Sie können die integrierte Logging-Infrastruktur des Apache Beam SDK verwenden, um Informationen beim Ausführen Ihrer Pipeline zu protokollieren. Mit der Google Cloud Console können Sie Logging-Informationen während und nach der Ausführung Ihrer Pipeline überwachen.
Einer Pipeline Lognachrichten hinzufügen
Java
Beim Apache Beam SDK for Java wird empfohlen, für das Logging von Worker-Nachrichten die Open-Source-Bibliothek SLF4J (Simple Logging Facade for Java) einzusetzen. Das Apache Beam SDK for Java implementiert die erforderliche Logging-Infrastruktur, sodass Ihr Java-Code nur die SLF4J API importieren muss. Anschließend wird ein Logger instanziiert, um das Nachrichtenlogging in Ihrem Pipeline-Code zu aktivieren.
Bei bereits vorhandenem Code und/oder Bibliotheken richtet das Apache Beam SDK for Java eine zusätzliche Logging-Infrastruktur ein. Lognachrichten, die von den folgenden Logging-Bibliotheken für Java erstellt werden, werden erfasst:
Python
Das Apache Beam SDK for Python stellt das Bibliothekspaket logging bereit, damit Pipeline-Worker Lognachrichten ausgeben können. Damit Sie die Bibliotheksfunktionen nutzen können, müssen Sie die Bibliothek importieren:
import logging
Go
Das Apache Beam SDK for Go stellt das Bibliothekspaket log bereit, damit Pipeline-Worker Lognachrichten ausgeben können. Damit Sie die Bibliotheksfunktionen nutzen können, müssen Sie die Bibliothek importieren:
import "github.com/apache/beam/sdks/v2/go/pkg/beam/log"
Codebeispiel für Worker-Lognachrichten
Java
Das folgende Beispiel verwendet SLF4J für das Dataflow-Logging. Weitere Informationen zur Konfiguration von SLF4J für Dataflow-Logging finden Sie im Artikel Java-Tipps.
Das WordCount in Apache Beam kann so geändert werden, dass eine Lognachricht ausgegeben wird, wenn das Wort "love" in einer Zeile des verarbeiteten Texts gefunden wird. Der ergänzte Code ist im folgenden Beispiel fett dargestellt (der Code davor und danach zeigt den Kontext).
package org.apache.beam.examples; // Import SLF4J packages. import org.slf4j.Logger; import org.slf4j.LoggerFactory; ... public class WordCount { ... static class ExtractWordsFn extends DoFn<String, String> { // Instantiate Logger. // Suggestion: As shown, specify the class name of the containing class // (WordCount). private static final Logger LOG = LoggerFactory.getLogger(WordCount.class); ... @ProcessElement public void processElement(ProcessContext c) { ... // Output each word encountered into the output PCollection. for (String word : words) { if (!word.isEmpty()) { c.output(word); } // Log INFO messages when the word "love" is found. if(word.toLowerCase().equals("love")) { LOG.info("Found " + word.toLowerCase()); } } } } ... // Remaining WordCount example code ...
Python
Das Beispiel wordcount.py in Apache Beam kann so geändert werden, dass eine Lognachricht ausgegeben wird, wenn das Wort "love" in einer Zeile des verarbeiteten Texts gefunden wird.
# import Python logging module. import logging class ExtractWordsFn(beam.DoFn): def process(self, element): words = re.findall(r'[A-Za-z\']+', element) for word in words: yield word if word.lower() == 'love': # Log using the root logger at info or higher levels logging.info('Found : %s', word.lower()) # Remaining WordCount example code ...
Go
Das Beispiel wordcount.go in Apache Beam kann so geändert werden, dass eine Lognachricht ausgegeben wird, wenn das Wort „love“ in einer Zeile des verarbeiteten Texts gefunden wird.
func (f *extractFn) ProcessElement(ctx context.Context, line string, emit func(string)) { for _, word := range wordRE.FindAllString(line, -1) { // increment the counter for small words if length of words is // less than small_word_length if strings.ToLower(word) == "love" { log.Infof(ctx, "Found : %s", strings.ToLower(word)) } emit(word) } } // Remaining Wordcount example
Java
Wenn die geänderte WordCount-Pipeline lokal mit dem standardmäßigen DirectRunner ausgeführt und die Ausgabe an eine lokale Datei (--output=./local-wordcounts) gesendet wird, enthält die Konsolenausgabe die hinzugefügten Lognachrichten:
INFO: Executing pipeline using the DirectRunner. ... Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love ... INFO: Pipeline execution complete.
