本文档介绍如何在有权访问 Google 服务的机器或自管理的虚拟机上安装和使用 JupyterLab 扩展程序。此外,还介绍了如何开发和部署无服务器 Spark 笔记本代码。
在几分钟内安装此扩展程序,即可享受以下功能:
- 启动无服务器 Spark 和 BigQuery 笔记本,快速开发代码
- 在 JupyterLab 中浏览和预览 BigQuery 数据集
- 在 JupyterLab 中修改 Cloud Storage 文件
- 在 Composer 上安排笔记本
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc API.
-
Install the Google Cloud CLI.
-
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
-
如需初始化 gcloud CLI,请运行以下命令:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc API.
-
Install the Google Cloud CLI.
-
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
-
如需初始化 gcloud CLI,请运行以下命令:
gcloud init 从
python.org/downloads下载并安装 Python 3.11 版或更高版本。- 验证 Python 3.11 及更高版本的安装情况。
python3 --version
- 验证 Python 3.11 及更高版本的安装情况。
虚拟化 Python 环境。
pip3 install pipenv
- 创建安装文件夹。
mkdir jupyter
- 切换到安装文件夹。
cd jupyter
- 创建虚拟环境。
pipenv shell
- 创建安装文件夹。
在虚拟环境中安装 JupyterLab。
pipenv install jupyterlab
安装 JupyterLab 扩展程序。
pipenv install bigquery-jupyter-plugin
jupyter lab
JupyterLab 启动器页面会在浏览器中打开。它包含 Dataproc 作业和会话部分。如果您有权访问 Dataproc 无服务器笔记本或项目中运行了 Jupyter 可选组件的 Dataproc 集群,该标签页还可能包含 Serverless for Apache Spark Notebooks 和 Dataproc Cluster Notebooks 部分。
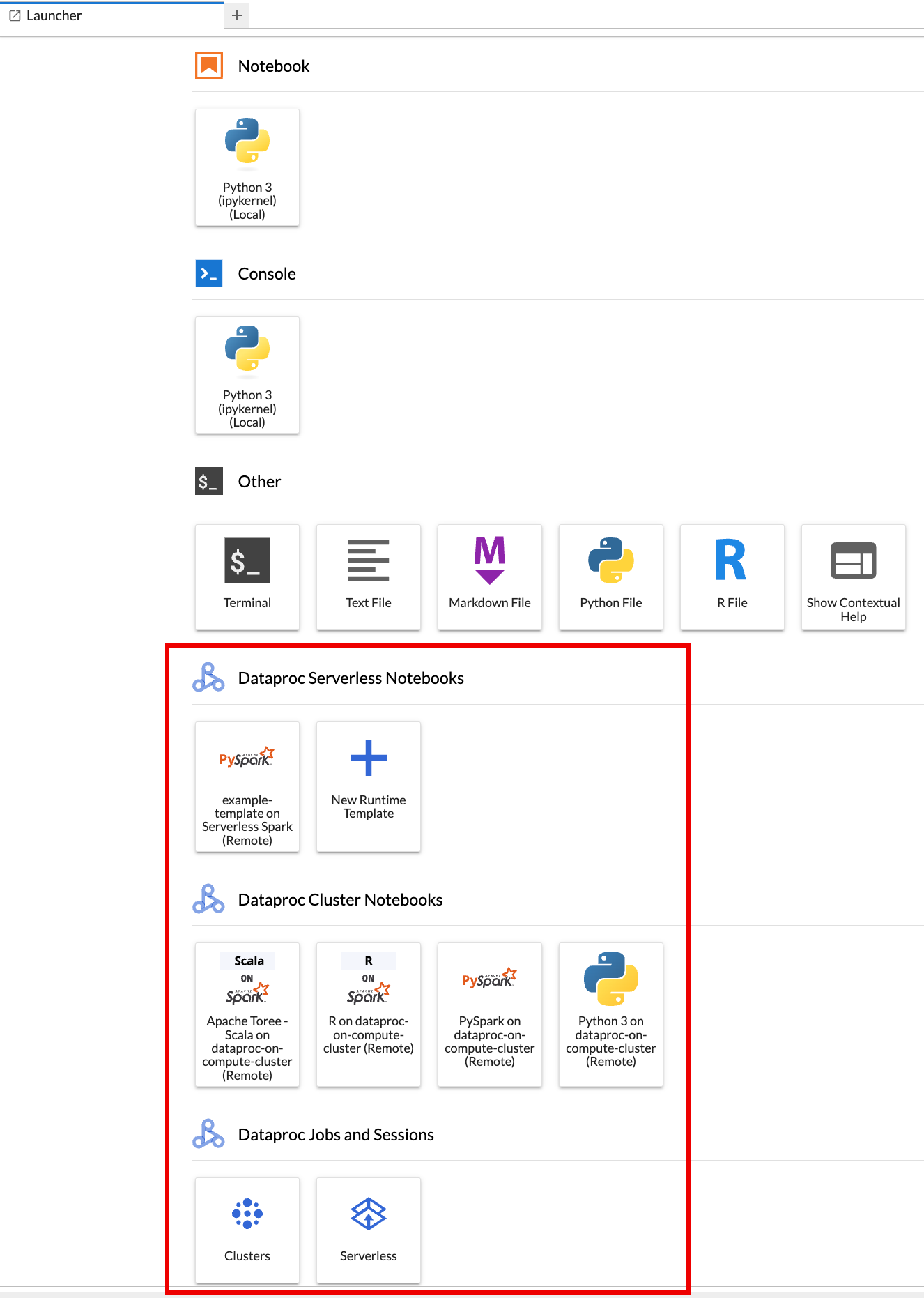
默认情况下,您的 Serverless for Apache Spark 交互式会话会在您运行
gcloud init时在准备工作中设置的项目和区域中运行。您可以在 JupyterLab 中依次前往设置 > Google Cloud 设置 > Google Cloud 项目设置,更改会话的项目和区域设置。您必须重启扩展程序,所做的更改才会生效。
