In diesem Dokument wird beschrieben, wie Sie einen laufenden Streamingjob aktualisieren. Sie können Ihren vorhandenen Dataflow-Job aus folgenden Gründen aktualisieren:
- Sie möchten den Pipelinecode verbessern oder erweitern.
- Sie möchten Programmfehler im Pipelinecode korrigieren.
- Sie möchten die Pipeline aktualisieren, um Änderungen des Datenformats, Versionsänderungen oder andere Änderungen in der Datenquelle zu berücksichtigen.
- Sie möchten eine Sicherheitslücke in Bezug auf Container-Optimized OS für alle Dataflow-Worker beheben.
- Sie möchten eine Apache Beam-Streamingpipeline skalieren, um eine andere Anzahl von Workern zu verwenden.
Sie können Jobs auf zwei Arten aktualisieren:
- Aktualisierung von In-Flight-Jobs: Bei Streamingjobs, die die Streaming Engine nutzen, können Sie die Joboptionen
min-num-workersundmax-num-workersaktualisieren, ohne den Job zu beenden oder die Job-ID zu ändern. - Ersatzjob: Um aktualisierten Pipelinecode auszuführen oder Joboptionen zu aktualisieren, die von Aktualisierungen von laufenden Jobs nicht unterstützt werden, starten Sie einen neuen Job, der den vorhandenen Job ersetzt. Prüfen Sie die relevante Jobgrafik, bevor Sie den neuen Job starten, um zu prüfen, ob ein Ersatzjob gültig ist.
Wenn Sie Ihren Job aktualisieren, führt der Dataflow-Dienst eine Prüfung der Kompatibilität zwischen dem derzeit ausgeführten und dem potenziellen Ersatzjob durch. Die Kompatibilitätsprüfung gewährleistet, dass beispielsweise Zwischenzustandsinformationen und gepufferte Daten vom vorigen Job auf den Ersatzjob übertragen werden können.
Sie können auch die integrierte Logging-Infrastruktur des Apache Beam SDK verwenden, um Informationen zu aktualisieren, wenn Sie Ihren Job aktualisieren. Weitere Informationen finden Sie unter Mit Pipelinelogs arbeiten.
Verwenden Sie die Logging-Ebene DEBUG, um Probleme mit dem Pipelinecode zu identifizieren.
- Eine Anleitung zum Aktualisieren von Streamingjobs, die klassische Vorlagen verwenden, finden Sie unter Streamingjob aus benutzerdefinierter Vorlage aktualisieren.
- Für eine Anleitung zum Aktualisieren von Streamingjobs, die flexible Vorlagen verwenden, folgen Sie entweder der gcloud CLI-Anleitung auf dieser Seite oder lesen Sie Flex-Vorlagenjob aktualisieren.
Aktualisierung der Option des laufenden Jobs
Für einen Streamingjob, der Streaming Engine verwendet, können Sie die folgenden Joboptionen aktualisieren, ohne den Job zu beenden oder die Job-ID zu ändern:
min-num-workers: Die Mindestanzahl von Compute Engine-Instanzen.max-num-workers: Die Mindestanzahl von Compute Engine-Instanzen.worker-utilization-hint: die CPU-Zielauslastung im Bereich [0,1, 0,9]
Für andere Jobaktualisierungen müssen Sie den aktuellen Job durch den aktualisierten Job ersetzen. Weitere Informationen finden Sie unter Ersatzjob starten.
Aktualisierung während der Übertragung durchführen
Führen Sie die folgenden Schritte aus, um eine Aktualisierung der Option eines laufenden Jobs durchzuführen.
gcloud
Führen Sie den Befehl gcloud dataflow jobs update-options aus:
gcloud dataflow jobs update-options \ --region=REGION \ --min-num-workers=MINIMUM_WORKERS \ --max-num-workers=MAXIMUM_WORKERS \ --worker-utilization-hint=TARGET_UTILIZATION \ JOB_ID
Ersetzen Sie Folgendes:
- REGION: die ID der Region des Jobs
- MINIMUM_WORKERS: Die Mindestanzahl von Compute Engine-Instanzen.
- MAXIMUM_WORKERS: Die Mindestanzahl von Compute Engine-Instanzen.
- TARGET_UTILIZATION: ein Wert im Bereich [0,1, 0,9]
- JOB_ID: Die ID des zu aktualisierenden Jobs
Sie können --min-num-workers, --max-num-workers und worker-utilization-hint auch einzeln aktualisieren.
REST
Verwenden Sie die Methode projects.locations.jobs.update:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?updateMask=MASK { "runtime_updatable_params": { "min_num_workers": MINIMUM_WORKERS, "max_num_workers": MAXIMUM_WORKERS, "worker_utilization_hint": TARGET_UTILIZATION } }
Ersetzen Sie Folgendes:
- MASK: eine durch Kommas getrennte Liste von Parametern, die aktualisiert werden sollen, aus folgenden Elementen:
runtime_updatable_params.max_num_workersruntime_updatable_params.min_num_workersruntime_updatable_params.worker_utilization_hint
- PROJECT_ID: Die Google Cloud-Projekt-ID des Dataflow-Jobs
- REGION: die ID der Region des Jobs
- JOB_ID: Die ID des zu aktualisierenden Jobs
- MINIMUM_WORKERS: Die Mindestanzahl von Compute Engine-Instanzen.
