
Managed Service for Apache Spark (舊稱 Dataproc)
革新 Spark 工作:更輕鬆、聰明、快速
在零營運負擔的無伺服器 Spark 環境或代管叢集執行 Apache Spark 工作負載。運用代理式 AI 工作流程加快開發速度,以 Lightning Engine 提升效能。
新客戶可獲得價值 $300 美元的免費抵免額,盡情體驗 Managed Service for Apache Spark 或其他 Google Cloud 產品。
Apache Spark 是 Apache Software Foundation 的商標。

功能
Lightning Engine 提供領先業界的效能
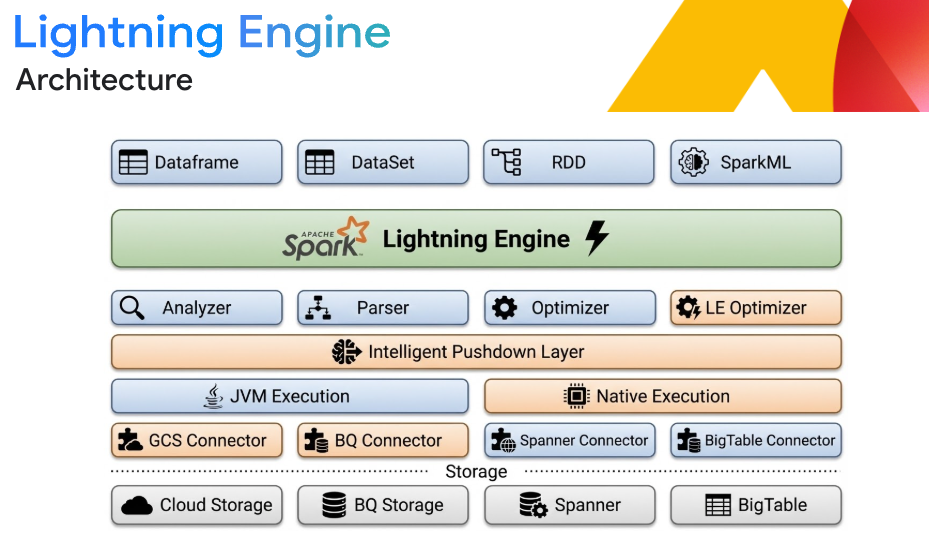
彈性的湖倉互通性
建構開放式湖倉架構,確保引擎獨立性。直接從 Google Cloud Storage 處理 Apache Iceberg 等開放格式的資料。與 BigQuery 和 Knowledge Catalog (舊稱 Dataplex) 完美整合,打造統一的分析與治理平台,確保多引擎互通性,不必使用轉譯層。
整合式 AI 輔助開發人員體驗
資料代理不僅能回答問題,還能採取行動,協助您處理待辦事項。您可以使用內建於 VSCode 代理式擴充功能的 Gemini,加快 Spark 工作負載從開發到正式環境的效率,也可以自由選擇喜好的 IDE。使用現成的 Data Cloud 代理,自動整理資料和處理 PySpark 程式設計作業,或使用 Data Agent Kit 直接從 IDE 管理資料集及執行查詢。透過 Gemini Cloud Assist,自動針對失敗的 Spark 工作解決問題。將 SQL 與 Spark 完美融合於單一整合式 AI 優先筆記本環境中。
全面支援企業級 AI/ML
建構整個機器學習生命週期並投入營運。透過 GPU 支援 (搭載 NVIDIA RAPIDS),以及為 PyTorch 和 XGBoost 預先設定的機器學習執行階段,加快模型訓練和推論速度。與 Google Cloud AI 生態系統整合,透過 Gemini Enterprise Agent Platform Model Registry 整合,自動化調度管理端對端 MLOps 並管理資產。
安全、可擴充且順暢的遷移作業
運用 IAM、VPC Service Controls 和 Kerberos,與安全防護機制完美整合,使用 Managed Service for Apache Spark 範本和工具,輕鬆遷移雲端和舊版 Spark 工作負載。支援 Spark 2.x 至 Spark 4.0,可以 lift-and-shift 工作負載,不必立即重構程式碼。
