Wenn Ihr "Infrastruktur als Code"-System ohne Planung über das "Hello World"-Beispiel hinauswächst, wird der Code leicht unstrukturiert. Nicht geplante Konfigurationen sind hartcodiert. Die Wartbarkeit sinkt drastisch.
In diesem Dokument erhalten Sie Informationen zur effizienteren und skalierten Strukturierung von Bereitstellungen.
Außerdem sollten Sie Ihre Namenskonvention und internen Best Practices bei all Ihren Teams durchsetzen. Dieses Dokument richtet sich an technisch fortgeschrittene Nutzer und setzt grundlegende Kenntnisse zu Python, zur Google Cloud-Infrastruktur, zu Deployment Manager und allgemein zur Infrastruktur als Code voraus.
Hinweise
- Wenn Sie die Befehlszeilenbeispiele in dieser Anleitung verwenden möchten, installieren Sie das gcloud-Befehlszeilentool.
- Wenn Sie die API-Beispiele in dieser Anleitung verwenden möchten, richten Sie den API-Zugriff ein.
Mehrere Umgebungen mit einer einzigen Codebasis
Bei umfangreichen Bereitstellungen mit mehr als einem Dutzend Ressourcen gilt es standardmäßig als Best Practice, eine große Menge von externen Attributen (Konfigurationsparameter) zu verwenden, sodass Sie Strings und Logik nicht in generischen Vorlagen hartcodieren müssen. Viele dieser Attribute werden aufgrund ähnlicher Umgebungen wie Entwicklungs-, Test- oder Produktionsumgebungen und ähnlicher Dienste teilweise dupliziert. Zum Beispiel werden alle Standarddienste auf einem ähnlichen LAMP-Stack ausgeführt. Die Einhaltung dieser Best Practices führt zu einer großen Anzahl von Konfigurationsattributen mit einer großen Anzahl von Duplizierungen, deren Pflege schwierig werden kann. Dadurch steigt die Wahrscheinlichkeit menschlicher Fehler.
Die folgende Tabelle ist ein Codebeispiel, das die Unterschiede zwischen der hierarchischen Konfiguration und einer Einzelkonfiguration pro Bereitstellung veranschaulicht. Die Tabelle zeigt eine häufige Duplizierung bei der Einzelkonfiguration. Bei Verwendung der hierarchischen Konfiguration wird in der Tabelle gezeigt, wie sich wiederholende Abschnitte auf eine höhere Ebene in der Hierarchie verschoben werden, um Wiederholungen zu vermeiden und die Wahrscheinlichkeit menschlicher Fehler zu verringern.
| Vorlage | Hierarchische Konfiguration ohne Redundanz | Einzelkonfiguration mit Redundanz |
|---|---|---|
|
|
– |
|
|
|
|
|
|
|
|
|
Zur besseren Handhabung einer großen Codebasis empfiehlt sich die Verwendung eines strukturierten hierarchischen Layouts mit einer kaskadierenden Zusammenführung von Konfigurationsattributen. Hierfür verwenden Sie mehrere Dateien für die Konfiguration und nicht nur eine. Außerdem arbeiten Sie mit Hilfsfunktionen und verwenden einen Teil der Codebasis innerhalb Ihrer Organisation gemeinsam.
Die hierarchische Strukturierung und Kaskadierung von Code bietet mehrere Vorteile:
- Wenn Sie die Konfiguration in mehrere Dateien aufteilen, verbessern Sie die Struktur und Lesbarkeit der Attribute. Sie vermeiden es auch, sie zu duplizieren.
- Sie entwerfen die hierarchische Zusammenführung so, dass die Werte logisch kaskadiert werden. Dabei werden Konfigurationsdateien der obersten Ebene erstellt, die für Projekte oder Komponenten wiederverwendbar sind.
- Sie definieren jedes Attribut nur einmal (mit Ausnahme von Überschreibungen), sodass Sie sich nicht mit Namespaces in Attributnamen befassen müssen.