- MAXIMUM_WORKERS: Die Mindestanzahl von Compute Engine-Instanzen.
- TARGET_UTILIZATION: ein Wert im Bereich [0,1, 0,9]
Sie können min_num_workers, max_num_workers und worker_utilization_hint auch einzeln aktualisieren.
Geben Sie im Abfrageparameter updateMask an, welche Parameter aktualisiert werden sollen, und fügen Sie die aktualisierten Werte in das Feld runtimeUpdatableParams des Anfragetexts ein. Im folgenden Beispiel wird min_num_workers aktualisiert:
PUT https://dataflow.googleapis.com/v1b3/projects/my_project/locations/us-central1/jobs/job1?updateMask=runtime_updatable_params.min_num_workers { "runtime_updatable_params": { "min_num_workers": 5 } }
Ein Job muss sich im Status "Wird ausgeführt" befinden, um für Aktualisierungen im laufenden Betrieb infrage zu kommen. Wenn der Job nicht gestartet wurde oder bereits abgebrochen wurde, tritt ein Fehler auf. Ebenso warten Sie beim Starten eines Ersatzjobs, bis er ausgeführt wird, bevor Sie In-Flight-Aktualisierungen an den neuen Job senden.
Nachdem Sie eine Aktualisierungsanfrage gesendet haben, warten Sie, bis die Anfrage abgeschlossen ist, bevor Sie eine weitere Aktualisierung senden. In den Joblogs sehen Sie, wann die Anfrage abgeschlossen ist.
Ersatzjob validieren
Prüfen Sie die relevante Jobgrafik, bevor Sie den neuen Job starten, um zu prüfen, ob ein Ersatzjob gültig ist. In Dataflow ist eine Jobgrafik eine grafische Darstellung einer Pipeline. Durch die Validierung der Jobgrafik verringern Sie das Risiko, dass in der Pipeline nach der Aktualisierung Fehler oder ein Pipelineversagen auftreten. Darüber hinaus können Sie Aktualisierungen validieren, ohne den ursprünglichen Job beenden zu müssen. So entsteht keine Ausfallzeit für den Job.
Führen Sie die Schritte zum Starten eines Ersatzjobs aus, um Ihre Jobgrafik zu validieren. Fügen Sie in den Aktualisierungsbefehl die Dataflow-Dienstoption graph_validate_only ein.
Java
- Übergeben Sie die Option
--update. - Setzen Sie die Option
--jobNameinPipelineOptionsauf den Namen des zu aktualisierenden Jobs. - Setzen Sie die Option
--regionauf die Region des Jobs, den Sie aktualisieren möchten. - Fügen Sie die Dienstoption
--dataflowServiceOptions=graph_validate_onlyein. - Sollten sich Transformationsnamen in Ihrer Pipeline geändert haben, müssen Sie eine Transformationszuordnung mit der Option
--transformNameMappingübergeben. - Wenn Sie einen Ersatzjob senden, der eine neuere Version des Apache Beam SDK verwendet, setzen Sie
--updateCompatibilityVersionauf die Apache Beam SDK-Version, die im ursprünglichen Job verwendet wurde.
Python
- Übergeben Sie die Option
--update. - Setzen Sie die Option
--job_nameinPipelineOptionsauf den Namen des zu aktualisierenden Jobs. - Setzen Sie die Option
--regionauf die Region des Jobs, den Sie aktualisieren möchten. - Fügen Sie die Dienstoption
--dataflow_service_options=graph_validate_onlyein. - Sollten sich Transformationsnamen in Ihrer Pipeline geändert haben, müssen Sie eine Transformationszuordnung mit der Option
--transform_name_mappingübergeben. - Wenn Sie einen Ersatzjob senden, der eine neuere Version des Apache Beam SDK verwendet, setzen Sie
--updateCompatibilityVersionauf die Apache Beam SDK-Version, die im ursprünglichen Job verwendet wurde.
Go
- Übergeben Sie die Option
--update. - Legen Sie für die Option
--job_namedenselben Namen wie für den zu aktualisierenden Job fest. - Setzen Sie die Option
--regionauf die Region des Jobs, den Sie aktualisieren möchten. - Fügen Sie die Dienstoption
--dataflow_service_options=graph_validate_onlyein. - Sollten sich Transformationsnamen in Ihrer Pipeline geändert haben, müssen Sie eine Transformationszuordnung mit der Option
--transform_name_mappingübergeben.
gcloud
Verwenden Sie den Befehl gcloud dataflow flex-template run mit der Option additional-experiments, um die Jobgrafik für einen Job mit flexibler Vorlage zu validieren:
- Übergeben Sie die Option
--update. - Legen Sie für JOB_NAME denselben Namen wie für den Job fest, den Sie aktualisieren möchten.
- Setzen Sie die Option
--regionauf die Region des Jobs, den Sie aktualisieren möchten. - Fügen Sie die Option
--additional-experiments=graph_validate_onlyein. - Sollten sich Transformationsnamen in Ihrer Pipeline geändert haben, müssen Sie eine Transformationszuordnung mit der Option
--transform-name-mappingsübergeben.
Beispiel:
gcloud dataflow flex-template run JOB_NAME --additional-experiments=graph_validate_only
Ersetzen Sie JOB_NAME durch den Namen des Jobs, den Sie aktualisieren möchten.