Standardmäßig werden nur Log-Zeilen mit der Kennzeichnung INFO und höher an Cloud Logging gesendet. Wenn Sie dies ändern möchten, finden Sie weitere Informationen unter Logebenen für Pipeline-Worker festlegen.
Python
Wenn die geänderte WordCount-Pipeline lokal mit dem standardmäßigen DirectRunner ausgeführt und die Ausgabe an eine lokale Datei (--output=./local-wordcounts) gesendet wird, enthält die Konsolenausgabe die hinzugefügten Lognachrichten:
INFO:root:Found : love INFO:root:Found : love INFO:root:Found : love
Standardmäßig werden nur Log-Zeilen mit der Kennzeichnung INFO und höher an Cloud Logging gesendet.
Go
Wenn die geänderte WordCount-Pipeline lokal mit dem standardmäßigen DirectRunner ausgeführt und die Ausgabe an eine lokale Datei (--output=./local-wordcounts) gesendet wird, enthält die Konsolenausgabe die hinzugefügten Lognachrichten:
2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love
Standardmäßig werden nur Log-Zeilen mit der Kennzeichnung INFO und höher an Cloud Logging gesendet.
Logvolumen steuern
Sie können auch das Volumen der generierten Logs reduzieren, indem Sie die Log-Ebenen der Pipeline ändern. Wenn Sie einige oder alle Dataflow-Logs nicht weiter aufnehmen möchten, fügen Sie einen Logging-Ausschluss hinzu, um Dataflow-Logs auszuschließen. Exportieren Sie die Logs dann an ein anderes Ziel wie BigQuery, Cloud Storage oder Pub/Sub. Weitere Informationen finden Sie unter Dataflow-Logaufnahme steuern.
Logging-Limit und Drosselung
Worker-Log-Nachrichten sind auf 15.000 Nachrichten alle 30 Sekunden pro Worker beschränkt. Wenn dieses Limit erreicht wird, wird eine einzelne Worker-Lognachricht hinzugefügt, die besagt, dass das Logging gedrosselt wird:
Throttling logger worker. It used up its 30s quota for logs in only 12.345s
Logspeicherung und -aufbewahrung
Betriebslogs werden im Log-Bucket _Default gespeichert.
Der Name des Logging API-Dienstes lautet dataflow.googleapis.com. Weitere Informationen zu den in Cloud Logging verwendeten überwachten Ressourcentypen und Diensten finden Sie unter Überwachte Ressourcen und Dienste.
Ausführliche Informationen zur Aufbewahrungsdauer der Logeinträge in Logging finden Sie unter Kontingente und Limits: Aufbewahrungsdauer für Logs.
Informationen zum Aufrufen von Betriebslogs finden Sie unter Pipelinelogs überwachen und ansehen.
Pipeline-Logs überwachen und ansehen
Wenn Sie Ihre Pipeline mit dem Dataflow-Dienst ausführen, können Sie mit der Dataflow-Monitoring-Oberfläche Logs ansehen, die von der Pipeline ausgegeben werden.
Beispiel für ein Dataflow-Worker-Log
Die geänderte WordCount-Pipeline kann in der Cloud mit den folgenden Optionen ausgeführt werden:
Java
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --tempLocation=gs://<bucket-name>/temp --stagingLocation=gs://<bucket-name>/binaries
Python
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Go
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Logs ansehen
Weil die WordCount-Cloud-Pipeline Blocking-Ausführung verwendet, werden Konsolennachrichten während der Pipelineausführung ausgegeben. Nachdem der Job gestartet wurde, wird ein Link zur Google Cloud Console-Seite an die Konsole ausgegeben, gefolgt von der Pipeline-Job-ID:
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/dataflow/job/2017-04-13_13_58_10-6217777367720337669 Submitted job: 2017-04-13_13_58_10-6217777367720337669
Die Console-URL führt zur Monitoring-Oberfläche von Dataflow. Dort wird eine Zusammenfassung des übermittelten Jobs angezeigt. Links ist eine dynamische Ausführungsgrafik dargestellt und rechts sind die zusammengefassten Informationen: Klicken Sie im unteren Bereich auf keyboard_capslock, um das Logfeld zu maximieren.
