Cloud Monitoring collecte des métriques, des événements et des métadonnées provenant des produits Google Cloud. Avec Cloud Monitoring, vous pouvez également configurer des tableaux de bord et des alertes d'utilisation personnalisés.
Ce document vous explique comment utiliser les métriques, découvrir le tableau de bord des métriques personnalisées et définir des alertes.
Ressources surveillées
Dans Cloud Monitoring, une ressource surveillée représente une entité logique ou physique, telle qu'une machine virtuelle, une base de données ou une application. Les ressources surveillées contiennent un ensemble unique de métriques qui peuvent être explorées, enregistrées dans un tableau de bord ou utilisées pour créer des alertes. Chaque ressource possède également un ensemble de libellés de ressources, qui sont des paires clé-valeur contenant des informations supplémentaires sur la ressource. Les libellés de ressources sont disponibles pour toutes les métriques associées à la ressource.
À l'aide de l'API Cloud Monitoring, les performances de Firestore en mode Datastore sont surveillées avec les ressources suivantes:
| Ressources | Description | Mode de base de données compatible |
firestore.googleapis.com/Database (recommandé) | Type de ressource surveillée qui fournit des répartitions pour project, location* et database_id . Le libellé database_id sera (default) pour les bases de données créées sans nom spécifique. | Toutes les métriques compatibles avec les deux modes, à l'exception des métriques suivantes qui ne sont pas compatibles avec Firestore en mode Datastore :
|
datastore_request | Type de ressource surveillé pour les projets Datastore et ne fournit pas de répartition pour les bases de données. |
Métriques
Firestore est disponible en deux modes différents : Firestore natif et Firestore en mode Datastore. Pour comparer les fonctionnalités de ces deux modes, consultez la section Choisir entre les modes de base de données.
Pour obtenir la liste complète des métriques de Firestore en mode Datastore, consultez la page Métriques de Firestore en mode Datastore.
Métriques d'exécution du service
Les métriques serviceruntime fournissent une vue d'ensemble du trafic d'un projet. Ces métriques sont disponibles pour la plupart des API Google Cloud. Le type de ressource surveillée consumed_api contient ces métriques courantes. Ces métriques sont échantillonnées toutes les 30 minutes, ce qui adoucit les données.
Le libellé de ressource method est important pour les métriques serviceruntime. Ce libellé représente la méthode RPC sous-jacente appelée. La méthode du SDK que vous appelez n'est pas nécessairement nommée de la même manière que la méthode RPC sous-jacente. En effet, le SDK fournit une abstraction d'API de haut niveau. Toutefois, lorsque vous essayez de comprendre comment votre application interagit avec Firestore, il est important de comprendre les métriques en fonction du nom de la méthode RPC.
Pour connaître la méthode RPC sous-jacente d'une méthode de SDK donnée, consultez la documentation de l'API.
api/request_count
Cette métrique fournit le nombre de requêtes terminées, par protocole(protocole de requête, tel que http, gRPC, etc.), code de réponse (code de réponse HTTP), response_code_class (classe de code de réponse, tels que 2xx, 4xx, etc.) et grpc_status_code (code de réponse gRPC numérique). Utilisez cette métrique pour observer la requête API globale et calculer le taux d'erreur.
Dans la figure 1, vous pouvez voir les requêtes qui renvoient un code 2xx, regroupées par service et par méthode. Les codes 2xx sont des codes d'état HTTP qui indiquent que la requête a réussi.