REST
Verwenden Sie das Feld additionalExperiments im Objekt FlexTemplateRuntimeEnvironment (flexible Vorlagen) oder RuntimeEnvironment.
{
additionalExperiments : ["graph_validate_only"]
...
}
Mit der Dienstoption graph_validate_only werden nur Pipelineaktualisierungen validiert. Verwenden Sie diese Option nicht beim Erstellen oder Starten von Pipelines. Starten Sie einen Ersatzjob ohne die Dienstoption graph_validate_only, um die Pipeline zu aktualisieren.
Wenn die Validierung des Jobdiagramms erfolgreich ist, zeigen Jobstatus und Joblogs die folgenden Statuswerte an:
- Der Jobstatus lautet
JOB_STATE_DONE. - In der Google Cloud Console lautet der Jobstatus
Succeeded. Die folgende Meldung wird in den Joblogs angezeigt:
Workflow job: JOB_ID succeeded validation. Marking graph_validate_only job as Done.
Wenn die Validierung des Jobdiagramms fehlschlägt, zeigen Jobstatus und Joblogs die folgenden Statuswerte an:
- Der Jobstatus lautet
JOB_STATE_FAILED. - In der Google Cloud Console lautet der Jobstatus
Failed. - In den Joblogs wird eine Meldung angezeigt, die den Inkompatibilitätsfehler beschreibt. Der Inhalt der Nachricht hängt vom Fehler ab.
Ersatzjob starten
Sie können einen vorhandenen Job aus folgenden Gründen ersetzen:
- So führen Sie aktualisierten Pipelinecode aus.
- So aktualisieren Sie Joboptionen, die keine In-Flight-Updates unterstützen
Prüfen Sie die relevante Jobgrafik, bevor Sie den neuen Job starten, um zu prüfen, ob ein Ersatzjob gültig ist.
Legen Sie beim Starten eines Ersatzjobs die folgenden Pipelineoptionen fest, um den Aktualisierungsvorgang zusätzlich zu den normalen Optionen des Jobs auszuführen:
Java
- Übergeben Sie die Option
--update. - Setzen Sie die Option
--jobNameinPipelineOptionsauf den Namen des zu aktualisierenden Jobs. - Setzen Sie die Option
--regionauf die Region des Jobs, den Sie aktualisieren möchten. - Sollten sich Transformationsnamen in Ihrer Pipeline geändert haben, müssen Sie eine Transformationszuordnung mit der Option
--transformNameMappingübergeben. - Wenn Sie einen Ersatzjob senden, der eine neuere Version des Apache Beam SDK verwendet, setzen Sie
--updateCompatibilityVersionauf die Apache Beam SDK-Version, die im ursprünglichen Job verwendet wurde.
Python
- Übergeben Sie die Option
--update. - Setzen Sie die Option
--job_nameinPipelineOptionsauf den Namen des zu aktualisierenden Jobs. - Setzen Sie die Option
--regionauf die Region des Jobs, den Sie aktualisieren möchten. - Sollten sich Transformationsnamen in Ihrer Pipeline geändert haben, müssen Sie eine Transformationszuordnung mit der Option
--transform_name_mappingübergeben. - Wenn Sie einen Ersatzjob senden, der eine neuere Version des Apache Beam SDK verwendet, setzen Sie
--updateCompatibilityVersionauf die Apache Beam SDK-Version, die im ursprünglichen Job verwendet wurde.
Go
- Übergeben Sie die Option
--update. - Legen Sie für die Option
--job_namedenselben Namen wie für den zu aktualisierenden Job fest. - Setzen Sie die Option
--regionauf die Region des Jobs, den Sie aktualisieren möchten. - Sollten sich Transformationsnamen in Ihrer Pipeline geändert haben, müssen Sie eine Transformationszuordnung mit der Option
--transform_name_mappingübergeben.
gcloud
Verwenden Sie den Befehl gcloud dataflow flex-template run, um einen flexiblen Vorlagenjob mit der gcloud CLI zu aktualisieren. Das Aktualisieren anderer Jobs mit der gcloud CLI wird nicht unterstützt.
- Übergeben Sie die Option
--update. - Legen Sie für JOB_NAME denselben Namen wie für den Job fest, den Sie aktualisieren möchten.
- Setzen Sie die Option
--regionauf die Region des Jobs, den Sie aktualisieren möchten. - Sollten sich Transformationsnamen in Ihrer Pipeline geändert haben, müssen Sie eine Transformationszuordnung mit der Option
--transform-name-mappingsübergeben.
REST
In dieser Anleitung wird gezeigt, wie Sie Jobs ohne Vorlagen mit der REST API aktualisieren. Informationen zum Aktualisieren eines Jobs mit klassischer Vorlage über die REST API finden Sie unter Streamingjob aus benutzerdefinierter Vorlage aktualisieren. Informationen zum Aktualisieren eines Jobs mit flexibler Vorlage mit der REST API finden Sie unter Job mit flexibler Vorlage aktualisieren.