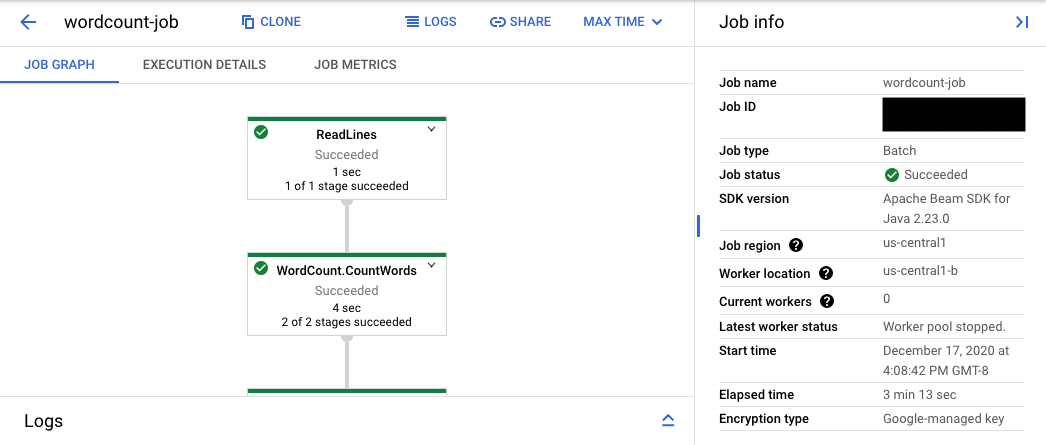
Im Logbereich werden standardmäßig Joblogs angezeigt, die den Status des Jobs insgesamt angeben. Sie können die im Logbereich angezeigten Nachrichten filtern. Klicken Sie dazu auf Infoarrow_drop_down und filter_listLogs filtern.
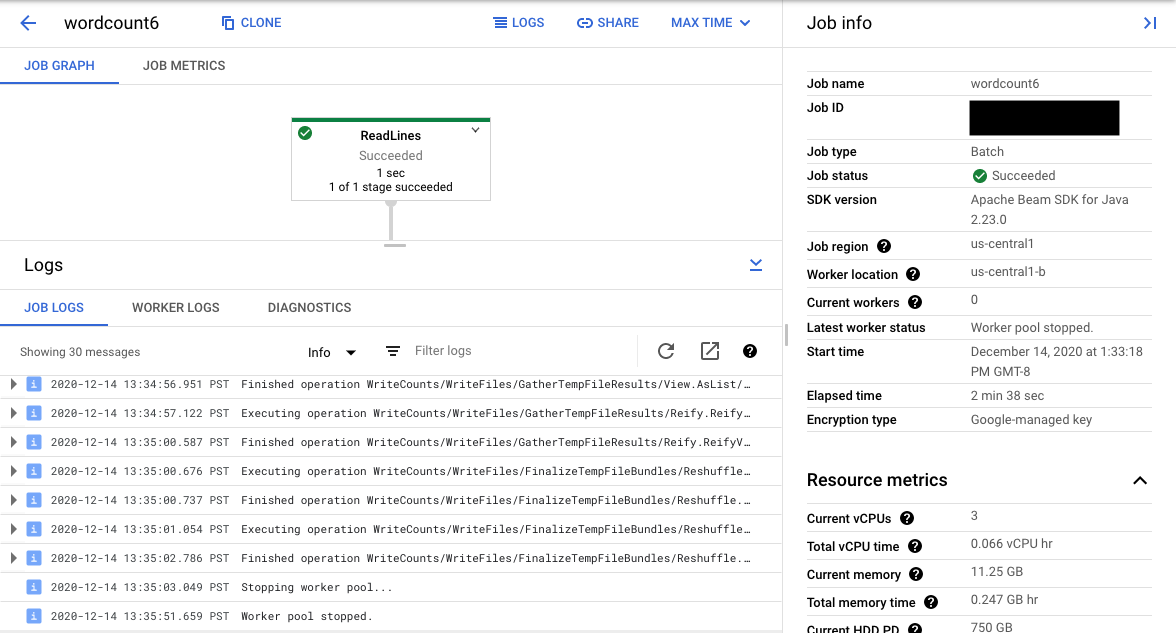
Durch Auswählen eines Pipelineschritts in der Grafik wird die Ansicht so geändert, dass sie die durch den Code generierten Logs für diesen Schritt und den generierten Code anzeigt, der in dem Pipelineschritt ausgeführt wird.
