Clasificación rápida y confiable en Datastore
La clasificación: un problema simple y muy complejo a la vez
Tomoaki Suzuki (Figura 1), un ingeniero líder de App Engine en Applibot, ha estado intentando resolver un problema muy común, pero muy difícil que enfrentan los servicios de videojuegos más grandes: la clasificación.

Applibot es uno de los mayores proveedores de aplicaciones sociales de Japón. Lo que hace única a esta empresa es su vasta experiencia y profundo conocimiento en la creación de servicios de videojuegos sociales súperescalables en Google App Engine, la plataforma como servicio (PaaS) que ofrece Google. Applibot aprovechó el poder de la plataforma y logró encontrar oportunidades de negocio en el mercado de los videojuegos sociales, no solo en Japón, sino también en los Estados Unidos. Ellos mismos pueden dar fe de su éxito. Legend of the Cryptids (Figura 2), uno de sus juegos más famosos, se posicionó número 1 en la categoría de videojuegos de la AppStore de Apple en Norte América en octubre de 2012. El juego tuvo 4.7 millones de descargas. Gang Road, otro de sus juegos, se posicionó en primer lugar en la clasificación de ventas totales en diciembre de 2012 en la AppStore de Japón.

Estos juegos pudieron escalar sin problemas y controlar el tráfico que aumentaba de manera exponencial Applibot no tuvo problemas para compilar clústeres complejos de servidores virtuales o bases de datos fragmentadas. Aprovecharon la potencia de App Engine y lograron tener escalabilidad y disponibilidad eficientes.
Sin embargo, la clasificación actualizada de los jugadores no es un problema simple de resolver para Tomoaki y otros desarrolladores, en especial a esta escala. Los requisitos son simples:
- Tu juego tiene cientos de miles (¡o más!) de jugadores.
- Cuando un jugador lucha contra sus enemigos (o hace otras actividades), su puntuación se modifica.
- Quieres que la clasificación del jugador esté actualizada en un portal web.
¿Cómo se calcula una clasificación?
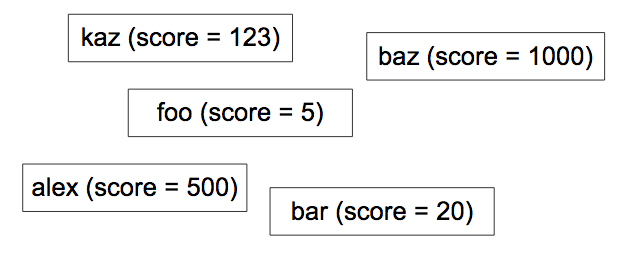
Obtener una clasificación es fácil, si no se pretende que también sea escalable y se haga rápido. Por ejemplo, puedes ejecutar la consulta siguiente:
SELECT count(key) FROM Players WHERE Score > YourScore
Esta consulta cuenta a todos los jugadores con una puntuación mayor que la tuya (Figura 4). ¿Pero quieres ejecutar esta consulta por cada solicitud del portal web? ¿Cuánto tiempo tomaría si hay un millón de jugadores?
Al comienzo, Tomoaki implementó este enfoque, pero tardaba unos segundos en obtener cada respuesta. Era muy lento, muy caro y el funcionamiento empeoraba a medida que la escala aumentaba.

Luego, Tomoaki intentó conservar los datos de clasificación en Memcache. Este método era rápido, pero poco confiable. Las entradas de Memcache podían ser expulsadas en cualquier momento y, a veces, el servicio de Memcache no estaba disponible. Era difícil mantener la coherencia y la disponibilidad con un servicio de clasificación que dependía únicamente de los valores claves que estaban en la memoria.
Como alternativa temporal, Tomoaki decidió reducir el nivel del servicio. En lugar de calcular la clasificación de cada solicitud, estableció una tarea programada que analizaba y actualizaba la clasificación de cada jugador cada una hora. De este modo, las solicitudes del portal web obtenían la clasificación del jugador instantáneamente, pero podían ser de hasta una hora de antigüedad.
Finalmente, Tomoaki buscaba una implementación de clasificación que fuera duradera, rápida, transaccional y escalable. También debía aceptar 300 solicitudes de actualización de puntuación por segundo y obtener una clasificación para cada jugador en cientos de milésimas de segundo. Para encontrar una solución, Tomoaki recurrió a Kaz Sato, un arquitecto de soluciones (SA) que, a su vez, era el administrador técnico de cuentas (TAM) del equipo de Google Cloud Platform asignado a Applibot a través de un contrato de asistencia nivel premium.