Rufen Sie die Ressource
jobfür den Job, den Sie ersetzen möchten, mit der Methodeprojects.locations.jobs.getab. Verwenden Sie den Abfrageparameterviewmit dem WertJOB_VIEW_DESCRIPTION. Wenn SieJOB_VIEW_DESCRIPTIONverwenden, wird die Datenmenge in der Antwort begrenzt, sodass Ihre nachfolgende Anfrage die Größenbeschränkungen nicht überschreitet. Für detailliertere Jobinformationen verwenden Sie den WertJOB_VIEW_ALL.GET https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?view=JOB_VIEW_DESCRIPTIONErsetzen Sie die folgenden Werte:
- PROJECT_ID: Die Google Cloud-Projekt-ID des Dataflow-Jobs
- REGION: Die Region des Jobs, den Sie aktualisieren möchten
- JOB_ID: Die Job-ID des Jobs, den Sie aktualisieren möchten
Verwenden Sie zum Aktualisieren des Feldes die Methode
projects.locations.jobs.create. Verwenden Sie im Anfragetext die abgerufenejob-Ressource.POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs { "id": JOB_ID, "replaceJobId": JOB_ID, "name": JOB_NAME, "type": "JOB_TYPE_STREAMING", "transformNameMapping": { string: string, ... }, }Ersetzen Sie Folgendes:
- JOB_ID: Die Job-ID des Jobs, den Sie aktualisieren möchten.
- JOB_NAME: Der Jobname des Jobs, den Sie aktualisieren möchten.
Sollten sich Transformationsnamen in Ihrer Pipeline geändert haben, müssen Sie eine Transformationszuordnung mit dem Feld
transformNameMappingübergeben.Optional: Zum Senden der Anfrage mit curl (Linux, macOS oder Cloud Shell) speichern Sie die Anfrage in einer JSON-Datei und führen Sie dann den folgenden Befehl aus:
curl -X POST -d "@FILE_PATH" -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-access-token)" https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobsErsetzen Sie FILE_PATH durch den Pfad zur JSON-Datei, die den Anfragetext enthält.
Namen des Ersatzjobs angeben
Java
Wenn Sie den Ersatzjob starten, muss der Wert, den Sie für die Option --jobName übergeben, exakt mit dem Namen des zu ersetzenden Jobs übereinstimmen.
Python
Wenn Sie den Ersatzjob starten, muss der Wert, den Sie für die Option --job_name übergeben, exakt mit dem Namen des zu ersetzenden Jobs übereinstimmen.
Go
Wenn Sie den Ersatzjob starten, muss der Wert, den Sie für die Option --job_name übergeben, exakt mit dem Namen des zu ersetzenden Jobs übereinstimmen.
gcloud
Wenn Sie den Ersatzjob starten, muss JOB_NAME genau mit dem Namen des zu ersetzenden Jobs übereinstimmen.
REST
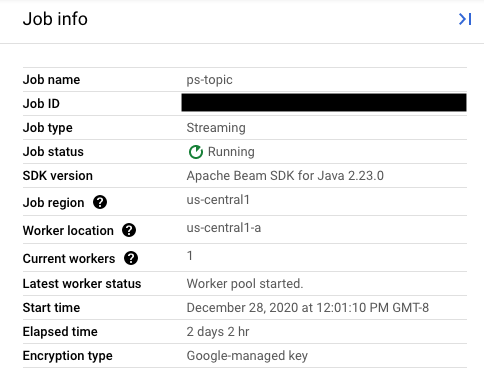
Legen Sie den Wert des Felds replaceJobId auf die Job-ID des zu aktualisierenden Jobs fest. Wählen Sie den vorigen Job in der Dataflow-Monitoring-Oberfläche aus, um den richtigen Jobnamen zu ermitteln.
Suchen Sie dann in der Seitenleiste Jobdetails das Feld Job-ID.
Wählen Sie den vorigen Job in der Dataflow-Monitoring-Oberfläche aus, um den richtigen Jobnamen zu ermitteln. Suchen Sie dann in der Seitenleiste Jobinfo das Feld Jobname:
Alternativ können Sie die Liste der vorhandenen Jobs über die Dataflow-Befehlszeilenschnittstelle abfragen.
Geben Sie den Befehl gcloud dataflow jobs list in Ihr Shell- oder Terminal-Fenster ein, um eine Liste der Dataflow-Jobs in Ihrem Google Cloud-Projekt zu erhalten, und suchen Sie nach dem NAME für den Job, den Sie ersetzen möchten:
JOB_ID NAME TYPE CREATION_TIME STATE REGION 2020-12-28_12_01_09-yourdataflowjobid ps-topic Streaming 2020-12-28 20:01:10 Running us-central1
Transformationszuordnung erstellen
Falls die Namen der Transformationen in der Ersatz-Pipeline von jenen in der vorigen Pipeline abweichen, benötigt der Dataflow-Dienst eine Transformationszuordnung. Die Transformationszuordnung dient dazu, die benannten Transformationen des vorigen Pipelinecodes den Namen im neuen Pipelinecode zuzuordnen.
Java
Übergeben Sie die Zuordnung mit der Befehlszeilenoption --transformNameMapping im folgenden Format:
--transformNameMapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Beachten Sie, dass Sie in --transformNameMapping nur Zuordnungseinträge für Transformationsnamen angeben müssen, die zwischen der vorherigen Pipeline und der Ersatzpipeline geändert wurden.
Hinweis: Bei der Ausführung mit --transformNameMapping müssen Anführungszeichen gemäß den Anforderungen Ihrer Shell gegebenenfalls mit Escapezeichen versehen werden. Zum Beispiel in Bash:
--transformNameMapping='{"oldTransform1":"newTransform1",...}'
Python
Übergeben Sie die Zuordnung mit der Befehlszeilenoption --transform_name_mapping im folgenden Format:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Beachten Sie, dass Sie in --transform_name_mapping nur Zuordnungseinträge für Transformationsnamen angeben müssen, die zwischen der vorherigen Pipeline und der Ersatzpipeline geändert wurden.