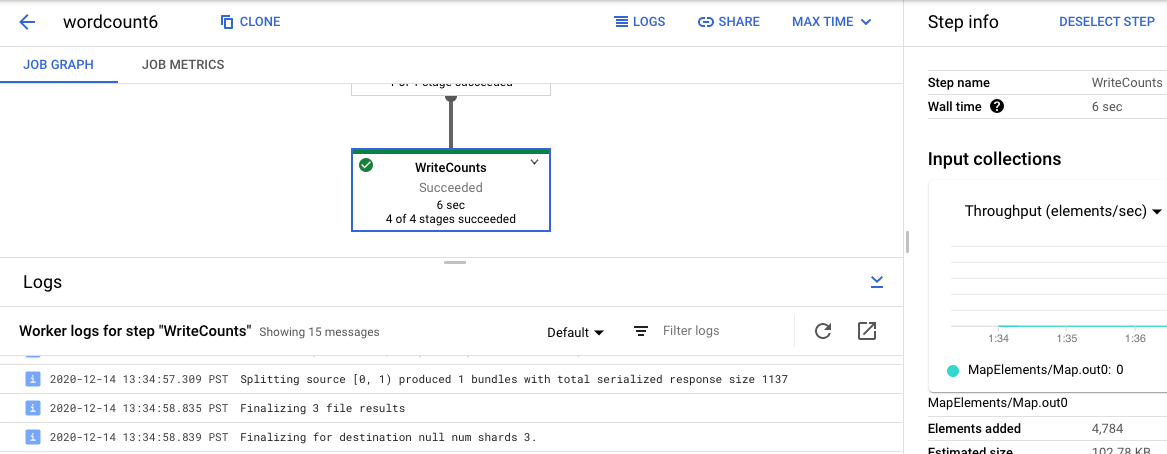
Wenn Sie wieder zu den Joblogs wechseln möchten, schließen Sie die Ansicht des Schritts. Klicken Sie dazu außerhalb der Grafik oder verwenden Sie die Schaltfläche Ausgewählten Schritt aufheben im rechten Fensterbereich.
Log-Explorer aufrufen
Klicken Sie im Logbereich auf Im Log-Explorer aufrufen (Schaltfläche für den externen Link), um den Log-Explorer zu öffnen und verschiedene Logtypen auszuwählen.
Klicken Sie im Log-Explorer auf die Ein-/Aus-Schaltfläche Logfelder, um das Feld mit verschiedenen Logtypen aufzurufen.
Auf der Seite „Log-Explorer“ können die Logs durch die Abfrage nach Jobschritt oder Logtyp gefiltert werden. Wenn Sie Filter entfernen möchten, klicken Sie auf die Ein-/Aus-Schaltfläche Abfrage anzeigen und bearbeiten Sie die Abfrage.
So rufen Sie alle für einen Job verfügbaren Logs auf:
Geben Sie im Feld Query die folgende Abfrage ein:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID"Ersetzen Sie JOB_ID durch die ID Ihrer Jobs.
Klicken Sie auf Abfrage ausführen.
Wenn Sie diese Abfrage verwenden und keine Logs für Ihren Job sehen, klicken Sie auf Zeit bearbeiten.
Passen Sie Beginn und Ende an und klicken Sie dann auf Übernehmen.
Logtypen
Der Log-Explorer enthält auch Infrastrukturlogs für eine Pipeline. Verwenden Sie Fehler- und Warnlogs, um beobachtete Pipelineprobleme zu diagnostizieren. Fehler und Warnungen in den Infrastrukturlogs, die nicht mit einem Pipelineproblem korrelieren, weisen nicht unbedingt auf ein Problem hin.
Hier finden Sie eine Zusammenfassung der verschiedenen Logtypen, die auf der Seite Log-Explorer angezeigt werden können:
- Job-Message-Logs enthalten Jobnachrichten, die von verschiedenen Komponenten von Dataflow generiert werden. Beispiele hierfür sind die automatische Skalierungskonfiguration beim Starten oder Herunterfahren von Workern, der Fortschritt des Jobschritts und Jobfehler. Fehler auf Worker-Ebene, die durch einen Absturz des Nutzercodes verursacht wurden und in Worker-Logs vorhanden sind, werden auch in die job-message-Logs übertragen.