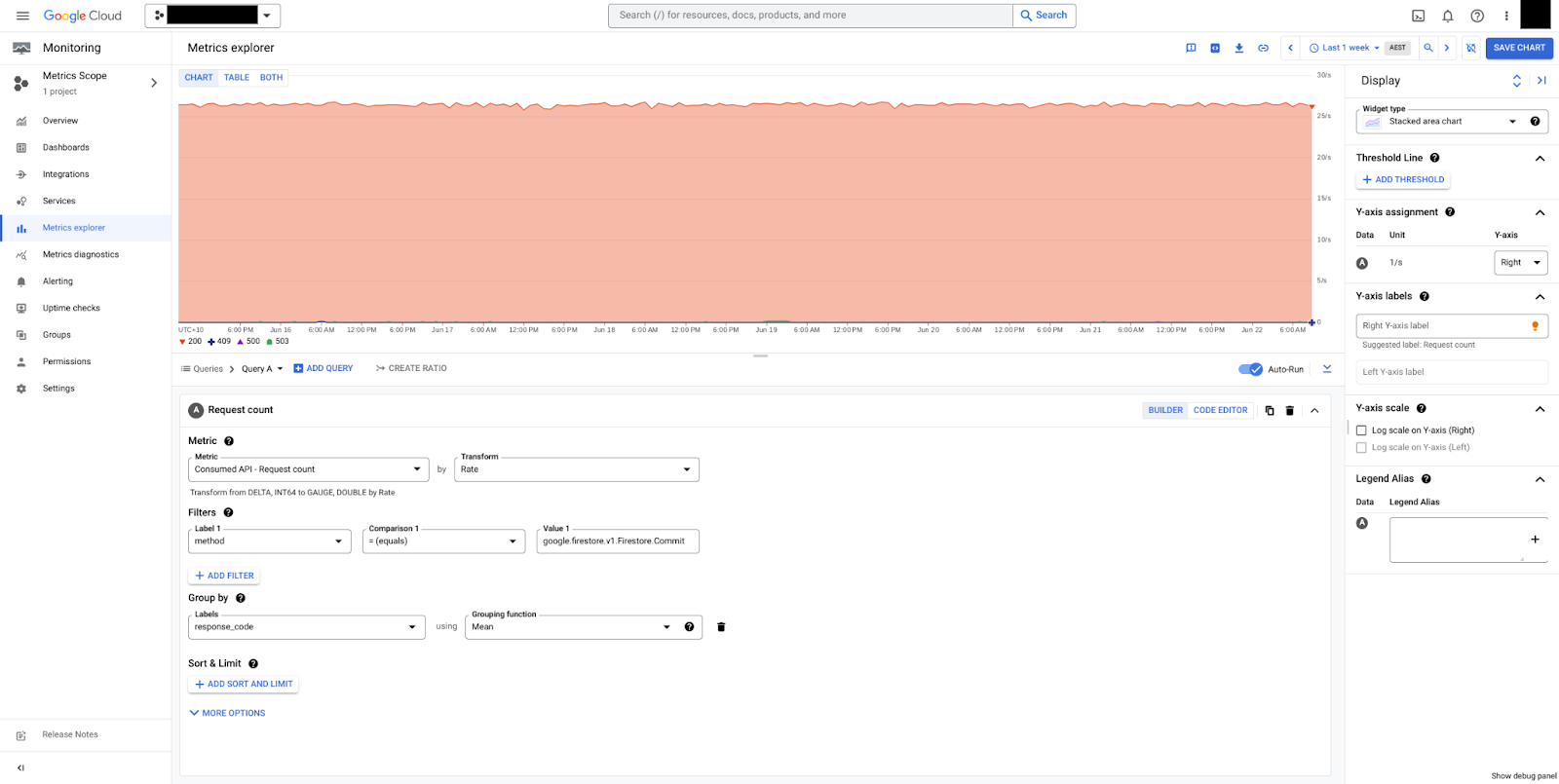
Dans la figure 2, vous pouvez voir les commits regroupés par response_code. Dans cet exemple, seules les réponses HTTP 200 s'affichent, ce qui signifie que la base de données est opérationnelle.
Utilisez les métriques d'exécution du service suivantes pour surveiller votre base de données.
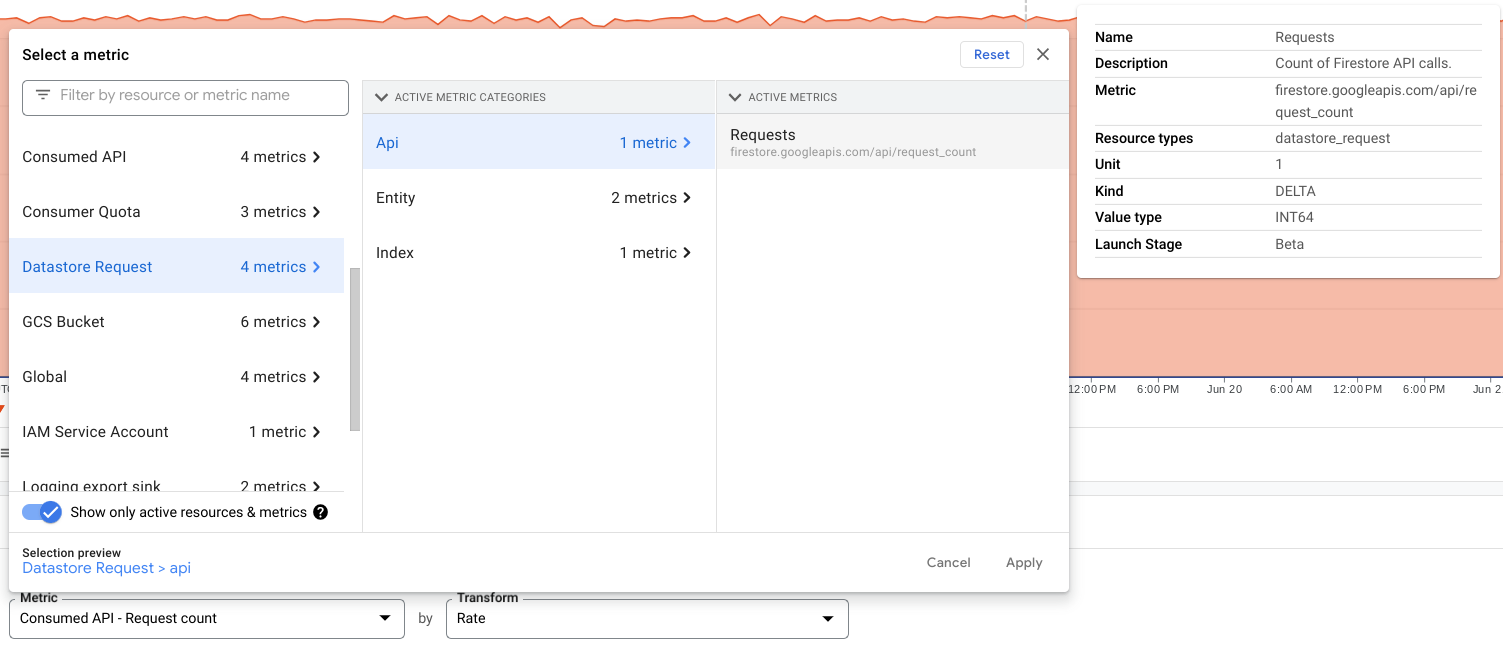
api/request_count dans le type de ressource datastore_request
La métrique api/request_count est également disponible sous le type de ressource datastore_request avec des répartitions api_method et response_code. Utilisez plutôt cette métrique pour profiter de la période d'échantillonnage plus fine, qui permet de détecter les pics.
api/request_latencies
La métrique api/request_latencies fournit des distributions de latence pour toutes les requêtes terminées.
