When your "Infrastructure as code" system grows beyond the "Hello World" example without planning, code tends to become unstructured. Unplanned configurations are hardcoded. Maintainability drops drastically.
Use this document to structure your deployments more efficiently and at scale.
In addition, enforce your naming convention and internal best practices across your teams. This document is intended for a technically advanced audience, and assumes that you have a basic understanding of Python, Google Cloud infrastructure, Deployment Manager, and, generally, infrastructure as code.
Before you begin
- If you want to use the command-line examples in this guide, install the `gcloud` command-line tool.
- If you want to use the API examples in this guide, set up API access.
Multiple environments with a single codebase
For large deployments with more than a dozen resources, standard best practices call for you to use a significant amount of external properties (configuration parameters), so that you can avoid hardcoding strings and logic to generic templates. Many of these properties are partially duplicated because of similar environments, such as development, test, or production environment, and similar services. For example, all the standard services are running on a similar LAMP stack. Following these best practices results in a large set of configuration properties with a high amount of duplication that can become hard to maintain, thus increasing the chance of human error.
The following table is a code sample to illustrate the differences between hierarchical versus a single configuration per deployment. The table highlights a common duplication in single configuration. By using hierarchical configuration, the table shows how to move repeating sections to a level higher in the hierarchy to avoid repetition and to decrease the chances of human error.
| Template | Hierarchical configuration with no redundancy | Single configuration with redundancy |
|---|---|---|
|
|
N/A |
|
|
|
|
|
|
|
|
|
To better handle a large codebase, use a structured hierarchical layout with a cascading merge of configuration properties. To do this, you use multiple files for configuration, rather than just one. Also, you work with helper functions and share part of the codebase across your organization.
Structuring and cascading your code hierarchically offers several benefits:
- When you split the configuration into multiple files, you improve the structure and readability of the properties. You also avoid duplicating them.
- You design the hierarchical merge to cascade the values in a logical way, creating top-level configuration files that are reusable across projects or components.
- You define each property only once (other than overwrites), avoiding the need to deal with namespacing in property names.
- Your templates don't need to know about the actual environment, because the appropriate configuration is loaded based on the appropriate variables.
Structuring your codebase hierarchically
A Deployment Manager deployment contains a YAML configuration or a schema file, along with several Python files. Together, these files form the codebase of a deployment. The Python files can serve different purposes. You can use the Python files as deployment templates, as general code files (helper classes), or as code files that store configuration properties.
To structure your codebase hierarchically, you use some Python files as configuration files, rather than the standard configuration file. This approach gives you greater flexibility than linking the deployment to a single YAML file.
Treating your infrastructure as real code
An important principle for clean code is Don't Repeat Yourself (DRY)). Define everything only once. This approach makes the codebase cleaner, easier to review and validate, and easier to maintain. When a property needs to be modified in only one place, the risk of human error decreases.
For a lighter codebase with smaller configuration files and minimal duplication, use these guidelines to structure your configurations to follow the DRY principle.
Organizations, departments, environments, and modules
The foundational principles for structuring your codebase cleanly and hierarchically are to use organizations, departments, environments, and modules. These principles are optional and extendable. For a diagram of the hierarchy of the example codebase, which follows these principles, see the configuration hierarchy.
In the following diagram, a module is deployed in an environment. The configuration merger selects the appropriate configuration files on each level based on the context where it is used. It also automatically defines the system and the department.
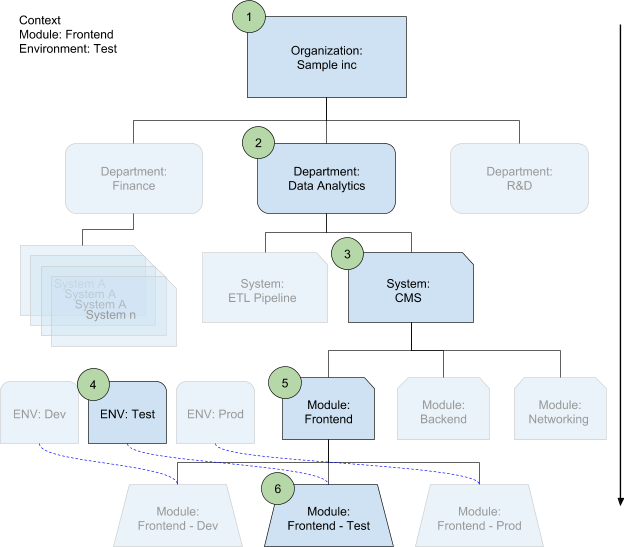
In the following list, the numbers represent the overwriting order:
Organizational properties
This is the highest level in your structure. At this level, you can store configuration properties such as
organization_name,organization_abbreviation, which you use in your naming convention, and helper functions that you wish to share and enforce across all the teams.Department properties
Organizations contain departments, if you have departments in your structure. In each department's configuration file, share properties that aren't used by other departments, for example,
department_nameorcost_center.System (project) properties
Each department contains systems. A system is a well-defined software stack, for example, your ecommerce platform. It is not a Google Cloud project, but a functioning ecosystem of services.