在 JupyterLab 启动器页面上的 Serverless for Apache Spark Notebooks 部分中,点击
New runtime template卡片。
填写运行时模板表单。
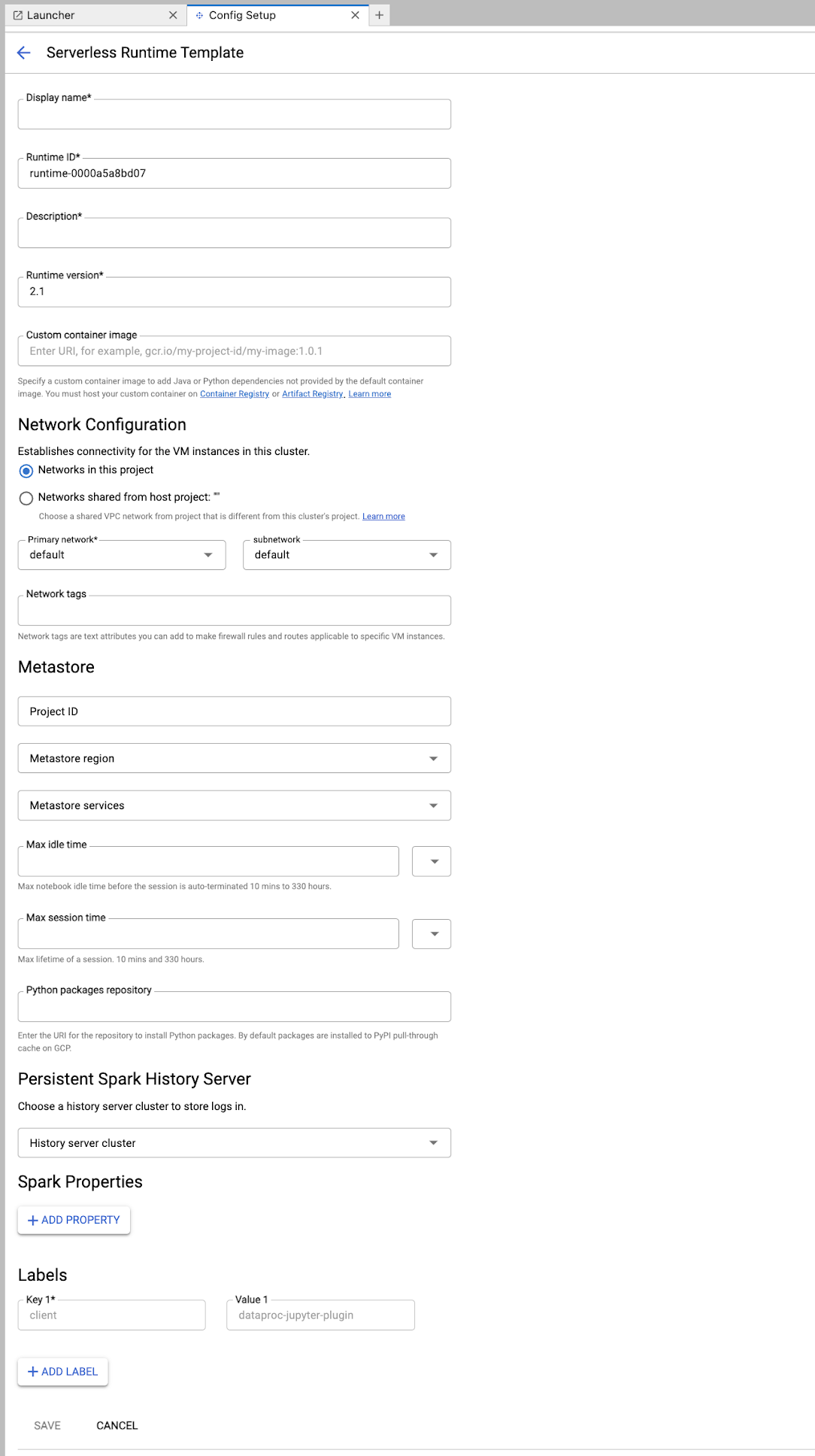
模板信息:
- 显示名、运行时 ID 和说明:接受或填写模板显示名、模板运行时 ID 和模板说明。
执行配置:选择用户账号,以使用用户身份(而非 Dataproc 服务账号身份)执行笔记本。
- 服务账号:如果您未指定服务账号,则系统会使用 Compute Engine 默认服务账号。
- 运行时版本:确认或选择运行时版本。
- 自定义容器映像:您可以选择指定自定义容器映像的 URI。
- 暂存存储桶:您可以选择性地指定一个 Cloud Storage 暂存存储桶的名称,供 Serverless for Apache Spark 使用。
- Python 软件包仓库:默认情况下,当用户在笔记本中执行
pip安装命令时,系统会从 PyPI 拉取缓存下载并安装 Python 软件包。您可以指定组织的私有 Python 软件包制品代码库,以用作默认的 Python 软件包代码库。
加密:接受默认的 Google-owned and Google-managed encryption key,或选择客户管理的加密密钥 (CMEK)。 如果是 CMEK,请选择或提供密钥信息。
网络配置:选择项目中的子网或从宿主项目共享的子网(您可以从 JupyterLab Settings > Google Cloud Settings > Google Cloud Project Settings 中更改项目)。您可以指定要应用于指定网络的网络标记。请注意,Serverless for Apache Spark 会在指定的子网中启用专用 Google 访问通道 (PGA)。如需了解网络连接要求,请参阅 Google Cloud Serverless for Apache Spark 网络配置。
会话配置:您可以选择填写这些字段,以限制使用相应模板创建的会话的持续时间。
- 最长空闲时间:会话终止前的最长空闲时间。允许的范围:10 分钟到 336 小时(14 天)。
- 会话时长上限:会话在终止之前的最长生命周期。允许的范围:10 分钟到 336 小时(14 天)。
Metastore:如需在会话中使用 Dataproc Metastore 服务,请选择 Metastore 项目 ID 和服务。
Persistent History Server:您可以选择可用的永久性 Spark 历史记录服务器,以便在会话期间和会话结束后访问会话日志。
Spark 属性:您可以选择并添加 Spark 资源分配、自动扩缩或 GPU 属性。点击 Add Property 以添加其他 Spark 属性。如需了解详情,请参阅 Spark 属性。
标签:针对要为使用相应模板创建的会话设置的每个标签,点击添加标签。
点击保存以创建模板。
查看或删除运行时模板。