- Ihre Vorlagen erfordern keine Informationen zur eigentlichen Umgebung, da die entsprechende Konfiguration basierend auf den entsprechenden Variablen geladen wird.
Codebasis hierarchisch strukturieren
Eine Deployment Manager-Bereitstellung enthält eine YAML-Konfigurations- oder Schemadatei sowie mehrere Python-Dateien. Zusammen bilden diese Dateien die Codebasis einer Bereitstellung. Die Python-Dateien können verschiedenen Zwecken dienen. Sie können die Python-Dateien als Bereitstellungsvorlagen, als allgemeine Codedateien (Hilfsklassen) oder als Codedateien verwenden, in denen Konfigurationsattribute gespeichert werden.
Um die Codebasis hierarchisch zu strukturieren, verwenden Sie als Konfigurationsdateien einige Python-Dateien anstatt der Standardkonfigurationsdatei. Dieser Ansatz bietet Ihnen mehr Flexibilität als das Verknüpfen der Bereitstellung mit einer einzelnen YAML-Datei.
Infrastruktur wie echten Code behandeln
Ein wichtiges Prinzip für sauberen Code ist Don't Repeat Yourself (DRY), also "wiederhole dich nicht". Definieren Sie alles nur einmal. Dieser Ansatz macht die Codebasis übersichtlicher, einfacher zu prüfen und zu validieren und leichter zu pflegen. Wenn ein Attribut nur an einer Stelle geändert werden muss, verringert sich das Risiko des menschlichen Fehlers.
Verwenden Sie diese Richtlinien und strukturieren Sie Ihre Konfigurationen entsprechend dem DRY-Prinzip, um eine schlankere Codebasis mit kleineren Konfigurationsdateien und minimaler Duplizierung zu erhalten.
Organisationen, Abteilungen, Umgebungen und Module
Die Verwendung von Organisationen, Abteilungen, Umgebungen und Modulen stellt die Grundprinzipien für eine saubere und hierarchische Strukturierung Ihrer Codebasis dar. Diese Prinzipien sind optional und erweiterbar. Ein Diagramm der Hierarchie der Beispiel-Codebasis, die diesen Prinzipien folgt, finden Sie in der Konfigurationshierarchie.
Im folgenden Diagramm wird ein Modul in einer Umgebung bereitgestellt. Die Konfigurationszusammenführung wählt die entsprechenden Konfigurationsdateien auf jeder Ebene basierend auf dem Kontext aus, in dem sie verwendet wird. Sie definiert auch automatisch das System und die Abteilung.
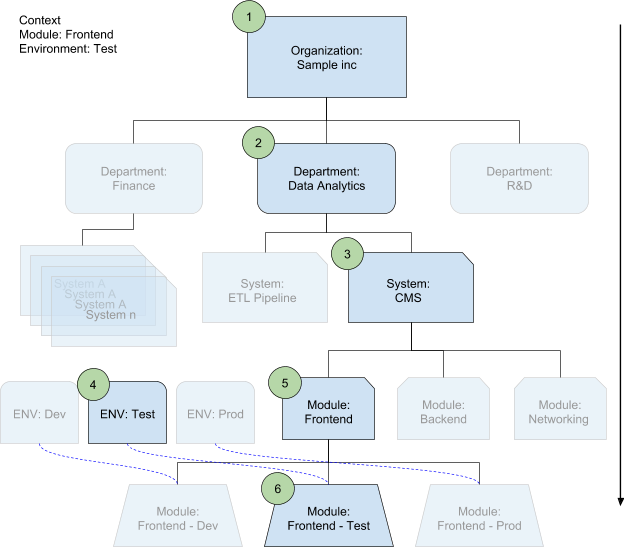
In der folgenden Liste stehen die Zahlen für die Überschreibungsreihenfolge:
Organisationsattribute
Dies ist die höchste Ebene in Ihrer Struktur. Auf dieser Ebene können Sie Konfigurationsattribute wie
organization_nameundorganization_abbreviationspeichern, die Sie in Ihrer Namenskonvention verwenden, sowie Hilfsfunktionen, die Sie teamübergreifend teilen und durchsetzen möchten.Abteilungsattribute
Organisationen enthalten Abteilungen, wenn Sie über Abteilungen in Ihrer Struktur verfügen. Geben Sie in der Konfigurationsdatei jeder Abteilung Attribute frei, die von anderen Abteilungen nicht verwendet werden, z. B.