Hinweis: Bei der Ausführung mit --transform_name_mapping müssen Anführungszeichen gemäß den Anforderungen Ihrer Shell gegebenenfalls mit Escapezeichen versehen werden. Zum Beispiel in Bash:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
Go
Übergeben Sie die Zuordnung mit der Befehlszeilenoption --transform_name_mapping im folgenden Format:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Beachten Sie, dass Sie in --transform_name_mapping nur Zuordnungseinträge für Transformationsnamen angeben müssen, die zwischen der vorherigen Pipeline und der Ersatzpipeline geändert wurden.
Hinweis: Bei der Ausführung mit --transform_name_mapping müssen Anführungszeichen gemäß den Anforderungen Ihrer Shell gegebenenfalls mit Escapezeichen versehen werden. Zum Beispiel in Bash:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
gcloud
Übergeben Sie die Zuordnung mit der Option --transform-name-mappings im folgenden Format:
--transform-name-mappings= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Beachten Sie, dass Sie in --transform-name-mappings nur Zuordnungseinträge für Transformationsnamen angeben müssen, die zwischen der vorherigen Pipeline und der Ersatzpipeline geändert wurden.
Hinweis: Bei der Ausführung mit --transform-name-mappings müssen Anführungszeichen gemäß den Anforderungen Ihrer Shell gegebenenfalls mit Escapezeichen versehen werden. Zum Beispiel in Bash:
--transform-name-mappings='{"oldTransform1":"newTransform1",...}'
REST
Übergeben Sie die Zuordnung mit dem Feld transformNameMapping im folgenden Format:
"transformNameMapping": {
oldTransform1: newTransform1,
oldTransform2: newTransform2,
...
}
Beachten Sie, dass Sie in transformNameMapping nur Zuordnungseinträge für Transformationsnamen angeben müssen, die zwischen der vorherigen Pipeline und der Ersatzpipeline geändert wurden.
Transformationsnamen bestimmen
Der Transformationsname in einer Instanz in der Zuordnung ist der Name, den Sie bei der Anwendung der Transformation in Ihrer Pipeline angegeben haben. Beispiel:
Java
.apply("FormatResults", ParDo
.of(new DoFn<KV<String, Long>>, String>() {
...
}
}))
Python
| 'FormatResults' >> beam.ParDo(MyDoFn())
Go
// In Go, this is always the package-qualified name of the DoFn itself.
// For example, if the FormatResults DoFn is in the main package, its name
// is "main.FormatResults".
beam.ParDo(s, FormatResults, results)
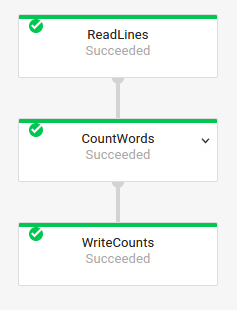
Außerdem können Sie die Transformationsnamen des vorigen Jobs durch Untersuchung der Ausführungsgrafik des Jobs in der Dataflow-Überwachungsoberfläche abrufen:
Benennung von zusammengesetzten Transformationen
Transformationsnamen sind in Abhängigkeit von der Hierarchie in der Pipeline hierarchisch aufgebaut. Wenn eine Pipeline über eine zusammengesetzte Transformation verfügt, werden die eingebetteten Transformationen mit Bezug auf die sie enthaltende Transformation benannt. Nehmen wir beispielsweise an, Ihre Pipeline enthält eine zusammengesetzte Transformation namens CountWidgets, die wiederum eine Transformation namens Parse enthält. Der vollständige Name der Transformation lautet CountWidgets/Parse. Dies ist der Name, den Sie in der Transformationszuordnung angeben müssen.
Wenn die neue Pipeline eine zusammengesetzte Transformation einem anderen Namen zuordnet, werden auch alle darin verschachtelten Transformationen automatisch umbenannt. Sie müssen die neuen Namen für die inneren Transformationen in der Transformationszuordnung angeben.
Transformationshierarchie refaktorieren
Wenn die Hierarchie der Ersatzpipeline von jener der vorigen Pipeline abweicht, müssen Sie die Zuordnung ausdrücklich deklarieren. Möglicherweise sehen Sie eine andere Transformationshierarchie, weil Sie die zusammengesetzten Transformationen refaktoriert haben oder die Pipeline von einer zusammengesetzten Transformation aus einer Mediathek abhängt, die sich geändert hat.