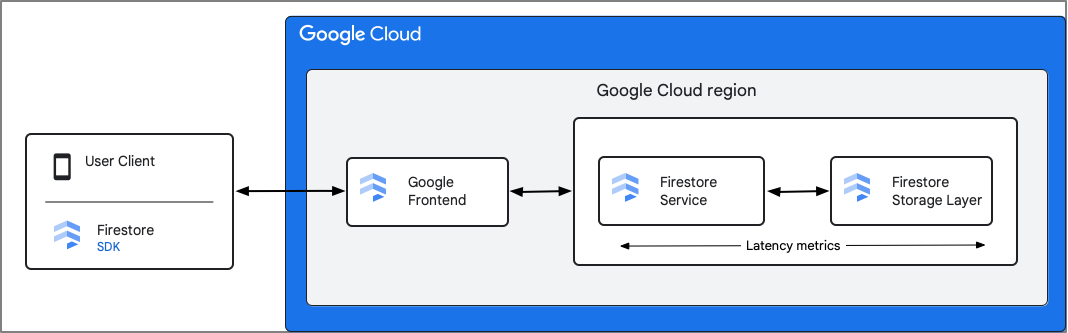
Firestore enregistre les métriques du composant Service Firestore. Les métriques de latence incluent le temps écoulé entre le moment où Firestore reçoit la requête et celui où il a fini d'envoyer la réponse, y compris les interactions avec la couche de stockage. Par conséquent, la latence aller-retour (rtt) entre le client et le service Firestore n'est pas incluse dans ces métriques.
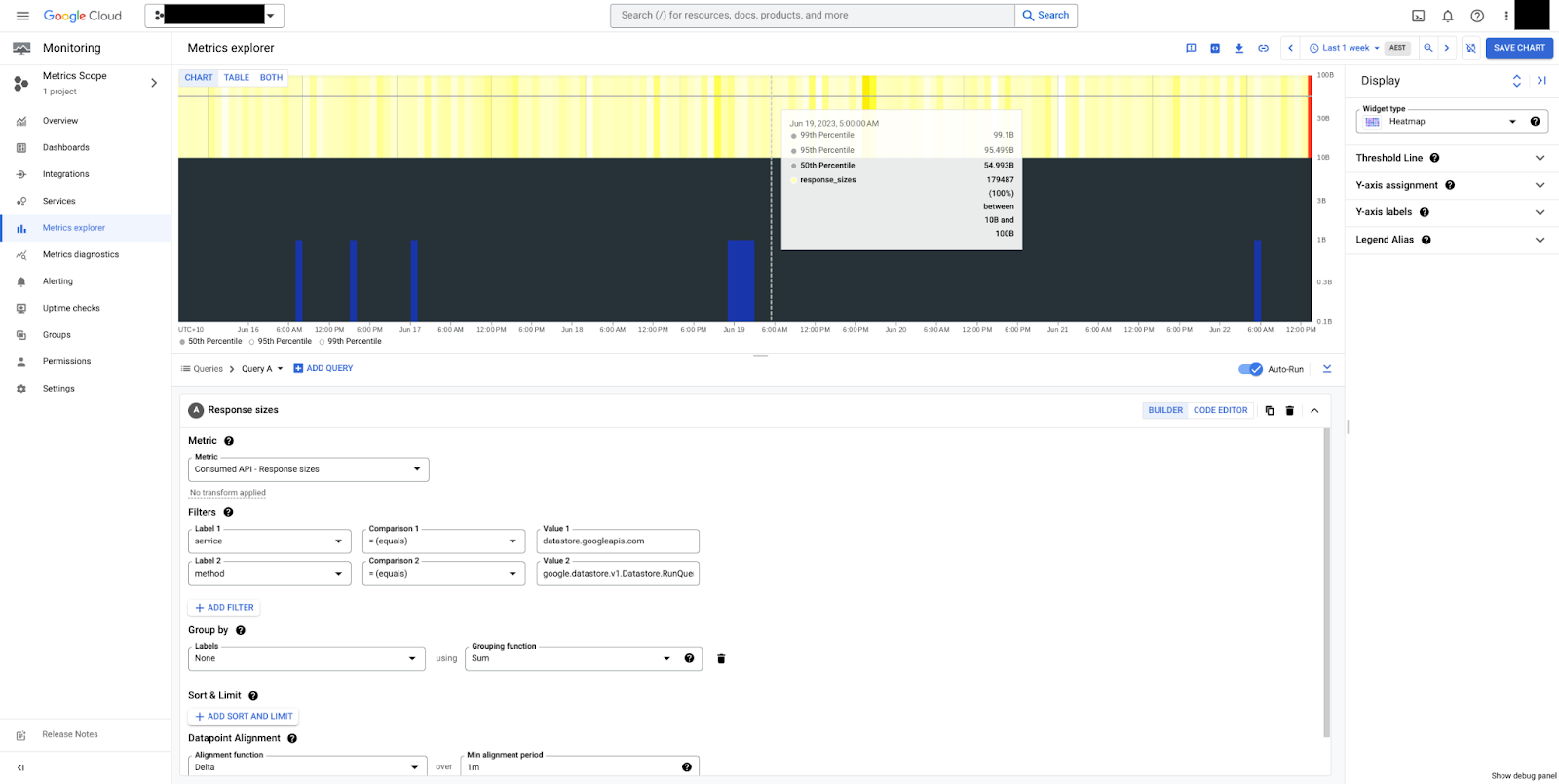
api/request_sizes et api/response_sizes
Les métriques api/request_sizes et api/response_sizes fournissent respectivement des insights sur les tailles de charge utile (en octets). Ils peuvent être utiles pour comprendre les charges de travail d'écriture qui envoient de grandes quantités de données ou des requêtes trop larges, et renvoient de grandes charges utiles.