Una forma muy rápida de resolver problemas
Muchos de los clientes o socios más grandes de Google Cloud Platform, como Applibot, se suscriben a un contrato de asistencia de nivel premium. Con ese contrato, además de contar con asistencia las 24 horas del equipo de atención al cliente de Cloud y asistencia para empresas del equipo de ventas de Cloud, Google asigna un administrador técnico de cuentas (TAM) a cada cliente.
Un TAM representa al cliente ante el equipo de Ingeniería de Google, que crea la infraestructura de nube. Los TAM comprenden la arquitectura y el sistema del cliente en detalle, y una vez que plantean un caso crítico utilizan su conocimiento y funcionan como representantes del equipo de Ingeniería de Google dentro de la empresa para resolver el problema. Los TAM pueden derivar los problemas a los arquitectos de soluciones del equipo o a los ingenieros de software del equipo de Cloud Platform. La asistencia de nivel premium es la forma rápida de encontrar una solución con Google Cloud Platform.
Kaz, el TAM que asistía a Applibot, sabía que la clasificación era un problema clásico y difícil de resolver para cualquier servicio distribuido escalable. Comenzó a analizar las implementaciones conocidas para clasificaciones en Google Cloud Datastore y en otros almacenes de datos NoSQL a fin de encontrar una solución que cumpliera con los requisitos de Applibot.
Cómo buscar un algoritmo O(log n)
La solución más simple para la consulta requiere analizar a todos los jugadores con puntuaciones más altas a fin de calcular la clasificación de un jugador. El tiempo polinómico de este algoritmo es O(n); significa que el tiempo requerido para ejecutar una consulta aumenta de forma proporcional al número de jugadores. En la práctica, significa que el algoritmo no es escalable. En cambio, necesitamos un algoritmo O(log n) o uno más rápido con el que el tiempo solo aumente de forma logarítmica a medida que el número de jugadores crece.
Si alguna vez fuiste a una clase de computación debes recordar que los algoritmos de árbol, como los árboles binarios, los árboles rojo-negro o los árboles B- pueden funcionar en un tiempo polinómico O(log n) para encontrar un elemento. Los algoritmos de árbol también se pueden utilizar para calcular el valor agregado de un intervalo de elementos, como cuenta, máx./mín. y promedio, si se ponen los valores agregados en el nodo de cada rama. Si se usa esta técnica es posible implementar un algoritmo de clasificación con el rendimiento de O(log n).
Kaz encontró una implementación de código abierto de un algoritmo de clasificación tipo árbol para Datastore, escrito por un ingeniero de Google: la Biblioteca de clasificación de Google Code Jam.
Esta biblioteca basada en Python expone dos métodos:
SetScorepara fijar la puntuación de un jugador.FindRankpara obtener la clasificación de una puntuación determinada.
A medida que se crean y actualizan pares de puntuaciones de jugador con el método SetScore, la biblioteca de clasificación de Code Jam crea un árbol N-ario1. Por ejemplo, tomemos un árbol ternario que puede contar el número de jugadores con puntuaciones en el intervalo de 0 a 80 (Figura 5). La biblioteca almacena el nodo raíz, que contiene tres números como una entidad. Cada número corresponde al número de jugadores que tienen puntuación en los subintervalos 0 - 26, 27 - 53 y 54 - 80, respectivamente. El nodo raíz tiene un nodo secundario por cada intervalo, que, a su vez, contiene tres valores por cada jugador en los subintervalos del subintervalo. La jerarquía necesita cuatro niveles para almacenar el número de jugadores de 81 puntuaciones diferentes.

Para determinar la clasificación de un jugador cuya puntuación es de 30, la biblioteca solo necesita leer cuatro entidades (los nodos dentro de la línea punteada en el diagrama) para sumar el número de jugadores cuya puntuación es mayor a 30. Si hay 22 jugadores a la "derecha" en cuatro entidades, la clasificación del jugador es número 23.
Del mismo modo, si se llama a SetScore solo es necesario actualizar cuatro entidades. Incluso si el número de puntuaciones es mayor, el acceso de Datastore simplemente aumenta a O(log n) y no se ve afectado por el número de jugadores. En la práctica, la biblioteca de clasificación de Code Jam utiliza el 100 (en lugar del 3) como número predeterminado de valores por nodo, por lo que solo es necesario acceder a dos (o tres, si el intervalo de puntuaciones es mayor a 100,000) entidades.