Beispiel: In der vorigen Pipeline wurde die zusammengesetzte Transformation CountWidgets angewendet, die eine innere Transformation namens Parse enthielt. Die Ersatzpipeline refaktoriert CountWidgets und verschachtelt Parse in eine andere Transformation namens Scan. Damit die Aktualisierung gelingen kann, müssen Sie den vollständigen Transformationsnamen in der vorigen Pipeline (CountWidgets/Parse) ausdrücklich dem Transformationsnamen in der neuen Pipeline (CountWidgets/Scan/Parse) zuordnen:
Java
--transformNameMapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Wenn Sie eine Transformation ganz aus der Ersatzpipeline löschen, müssen Sie eine Null-Zuordnung angeben. Nehmen wir an, aus der Ersatzpipeline wird die Transformation CountWidgets/Parse vollkommen entfernt:
--transformNameMapping={"CountWidgets/Parse":""}
Python
--transform_name_mapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Wenn Sie eine Transformation ganz aus der Ersatzpipeline löschen, müssen Sie eine Null-Zuordnung angeben. Nehmen wir an, aus der Ersatzpipeline wird die Transformation CountWidgets/Parse vollkommen entfernt:
--transform_name_mapping={"CountWidgets/Parse":""}
Go
--transform_name_mapping={"CountWidgets/main.Parse":"CountWidgets/Scan/main.Parse"}
Wenn Sie eine Transformation ganz aus der Ersatzpipeline löschen, müssen Sie eine Null-Zuordnung angeben. Nehmen wir an, aus der Ersatzpipeline wird die Transformation CountWidgets/Parse vollkommen entfernt:
--transform_name_mapping={"CountWidgets/main.Parse":""}
gcloud
--transform-name-mappings={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Wenn Sie eine Transformation ganz aus der Ersatzpipeline löschen, müssen Sie eine Null-Zuordnung angeben. Nehmen wir an, aus der Ersatzpipeline wird die Transformation CountWidgets/Parse vollkommen entfernt:
--transform-name-mappings={"CountWidgets/main.Parse":""}
REST
"transformNameMapping": {
CountWidgets/Parse: CountWidgets/Scan/Parse
}
Wenn Sie eine Transformation ganz aus der Ersatzpipeline löschen, müssen Sie eine Null-Zuordnung angeben. Nehmen wir an, aus der Ersatzpipeline wird die Transformation CountWidgets/Parse vollkommen entfernt:
"transformNameMapping": {
CountWidgets/main.Parse: null
}
Auswirkungen des Ersetzens eines Jobs
Wenn Sie einen vorhandenen Job ersetzen, führt ein neuer Job den aktualisierten Pipelinecode aus. Der Dataflow-Dienst behält den Jobnamen bei, führt den Ersatzjob aber mit einer aktualisierten Job-ID aus. Dieser Vorgang kann zu Ausfallzeiten führen, während der vorhandene Job angehalten wird, die Kompatibilitätsprüfung ausgeführt wird und der neue Job gestartet wird.
Der Ersatzjob behält folgende Elemente bei:
- Zwischenzustandsdaten aus dem vorigen Job. In-Memory-Caches werden nicht gespeichert.
- Zwischengespeicherte Datensätze oder Metadaten, die gerade vom vorigen Job übertragen werden. So können beispielsweise einige Datensätze in der Pipeline gepuffert werden, bis eine Windowing-Auflösung abgeschlossen ist.
- In-Flight-Aktualisierungen von Joboptionen, die Sie auf den vorigen Job angewendet haben.
Zwischenzustandsdaten
Zwischenzustandsdaten aus dem vorherigen Job bleiben erhalten. Zustandsdaten enthalten keine In-Memory-Caches. Wenn Sie bei der Aktualisierung Ihrer Pipeline die Cache-Daten beibehalten möchten, refaktorieren Sie Ihre Pipeline so, dass Caches in Statusdaten oder Nebeneingaben umgewandelt werden. Weitere Informationen zur Verwendung von Nebeneingaben finden Sie in der Apache Beam-Dokumentation unter Nebeneingabemuster.
Streamingpipelines haben Größenbeschränkungen für ValueState und für Nebeneingaben.
Wenn Sie große Caches haben, die Sie beibehalten möchten, müssen Sie daher möglicherweise einen externen Speicher wie Memorystore oder Bigtable verwenden.
In-Flight-Daten
In-Flight-Daten werden durch die Transformationen in der neuen Pipeline verarbeitet. Ob zusätzliche Transformationen, die Sie dem Ersatz-Pipelinecode hinzufügen, wirksam werden, hängt jedoch davon ab, wo die Datensätze gepuffert werden. In diesem Beispiel verfügt Ihre vorhandene Pipeline über die folgenden Transformationen:
Java
p.apply("Read", ReadStrings())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, FormatStrings)
Sie können Ihren Job folgendermaßen durch neuen Pipelinecode ersetzen:
Java
p.apply("Read", ReadStrings())
.apply("Remove", RemoveStringsStartingWithA())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Remove' >> RemoveStringsStartingWithA()
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, RemoveStringsStartingWithA) beam.ParDo(s, FormatStrings)
Selbst wenn Sie eine Transformation zum Herausfiltern von Strings, die mit dem Buchstaben "A" beginnen, hinzugefügen, sieht die nächste Transformation (FormatStrings) möglicherweise trotzdem gepufferte oder in Übertragung befindliche (In-Flight-)Strings des vorigen Jobs, die mit "A" beginnen.
Windowing ändern
Sie können die Windowing- und Trigger-Strategien für die PCollection-Objekte in der Ersatzpipeline ändern. Dabei ist jedoch Vorsicht geboten.
Eine Änderung der Windowing- oder Trigger-Strategien wirkt sich nicht auf bereits gepufferte oder anderweitig in Übertragung befindliche Daten aus.
Es empfiehlt sich, nur geringfügige Änderungen am Windowing der Pipeline vorzunehmen, z. B. eine Änderung der Dauer von festen oder fließenden Zeitfenstern. Durch größere Änderungen an Windowing- oder Trigger-Strategien, z. B. eine Änderung des Windowing-Algorithmus, kann die Pipelineausgabe unvorhersehbare Ergebnisse liefern.