department_nameodercost_center.System- bzw. Projektattribute
Jede Abteilung enthält Systeme. Ein System ist ein klar definierter Software-Stack, beispielsweise Ihre E-Commerce-Plattform. Es ist keinGoogle Cloud -Projekt, sondern ein funktionierendes Ökosystem von Diensten.
Auf der Systemebene hat Ihr Team viel mehr Autonomie als auf den darüber liegenden Ebenen. Hier können Sie Hilfsfunktionen definieren, z. B.
project_name_generator(),instance_name_generator()oderinstance_label_generator()für team- und systemweite Parameter (z. B.system_name,default_instance_sizeodernaming_prefix).Umgebungsattribute
Ihr System verfügt wahrscheinlich über mehrere Umgebungen (z. B.
Dev,TestoderProdund optionalQAundStaging), die einander ziemlich ähnlich sind. Im Idealfall verwenden sie dieselbe Codebasis und unterscheiden sich nur auf der Konfigurationsebene. Auf der Umgebungsebene können Sie Attribute wiedefault_instance_sizefür dieProd- undQA-Konfigurationen überschreiben.Modulattribute
Wenn Ihr System groß ist, teilen Sie es in mehrere Module auf, anstatt es als einen großen monolithischen Block zu behalten. Sie können beispielsweise das Kernnetzwerk und die Sicherheit in separate Blöcke schieben. Sie können auch Backend-, Frontend- und Datenbankschicht in separate Module aufteilen. Module sind von Dritten entwickelte Vorlagen, in denen Sie nur die entsprechende Konfiguration einfügen. Auf Modulebene können Sie Attribute definieren, die nur für bestimmte Module relevant sind, einschließlich Attribute, die dazu dienen, vererbte Attribute auf Systemebene zu überschreiben. Die Umgebungs- und Modulebenen sind parallele Einteilungen in einem System, die Module folgen jedoch den Umgebungen im Zusammenführungsprozess.
Umgebungsspezifische Modulattribute
Einige Ihrer Modulattribute können auch von der Umgebung abhängen, z. B. Instanzgrößen, Images, Endpunkte. Umgebungsspezifische Modulattribute sind die spezifischste Ebene und der letzte Punkt in der kaskadierenden Zusammenführung für die Überschreibung zuvor definierter Werte.
Hilfsklasse zum Zusammenführen von Konfigurationen
Die config_merger ist eine Hilfsklasse, die automatisch die entsprechenden Konfigurationsdateien lädt und ihren Inhalt in einem einzelnen Wörterbuch zusammenführt.
Um die Klasse config_merger zu verwenden, müssen Sie die folgenden Informationen angeben:
- Den Modulnamen
- Den globalen Kontext, der den Umgebungsnamen enthält
Beim Aufrufen der statischen Funktion ConfigContext wird das zusammengeführte Konfigurationswörterbuch zurückgegeben.
Der folgende Code zeigt, wie Sie diese Klasse verwenden:
module = "frontend"gibt den Kontext an, in den die Attributdateien geladen werden.- Die Umgebung wird automatisch aus
context.properties["envName"]ausgewählt. Die globale Konfiguration
cc = config_merger.ConfigContext(context.properties, module) print cc.configs['ServiceName']
Hinter den Kulissen muss sich diese Hilfsklasse an Ihre Konfigurationsstrukturen anpassen, alle Ebenen in der richtigen Reihenfolge laden und die entsprechenden Konfigurationswerte überschreiben. Um die Ebenen oder die Überschreibungsreihenfolge zu ändern, ändern Sie die Konfigurationszusammenführungsklasse.
Im täglichen und routinemäßigen Gebrauch müssen Sie diese Klasse normalerweise nicht ändern. In der Regel bearbeiten Sie die Vorlagen und die entsprechenden Konfigurationsdateien und verwenden dann das Ausgabewörterbuch mit allen Konfigurationen.
Die Beispiel-Codebasis enthält die folgenden drei hartcodierten Konfigurationsdateien:
org_config.pydepartment_config.pysystem_config.py
Sie können die Organisations- und Abteilungskonfigurationsdateien während der Initiierung des Repositorys als symbolische Links erstellen. Diese Dateien können in einem separaten Code-Repository gespeichert werden, da dies logischerweise nicht Teil der Codebasis eines Projektteams ist, sondern von der gesamten Organisation und Abteilung gemeinsam genutzt wird.
Die Konfigurationszusammenführung sucht auch nach Dateien, die den verbleibenden Ebenen Ihrer Struktur entsprechen:
envs/[environment name].py[environment name]/[module name].pymodules/[module name].py
Konfigurationsdatei
Deployment Manager verwendet eine Konfigurationsdatei, wobei es sich um eine einzelne Datei für eine spezifische Bereitstellung handelt. Sie kann nicht für mehrere Bereitstellungen gleichzeitig verwendet werden.
Wenn Sie die Klasse config-merger verwenden, werden die Konfigurationseigenschaften vollständig von dieser Konfigurationsdatei getrennt, da Sie sie nicht verwenden.
Stattdessen verwenden Sie eine Sammlung von Python-Dateien, wodurch Sie von viel mehr Flexibilität bei der Bereitstellung profitieren. Diese Dateien können auch von mehreren Bereitstellungen gemeinsam verwendet werden.
Jede Python-Datei kann Variablen enthalten, sodass Sie Ihre Konfiguration strukturiert, aber verteilt speichern können. Der beste Ansatz besteht darin, Wörterbücher mit einer vereinbarten Struktur zu verwenden. Die Konfigurationszusammenführung sucht in jeder Datei in der Zusammenführungskette nach einem Wörterbuch namens configs. Diese separaten configs werden zu einer zusammengefügt.
Wenn während der Zusammenführung ein Attribut mit demselben Pfad und Namen mehrmals in den Wörterbüchern erscheint, überschreibt die Konfigurationszusammenführung dieses Attribut. In einigen Fällen ist dieses Verhalten hilfreich, z. B. wenn ein Standardwert mit einem kontextspezifischen Wert überschrieben wird. Es gibt jedoch viele andere Fälle, in denen das Überschreiben des Attributs vermieden werden sollte. Um das Überschreiben eines Attributs zu verhindern, fügen Sie einen separaten Namespace hinzu, um es einmalig zu machen. Im folgenden Beispiel fügen Sie einen Namespace hinzu, indem Sie im Konfigurationswörterbuch eine zusätzliche Ebene erstellen, wodurch ein Unterwörterbuch erstellt wird.
config = {
'Zip_code': '1234'
'Count': '3'
'project_module': {
'admin': 'Joe',
}
}
config = {
'Zip_code': '5555'
'Count': '5'
'project_module_prod': {
'admin': 'Steve',
}
}
Hilfsklassen und Namenskonventionen
Namenskonventionen sind die beste Möglichkeit, um Ihre Deployment Manager-Infrastruktur unter Kontrolle zu halten. Sie sollten keine vagen oder allgemeinen Namen wie my project oder test instance verwenden.