Kaz utilizó la herramienta popular de prueba de carga Apache JMeter para hacer una prueba de carga a la biblioteca de clasificación de Code Jam y confirmó que la biblioteca responde rápido. SetScore y FindRank pueden completar su trabajo dentro de cientos de milisegundos mediante el uso de un algoritmo N-ario que funciona en el tiempo polinómico O(log n).
Las actualizaciones simultáneas limitan la escalabilidad
Sin embargo, cuando Kaz hizo la prueba de carga, encontró una limitación grave en la biblioteca de clasificación de Code Jam. Su escalabilidad en cuanto a la capacidad de procesamiento de las actualizaciones era algo baja. Cuando aumentó la carga a tres actualizaciones por segundo, la biblioteca comenzó a mostrar errores de reintento de la transacción. Era obvio que la biblioteca no podía cumplir con el requisito de Applibot de 300 actualizaciones por segundo. Solo podía controlar cerca del 1% de esa capacidad de procesamiento.
¿Por qué pasó eso? La razón es el costo de mantener la coherencia del árbol. En Datastore, es necesario usar un grupo de entidad para asegurar una coherencia sólida en la actualización de múltiples entidades en una transacción. Consulta la página sobre cómo balancear la coherencia sólida y la eventual con Google Cloud Datastore. La biblioteca de clasificación de Code Jam utiliza un solo grupo de entidad para contener el árbol entero y así asegurar la coherencia de las cuentas en los elementos de árbol.
Sin embargo, un grupo de entidad en Datastore tiene un límite de rendimiento. Datastore solo resiste una transacción por segundo en un grupo de entidad. Además, si el mismo grupo de entidad se modifica en transacciones simultáneas, es posible que fallen y haya que intentar de nuevo. La biblioteca de clasificación de Code Jam es muy coherente, transaccional y bastante rápida, pero no resiste un gran número de actualizaciones simultáneas.
Solución del equipo de Datastore: Agregación de trabajos
Kaz recordó que un ingeniero de software del equipo de Datastore había mencionado una técnica para obtener una capacidad de procesamiento mayor que una actualización por segundo en un grupo de entidad. Esto se lograba mediante el agregado de un lote de actualizaciones a una transacción en lugar de ejecutar cada actualización por separado en una transacción. Sin embargo, como la transacción incluye un gran número de actualizaciones cada una tarda más tiempo, y esto aumenta la posibilidad de conflictos de transacciones simultáneas.
Para responder a la solicitud de Kaz, el equipo de Datastore discutió el problema y recomendaron el uso de Agregación de trabajos, uno de los patrones de diseño utilizado con Megastore.
Megastore es la capa de almacenamiento subyacente de Datastore, controla la coherencia y transaccionalidad de los grupos de entidad. En esta capa se origina el límite de una actualización por segundo. Dado que varios servicios de Google utilizan Megastore ampliamente, los ingenieros habían estado recopilando y compartiendo recomendaciones y patrones de diseño dentro de la empresa para compilar un sistema escalable y coherente con este almacén de datos NoSQL.
La idea básica de Agregación de trabajos es usar un solo subproceso para procesar un lote de actualizaciones. Como hay solo una transacción y un subproceso abiertos en el grupo de entidad no hay fallas de transacción causadas por las actualizaciones simultáneas. Puedes encontrar ideas similares en otros productos de almacenamiento como VoltDb y Redis.
Sin embargo, el patrón de Agregación de trabajos tiene su desventaja: utiliza un solo subproceso para agregar todas las actualizaciones, esto limita la velocidad con la que envía las actualizaciones a Datastore. Por lo tanto, era importante definir si Agregación de trabajos podía cumplir con los requisitos de capacidad de procesamiento de Applibot de 300 actualizaciones por segundo.
Agregación de trabajos con listas de extracción
Kaz tomó el consejo del equipo de Datastore y escribió una prueba de concepto (PoC) que combina el patrón de Agregación de trabajos con la biblioteca de clasificación de Code Jam. La PoC tiene los siguientes componentes:
- Frontend: Acepta solicitudes
SetScorede los usuarios y las agrega como tareas a una lista de extracción. - Lista de extracción: recibe y contiene las
SetScoresolicitudes de actualización de frontend. - Backend: Ejecuta un bucle infinito con un solo subproceso que extrae las solicitudes de actualización y las ejecuta con la biblioteca de clasificación de Code Jam.
La PoC crea una lista de extracción, que es una especie de lista de tareas en cola en App Engine que permite a los desarrolladores implementar uno o múltiples trabajadores que realicen las tareas de la cola. La instancia de backend tiene un solo subproceso en un bucle infinito que extrae la mayor cantidad posible de tareas (hasta 1,000) de la cola. El subproceso pasa cada solicitud de actualización a la biblioteca de clasificación de Code Jam, que las ejecuta como un lote en una sola transacción. La transacción puede estar abierta por un segundo o más, pero dado que hay un solo subproceso conduciendo la biblioteca y Datastore, no hay contención ni un problema de modificación simultánea.