Kompatibilitätsprüfung von Jobs
Wenn Sie Ihren Ersatzjob starten, führt der Dataflow-Dienst eine Prüfung der Kompatibilität zwischen dem Ersatzjob und dem vorigen Job durch. Bei Bestehen der Kompatibilitätsprüfung wird der vorige Job angehalten. Der Ersatzjob startet dann unter demselben Jobnamen im Dataflow-Dienst. Bei Nichtbestehen der Kompatibilitätsprüfung wird der vorige Job weiterhin im Dataflow-Dienst ausgeführt und der Ersatzjob gibt einen Fehler zurück.
Java
Aufgrund einer Einschränkung müssen Sie die Blockierung der Ausführung verwenden, damit fehlgeschlagene Aktualisierungsfehler in der Konsole oder dem Terminal angezeigt werden. Mit folgenden Schritten kann das Problem derzeit umgangen werden:
- Verwenden Sie pipeline.run().waitUntilFinish() in Ihrem Pipelinecode.
- Führen Sie Ihr Ersatz-Pipelineprogramm mit der Option
--updateaus. - Warten Sie, bis der Ersatzjob die Kompatibilitätsprüfung erfolgreich bestanden hat.
- Beenden Sie den Blocking-Ausführungsprozess durch Eingabe von
Ctrl+C.
Alternativ können Sie den Status Ihres Ersatzjobs in der Monitoring-Oberfläche von Dataflow überwachen. Wenn Ihr Job erfolgreich gestartet wurde, hat er auch die Kompatibilitätsprüfung bestanden.
Python
Aufgrund einer Einschränkung müssen Sie die Blockierung der Ausführung verwenden, damit fehlgeschlagene Aktualisierungsfehler in der Konsole oder dem Terminal angezeigt werden. Mit folgenden Schritten kann das Problem derzeit umgangen werden:
- Verwenden Sie pipeline.run().wait_until_finish() in Ihrem Pipelinecode.
- Führen Sie Ihr Ersatz-Pipelineprogramm mit der Option
--updateaus. - Warten Sie, bis der Ersatzjob die Kompatibilitätsprüfung erfolgreich bestanden hat.
- Beenden Sie den Blocking-Ausführungsprozess durch Eingabe von
Ctrl+C.
Alternativ können Sie den Status Ihres Ersatzjobs in der Monitoring-Oberfläche von Dataflow überwachen. Wenn Ihr Job erfolgreich gestartet wurde, hat er auch die Kompatibilitätsprüfung bestanden.
Go
Aufgrund einer Einschränkung müssen Sie die Blockierung der Ausführung verwenden, damit fehlgeschlagene Aktualisierungsfehler in der Konsole oder dem Terminal angezeigt werden.
Insbesondere müssen Sie die nicht blockierende Ausführung mit dem Flag --execute_async oder --async einstellen. Mit folgenden Schritten kann das Problem derzeit umgangen werden:
- Führen Sie Ihr Ersatz-Pipelineprogramm mit der Option
--updateund ohne das Flag--execute_asyncoder--asyncaus. - Warten Sie, bis der Ersatzjob die Kompatibilitätsprüfung erfolgreich besteht.
- Beenden Sie den Blocking-Ausführungsprozess durch Eingabe von
Ctrl+C.
gcloud
Aufgrund einer Einschränkung müssen Sie die Blockierung der Ausführung verwenden, damit fehlgeschlagene Aktualisierungsfehler in der Konsole oder dem Terminal angezeigt werden. Mit folgenden Schritten kann das Problem derzeit umgangen werden:
- Verwenden Sie bei Java-Pipelines pipeline.run().waitUntilFinish() in Ihrem Pipelinecode. Verwenden Sie bei Python-Pipelines pipeline.run().wait_until_finish() in Ihrem Pipelinecode. Führen Sie bei Go-Pipelines die Schritte auf dem Tab „Go“ aus.
- Führen Sie Ihr Ersatz-Pipelineprogramm mit der Option
--updateaus. - Warten Sie, bis der Ersatzjob die Kompatibilitätsprüfung erfolgreich bestanden hat.
- Beenden Sie den Blocking-Ausführungsprozess durch Eingabe von
Ctrl+C.
REST
Aufgrund einer Einschränkung müssen Sie die Blockierung der Ausführung verwenden, damit fehlgeschlagene Aktualisierungsfehler in der Konsole oder dem Terminal angezeigt werden. Mit folgenden Schritten kann das Problem derzeit umgangen werden:
- Verwenden Sie bei Java-Pipelines pipeline.run().waitUntilFinish() in Ihrem Pipelinecode. Verwenden Sie bei Python-Pipelines pipeline.run().wait_until_finish() in Ihrem Pipelinecode. Führen Sie bei Go-Pipelines die Schritte auf dem Tab „Go“ aus.
- Führen Sie Ihr Ersatz-Pipelineprogramm mit dem Feld
replaceJobIdaus. - Warten Sie, bis der Ersatzjob die Kompatibilitätsprüfung erfolgreich besteht.
- Beenden Sie den Blocking-Ausführungsprozess durch Eingabe von
Ctrl+C.