- Worker-Logs werden von Dataflow-Workern erstellt. Worker erledigen die meisten Pipelineaufgaben. Sie wenden z. B.
ParDoauf Daten an. Worker-Logs enthalten von Ihrem Code und von Dataflow erfasste Nachrichten. - Worker-Startup-Logs sind in den meisten Dataflow-Jobs vorhanden und erfassen mit dem Startvorgang zusammenhängende Nachrichten. Dieser umfasst das Herunterladen der JAR-Dateien des Jobs aus Cloud Storage und das anschließende Starten der Worker. Bei Problemen mit dem Worker-Start können diese Logs aufschlussreich sein.
- shuffler-Logs enthalten Nachrichten von Workern, die die Ergebnisse paralleler Pipelineoperationen konsolidieren.
- System-Logs enthalten Nachrichten von den Hostbetriebssystemen von Worker-VMs. In einigen Szenarien können sie Prozessabstürze oder OOM-Ereignisse (Out-of-Memory) erfassen.
- Docker- und Kubelet-Logs enthalten Nachrichten, die mit diesen öffentlichen Technologien in Zusammenhang stehen und für Dataflow-Worker genutzt werden.
- nvidia-mps-Logs enthalten Nachrichten zu NVIDIA Multi-Process-Dienst-Vorgängen (MPS).
Logebenen für Pipeline-Worker festlegen
Java
Als standardmäßige SLF4J-Log-Ebene für Worker wird vom Apache Beam SDK for Java INFO festgelegt. Daher werden alle Lognachrichten mit der Kennzeichnung INFO oder höher (INFO, WARN, ERROR) ausgegeben. Sie können eine andere Standard-Log-Ebene festlegen, um niedrigere SLF4J-Log-Ebenen (TRACE oder DEBUG) zu unterstützen, oder verschiedene Log-Ebenen für unterschiedliche Klassenpakete in Ihrem Code einrichten.
Mit den folgenden Pipelineoptionen können Sie Worker-Logebenen über die Befehlszeile oder programmatisch festlegen:
--defaultSdkHarnessLogLevel=<level>: Verwenden Sie diese Option, um alle Logger auf die angegebene Standardebene festzulegen. Die folgende Befehlszeilenoption überschreibt beispielsweise die Standard-Log-Ebenen von DataflowINFOund legt sie aufDEBUG:
--defaultSdkHarnessLogLevel=DEBUGfest.--sdkHarnessLogLevelOverrides={"<package or class>":"<level>"}: Verwenden Sie diese Option, um die Log-Ebene für bestimmte Pakete oder Klassen vorzugeben. Die Standard-Log-Ebene der Pipeline für das Paketorg.apache.beam.runners.dataflowkönnen Sie beispielsweise so überschreiben und aufTRACEfestlegen:
--sdkHarnessLogLevelOverrides='{"org.apache.beam.runners.dataflow":"TRACE"}'
Um mehrere Überschreibungen durchzuführen, stellen Sie eine JSON-Zuordnung bereit:
(--sdkHarnessLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...}).- Die Pipelineoptionen
defaultSdkHarnessLogLevelundsdkHarnessLogLevelOverrideswerden für Pipelines, die die Apache Beam SDK-Versionen 2.50.0 und früher ohne Runner v2 verwenden, nicht unterstützt. Verwenden Sie in diesem Fall die Pipelineoptionen--defaultWorkerLogLevel=<level>und--workerLogLevelOverrides={"<package or class>":"<level>"}. Wenn Sie mehrere Überschreibungen vornehmen möchten, geben Sie eine JSON-Zuordnung an:
(--workerLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})
Im folgenden Beispiel werden Pipeline-Logging-Optionen programmatisch mit Standardwerten eingerichtet, die über die Befehlszeile überschrieben werden können:
PipelineOptions options = ... SdkHarnessOptions loggingOptions = options.as(SdkHarnessOptions.class); // Overrides the default log level on the worker to emit logs at TRACE or higher. loggingOptions.setDefaultSdkHarnessLogLevel(LogLevel.TRACE); // Overrides the Foo class and "org.apache.beam.runners.dataflow" package to emit logs at WARN or higher. loggingOptions.getSdkHarnessLogLevelOverrides() .addOverrideForClass(Foo.class, LogLevel.WARN) .addOverrideForPackage(Package.getPackage("org.apache.beam.runners.dataflow"), LogLevel.WARN);
Python
Als standardmäßige Logging-Ebene für Worker wird vom Apache Beam SDK for Python INFO festgelegt. Daher werden alle Lognachrichten mit der Kennzeichnung INFO oder höher (INFO, WARNING, ERROR, CRITICAL) ausgegeben.