多租戶效率和 FinOps 控制項
充分運用資源並減少閒置成本。部署多租戶 Spark 叢集,讓最多 800 位使用者共用運算資源,同時維持嚴格的資料和環境隔離。透過將資源調度率降至零功能、按秒計費和 Spot VM 支援彈性工作負載,有效控管帳單。
具彈性的開放生態系統
不必受制於特定廠商。我們的代管叢集專為 Apache Spark 最佳化,但同時支援超過 30 種開放原始碼工具,例如 Apache Hadoop、Flink 和 Trino。可與 Managed Service for Apache Airflow 等自動調度管理工具完美整合,並透過 Kubernetes 和 Docker 擴充,提供最大的彈性。
部署方案
| 部署方案 | 您可以選擇精細控管的代管叢集,或是零營運負擔的無伺服器體驗,藉此找出最適合工作負載的方案。 | ||
|---|---|---|---|
| 部署模式: | 說明: | 適用情況: | 付費依據: |
無伺服器 | Spark 工作即服務。 Managed Spark、代管基礎架構。 | 適合用於新的管道、互動式分析,以及激增的工作負載,這類工作負載會優先考量零營運負擔和按工作計費的模式。 | 工作執行時間 |
叢集 | Spark 叢集即服務。 Managed Spark,基礎架構由您管理。 | 遷移舊版 Spark 或 OSS 工作負載、執行永久叢集,或是需要深度自訂開放原始碼。 | 叢集運作時間 |
部署方案
您可以選擇精細控管的代管叢集,或是零營運負擔的無伺服器體驗,藉此找出最適合工作負載的方案。
無伺服器
Spark 工作即服務。
Managed Spark、代管基礎架構。
適合用於新的管道、互動式分析,以及激增的工作負載,這類工作負載會優先考量零營運負擔和按工作計費的模式。
工作執行時間
叢集
Spark 叢集即服務。
Managed Spark,基礎架構由您管理。
遷移舊版 Spark 或 OSS 工作負載、執行永久叢集,或是需要深度自訂開放原始碼。
叢集運作時間
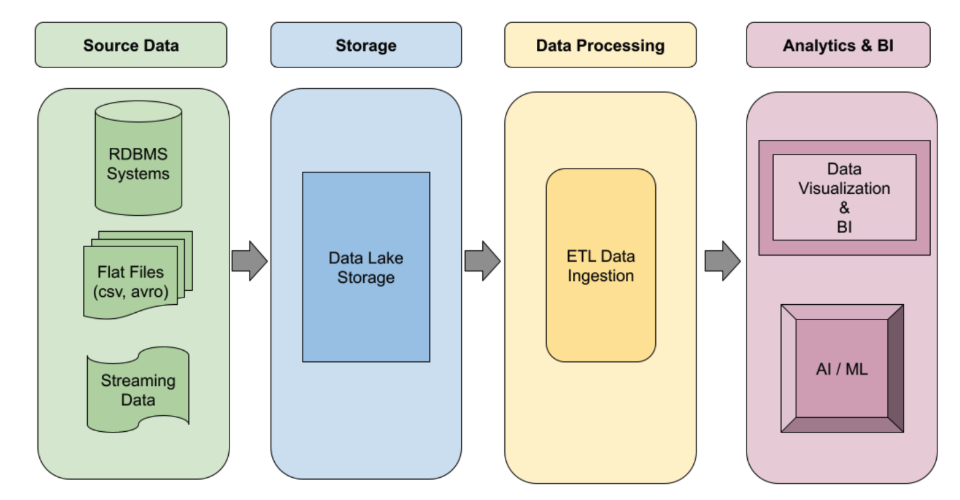
大規模資料工程
自動化 ETL 管道
自動化 ETL 管道
建構穩固的事件導向 Spark ETL 管道,可根據需求自動調整資源配置。您可以利用無伺服器執行環境處理尖峰工作負載,或使用代管叢集執行持續性工作。使用工作流程範本,自動化最重要的正式環境等級資料處理工作,從頭到尾一手包辦。