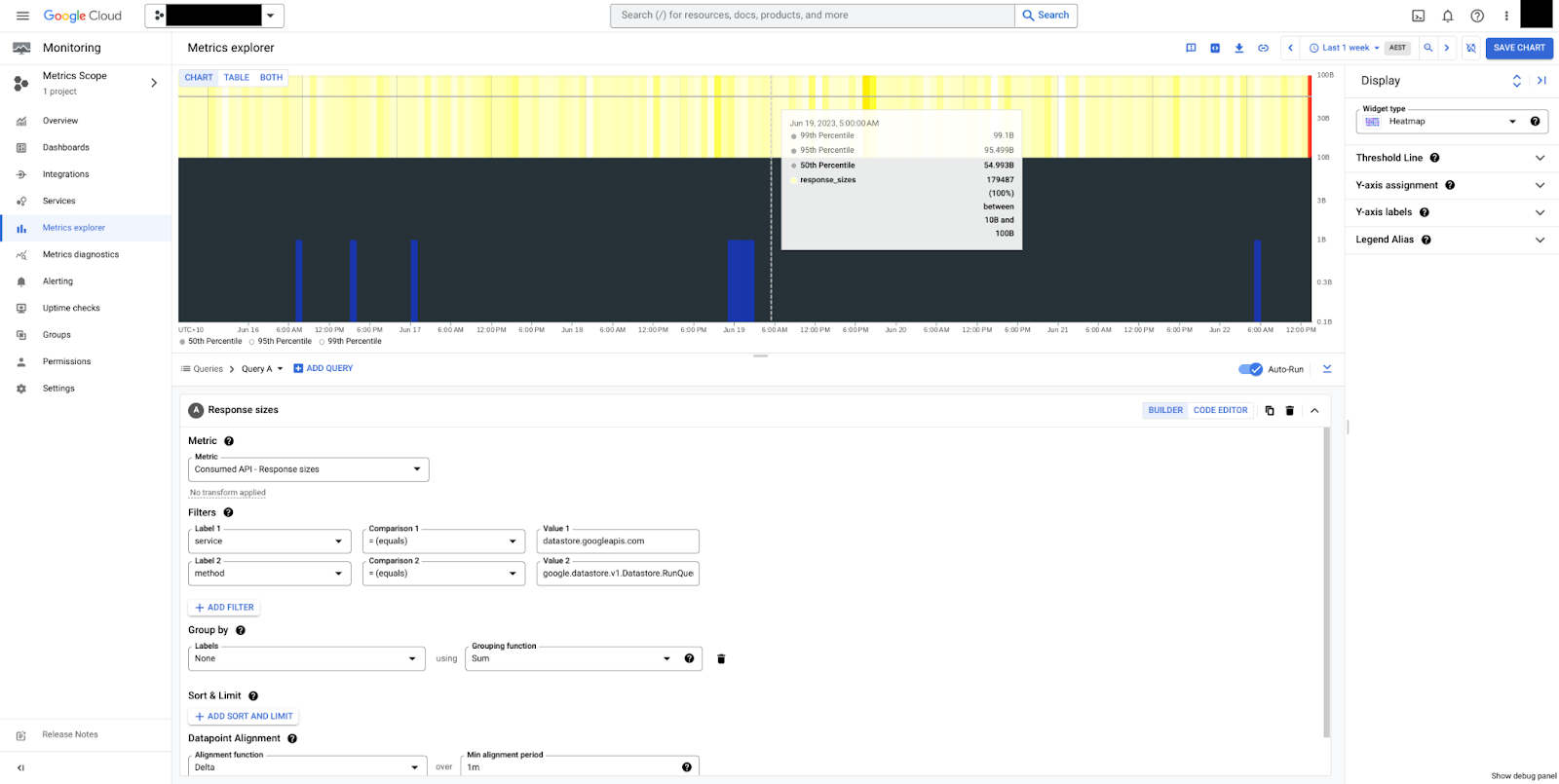
La figure 5 présente une carte de densité des tailles de réponse pour la méthode RunQuery.
Nous pouvons voir que les tailles sont stables, avec une médiane de 50 octets et une plage globale comprise entre 10 et 100 octets. Notez que les tailles de charge utile sont toujours mesurées en octets non compressés, sans frais généraux de contrôle de la transmission.
Métriques sur les opérations d'entité
Ces métriques fournissent des distributions en octets des tailles de la charge utile pour les lectures (recherches et requêtes) et les écritures dans une base de données Firestore. Les valeurs représentent la taille totale de la charge utile. Par exemple, les résultats renvoyés par une requête.
Ces métriques sont similaires aux métriques api/request_sizes et api/response_sizes, la principale différence étant que les métriques d'opération d'entité fournissent un échantillonnage plus précis, mais des répartitions moins précises.
Par exemple, les métriques d'opération d'entité utilisent la ressource surveillée datastore_request. Il n'y a donc pas de répartition du service ou de la méthode.
entity/read_sizes: répartition des tailles des entités lues, regroupées par type.entity/write_sizes: distribution des tailles des entités écrites, regroupées par opérations.
Métriques d'index
Vous pouvez comparer les taux d'écriture d'index à la métrique document/write_ops_count pour comprendre le ratio de fanout de l'index.
index/write_count: nombre d'écritures d'index.
