Verwenden Sie den spark-bigquery-connector mit Apache Spark, um Daten aus BigQuery zu lesen und zu schreiben.
In dieser Anleitung wird eine PySpark-Anwendung gezeigt, die die spark-bigquery-connector verwendet.
BigQuery-Connector mit Ihrer Arbeitslast verwenden
Unter Serverless for Apache Spark-Laufzeitversionen finden Sie die BigQuery-Connector-Version, die in Ihrer Batcharbeitslast-Laufzeitversion installiert ist. Wenn der Connector nicht aufgeführt ist, finden Sie im nächsten Abschnitt eine Anleitung dazu, wie Sie den Connector für Anwendungen verfügbar machen.
Connector mit Spark-Laufzeitversion 2.0 verwenden
Der BigQuery-Connector ist in der Spark-Laufzeitversion 2.0 nicht installiert. Wenn Sie die Spark-Laufzeitversion 2.0 verwenden, können Sie den Connector auf eine der folgenden Arten für Ihre Anwendung verfügbar machen:
- Verwenden Sie den Parameter
jars, um beim Einreichen Ihrer Google Cloud Serverless for Apache Spark-Batcharbeitslast auf eine Connector-JAR-Datei zu verweisen. Im folgenden Beispiel wird eine Connector-JAR-Datei angegeben. Eine Liste der verfügbaren Connector-JAR-Dateien finden Sie im Repository GoogleCloudDataproc/spark-bigquery-connector auf GitHub.- Beispiel für Google Cloud CLI:
gcloud dataproc batches submit pyspark \ --region=region \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.13-version.jar \ ... other args
- Beispiel für Google Cloud CLI:
- Schließen Sie die Connector-JAR-Datei in Ihre Spark-Anwendung als Abhängigkeit ein (siehe Für den Connector kompilieren).
Kosten berechnen
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloudverwendet, darunter:
- Serverless for Apache Spark
- BigQuery
- Cloud Storage
Der Preisrechner kann eine Kostenschätzung anhand Ihrer voraussichtlichen Nutzung generieren.
BigQuery-E/A
In diesem Beispiel werden Daten aus BigQuery in einen Spark-DataFrame eingelesen und dann mit der Standard-Datenquellen-API einer Wortzählung unterzogen.
Der Connector schreibt die Wordcount-Ausgabe so in BigQuery:
Puffern der Daten in temporären Dateien in Ihrem Cloud Storage-Bucket
Kopieren der Daten in einem Vorgang aus Ihrem Cloud Storage-Bucket in BigQuery
Löschen der temporären Dateien in Cloud Storage nach Abschluss des BigQuery-Ladevorgangs (temporäre Dateien werden auch nach Beendigung der Spark-Anwendung gelöscht). Wenn das Löschen fehlschlägt, müssen Sie alle unerwünschten temporären Cloud Storage-Dateien löschen, die sich in der Regel in
gs://YOUR_BUCKET/.spark-bigquery-JOB_ID-UUIDbefinden.
Abrechnung konfigurieren
Standardmäßig wird das Projekt, das mit den Anmeldedaten oder dem Dienstkonto verbunden ist, für die API-Nutzung abgerechnet. Wenn Sie ein anderes Projekt in Rechnung stellen möchten, legen Sie die folgende Konfiguration fest: spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>").
Sie kann auch folgendermaßen einem Lese- oder Schreibvorgang hinzugefügt werden: .option("parentProject", "<BILLED-GCP-PROJECT>").
PySpark-Batcharbeitslast für die Wortzählung senden
Führen Sie eine Spark-Batcharbeitslast aus, die die Anzahl der Wörter in einem öffentlichen Dataset zählt.
- Öffnen Sie ein lokales Terminal oder die Cloud Shell.
- Erstellen Sie die
wordcount_datasetmit dem bq-Befehlszeilentool in einem lokalen Terminal oder in Cloud Shell.bq mk wordcount_dataset
- Erstellen Sie einen Cloud Storage-Bucket mit der Google Cloud CLI.
gcloud storage buckets create gs://YOUR_BUCKET
YOUR_BUCKETdurch den Namen des Cloud Storage-Bucket, den Sie erstellt haben. - Erstellen Sie die Datei
wordcount.pylokal in einem Texteditor, indem Sie den folgenden PySpark-Code kopieren.#!/usr/bin/python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName('spark-bigquery-demo') \ .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "YOUR_BUCKET" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .option('table', 'bigquery-public-data:samples.shakespeare') \ .load() words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Saving the data to BigQuery word_count.write.format('bigquery') \ .option('table', 'wordcount_dataset.wordcount_output') \ .save()
- Senden Sie die PySpark-Batcharbeitslast:
gcloud dataproc batches submit pyspark wordcount.py \ --region=REGION \ --deps-bucket=YOUR_BUCKET
... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Wenn Sie eine Vorschau der Ausgabetabelle in der Google Cloud Console aufrufen möchten, öffnen Sie die Seite BigQuery für Ihr Projekt, wählen Sie die Tabellewordcount_outputaus und klicken Sie dann auf Vorschau.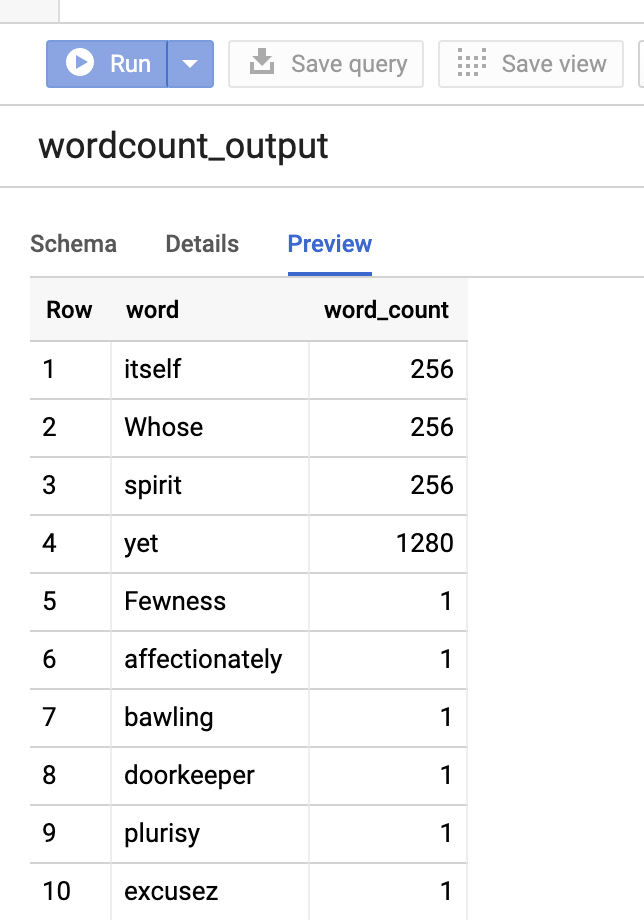
Weitere Informationen
- BigQuery Storage und Spark SQL – Python
- Tabellendefinitionsdatei für eine externe Datenquelle erstellen
- Extern partitionierte Daten verwenden