At the system level, your team has much more autonomy than at the levels above it. Here, you can define helper functions (such as
project_name_generator(),instance_name_generator(), orinstance_label_generator()) for the team- and system-wide parameters (for example,system_name,default_instance_size, ornaming_prefix).Environment properties
Your system is likely to have multiple environments, such as
Dev,Test, orProd(and, optionally,QAandStaging), that are fairly similar to each other. Ideally, they use the same codebase, and differ only at the configuration level. At the environment level, you can overwrite properties such asdefault_instance_sizefor theProdandQAconfigurations.Modules Properties
If your system is large, split it into multiple modules, rather than keeping it as one large monolithic block. You might, for example, move the core networking and security into separate blocks. You can also separate backend, frontend, and database layers into separate modules. Modules are templates developed by third parties, in which you add only the appropriate configuration. At the module level, you can define properties that are relevant only for particular modules, including properties designed to overwrite inherited system-level properties. The environment and module levels are parallel divisions in a system, but modules follow environments in the merge process.
Environment-specific module properties
Some of your module properties might also depend on the environment, for example, instance sizes, images, endpoints. Environment-specific module properties are the most specific level, and the last point in the cascading merge for overwriting previously defined values.
Helper class to merge configurations
The config_merger class is a helper class that automatically loads the
appropriate configuration files and merges their content into a single
dictionary.
To use the config_merger class, you must provide the following
information:
- The module name.
- The global context, which contains the environment name.
Calling the ConfigContext static function returns the merged configuration
dictionary.
The following code shows how you to use this class:
- The
module = "frontend"specifies the context, to which property files are loaded. - The environment is automatically picked from
context.properties["envName"]. The global configuration.
cc = config_merger.ConfigContext(context.properties, module) print cc.configs['ServiceName']
Behind the scenes, this helper class has to align with your configuration structures, load all the levels in the right order, and overwrite the appropriate configuration values. To change the levels or the overwriting order, you modify the configuration merger class.
In daily and routine use, you won't typically need to touch this class. Usually, you edit the templates and the appropriate configuration files, and then use the output dictionary with all the configurations in it.
The example codebase contains the following three hardcoded configuration files:
org_config.pydepartment_config.pysystem_config.py
You can create the organization and department configuration files as symbolic links during the initiation of the repository. These files can live in a separate code repository, since this isn't logically part of a project team's codebase but shared across the entire organization and department.
The configuration merger also looks for files matching the remaining levels of your structure:
envs/[environment name].py[environment name]/[module name].pymodules/[module name].py
Configuration file
Deployment Manager uses one configuration file, which is a single file for a specific deployment. It cannot be shared across deployments.
When you use the config-merger class, the configuration properties are
completely detached from this configuration file because you aren't using it.
Instead, you use a collection of Python files, which gives you a lot more
flexibility in a deployment. These files can also be shared across
deployments.
Any Python file can contain variables, which enables you to store your
configuration in a structured, but distributed, way. The best approach is to use
dictionaries with an agreed-upon structure. The configuration merger looks for a
dictionary called configs in every file in the merging chain. Those separate
configs are merged into one.
During the merge, when a property with the same path and name appears in the dictionaries multiple times, the configuration merger overwrites that property. In some cases, this behavior is useful, such as when a default value is overwritten by a context-specific value. However, there are many other cases where you want to avoid overwriting the property. To prevent the overwriting of a property, add a separate namespace to it to make it unique. In the following example you add a namespace, by creating an additional level in the configuration dictionary, which creates a subdictionary.
config = {
'Zip_code': '1234'
'Count': '3'
'project_module': {
'admin': 'Joe',
}
}
config = {
'Zip_code': '5555'
'Count': '5'
'project_module_prod': {
'admin': 'Steve',
}
}
Helper classes and naming conventions
Naming conventions are the best way to keep your Deployment Manager
infrastructure under control. You don't want to use any vague or generic names,
such as my project or test instance.