Bei der Kompatibilitätsprüfung wird die bereitgestellte Transformationszuordnung verwendet, um sicherzustellen, dass Dataflow Daten in einem Zwischenzustand aus den Schritten des vorigen Jobs an den Ersatzjob übertragen kann. Außerdem sorgt die Kompatibilitätsprüfung dafür, dass die PCollection-Objekte in Ihrer Pipeline dieselben Coder verwenden.
Wenn Sie einen Coder ändern, kann die Kompatibilitätsprüfung fehlschlagen, da etwaige In-Flight-Daten oder gepufferte Datensätze in der Ersatzpipeline möglicherweise nicht richtig serialisiert werden.
Kompatibilitätsbrüche verhindern
Bestimmte Unterschiede zwischen der vorigen und der Ersatzpipeline können zum Nichtbestehen der Kompatibilitätsprüfung führen. Zu diesen Unterschieden gehören:
- Änderung des Pipelinediagramms ohne Angabe einer Zuordnung: Wenn Sie einen Job aktualisieren, wird von Dataflow versucht, die Transformationen aus dem vorigen und dem Ersatzjob einander zuzuordnen. Durch diesen Abgleichsprozess kann Dataflow Zwischenzustandsdaten für jeden Schritt übertragen. Wenn Sie Schritte umbenennen oder entfernen, müssen Sie eine Transformationszuordnung bereitstellen, damit Dataflow Zustandsdaten entsprechend zuordnen kann.
- Änderung der Nebeneingaben für einen Schritt: Wenn Sie einer Transformation in der Ersatzpipeline Nebeneingaben hinzufügen oder sie aus ihr entfernen, schlägt die Kompatibilitätsprüfung fehl.
- Änderung des Codes für einen Schritt: Wenn Sie einen Job aktualisieren, werden alle derzeit zwischengespeicherten Datensätze von Dataflow beibehalten und im Ersatzjob verarbeitet. Gepufferte Daten können beispielsweise während der Windowing-Auflösung auftreten. Wenn der Ersatzjob eine andere oder eine inkompatible Datencodierung verwendet, können diese Datensätze von Dataflow nicht serialisiert oder deserialisiert werden.
"Zustandsorientierten" Vorgang aus der Pipeline entfernen. Wenn Sie zustandsorientierte Vorgänge aus der Pipeline entfernen, besteht der Ersatzjob möglicherweise die Kompatibilitätsprüfung nicht. Dataflow kann im Sinne der Effizienz mehrere Schritte zusammenfassen. Wenn eine zustandsabhängige Operation aus einem zusammengefassten Schritt fehlt, schlägt die Prüfung fehl. Bei "stateful"-Operationen handelt es sich um:
- Transformationen, die Nebeneingaben erzeugen oder verbrauchen.
- E/A-Lesevorgänge
- Transformationen mit verschlüsselten Zuständen
- Transformationen mit Fensterzusammenführung
Zustandsorientierte
DoFn-Variablen ändern. Wenn bei Streaming-Jobs Ihre Pipeline zustandsorientierteDoFns enthält, kann das Ändern der zustandsorientiertenDoFn-Variablen dazu führen, dass die Pipeline fehlschlägt.Es wird versucht, den Ersatzjob in einer anderen geografischen Zone auszuführen: Führen Sie den Ersatzjob in derselben Zone aus, in der Sie den vorigen Job ausgeführt haben.
Schemas aktualisieren
Apache Beam lässt PCollection zu Schemas mit benannten Feldern zu. In diesem Fall sind keine expliziten Coder erforderlich. Wenn die Feldnamen und -typen für ein bestimmtes Schema unverändert bleiben (einschließlich verschachtelter Felder), führt dieses Schema nicht dazu, dass die Aktualisierungsprüfung fehlschlägt. Die Aktualisierung kann jedoch weiterhin blockiert sein, wenn andere Segmente der neuen Pipeline nicht kompatibel sind.
Schemas entwickeln
Häufig ist es erforderlich, das Schema einer PCollection aufgrund von sich entwickelnden Geschäftsanforderungen zu entwickeln. Der Dataflow-Dienst ermöglicht beim Aktualisieren der Pipeline die folgenden Änderungen an einem Schema:
- Ein oder mehrere neue Felder zu einem Schema hinzufügen, einschließlich verschachtelter Felder.
- Obligatorischer Feldtyp (keine Nullwerte zulässig), der optional sein kann (Nullwerte zulässig).
Das Entfernen von Feldern, Ändern von Feldnamen oder Ändern von Feldtypen ist während der Aktualisierung nicht zulässig.
Zusätzliche Daten an einen vorhandenen ParDo-Vorgang übergeben
Sie können je nach Anwendungsfall zusätzliche (Out-of-Band-)Daten an einen vorhandenen ParDo-Vorgang übergeben. Verwenden Sie dazu je nach Anwendungsfall eine der folgenden Methoden:
- Informationen als Felder in Ihrer
DoFn-Unterklasse serialisieren. - Alle Variablen, auf die in den Methoden in einem anonymen
DoFnverwiesen wird, werden automatisch serialisiert. - Daten innerhalb von
DoFn.startBundle()berechnen. - Daten mit
ParDo.withSideInputsübergeben.
Weitere Informationen finden Sie auf den folgenden Seiten:
- Programmieranleitung für Apache Beam: ParDo, insbesondere die Abschnitte zum Erstellen von DoFn und Nebeneingaben.
- Referenz zum Apache Beam SDK für Java: ParDo