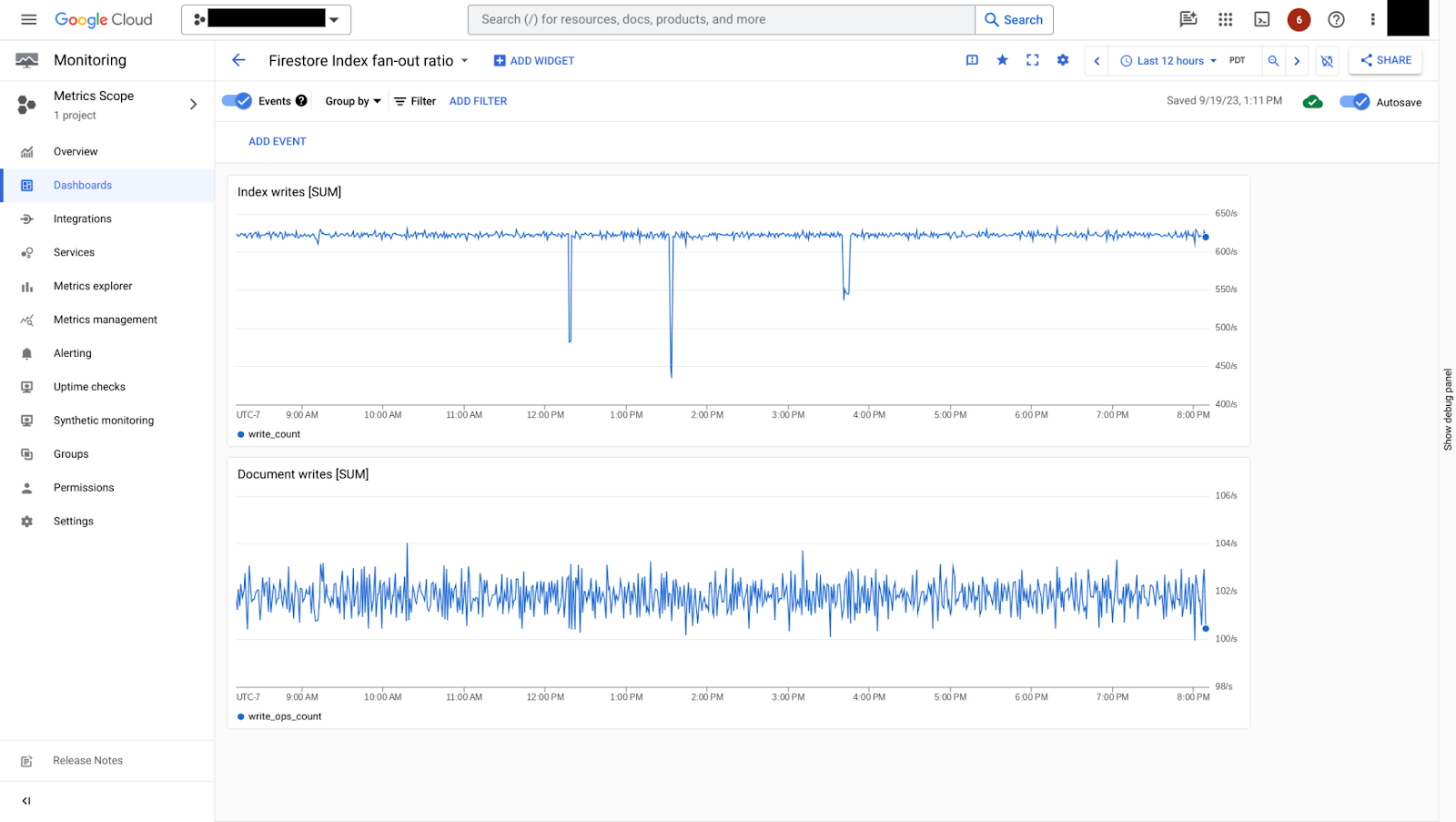
La figure 7 montre comment le débit d'écriture d'index peut être comparé au débit d'écriture de documents. Dans cet exemple, pour chaque écriture de document, il y a environ six écritures d'index, ce qui correspond à un taux de fanout d'index relativement faible.
Métriques TTL
Les métriques TTL sont disponibles à la fois pour les bases de données Firestore Native et Firestore en mode Datastore. Utilisez ces métriques pour surveiller l'impact de la stratégie de TTL appliquée.
entity/ttl_deletion_count: nombre total d'entités supprimées par les services TTL.entity/ttl_expiration_to_deletion_delays: temps écoulé entre l'expiration d'une entité avec un TTL et sa suppression effective.Si vous constatez que les délais de suppression du TTL prennent plus de 24 heures, contactez l'assistance.
Étape suivante
- Découvrez comment utiliser le tableau de bord Cloud Monitoring pour afficher des métriques.