The following example is an organization-wide naming convention for instances:
def getInstanceName(self, name):
return '-'.join(self.configs['Org_level_configs']['Org_Short_Name'],
self.configs['Department_level_configs']['Department_Short_Name'],
self.configs['System_short_name'],
name,
self.configs["envName"])
Providing a helper function makes it easy to name each instance based on the agreed-upon convention. It also makes code review easy because no instance name comes from anywhere other than this function. The function automatically picks up names from higher-level configurations. This approach helps to avoid unnecessary input.
You can apply these naming conventions to most Google Cloud resources and for labels. More complex functions can even generate a set of default labels.
Folder structure of the example codebase
The folder structure of the example codebase is flexible and customizable. However, it is partially hardcoded to the configuration merger and the Deployment Manager schema file, which means that if you make a modification, you need to reflect those changes in the configuration merger and schema files.
├── global
│ ├── configs
│ └── helper
└── systems
└── my_ecom_system
├── configs
│ ├── dev
│ ├── envs
│ ├── modules
│ ├── prod
│ └── test
├── helper
└── templates
The global folder contains files that are shared across different project teams. For simplicity, the configuration folder contains the organization configuration and all the departments' configuration files. In this example, there is no separate helper class for departments. You can add any helper class at the organization or system level.
The global folder can live in a separate Git repository. You can reference its files from the individual systems. You can also use symbolic links, but they might create confusion or breaks in certain operating systems.
├── configs
│ ├── Department_Data_config.py
│ ├── Department_Finance_config.py
│ ├── Department_RandD_config.py
│ └── org_config.py
└── helper
├── config_merger.py
└── naming_helper.py
The systems folder contains one or more different systems. The systems are separated from one other, and they don't share configurations.
├── configs │ ├── dev │ ├── envs │ ├── modules │ ├── prod │ └── test ├── helper └── templates
The configuration folder contains all the configuration files that are unique to this system, also referencing for the global configurations by symbolic links.
├── department_config.py -> ../../../global/configs/Department_Data_config.py
├── org_config.py -> ../../../global/configs/org_config.py
├── system_config.py
├── dev
│ ├── frontend.py
│ └── project.py
├── prod
│ ├── frontend.py
│ └── project.py
├── test
│ ├── frontend.py
│ └── project.py
├── envs
│ ├── dev.py
│ ├── prod.py
│ └── test.py
└── modules
├── frontend.py
└── project.py
Org_config.py:
config = {
'Org_level_configs': {
'Org_Name': 'Sample Inc.',
'Org_Short_Name': 'sampl',
'HQ_Address': {
'City': 'London',
'Country': 'UK'
}
}
}
In the helper folder, you can add further helper classes and reference the global classes.
├── config_merger.py -> ../../../global/helper/config_merger.py └── naming_helper.py -> ../../../global/helper/naming_helper.py
In the templates folder, you can store or reference the Deployment Manager templates. Symbolic links work here as well.
├── project_creation -> ../../../../../../examples/v2/project_creation └── simple_frontend.py
Best practices
The following best practices can help you structure your code hierarchically.
Schema files
In the schema file, it is a Deployment Manager requirement to list each file you use in any way during deployment. Adding an entire folder makes your code shorter and more generic.
- Helper classes:
- path: helper/*.py
- Configuration files:
- path: configs/*.py - path: configs/*/*.py
- Bulk (glob style) imports
gcloud config set deployment_manager/glob_imports True
Multiple deployments
It's a best practice for a system to contain multiple deployments, meaning they use the same sets of configurations, even if they are different modules, for example, networking, firewalls, backend, frontend. You might need to access the output of these deployments from another deployment. You can query the output of the deployment after it's ready and save it under the configurations folder. You can add these configuration files during the merging process.
Symbolic links
Symbolic links are supported by the gcloud deployment-manager commands, and
linked files are properly loaded. However, symbolic links are not supported in
every OS.
Configuration hierarchy
The following diagram is an overview of the different levels and their relations. Each rectangle represents a property file, as indicated by the filename in red.
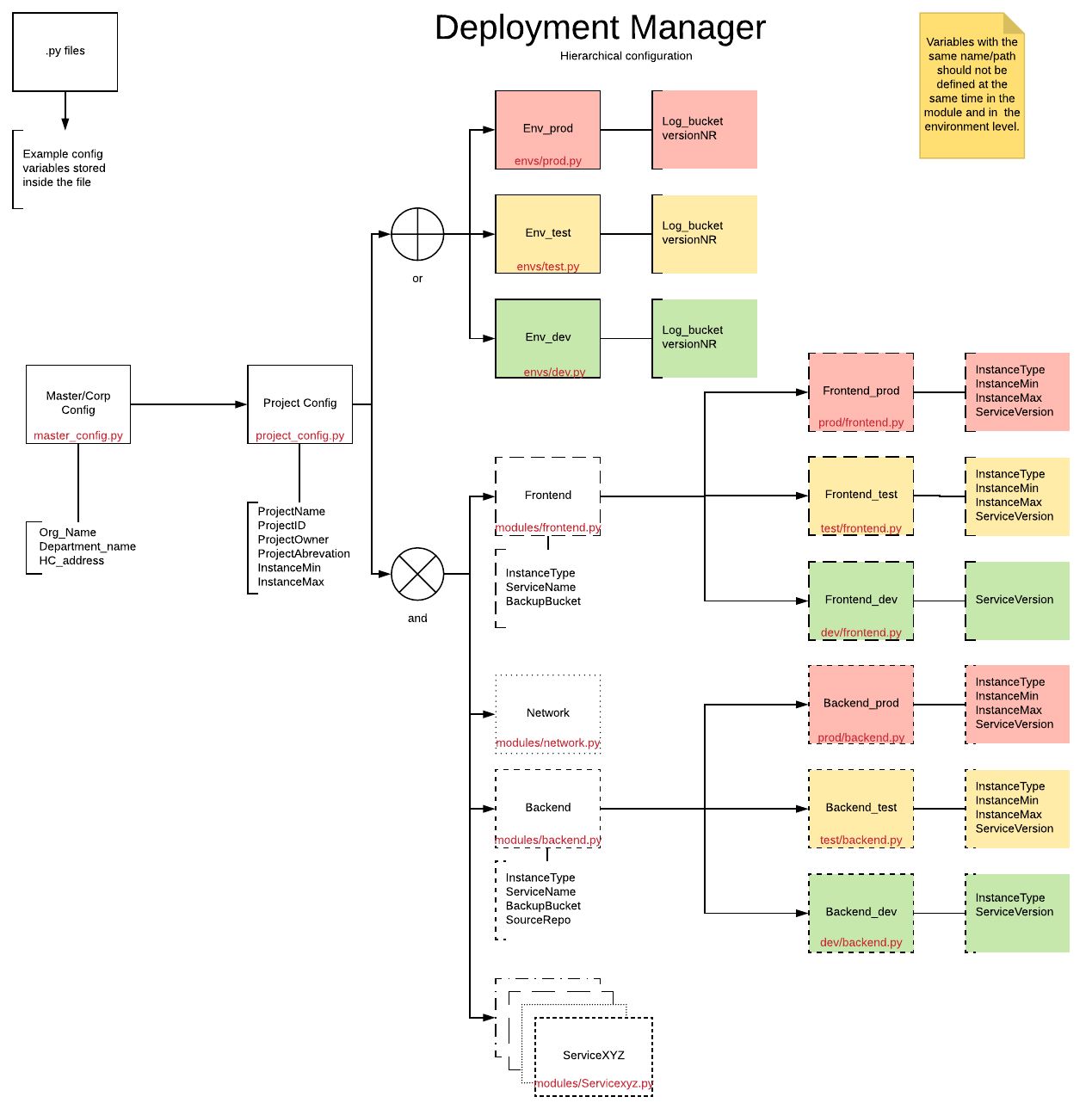
Context-aware merge order
The configuration merger selects the appropriate configuration files on each level based on the context within which each file is used. The context is a module you are deploying in an environment. This context defines the system and department automatically.
In the following diagram, the numbers represent the order of overwriting in the hierarchy:
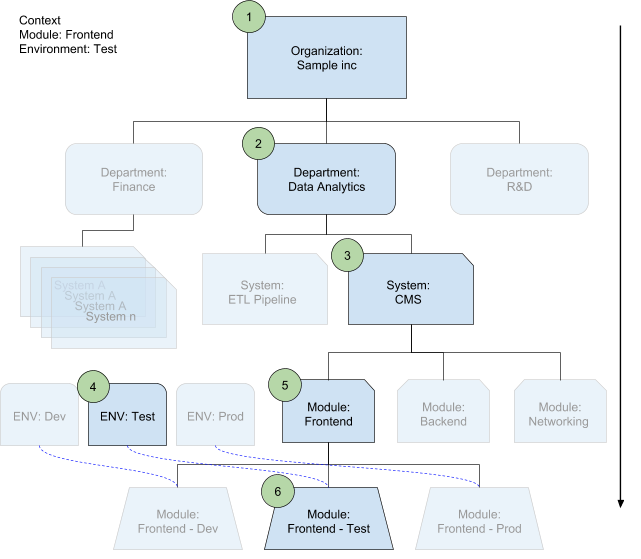
What's next
- See more example deployments in the Deployment Manager GitHub repository.
- Read more about templates and deployments.