- 依次点击设置 > Google Cloud 设置。
Dataproc 设置 > 无服务器运行时模板部分会显示运行时模板列表。
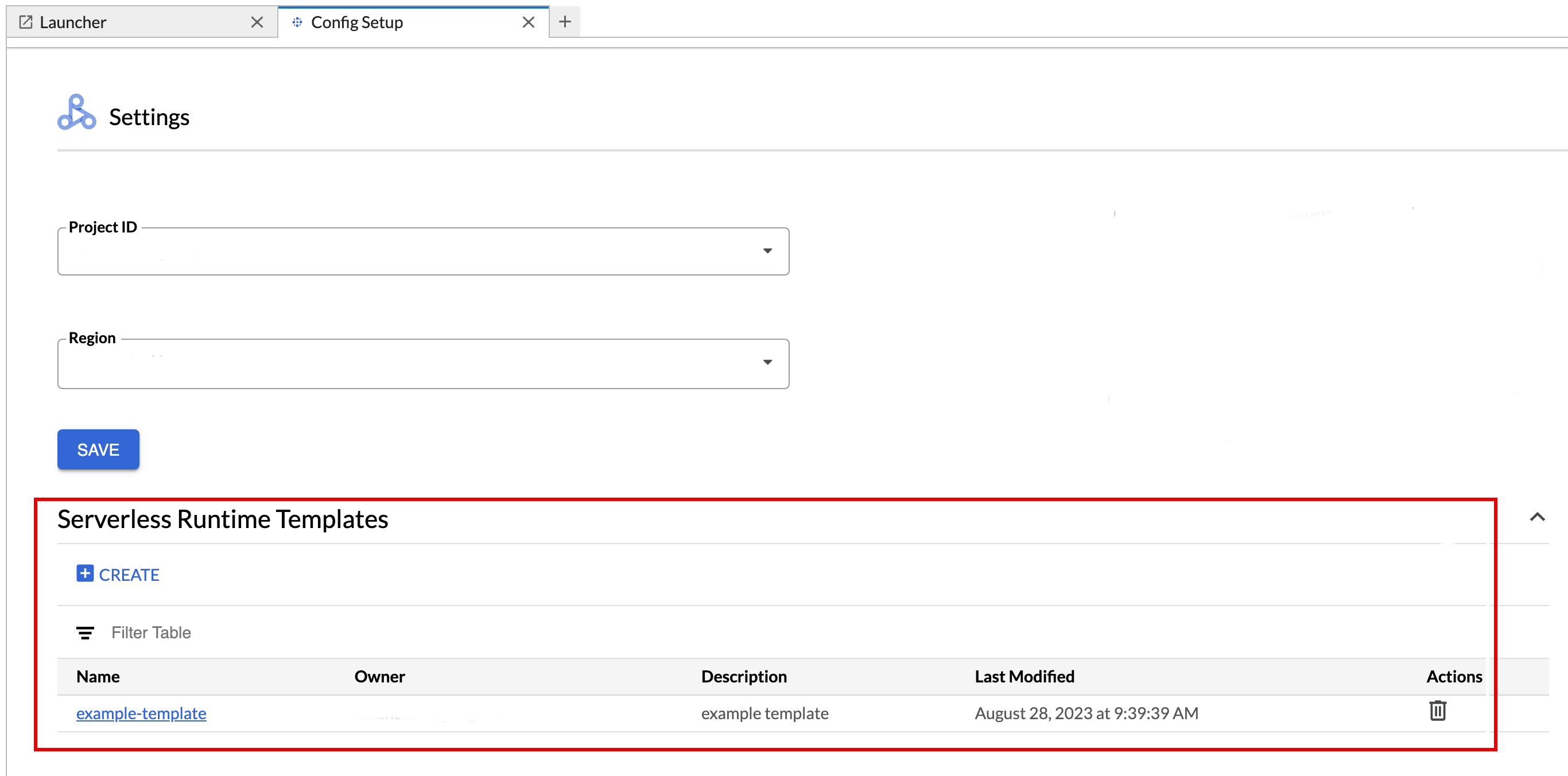
- 点击模板名称可查看模板详细信息。
- 您可以通过模板的操作菜单删除模板。
打开并重新加载 JupyterLab 启动器页面,以在 JupyterLab 启动器页面上查看已保存的笔记本模板卡片。

创建包含运行时模板配置的 YAML 文件。
简单 YAML
environmentConfig: executionConfig: networkUri: default jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing description: Team A Development Environment
复杂的 YAML
description: Example session template environmentConfig: executionConfig: serviceAccount: sa1 # Choose either networkUri or subnetworkUri networkUri: subnetworkUri: default networkTags: - tag1 kmsKey: key1 idleTtl: 3600s ttl: 14400s stagingBucket: staging-bucket peripheralsConfig: metastoreService: projects/my-project-id/locations/us-central1/services/my-metastore-id sparkHistoryServerConfig: dataprocCluster: projects/my-project-id/regions/us-central1/clusters/my-cluster-id jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing runtimeConfig: version: "2.3" containerImage: gcr.io/my-project-id/my-image:1.0.1 properties: "p1": "v1" description: Team A Development Environment
通过在本地或 Cloud Shell 中运行以下 gcloud beta dataproc session-templates import 命令,从 YAML 文件创建会话(运行时)模板:
gcloud beta dataproc session-templates import TEMPLATE_ID \ --source=YAML_FILE \ --project=PROJECT_ID \ --location=REGION
- 如需查看用于描述、列出、导出和删除会话模板的命令,请参阅 gcloud beta dataproc session-templates。
