 항목을 설정합니다. 이후에는 데이터 저장소 또는 API에 대해 최종 시퀀스를 검증할 수 있도록 웹훅을 추가합니다.
- 새 항목을 생성합니다. 여기에서는 모든 영숫자 입력을 수락하기 때문에 'alphanumeric'이라고 이름을 지정합니다.
- 정규 표현식 항목 상자를 선택합니다.
- 단일 항목
^[a-zA-Z0-9]{3}[a-zA-Z0-9]*$를 추가합니다. - 저장을 클릭합니다.
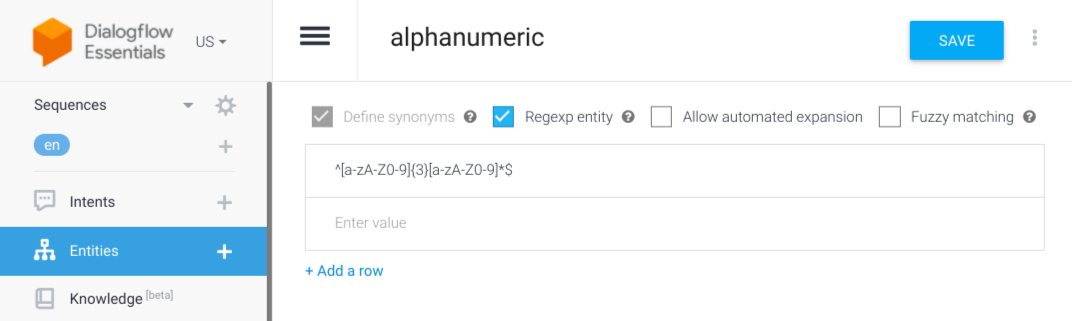
추가한 정규 표현식은 공백 또는 대시 없이 해당 영숫자 문자열만 검색한다는 점에서 매우 엄격합니다. 이것이 중요한 것은 두 가지 이유 때문입니다.
- 이 정규 표현식은 '한 글자씩 철자를 말하는 시퀀스' 인식기 모드를 사용 설정하기 위한 자동 음성 적응 요구사항을 따릅니다.
- 공백을 검색하지 않고 전체 문구(
^...$)만 검색함으로써 최종 사용자가 시퀀스 인식을 쉽게 종료하도록 허용합니다. 예를 들어 '주문 번호를 알려주세요'로 프롬프트했을 때 최종 사용자가 '아니요, 주문을 하고 싶어요'라고 응답할 경우, 정규 표현식이 처리를 거부하고 Dialogflow가 이 문구와 일치할 수 있는 다른 인텐트를 검색해야 한다는 것을 알수 있습니다.
숫자 값에만 관심이 있을 때는 [0-9]{3}[0-9]*와 같은 보다 맞춤화된 항목을 만들거나 기본 제공되는 @sys.number-sequence 항목만 사용해도 됩니다.
이 가이드의 나머지 부분에서는 영숫자 시퀀스를 수집한다고 가정합니다. 이러한 시퀀스 수집을 위해 인텐트를 설정하는 방법을 알아보려면 다음 섹션으로 이동하세요.