Sie können eine andere Standard-Logebene festlegen, um niedrigere Logging-Ebenen (DEBUG) zu unterstützen, oder verschiedene Logebenen für unterschiedliche Module in Ihrem Code festlegen.
Es gibt zwei Pipelineoptionen, um Worker-Logebenen über die Befehlszeile oder programmatisch festzulegen:
--default_sdk_harness_log_level=<level>: Verwenden Sie diese Option, um alle Logger auf die angegebene Standardebene festzulegen. Die folgende Befehlszeilenoption überschreibt beispielsweise die Standard-Logebene von DataflowINFOund legt sie aufDEBUG:
--default_sdk_harness_log_level=DEBUGfest.--sdk_harness_log_level_overrides={\"<module>\":\"<level>\"}: Verwenden Sie diese Option, um die Log-Ebene für bestimmte Module vorzugeben. Die Standard-Log-Ebene der Pipeline für das Modulapache_beam.runners.dataflowkönnen Sie beispielsweise so überschreiben und aufDEBUGfestlegen:
--sdk_harness_log_level_overrides={\"apache_beam.runners.dataflow\":\"DEBUG\"}
Um mehrere Überschreibungen durchzuführen, stellen Sie eine JSON-Zuordnung bereit:
(--sdk_harness_log_level_overrides={\"<module>\":\"<level>\",\"<module>\":\"<level>\",...}).
Im folgenden Beispiel wird die Klasse WorkerOptions verwendet, um Pipeline-Logging-Optionen programmatisch festzulegen, die über die Befehlszeile überschrieben werden können:
from apache_beam.options.pipeline_options import PipelineOptions, WorkerOptions pipeline_args = [ '--project=PROJECT_NAME', '--job_name=JOB_NAME', '--staging_location=gs://STORAGE_BUCKET/staging/', '--temp_location=gs://STORAGE_BUCKET/tmp/', '--region=DATAFLOW_REGION', '--runner=DataflowRunner' ] pipeline_options = PipelineOptions(pipeline_args) worker_options = pipeline_options.view_as(WorkerOptions) worker_options.default_sdk_harness_log_level = 'WARNING' # Note: In Apache Beam SDK 2.42.0 and earlier versions, use ['{"apache_beam.runners.dataflow":"WARNING"}'] worker_options.sdk_harness_log_level_overrides = {"apache_beam.runners.dataflow":"WARNING"} # Pass in pipeline options during pipeline creation. with beam.Pipeline(options=pipeline_options) as pipeline:
Dabei gilt:
PROJECT_NAMEist der Name des Projekts.JOB_NAME: Der Name des Jobs.STORAGE_BUCKET: der Cloud Storage-NameDATAFLOW_REGION: die Region, in der Sie den Dataflow-Job bereitstellen möchtenDas Flag
--regionüberschreibt die Standardregion, die auf dem Metadatenserver, auf Ihrem lokalen Client oder in Umgebungsvariablen festgelegt ist.
Go
Diese Funktion ist derzeit im Apache Beam SDK for Go nicht verfügbar.
Log von gestarteten BigQuery-Jobs aufrufen
Wenn Sie BigQuery in Ihrer Dataflow-Pipeline verwenden, werden BigQuery-Jobs gestartet, um verschiedene Aktionen für Sie auszuführen. Diese Aktionen können das Laden von Daten, das Exportieren von Daten usw. umfassen. Weitere Informationen zu Fehlerbehebung und Monitoring dieser BigQuery-Jobs finden Sie in der Dataflow-Monitoring-Oberfläche unter Logs.
Die BigQuery-Jobinformationen, die im Bereich Logs angezeigt werden, werden in einer BigQuery-Systemtabelle gespeichert und geladen. Abrechnungskosten fallen an, wenn die zugrunde liegende BigQuery-Tabelle abgefragt wird.
BigQuery-Jobdetails aufrufen
Zur Anzeige der BigQuery-Jobinformationen muss Ihre Pipeline Apache Beam 2.24.0 oder höher verwenden.