点击卡片以创建 Serverless for Apache Spark 会话并启动笔记本。当会话创建完成且笔记本内核准备就绪时,内核状态会从
Starting变为Idle (Ready)。编写和测试笔记本代码。
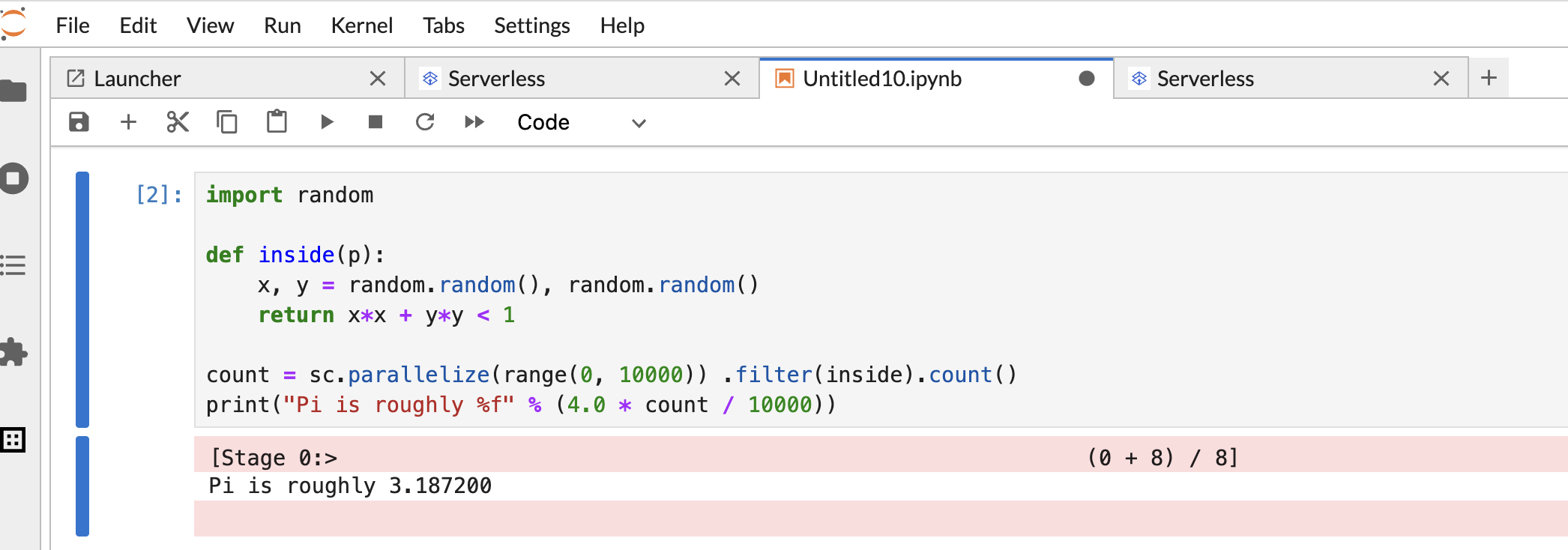
将以下 PySpark
Pi estimation代码复制并粘贴到 PySpark 笔记本单元中,然后按 Shift+Return 运行该代码。import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, 10000)) .filter(inside).count() print("Pi is roughly %f" % (4.0 * count / 10000))
笔记本结果:
创建并使用笔记本后,您可以点击内核标签页中的关闭内核来终止笔记本会话。
- 如需重复使用会话,请从文件>>新建菜单中选择笔记本,以创建新笔记本。创建新笔记本后,从内核选择对话框中选择现有会话。新笔记本将重复使用会话,并保留之前笔记本中的会话上下文。
如果您不终止会话,Dataproc 会在会话空闲计时器到期时终止会话。您可以在运行时模板配置中配置会话空闲时间。默认会话空闲时间为 1 小时。
点击 Dataproc 集群笔记本部分中的卡片。
当内核状态从
Starting变为Idle (Ready)时,您就可以开始编写和执行笔记本代码了。创建并使用笔记本后,您可以点击内核标签页中的关闭内核来终止笔记本会话。
如需访问 Cloud Storage 浏览器,请点击 JupyterLab 启动器页面边栏中的 Cloud Storage 浏览器图标,然后双击某个文件夹以查看其内容。
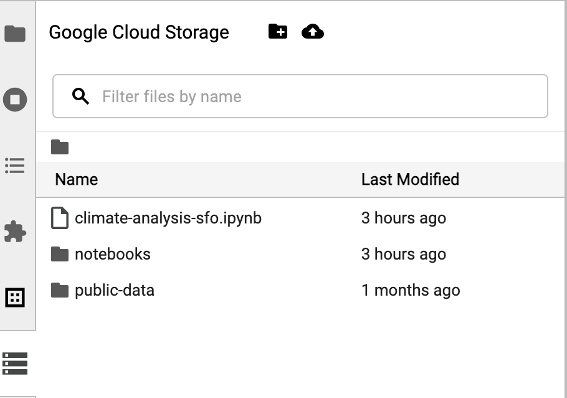
您可以点击 Jupyter 支持的文件类型,以打开并修改相应文件。当您保存对文件的更改时,这些更改会写入 Cloud Storage。
如需创建新的 Cloud Storage 文件夹,请点击“新建文件夹”图标,然后输入文件夹的名称。
如需将文件上传到 Cloud Storage 存储桶或文件夹,请点击上传图标,然后选择要上传的文件。
在 JupyterLab 启动器页面上,点击 Serverless for Apache Spark 笔记本或 Dataproc 集群笔记本部分中的 PySpark 卡片,以打开 PySpark 笔记本。
在 JupyterLab 启动器页面上的 Dataproc 集群笔记本部分中,点击 Python 内核卡片以打开 Python 笔记本。
在 JupyterLab 启动器页面上的 Dataproc 集群笔记本部分中,点击 Apache Toree 卡片,打开一个用于 Scala 代码开发的笔记本。

图 1. JupyterLab 启动器页面中的 Apache Toree 内核卡片。 - 在 Serverless for Apache Spark 笔记本中开发和运行 Spark 代码。