La instancia de backend se define como un módulo, una característica de App Engine que permite a los desarrolladores definir una instancia de aplicación con varias características. En esta PoC, la instancia de backend se define como una instancia manual de escalamiento. Solo se ejecuta una de estas instancias por vez.
Kaz usó JMeter para hacerle una prueba de carga a la PoC. Confirmó que la PoC podía realizar 200 solicitudes SetScore por segundo, con lotes de 500 a 600 actualizaciones por transacción. ¡Agregación de trabajos funciona!
Fragmentación de listas para un rendimiento estable
Pronto, Kaz encontró otro problema. Cuando ejecutó la prueba por varios minutos, notó que la capacidad de procesamiento de la lista de extracción fluctuaba en algunas ocasiones (Figura 6). En particular, cuando seguía agregando solicitudes a la cola con 200 tareas por segundo durante varios minutos. De repente, la cola dejaba de pasar tareas al backend y la latencia de cada tarea aumentaba de manera drástica.
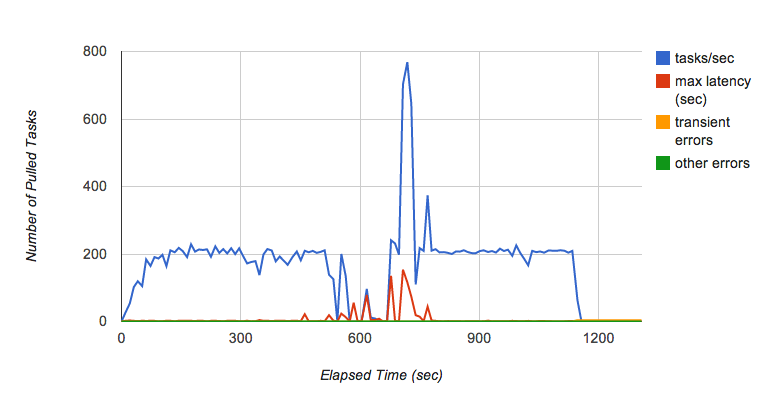
Kaz consultó al equipo de la Lista de tareas en cola para saber qué estaba ocurriendo. Según el equipo de Lista de tareas en cola, es un comportamiento conocido de la implementación actual de la lista de extracción que depende de Bigtable como su capa de persistencia. Cuando una tablet de Bigtable crece demasiado se divide en múltiples tablets. Durante el proceso de división de la tablet las tareas no se entregan y eso causa una fluctuación en el rendimiento cuando la cola recibe tareas con mucha frecuencia. El equipo de la Lista de tareas en cola está trabajando para mejorar estas características de rendimiento.
Michael Tang, un arquitecto de soluciones, recomendó usar Fragmentación de listas como alternativa. Propuso que en lugar de usar una sola lista se distribuya la carga en múltiples listas. Cada lista se puede almacenar en un servidor de tablet de Bigtable diferente para minimizar el efecto de división de una tablet y mantener una frecuencia de procesamiento alta. Mientras una lista está procesando una división, las otras siguen trabajando y la fragmentación disminuye la carga de cada lista, por lo que la fragmentación de tablets ocurre con menos frecuencia.
El bucle de la instancia de backend mejorado ejecuta el siguiente algoritmo:
- Asigna tareas
SetScorede 10 colas. - Llama al método
SetScorescon las tareas. - Borra las tareas asignadas de las listas.
En el paso 1, cada cola proporciona hasta 1,000 tareas, cada tarea contiene el nombre de un jugador y su puntuación. Luego de agregar todos los pares de puntuaciones de jugador a un diccionario, el paso 2 pasa el lote de actualizaciones al método SetScores de la biblioteca de clasificación de Code Jam, que abre una transacción para almacenarlas en Datastore. Si no hubo errores en la ejecución del método, el paso 3 borra las tareas asignadas de las listas.
Si hay un cierre inesperado del bucle o de la instancia de backend, las tareas de actualización permanecerán en las listas de tareas en cola para que sean procesadas cuando se reinicie la instancia. En un sistema de producción, puedes tener otro backend que funcione como controlador en modo de espera listo para actuar como reemplazo si la primera instancia falla.
La solución propuesta: ejecuta 300 actualizaciones por segundo de forma constante2
La Figura 7 muestra el resultado de la prueba de carga de la implementación final de la PoC con Fragmentación de listas. Minimiza el rendimiento de las fluctuaciones en las listas de forma efectiva y puede realizar 300 actualizaciones por segundo de forma constante durante varias horas. Con la carga usual, cada actualización se aplica a Datastore en unos segundos desde que se recibe la solicitud.
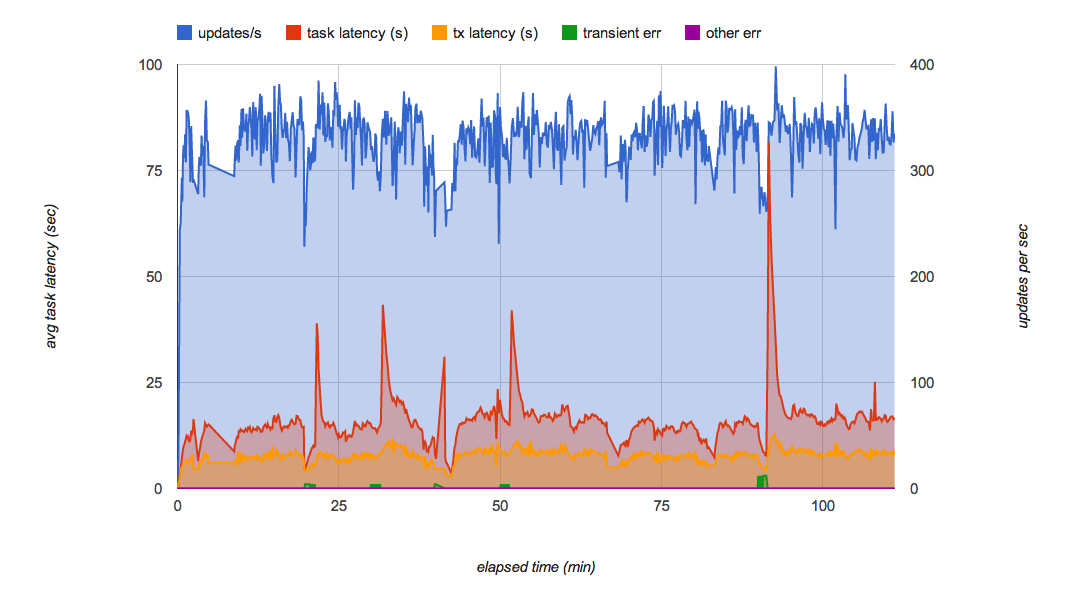
Esta solución cumple con todos los requisitos originales de Applibot:
- Es escalable para poder resistir a miles de jugadores.
- Es persistente y consistente, ya que todas las actualizaciones se ejecutan en transacciones de Datastore.
- Es lo suficientemente rápido para poder controlar 300 actualizaciones por segundo.
Con los resultados de la prueba de carga y el código de la PoC, Kaz presentó la solución a Tomoaki y otros ingenieros de Applibot. Tomoaki planea incorporar la solución en su sistema de producción, espera poder reducir la latencia de actualización de la información de clasificación de una hora a unos segundos, y espera mejorar la experiencia del usuario considerablemente.
Resumen del árbol de clasificaciones con Agregación de trabajos
La solución que se propuso tiene muchas ventajas y una desventaja:
Ventajas:
- Es rápida: Llamar a
FindRanktarda milésimas de segundo o menos. - Es rápida:
SetScoredespacha una tarea que el backend procesa en unos segundos. - Es muy coherente y persiste en Datastore.
- Las clasificaciones son precisas.
- Es escalable a cualquier cantidad de jugadores.
Desventaja:
- La capacidad de procesamiento es limitada (con la implementación actual realiza cerca de 300 actualizaciones por s)
Esta solución utiliza el patrón de Agregación de trabajos, por lo que depende de un subproceso para agregar todas las actualizaciones. Se necesita complejidad o trabajo adicionales para obtener una capacidad de procesamiento mayor a 300 actualizaciones por s con el poder de CPU de las instancias de App Engine y el rendimiento de Datastore.
Una solución más escalable con un árbol fragmentado
Si necesitas una frecuencia de actualización mayor tal vez debas fragmentar el árbol de clasificaciones. Se crearían múltiples implementaciones del sistema mencionado; un conjunto de listas que conducen un módulo backend que actualiza su propio árbol de clasificaciones.
Por lo general, no se requiere o se espera que los árboles estén coordinados. En el caso más simple, cada actualización SetScore se despacha a una lista de forma aleatoria. Con tres árboles de este tipo, cada uno con su propio servidor de backend y grupo de entidad de Datastore, la capacidad de procesamiento esperable de la actualización sería tres veces mayor. El término medio es que FindRank consulte a cada árbol de clasificaciones para obtener la clasificación de una puntuación y que sume la clasificación de cada árbol a fin de obtener la clasificación real, lo que tarda un poco más. El tiempo de consulta de FindRank se puede reducir en gran medida si se conservan las entidades en Memcache.
Es similar al enfoque conocido de usar contadores fragmentados: cada contador aumenta de forma independiente y la suma total solo se calcula si el cliente lo necesita.
Por ejemplo, con tres árboles, FindRank(865) puede encontrar las tres clasificaciones 124, 183 y 156 que indican que cada árbol contiene el número de puntuaciones respectivas mayores a 865. Entonces el cálculo total de las puntuaciones mayores a 865 es 124 + 183 + 156 = 463.
Este enfoque no funciona con todos los tipos de algoritmos distribuidos, pero dado que la clasificación es básicamente un problema de conteo debería funcionar para problemas de clasificación de cantidades grandes.
Soluciones más escalables con enfoques aproximados
Si tu aplicación necesita más escalabilidad que precisión en las clasificaciones y puede tolerar un cierto nivel de imprecisión o aproximación, podrías optar por un enfoque estocástico como:
- Depósitos con consulta global
- Método de conteo con pérdida
- Transmisión austera
Estos enfoques aproximados son todas variantes de una idea. ¿Cómo comprimes el almacenamiento de la información de clasificación concediendo un margen de degradación de la precisión de esta?
Los depósitos con consulta global son una solución alternativa que propuso el equipo de Datastore y Alex Amies, un TAM. Alex implementó una PoC basada en la idea del equipo de Datastore y realizó un extenso análisis del rendimiento. Demostró que esta es una solución de clasificación escalable con una degradación mínima en la precisión que puede ser adecuada para aplicaciones que requieran una capacidad de procesamiento mayor que la biblioteca de clasificación de Code Jam. Consulta el Apéndice para obtener una descripción detallada y resultados de pruebas.
Al método de conteo con pérdida y a la transmisión austera se los llaman algoritmos en línea y algoritmos de transmisión, ya que puedes usar una cantidad muy pequeña de almacenamiento en memoria para calcular una estimación estocástica de las puntuaciones más altas de un flujo de pares de puntuaciones de jugador. Estos algoritmos son adecuados para aplicaciones que requieran latencia muy baja y mucho ancho de banda, como miles de actualizaciones por segundo, con cobertura de los resultados de clasificación y precisión más limitadas. Por ejemplo, si quieres tener un panel que muestre las 100 palabras más usadas en una red social en tiempo real, estos algoritmos te serán de ayuda.
Conclusión
La clasificación es un problema clásico, pero difícil de resolver, si necesitas que el algoritmo sea escalable, consistente y rápido. En este artículo describimos en detalle como trabajaron los TAM de Google con el cliente y los equipos de ingeniería de Google para abordar un desafío y proporcionar una solución que pudiera reducir la latencia de las actualizaciones de la clasificación de una hora a unos segundos. Los patrones de diseño que se descubrieron en el proceso (Agregación de trabajos y Fragmentación de listas) también se pueden aplicar a problemas comunes de otros diseños de sistema basados en Datastore que requieren cientos de actualizaciones de coherencia sólida por segundo.
Notas
- La biblioteca de clasificación de Code Jam toma un parámetro llamado "factor de ramificación" que especifica cuántas puntuaciones contendrá cada entidad. Cada biblioteca utiliza el número 100 cómo parámetro de forma predeterminada. En este caso, las puntuaciones del 0 al 9,999 se almacenan en las entidades 100 como secundarias del nodo raíz. Si necesitas un intervalo de puntuaciones mayor puedes cambiar el factor de ramificación a un valor mayor para optimizar el número de accesos a la entidad.
- Las figuras de rendimiento descriptas en esta guía son valores de referencia y no garantizan un rendimiento absoluto de App Engine, Datastore ni de otros servicios.
Apéndice: Solución Depósitos con consulta global
Como se mencionó en la sección Cómo se calcula una clasificación, hacer una consulta a la base de datos por cada solicitud de clasificación es costoso. Este enfoque alternativo obtiene el recuento de todas las puntuaciones, calcula la clasificación de aquellas seleccionadas y proporciona esos datos para que se usen en clasificaciones informáticas de jugadores específicos de forma periódica. El rango total de puntuaciones se particiona en “bucket s”. Cada bucket se caracteriza por contar con un subrango de puntuaciones y la cantidad de jugadores con puntuaciones en ese rango. Con los datos, se puede obtener la clasificación de cualquier puntuación de forma aproximada. Estos bucket s son similares al nodo superior del árbol de clasificación, pero en lugar de descender a nodos más detallados, este algoritmo interpola dentro de un bucket.
La recuperación de clasificaciones por parte de los usuarios desde el frontend está separada del cálculo de las clasificaciones en depósitos del backend para minimizar el tiempo de búsqueda de una clasificación. Cuando se solicita la clasificación de un jugador, se busca el bucket correspondiente basándose en la puntuación del jugador. El bucket incluye un límite de clasificación superior y un conteo de jugadores dentro del bucket. La interpolación linear dentro de los depósitos se utiliza para estimar la clasificación de los jugadores dentro de los depósitos. En las pruebas, pudimos obtener la clasificación de un jugador en menos de 400 milésimas de segundo para un viaje de HTTP ida y vuelta completo. El costo del método FindRank no depende de la cantidad de jugadores en la población.
Cómo calcular la clasificación para una puntuación en particular
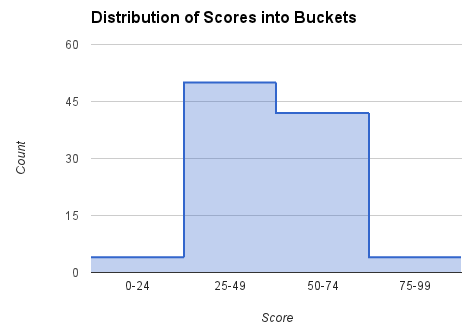
El conteo y la clasificación superior, es decir, la clasificación mayor dentro de este bucket, se registran en cada bucket. Con las puntuaciones debajo de los límites de puntuación baja y alta de un bucket utilizamos interpolación linear para calcular la clasificación. Por ejemplo, si la puntuación de un jugador es 60, miramos el depósito [50, 74] mediante el uso del recuento (cantidad de jugadores/puntuaciones en un depósito) (42) y la clasificación superior (5) para calcular la clasificación del jugador con esta fórmula:
rank = 5 + (74 - 60)*42/(74 - 50) = 30
Cómo calcular el conteo y el intervalo de cada bucket
Los conteos de cada bucket se calculan en segundo plano con un trabajo cron o una lista de tareas en cola y se guardan mediante una iteración de todos los bucket s. Lo llamamos consulta global, porque calcula los parámetros que se necesitan para estimar las clasificaciones a través de un análisis de las puntuaciones de todos los jugadores. A continuación, se ofrece un ejemplo de código de Python para realizar esta tarea con las puntuaciones en el intervalo [low_score, high_score] de cada depósito.
next_upper_rank = 1 for b in buckets: count = GetCountInRange(b.low_score, b.high_score) b.count = count b.upper_rank = next_upper_rank b.put() next_upper_rank += count
El método GetCountInRange() cuenta las puntuaciones de cada jugador en el intervalo que abarca el depósito. Gracias a que Datastore mantiene un índice ordenado de las puntuaciones de los jugadores, este conteo se puede calcular de forma eficiente.
Cuando necesitamos encontrar la clasificación de un jugador en particular, podemos usar código como se muestra a continuación.
b = GetBucketByScore(score) rank = RankInBucket(b, score) return rank + b.upper_rank - 1
El método GetBucketByScore(score) recupera el depósito que contiene la puntuación determinada. El método RankInBucket() estima las clasificaciones dentro del depósito. La clasificación del jugador es la suma de la clasificación superior del bucket y la clasificación del bucket específico que pone entre paréntesis la puntuación del jugador. Debemos extraer 1 del resultado porque la clasificación superior del bucket superior será 1 y la clasificación del mejor jugador dentro de un bucket específico también será 1.
Los depósitos se almacenan en Datastore y en Memcache. Para calcular la clasificación, lee los depósitos de Memcache (o de Datastore, si en Memcache falta información). En nuestra implementación de este algoritmo utilizamos la biblioteca cliente de Python NDB que utiliza Memcache para almacenar en caché los datos almacenados en Datastore.
Dado que los depósitos (o bien otros métodos) se utilizan para representar los datos de forma compacta, las clasificaciones que se obtienen no son exactas. Las clasificaciones de un bucket se aproximan con interpolación linear. Podrían utilizarse otros métodos más precisos para obtener una aproximación mejor dentro del bucket, como la fórmula de regresión.
Costo
El costo de encontrar una clasificación y actualizar la puntuación de un jugador son ambos O(1), es decir, que son independientes del número de jugadores.