教學課程、快速入門導覽課程和研究室
自動化 ETL 管道
自動化 ETL 管道
建構穩固的事件導向 Spark ETL 管道,可根據需求自動調整資源配置。您可以利用無伺服器執行環境處理尖峰工作負載,或使用代管叢集執行持續性工作。使用工作流程範本,自動化最重要的正式環境等級資料處理工作,從頭到尾一手包辦。
資料科學與機器學習
互動式資料科學
互動式資料科學
協助資料科學家探索資料,並疊代 Spark 機器學習模型。透過 VSCode 代理式擴充功能或您選擇的 IDE,使用 Gemini 整合 SQL 和 Spark,透過無伺服器執行作業,順暢地從資料探索轉為使用 PySpark 建構模型。只要一個指令,就能連接 GPU。


教學課程、快速入門導覽課程和研究室
互動式資料科學
互動式資料科學
協助資料科學家探索資料,並疊代 Spark 機器學習模型。透過 VSCode 代理式擴充功能或您選擇的 IDE,使用 Gemini 整合 SQL 和 Spark,透過無伺服器執行作業,順暢地從資料探索轉為使用 PySpark 建構模型。只要一個指令,就能連接 GPU。
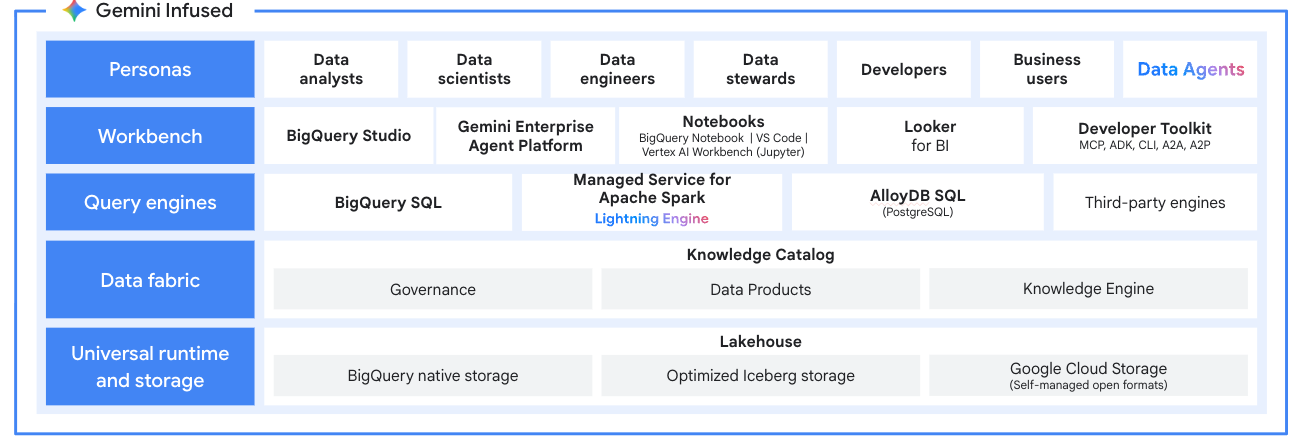
湖倉現代化
開放式資料湖倉
開放式資料湖倉
Managed Service for Apache Spark 是現代化資料湖倉的處理引擎。直接從資料湖泊處理 Apache Iceberg 等開放格式的資料,消除資料孤島。與 BigQuery 和 Lakehouse for Apache Iceberg 整合,打造統一的多引擎分析平台。

教學課程、快速入門導覽課程和研究室
開放式資料湖倉
開放式資料湖倉
Managed Service for Apache Spark 是現代化資料湖倉的處理引擎。直接從資料湖泊處理 Apache Iceberg 等開放格式的資料,消除資料孤島。與 BigQuery 和 Lakehouse for Apache Iceberg 整合,打造統一的多引擎分析平台。
定價
| Managed Service for Apache Spark 定價方式 | 價格取決於您選擇的部署模式。無伺服器是依據工作執行次數計費,叢集則是依據基礎運算資源和運作時間計費。 | |
|---|---|---|
| 部署模式: | 付費內容: | 付費內容: |
無伺服器 | 只需依實際用量付費。運算、GPU 和重組儲存空間皆以秒計費。將資源調度率降至零功能可確保您不會為閒置容量付費。 | 起始價 每個 DCU 小時 $0.06 美元 |
進階級與加速器: 使用 Lightning Engine 可將效能提升達 4.9 倍,或連接 NVIDIA GPU 來處理 AI/機器學習工作負載。 | 起始價 每個 DCU 小時 $0.089 美元 無伺服器進階級 | |
叢集 | 依據叢集運作時間付費。除了基礎 Compute Engine 資源的費用外,還需支付固定管理費。運用 Spot VM 和零規模功能,妥善控管成本。 | 起始價 每個 vCPU 小時 $0.01 美元 管理費 |
Lightning Engine 外掛程式: 為叢集帶來突破性效能,執行速度比開放原始碼 Spark 快 4.9 倍。 | 起始價 每個 vCPU 小時 $0.0025 美元 | |
進一步瞭解 Managed Service for Apache Spark 定價 查看所有定價詳細資料。
Managed Service for Apache Spark 定價方式
價格取決於您選擇的部署模式。無伺服器是依據工作執行次數計費,叢集則是依據基礎運算資源和運作時間計費。
無伺服器
只需依實際用量付費。運算、GPU 和重組儲存空間皆以秒計費。將資源調度率降至零功能可確保您不會為閒置容量付費。
Starting at
每個 DCU 小時 $0.06 美元
進階級與加速器:
使用 Lightning Engine 可將效能提升達 4.9 倍,或連接 NVIDIA GPU 來處理 AI/機器學習工作負載。
Starting at
每個 DCU 小時 $0.089 美元
無伺服器進階級
叢集
依據叢集運作時間付費。除了基礎 Compute Engine 資源的費用外,還需支付固定管理費。運用 Spot VM 和零規模功能,妥善控管成本。
Starting at
每個 vCPU 小時 $0.01 美元
管理費
Lightning Engine 外掛程式:
為叢集帶來突破性效能,執行速度比開放原始碼 Spark 快 4.9 倍。
Starting at
每個 vCPU 小時 $0.0025 美元
進一步瞭解 Managed Service for Apache Spark 定價 查看所有定價詳細資料。
企業案例
客戶成功案例