- 创建和管理 Serverless for Apache Spark 运行时(会话)模板、交互式会话和批量工作负载。
- 开发和执行 BigQuery 笔记本。
- 浏览、检查和预览 BigQuery 数据集。
- 下载并安装 VS Code。
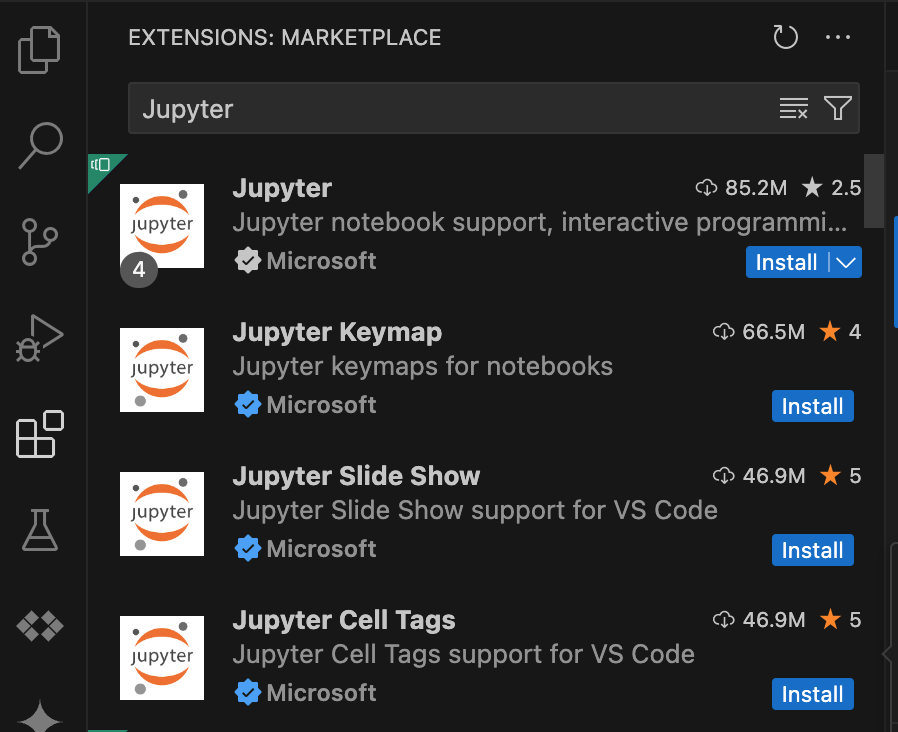
- 打开 VS Code,然后在活动栏中点击扩展程序。
使用搜索栏找到 Jupyter 扩展程序,然后点击安装。Microsoft 的 Jupyter 扩展程序是必需的依赖项。
- 打开 VS Code,然后在活动栏中点击扩展程序。
使用搜索栏找到 Google Cloud Code 扩展程序,然后点击安装。

如果出现提示,请重启 VS Code。
- 打开 VS Code,然后在活动栏中点击 Google Cloud Code。
- 打开 Dataproc 部分。
- 点击登录 Google Cloud。系统会将您重定向到登录页面,您可在此处输入自己的凭据。
- 使用顶层应用任务栏,依次前往代码 > 设置 > 设置 > 扩展程序。
- 找到Google Cloud 代码,然后点击管理图标以打开菜单。
- 选择设置。
- 在项目和 Dataproc 区域字段中,输入要用于开发笔记本和管理 Serverless for Apache Spark 资源的 Google Cloud 项目和区域的名称。
- 打开 VS Code,然后在活动栏中点击 Google Cloud Code。
- 打开笔记本部分,然后点击新建 Serverless Spark 笔记本。
- 选择或创建一个新的运行时(会话)模板,以用于笔记本会话。
系统会创建一个包含示例代码的新
.ipynb文件,并在编辑器中打开该文件。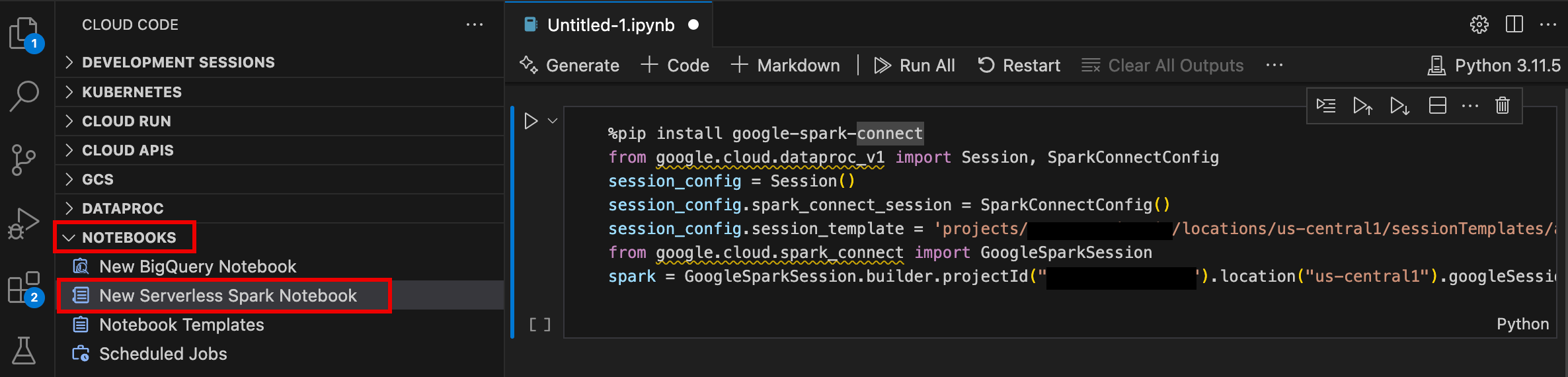
现在,您可以在 Serverless for Apache Spark 笔记本中编写和执行代码。
- 打开 VS Code,然后在活动栏中点击 Google Cloud Code。
打开 Dataproc 部分,然后点击以下资源名称:
- 集群:创建和管理集群及作业。
- 无服务器:创建和管理批处理工作负载和交互式会话。
- Spark 运行时模板:创建和管理会话模板。

在 Google Cloud Serverless for Apache Spark 基础设施上执行笔记本代码
在 Cloud Composer 上安排笔记本执行
将批处理作业提交到 Google Cloud Serverless for Apache Spark 基础架构或 Dataproc on Compute Engine 集群。
点击笔记本右上角的 Job Scheduler 按钮。
填写创建预定作业表单,以提供以下信息:
- 笔记本执行作业的唯一名称
- 用于部署笔记本的 Cloud Composer 环境
- 笔记本是否已参数化时的输入参数
- 用于运行笔记本的 Dataproc 集群或无服务器运行时模板
- 如果选择了集群,是否在笔记本在集群上完成执行后停止集群