El costo del trabajo de consulta global es O(Jugadores) * frecuencia de la actualización de la caché.
El costo de calcular los datos del bucket en el trabajo de backend también se relaciona con el número de bucket s, dado que se realiza una consulta de conteo por cada bucket. La consulta de conteo está optimizada para utilizar una consulta de solo clave, pero aun así se debe recuperar la lista de claves completa.
Ventajas
Este método es muy rápido, para actualizar la puntuación de un jugador y encontrar la clasificación de una puntuación. Aunque los resultados se basan en trabajos en segundo plano, si la puntuación de un jugador cambia, la clasificación mostrará un cambio en la dirección correspondiente de forma inmediata. Esto ocurre debido a la interpolación que se utiliza dentro del bucket.
Como el cálculo de la clasificación superior de un bucket se hace en segundo plano con un trabajo programado, las puntuaciones del jugador pueden actualizarse sin necesidad de conservar los datos sincronizados en un bucket. Así que este enfoque no limita la capacidad de procesamiento de actualizar las puntuaciones de los jugadores.
Desventajas
Debe considerarse el tiempo que toma contar las puntuaciones de todos los jugadores, calcular las clasificaciones globales y actualizar los depósitos. En nuestras pruebas, en una población de diez millones de jugadores, el tiempo de la prueba de sistema en App Engine fue de 8 minutos y 34 segundos. Es más rápido que las horas que tomaría calcular la clasificación de cada jugador, pero la compensación es la aproximación de puntuaciones dentro de cada bucket. En contraste, el algoritmo de árbol calcula los “intervalos de los depósitos” (el nodo superior del árbol) de forma progresiva cada unos segundos, pero la complejidad de implementación es mayor y la capacidad de procesamiento limitada.
En todos los casos, el tiempo de FindRank depende de la recuperación rápida de datos (nodos de árbol o depósito) desde Memcache. Si los datos son expulsados de Memcache deben volver a buscarse en Datastore y volver a almacenarse en caché para solicitudes FindRank posteriores.
Precisión
La precisión del método de bucket depende de la cantidad de bucket s que haya, la clasificación de cada jugador y la distribución de las puntuaciones. La Figura 9 muestra los resultados del estudio de precisión de los estimados de clasificación con distintos números de depósitos.

Se hicieron pruebas en una población de 10,000 jugadores con puntuaciones distribuidas de manera uniforme en el intervalo [0-9,999]. El error relativo es de alrededor del 1% incluso para solo 5 depósitos.
La precisión disminuye para los jugadores con mayor puntuación, principalmente porque la ley de los números grandes no aplica cuando se toman solo las mejores puntuaciones. En muchos casos, es recomendable utilizar un algoritmo más preciso para mantener las clasificaciones de los mil o dos mil mejores jugadores. El problema se reduce en gran medida, dado que hay que seguir a menos jugadores y en consecuencia la frecuencia de actualizaciones agregada es más baja.
En la prueba mencionada, el uso de números aleatorios distribuidos de manera uniforme, con una función de distribución acumulativa linear, favorece el uso de la interpolación linear dentro del bucket, pero la interpolación dentro de bucket s funciona bien para cualquier distribución de puntuaciones densa. La Figura 10 muestra una clasificación real y estimada para una distribución de puntuaciones aproximadamente normal.
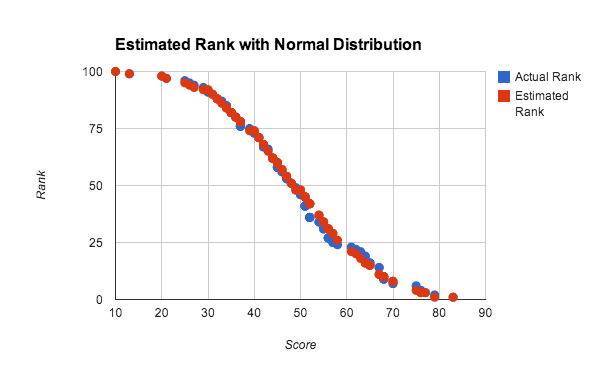
En este experimento, se usó una población de 100 jugadores para probar la precisión de un conjunto de datos pequeño. Cada puntuación se generó tomando el promedio de 4 números aleatorios entre 0 y 100, que se aproxima a una distribución de puntuaciones normal. Para calcular la clasificación estimada, se utilizó el método de consulta global con interpolación linear en 10 depósitos. Puede observarse que los resultados son muy buenos incluso para conjuntos de datos pequeños y distribuciones no uniformes.