「我們發現,部分品質檢查作業從 11 小時縮短至幾分鐘。」
鄧白氏技術長 Michael Manos
遷移至 Google Cloud 後,鄧白氏集團大幅提升資料流程速度,將品質檢查流程從數小時縮短至數分鐘,新資料發布時間也縮短一半。有了穩固的資料基礎,鄧白氏就能充分發揮 Google Cloud 生態系統的強大功能,包括尖端的資料和 AI 技術。



Managed Service for Apache Spark 的獨特優勢
提供彈性部署選項,免去作業負擔,提升工作效率。您可以選擇無伺服器執行環境或全代管叢集,免除基礎架構手動作業和調整作業。
代理式 AI 開發。您可以在 VSCode 代理式擴充功能中使用內建的 Gemini,或在偏好的 IDE 中搭配資料代理,在統一的筆記本中自動執行 PySpark 程式設計、資料整理和工作疑難排解作業,加快工作流程。
效能領先業界,搭載 Lightning Engine。可將最嚴苛的 ETL 和資料科學工作負載提速高達 4.9 倍,大幅降低總持有成本










其他資源:
常見問題
Dataproc 和 Serverless Spark 發生了什麼事?
為簡化使用體驗,我們將 Dataproc 和 Google Cloud Serverless for Apache Spark 整合為單一產品:Managed Service for Apache Spark。您可以透過單一整合介面,選擇偏好的部署模式 (零營運負擔的無伺服器或全代管叢集),享有完全相同的強大功能。進一步詳細比較兩種部署模式。
選用無伺服器或代管叢集的時機?
如果想專注於程式碼,完全不必費心管理基礎架構,選擇無伺服器選項最為合適,特別適用於建立新管道與臨時分析需求。如果需要細微控管、遷移舊版或雲端 Spark 或其他 OSS 工作負載,或需要具備多種開放原始碼工具的永久叢集,代管叢集是理想選擇。
什麼是 Lightning Engine?
Lightning Engine 是 Google Cloud 的原生執行引擎,經過高度最佳化。這項服務採用 C++ 程式庫建構而成,可最佳化各層,包括高處理量儲存空間連接器和智慧型快取。效能比標準 Spark 高出 4.9 倍,性價比與領先的高速 Spark 替代方案高出 2 倍,而且能與無伺服器或叢集部署作業完美整合,完全不必變更程式碼。
我需要安裝自己的機器學習程式庫,例如 PyTorch 嗎?
否。如果您執行 AI/機器學習工作負載,可以使用預先設定的機器學習執行階段。這些環境內建 PyTorch、XGBoost 和 scikit-learn 等常見程式庫,並提供最佳化的 NVIDIA GPU 驅動程式,省去複雜的設定程序。
Managed Service for Apache Spark 是否完全相容於開放原始碼?
是,我們提供與開放原始碼完全相容的 Apache Spark 環境。您可以直接執行現有的 Spark 程式碼,無須修改,確保工作負載完全可攜性,避免受制於特定廠商。
Gemini AI 如何協助 Spark 開發?
Gemini AI 可直接整合至您偏好的 IDE,成為您的 AI 助理。有了這項服務,您可以更快編寫 PySpark 程式碼並偵錯,Gemini Cloud Assist 還能自動分析失敗工作的根本原因,並提供疑難排解建議。
我可以使用這項服務建構開放式資料湖倉嗎?
當然可以!Managed Service for Apache Spark 是 Google Cloud 開放式湖倉的核心處理引擎。您可以直接從 Cloud Storage 處理 Apache Iceberg 等開放格式的資料,並與 BigQuery 和 Knowledge Catalog for Apache Iceberg 完美整合。
標準版和進階版定價級別的運作方式
目前標準級和進階級方案僅適用於無伺服器部署作業。標準級適合用於符合成本效益的一般用途批次處理和 ETL。進階級專為最嚴苛的工作負載設計,可透過 Lightning Engine 將效能提升 4.9 倍 (相較於開放原始碼 Apache Spark),並提供 GPU 加速的 AI/機器學習功能。


