- 如果笔记本执行在第一次尝试时失败,则重试次数和重试延迟时间(以分钟为单位)
- 要发送的执行通知以及收件人列表。 通知通过 Airflow SMTP 配置发送。
- 笔记本执行时间表
点击创建。
成功安排笔记本后,作业名称会显示在 Cloud Composer 环境的预定作业列表中。

在 JupyterLab 启动器页面上的 Dataproc 作业和会话部分中,点击无服务器卡片。
点击批次标签页,然后点击创建批次并填写批次信息字段。
点击提交以提交作业。
在 JupyterLab 启动器页面上的 Dataproc 作业和会话部分中,点击集群卡片。
点击作业标签页,然后点击提交作业。
选择一个集群,然后填写作业字段。
点击提交以提交作业。
- 点击无服务器卡片。
- 点击会话标签页,然后点击某个会话 ID 以打开会话详情页面,您可以在该页面中查看会话属性、在 Logs Explorer 中查看 Google Cloud 日志,以及终止会话。 注意:系统会创建一个唯一的 Google Cloud Serverless for Apache Spark 会话来启动每个 Google Cloud Serverless for Apache Spark 笔记本。
- 点击批处理标签页,查看当前项目和区域中的 Google Cloud Serverless for Apache Spark 批处理列表。点击批次 ID 可查看批次详情。
- 点击集群卡片。选择集群标签页,以列出当前项目和区域中的有效 Dataproc on Compute Engine 集群。您可以点击操作列中的图标来启动、停止或重启集群。点击集群名称可查看集群详细信息。您可以点击操作列中的图标来克隆、停止或删除作业。
- 点击作业卡片,查看当前项目中的作业列表。点击作业 ID 即可查看作业详情。
安装 JupyterLab 扩展程序
您可以在有权访问 Google 服务的机器或虚拟机上安装和使用 JupyterLab 扩展程序,例如本地机器或 Compute Engine 虚拟机实例。
如需安装该扩展程序,请按以下步骤操作:
创建 Serverless for Apache Spark 运行时模板
Serverless for Apache Spark 运行时模板(也称为会话模板)包含用于在会话中执行 Spark 代码的配置设置。您可以使用 JupyterLab 或 gcloud CLI 创建和管理运行时模板。
JupyterLab
gcloud
启动和管理笔记本
安装 Dataproc JupyterLab 扩展程序后,您可以点击 JupyterLab 启动器页面上的模板卡片,以执行以下操作:
在 Serverless for Apache Spark 上启动 Jupyter 笔记本
JupyterLab 启动器页面上的 Serverless for Apache Spark Notebooks 部分会显示与 Serverless for Apache Spark 运行时模板对应的笔记本模板卡片(请参阅创建 Serverless for Apache Spark 运行时模板)。