Zum Auflisten der BigQuery-Jobs öffnen Sie den Tab BigQuery-Jobs und wählen den Speicherort der BigQuery-Jobs aus. Klicken Sie dann auf BigQuery-Jobs laden und bestätigen Sie das Dialogfeld. Nach Abschluss der Abfrage wird die Jobliste angezeigt.
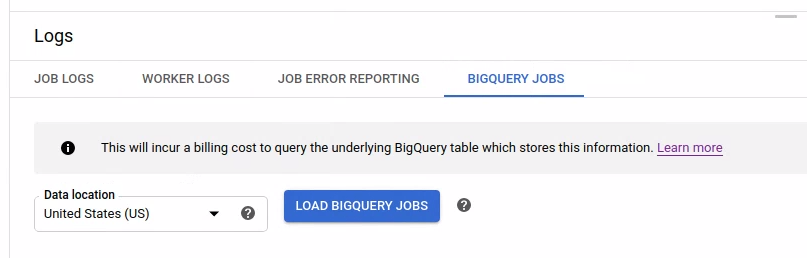
Es werden grundlegende Informationen zu jedem Job bereitgestellt, einschließlich der Job-ID, des Typs, der Dauer usw.
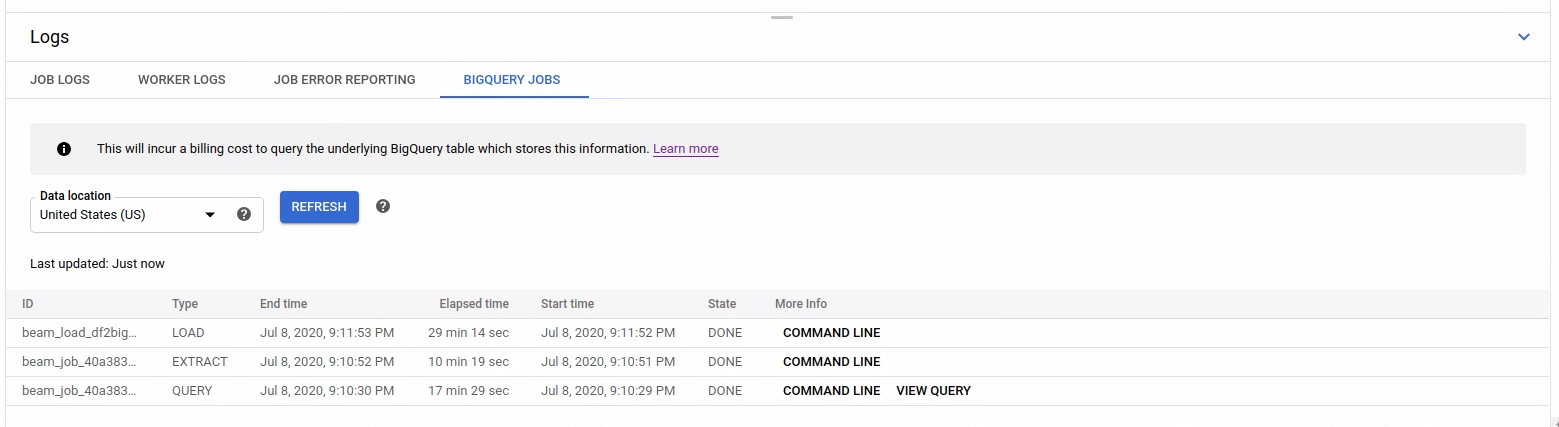
Weitere Informationen zu einem bestimmten Job erhalten Sie, wenn Sie in der Spalte Weitere Informationen auf Befehlszeile klicken.
Kopieren Sie im modalen Fenster für die Befehlszeile den Befehl bq jobs describe und führen Sie ihn lokal oder in Cloud Shell aus.
gcloud alpha bq jobs describe BIGQUERY_JOB_ID
Der Befehl bq jobs describe gibt JobStatistics aus. Sie erhalten damit weitere Details, die bei der Diagnose eines langsamen oder hängenden BigQuery-Jobs hilfreich sind.
Wenn Sie alternativ BigQueryIO mit einer SQL-Abfrage verwenden, wird ein Abfragejob ausgegeben. Klicken Sie in der Spalte Weitere Informationen auf Suchanfrage anzeigen, um die vom Job verwendete SQL-Abfrage aufzurufen.