Das folgende Beispiel ist eine organisationsweite Namenskonvention für Instanzen:
def getInstanceName(self, name):
return '-'.join(self.configs['Org_level_configs']['Org_Short_Name'],
self.configs['Department_level_configs']['Department_Short_Name'],
self.configs['System_short_name'],
name,
self.configs["envName"])
Durch die Bereitstellung einer Hilfsfunktion wird es einfach, jede Instanz basierend auf der vereinbarten Konvention zu benennen. Das erleichtert auch die Codeüberprüfung, da kein Instanzname von einer anderen Stelle als dieser Funktion stammt. Die Funktion übernimmt automatisch Namen aus übergeordneten Konfigurationen. Dieser Ansatz hilft, unnötige Eingaben zu vermeiden.
Sie können diese Namenskonventionen auf die meisten Google Cloud Ressourcen und für Labels anwenden. Komplexere Funktionen können sogar eine Reihe von Standardlabels generieren.
Ordnerstruktur der Beispiel-Codebasis
Die Ordnerstruktur der Beispiel-Codebasis ist flexibel und anpassbar. Sie ist jedoch teilweise fest mit der Konfigurationszusammenführung und der Deployment Manager-Schemadatei verbunden. Wenn Sie also eine Änderung vornehmen, müssen Sie diese Änderungen auch in der Konfigurationszusammenführung und den Schemadateien berücksichtigen.
├── global
│ ├── configs
│ └── helper
└── systems
└── my_ecom_system
├── configs
│ ├── dev
│ ├── envs
│ ├── modules
│ ├── prod
│ └── test
├── helper
└── templates
Der Ordner "global" enthält Dateien, die von verschiedenen Projektteams gemeinsam genutzt werden. Zur Vereinfachung enthält der Konfigurationsordner die Organisationskonfiguration und alle Konfigurationsdateien der Abteilungen. In diesem Beispiel gibt es keine separate Hilfsklasse für Abteilungen. Sie können auf Organisations- oder Systemebene beliebige Hilfsklassen hinzufügen.
Der Ordner "global" kann in einem separaten Git-Repository gespeichert werden. Sie können seine Dateien von den einzelnen Systemen aus referenzieren. Sie können auch symbolische Links verwenden, die jedoch bei bestimmten Betriebssystemen zu Unklarheiten oder Fehlern führen können.
├── configs
│ ├── Department_Data_config.py
│ ├── Department_Finance_config.py
│ ├── Department_RandD_config.py
│ └── org_config.py
└── helper
├── config_merger.py
└── naming_helper.py
Der Ordner "systems" enthält ein oder mehrere verschiedene Systeme. Die Systeme sind voneinander getrennt und haben keine gemeinsamen Konfigurationen.
├── configs │ ├── dev │ ├── envs │ ├── modules │ ├── prod │ └── test ├── helper └── templates
Der Konfigurationsordner enthält alle Konfigurationsdateien speziell für dieses System und verweist mit symbolischen Links auch auf die globalen Konfigurationen.
├── department_config.py -> ../../../global/configs/Department_Data_config.py
├── org_config.py -> ../../../global/configs/org_config.py
├── system_config.py
├── dev
│ ├── frontend.py
│ └── project.py
├── prod
│ ├── frontend.py
│ └── project.py
├── test
│ ├── frontend.py
│ └── project.py
├── envs
│ ├── dev.py
│ ├── prod.py
│ └── test.py
└── modules
├── frontend.py
└── project.py
Org_config.py:
config = {
'Org_level_configs': {
'Org_Name': 'Sample Inc.',
'Org_Short_Name': 'sampl',
'HQ_Address': {
'City': 'London',
'Country': 'UK'
}
}
}
Im Ordner "helper" können Sie weitere Hilfsklassen hinzufügen und die globalen Klassen referenzieren.
├── config_merger.py -> ../../../global/helper/config_merger.py └── naming_helper.py -> ../../../global/helper/naming_helper.py
Im Ordner "templates" können Sie die Deployment Manager-Vorlagen speichern oder referenzieren. Symbolische Links funktionieren auch hier.
├── project_creation -> ../../../../../../examples/v2/project_creation └── simple_frontend.py
Best Practices
Mit den folgenden Best Practices können Sie Ihren Code hierarchisch strukturieren.
Schemadateien
Deployment Manager erfordert, dass Sie in der Schemadatei jede Datei auflisten, die Sie während der Bereitstellung auf irgendeine Weise verwenden. Durch das Hinzufügen eines gesamten Ordners wird der Code kürzer und allgemeiner.
- Hilfsklassen:
- path: helper/*.py
- Konfigurationsdateien:
- path: configs/*.py - path: configs/*/*.py
- Massenimporte (Glob-Stil)
gcloud config set deployment_manager/glob_imports True
Mehrere Bereitstellungen
Es gilt als Best Practice, dass ein System mehrere Bereitstellungen enthält. Das bedeutet, dass dieselben Konfigurationen verwendet werden, auch wenn es sich um unterschiedliche Module handelt, wie z. B. Netzwerke, Firewalls, Backend, Frontend. Sie müssen möglicherweise von einer anderen Bereitstellung aus auf die Ausgabe dieser Bereitstellungen zugreifen. Sie können die Ausgabe der Bereitstellung abfragen, sobald sie fertig ist, und sie im Konfigurationsordner speichern. Sie können diese Konfigurationsdateien während des Zusammenführungsprozesses hinzufügen.
Symbolische Links
Symbolische Links werden von den gcloud deployment-manager-Befehlen unterstützt und verknüpfte Dateien werden ordnungsgemäß geladen. Symbolische Links werden jedoch nicht in allen Betriebssystemen unterstützt.
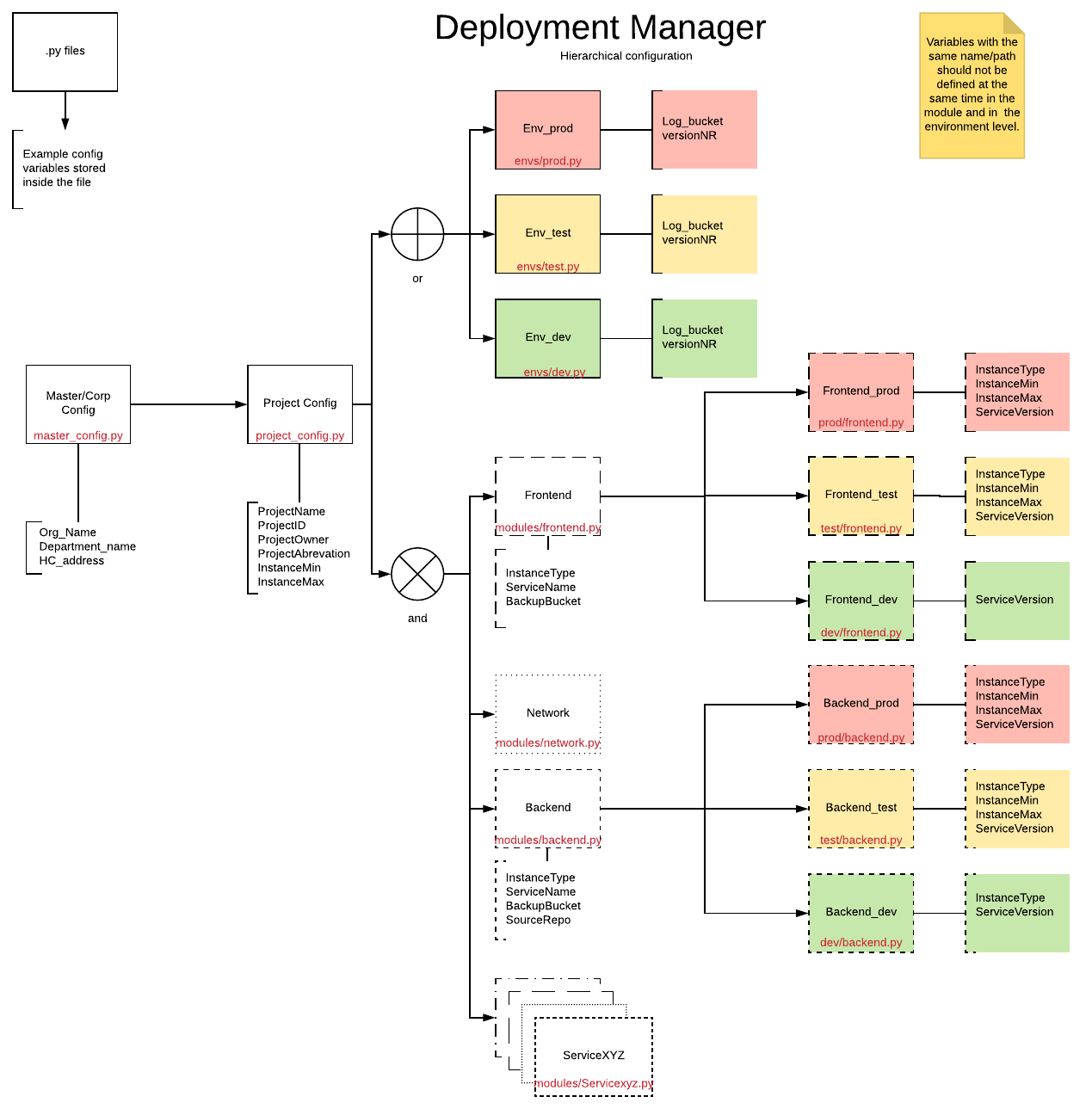
Konfigurationshierarchie
Das folgende Diagramm gibt einen Überblick über die verschiedenen Ebenen und ihre Beziehungen. Jedes Rechteck stellt eine Attributdatei dar, wie durch den Dateinamen in Rot angegeben.
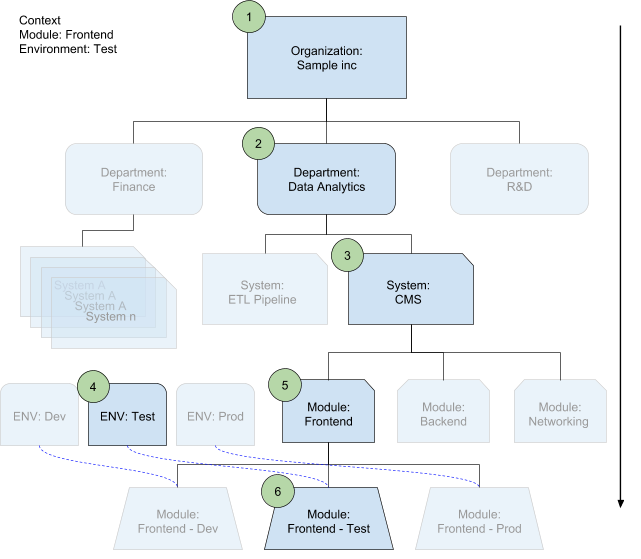
Kontextsensitive Zugriffssteuerung
Die Konfigurationszusammenführung wählt die entsprechenden Konfigurationsdateien auf jeder Ebene basierend auf dem Kontext aus, in dem jede Datei verwendet wird. Der Kontext ist ein Modul, das Sie in einer Umgebung bereitstellen. Dieser Kontext definiert das System und die Abteilung automatisch.
Im folgenden Diagramm geben die Zahlen die Reihenfolge des Überschreibens in der Hierarchie an:
Nächste Schritte
- Weitere Beispielbereitstellungen finden Sie im GitHub-Repository von Deployment Manager.
- Vorlagen und Bereitstellungen