在 Dataproc on Compute Engine 集群上启动笔记本
如果您创建了 Dataproc on Compute Engine Jupyter 集群,则 JupyterLab 启动器页面会包含一个 Dataproc Cluster Notebook 部分,其中包含预安装的内核卡片。
如需在 Dataproc on Compute Engine 集群上启动 Jupyter 笔记本,请执行以下操作:
在 Cloud Storage 中管理输入和输出文件
分析探索性数据和构建机器学习模型通常涉及基于文件的输入和输出。Serverless for Apache Spark 会访问 Cloud Storage 中的这些文件。
开发 Spark 笔记本代码
安装 Dataproc JupyterLab 扩展程序后,您可以从 JupyterLab 启动器页面启动 Jupyter 笔记本,以开发应用代码。
PySpark 和 Python 代码开发
Serverless for Apache Spark 和 Dataproc on Compute Engine 集群支持 PySpark 内核。Compute Engine 上的 Dataproc 还支持 Python 内核。
SQL 代码开发
如需打开 PySpark 笔记本以编写和执行 SQL 代码,请在 JupyterLab 启动器页面上的 Serverless for Apache Spark 笔记本或 Dataproc 集群笔记本部分中,点击 PySpark 内核卡片。
Spark SQL magic:由于启动无服务器版 Apache Spark Notebook 的 PySpark 内核预加载了 Spark SQL magic,因此您无需使用 spark.sql('SQL STATEMENT').show() 来封装 SQL 语句,只需在单元格顶部输入 %%sparksql magic,然后在单元格中输入 SQL 语句即可。
BigQuery SQL:借助 BigQuery Spark 连接器,您的笔记本代码可以从 BigQuery 表中加载数据,在 Spark 中执行分析,然后将结果写入 BigQuery 表。
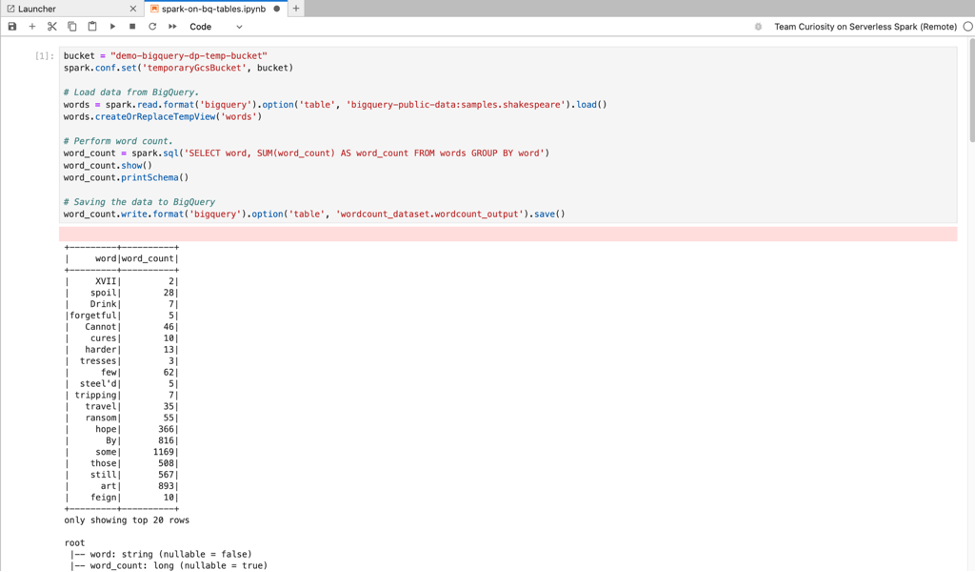
Serverless for Apache Spark 2.2 及更高版本的运行时包含 BigQuery Spark 连接器。如果您使用较早的运行时启动 Serverless for Apache Spark 笔记本,可以通过将以下 Spark 属性添加到 Serverless for Apache Spark 运行时模板来安装 Spark BigQuery 连接器:
spark.jars: gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar
Scala 代码开发
使用映像版本 2.0 及更高版本创建的 Dataproc on Compute Engine 集群包含 Apache Toree,这是一个适用于 Jupyter Notebook 平台的 Scala 内核,可提供对 Spark 的交互式访问。
使用 Visual Studio Code 扩展程序开发代码
您可以使用 Google Cloud Visual Studio Code (VS Code) 扩展程序执行以下操作:
Visual Studio Code 扩展程序是免费的,但您需要为使用的任何Google Cloud 服务(包括 Dataproc、Serverless for Apache Spark 和 Cloud Storage 资源)付费。
将 VS Code 与 BigQuery 搭配使用:您还可以将 VS Code 与 BigQuery 搭配使用,以执行以下操作:
准备工作
安装 Google Cloud 扩展程序
Google Cloud 代码图标现在显示在 VS Code 活动栏中。
配置扩展程序
开发 Serverless for Apache Spark 笔记本
创建和管理 Serverless for Apache Spark 资源
数据集探索器
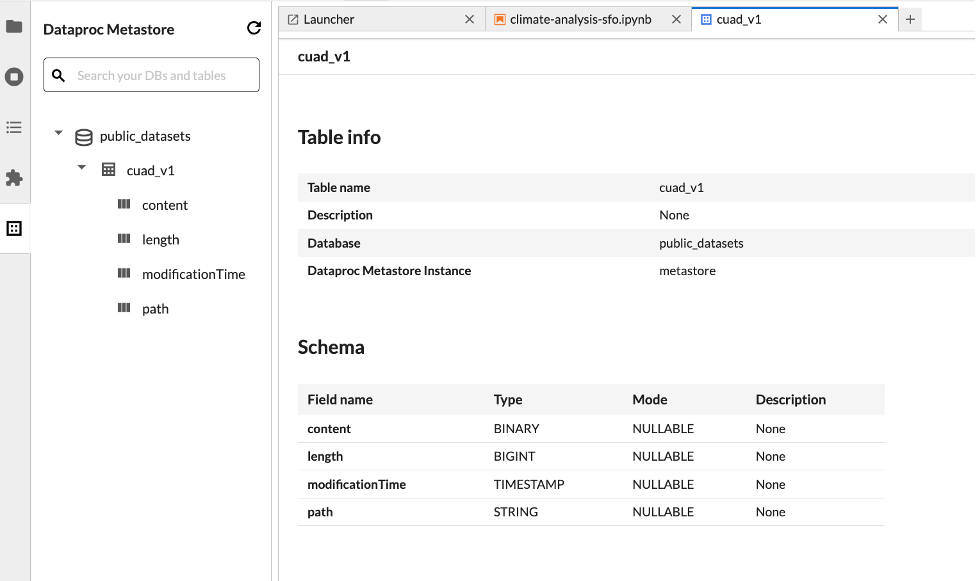
使用 JupyterLab 数据集资源管理器查看 BigLake metastore 数据集。
如需打开 JupyterLab 数据集资源管理器,请点击边栏中的相应图标。
您可以在数据集探索器中搜索数据库、表或列。 点击数据库、表或列名称,即可查看关联的元数据。
部署代码
安装 Dataproc JupyterLab 扩展程序后,您可以使用 JupyterLab 执行以下操作:
在 Cloud Composer 上安排笔记本执行
完成以下步骤,在 Cloud Composer 上安排笔记本代码,以在 Serverless for Apache Spark 上或在 Dataproc on Compute Engine 集群上作为批量作业运行。
向 Google Cloud Serverless for Apache Spark 提交批量作业
向 Dataproc on Compute Engine 集群提交批量作业
查看和管理资源
安装 Dataproc JupyterLab 扩展程序后,您可以在 JupyterLab 启动器页面上的 Dataproc 作业和会话部分中查看和管理 Google Cloud Serverless for Apache Spark 和 Dataproc on Compute Engine。
点击 Dataproc 作业和会话部分,以显示集群和 Serverless 卡片。
如需查看和管理 Google Cloud Serverless for Apache Spark 会话,请执行以下操作:
如需查看和管理 Google Cloud Serverless for Apache Spark 批处理作业,请执行以下操作:
如需查看和管理 Dataproc on Compute Engine 集群,请执行以下操作:
如需查看和管理 Dataproc on Compute Engine 作业,请执行以下操作: