Jika Anda mengalami masalah dengan pipeline atau tugas Dataflow, halaman ini akan mencantumkan pesan error yang mungkin Anda lihat dan memberikan saran tentang cara memperbaiki setiap error.
Error dalam jenis log dataflow.googleapis.com/worker-startup,
dataflow.googleapis.com/harness-startup, dan dataflow.googleapis.com/kubelet
menunjukkan masalah konfigurasi pada suatu tugas. Parameter ini juga dapat menunjukkan kondisi
yang mencegah jalur logging normal berfungsi.
Pipeline Anda mungkin menampilkan pengecualian saat memproses data. Beberapa error ini bersifat sementara, misalnya saat terjadi kesulitan sementara saat mengakses layanan eksternal. Beberapa error ini bersifat permanen, seperti error yang disebabkan oleh data input yang rusak atau tidak dapat diurai, atau pointer null selama komputasi.
Dataflow memproses elemen dalam paket arbitrer dan mencoba ulang paket lengkap saat error ditampilkan untuk elemen apa pun dalam paket tersebut. Saat berjalan dalam mode batch, paket yang berisi item yang gagal akan dicoba ulang empat kali. Pipeline gagal sepenuhnya ketika satu bundle gagal sebanyak empat kali. Saat berjalan dalam mode streaming, paket yang berisi item yang gagal akan dicoba ulang tanpa batas waktu, yang dapat menyebabkan pipeline Anda berhenti secara permanen.
Pengecualian dalam kode pengguna, misalnya, instance DoFn, dilaporkan dalam
Antarmuka pemantauan Dataflow.
Jika menjalankan pipeline dengan BlockingDataflowPipelineRunner, Anda juga akan melihat pesan error yang dicetak di jendela konsol atau terminal.
Pertimbangkan untuk melindungi dari error dalam kode Anda dengan menambahkan pengendali pengecualian. Misalnya, jika Anda ingin menghapus elemen yang gagal dalam validasi input kustom
yang dilakukan di ParDo, gunakan blok try/catch dalam ParDo untuk menangani
pengecualian serta mencatat log dan menghapus elemen. Untuk beban kerja produksi, implementasikan pola pesan yang belum diproses. Untuk melacak jumlah error, Anda menggunakan
transformasi agregasi.
File log tidak ada
Jika log untuk tugas Anda tidak terlihat, hapus filter pengecualian yang berisi resource.type="dataflow_step" dari semua sink Router Log Cloud Logging.
Untuk mengetahui detail selengkapnya tentang cara menghapus pengecualian log, lihat panduan Menghapus pengecualian.
Error pipeline
Bagian berikut berisi error pipeline umum yang mungkin Anda alami serta langkah-langkah untuk menyelesaikan atau memecahkan masalah error tersebut.
Beberapa Cloud API perlu diaktifkan
Saat Anda mencoba menjalankan tugas Dataflow, error berikut akan terjadi:
Some Cloud APIs need to be enabled for your project in order for Cloud Dataflow to run this job.
Masalah ini terjadi karena beberapa API yang diperlukan tidak diaktifkan di project Anda.
Untuk mengatasi masalah ini dan menjalankan tugas Dataflow, aktifkan Google Cloud API berikut di project Anda:
- API Compute Engine (Compute Engine)
- Cloud Logging API
- Cloud Storage
- Cloud Storage JSON API
- BigQuery API
- Pub/Sub
- Datastore API
Untuk petunjuk mendetail, lihat bagian Memulai tentang mengaktifkan Google Cloud API .
"@*" dan "@N" adalah spesifikasi sharding yang dicadangkan
Saat Anda mencoba menjalankan tugas, error berikut akan muncul dalam file log, dan tugas tersebut gagal:
Workflow failed. Causes: "@*" and "@N" are reserved sharding specs. Filepattern must not contain any of them.
Error ini terjadi jika nama file untuk jalur Cloud Storage Anda untuk file sementara (tempLocation atau temp_location) memiliki tanda at (@) yang diikuti dengan angka atau tanda bintang (*).
Untuk mengatasi masalah ini, ubah nama file sehingga tanda @ diikuti dengan karakter yang didukung.
Permintaan yang buruk
Saat Anda menjalankan tugas Dataflow, log Cloud Monitoring akan menampilkan serangkaian peringatan yang serupa dengan berikut ini:
Unable to update setup work item STEP_ID error: generic::invalid_argument: Http(400) Bad Request
Update range task returned 'invalid argument'. Assuming lost lease for work with id LEASE_ID
with expiration time: TIMESTAMP, now: TIMESTAMP. Full status: generic::invalid_argument: Http(400) Bad Request
Peringatan permintaan yang buruk terjadi jika informasi status pekerja sudah tidak berlaku atau tidak sinkron karena penundaan pemrosesan. Sering kali, tugas Dataflow Anda berhasil meskipun ada peringatan permintaan yang buruk. Jika demikian, abaikan peringatan.
Tidak dapat membaca dan menulis di lokasi yang berbeda
Saat menjalankan tugas Dataflow, Anda mungkin melihat error berikut dalam file log:
message:Cannot read and write in different locations: source: SOURCE_REGION, destination: DESTINATION_REGION,reason:invalid
Error ini terjadi jika sumber dan tujuan berada di region yang berbeda. Error ini juga dapat terjadi saat lokasi dan tujuan staging berada di region yang berbeda. Misalnya, jika tugas dibaca dari Pub/Sub, lalu menulis ke bucket temp Cloud Storage sebelum menulis ke tabel BigQuery, bucket temp Cloud Storage dan tabel BigQuery harus berada di region yang sama.
Lokasi multi-region dianggap berbeda dari lokasi satu region, meskipun jika satu region berada dalam cakupan lokasi multi-region.
Misalnya, us (multiple regions in the United States) dan us-central1 adalah region yang berbeda.
Untuk mengatasi masalah ini, tempatkan lokasi tujuan, sumber, dan staging di region yang sama. Lokasi bucket Cloud Storage tidak dapat diubah, sehingga Anda mungkin perlu membuat bucket Cloud Storage baru di region yang benar.
Waktu koneksi habis
Saat menjalankan tugas Dataflow, Anda mungkin melihat error berikut dalam file log:
org.springframework.web.client.ResourceAccessException: I/O error on GET request for CONNECTION_PATH: Connection timed out (Connection timed out); nested exception is java.net.ConnectException: Connection timed out (Connection timed out)
Masalah ini terjadi saat pekerja Dataflow gagal membuat atau mempertahankan koneksi dengan sumber data atau tujuan.
Untuk mengatasi masalah tersebut, ikuti langkah-langkah pemecahan masalah berikut:
- Pastikan sumber data sedang berjalan.
- Pastikan tujuan sedang berjalan.
- Tinjau parameter koneksi yang digunakan dalam konfigurasi pipeline Dataflow.
- Pastikan masalah performa tidak memengaruhi sumber atau tujuan.
- Pastikan aturan firewall tidak memblokir koneksi.
Objek tersebut tidak ada
Saat menjalankan tugas Dataflow, Anda mungkin melihat error berikut dalam file log:
..., 'server': 'UploadServer', 'status': '404'}>, <content <No such object:...
Error ini biasanya terjadi ketika beberapa tugas Dataflow yang sedang berjalan menggunakan temp_location yang sama untuk melakukan staging file tugas sementara yang dibuat saat pipeline berjalan. Jika beberapa tugas serentak memiliki temp_location yang sama,
tugas ini mungkin menginjak data sementara satu sama lain, dan kondisi race mungkin
terjadi. Untuk menghindari masalah ini, sebaiknya gunakan temp_location
yang unik untuk setiap tugas.
Dataflow tidak dapat menentukan backlog
Saat menjalankan pipeline streaming dari Pub/Sub, peringatan berikut akan terjadi:
Dataflow is unable to determine the backlog for Pub/Sub subscription
Saat pipeline Dataflow mengambil data dari Pub/Sub, Dataflow harus berulang kali meminta informasi dari Pub/Sub. Informasi ini mencakup jumlah backlog pada langganan dan usia pesan terlama yang tidak dikonfirmasi. Terkadang, Dataflow tidak dapat mengambil informasi ini dari Pub/Sub karena masalah sistem internal, yang dapat menyebabkan akumulasi backlog sementara.
Untuk mengetahui informasi selengkapnya, lihat Streaming Dengan Cloud Pub/Sub.
DEADLINE_EXCEEDED atau Server Tidak Responsif
Saat menjalankan tugas, Anda mungkin menemukan pengecualian waktu tunggu RPC atau salah satu error berikut:
DEADLINE_EXCEEDED
Atau:
Server Unresponsive
Error ini biasanya terjadi karena salah satu alasan berikut:
Jaringan Virtual Private Cloud (VPC) yang digunakan untuk tugas Anda mungkin tidak memiliki aturan firewall. Aturan firewall harus mengaktifkan semua traffic TCP di antara VM di jaringan VPC yang Anda tentukan di opsi pipeline. Untuk mengetahui informasi lebih lanjut, baca Aturan firewall untuk Dataflow.
Terkadang, pekerja tidak dapat berkomunikasi satu sama lain. Saat Anda menjalankan tugas Dataflow yang tidak menggunakan Dataflow Shuffle atau Streaming Engine, pekerja harus berkomunikasi satu sama lain menggunakan port TCP
12345dan12346dalam jaringan VPC. Dalam skenario ini, error mencakup nama harness pekerja dan port TCP yang diblokir. Error akan terlihat seperti salah satu contoh berikut:DEADLINE_EXCEEDED: (g)RPC timed out when SOURCE_WORKER_HARNESS talking to DESTINATION_WORKER_HARNESS:12346.Rpc to WORKER_HARNESS:12345 completed with error UNAVAILABLE: failed to connect to all addresses Server unresponsive (ping error: Deadline Exceeded, UNKNOWN: Deadline Exceeded...)Untuk mengatasi masalah ini, gunakan flag rules
gcloud compute firewall-rules createuntuk mengizinkan traffic jaringan ke port12345dan12346. Contoh berikut menunjukkan perintah Google Cloud CLI:gcloud compute firewall-rules create FIREWALL_RULE_NAME \ --network NETWORK \ --action allow \ --direction IN \ --target-tags dataflow \ --source-tags dataflow \ --priority 0 \ --rules tcp:12345-12346Ganti kode berikut:
FIREWALL_RULE_NAME: nama aturan firewall AndaNETWORK: nama jaringan Anda
Tugas Anda terikat secara acak.
Untuk mengatasi masalah ini, buat satu atau beberapa perubahan berikut.
Java
- Jika tugas tidak menggunakan shuffle berbasis layanan, beralihlah untuk menggunakan Dataflow Shuffle berbasis layanan dengan menetapkan
--experiments=shuffle_mode=service. Untuk mengetahui detail dan ketersediaan, lihat Dataflow Shuffle. - Tambahkan lebih banyak pekerja. Coba tetapkan
--numWorkersdengan nilai yang lebih tinggi saat Anda menjalankan pipeline. - Tingkatkan ukuran disk yang terpasang untuk pekerja. Coba tetapkan
--diskSizeGbdengan nilai yang lebih tinggi saat Anda menjalankan pipeline. - Gunakan persistent disk yang didukung SSD. Coba tetapkan
--workerDiskType="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"saat Anda menjalankan pipeline.
Python
- Jika tugas tidak menggunakan shuffle berbasis layanan, beralihlah untuk menggunakan Dataflow Shuffle berbasis layanan dengan menetapkan
--experiments=shuffle_mode=service. Untuk mengetahui detail dan ketersediaan, lihat Dataflow Shuffle. - Tambahkan lebih banyak pekerja. Coba tetapkan
--num_workersdengan nilai yang lebih tinggi saat Anda menjalankan pipeline. - Tingkatkan ukuran disk yang terpasang untuk pekerja. Coba tetapkan
--disk_size_gbdengan nilai yang lebih tinggi saat Anda menjalankan pipeline. - Gunakan persistent disk yang didukung SSD. Coba tetapkan
--worker_disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"saat Anda menjalankan pipeline.
Go
- Jika tugas tidak menggunakan shuffle berbasis layanan, beralihlah untuk menggunakan Dataflow Shuffle berbasis layanan dengan menetapkan
--experiments=shuffle_mode=service. Untuk mengetahui detail dan ketersediaan, lihat Dataflow Shuffle. - Tambahkan lebih banyak pekerja. Coba tetapkan
--num_workersdengan nilai yang lebih tinggi saat Anda menjalankan pipeline. - Tingkatkan ukuran disk yang terpasang untuk pekerja. Coba tetapkan
--disk_size_gbdengan nilai yang lebih tinggi saat Anda menjalankan pipeline. - Gunakan persistent disk yang didukung SSD. Coba tetapkan
--disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"saat Anda menjalankan pipeline.
- Jika tugas tidak menggunakan shuffle berbasis layanan, beralihlah untuk menggunakan Dataflow Shuffle berbasis layanan dengan menetapkan
Error encoding, IOException, atau perilaku tidak terduga dalam kode pengguna
Apache Beam SDK dan pekerja Dataflow bergantung pada komponen pihak ketiga umum. Komponen ini mengimpor dependensi tambahan. Bentrok versi dapat mengakibatkan perilaku yang tidak terduga dalam layanan. Selain itu, beberapa {i>library<i} tidak kompatibel dengan versi baru. Anda mungkin perlu menyematkan ke versi tercantum yang berada dalam cakupan selama eksekusi. Dependensi SDK dan Pekerja berisi daftar dependensi dan versi yang diperlukan.
Terjadi error saat menjalankan LookupEffectiveGuestPolicies
Saat menjalankan tugas Dataflow, Anda mungkin melihat error berikut dalam file log:
OSConfigAgent Error policies.go:49: Error running LookupEffectiveGuestPolicies:
error calling LookupEffectiveGuestPolicies: code: "Unauthenticated",
message: "Request is missing required authentication credential.
Expected OAuth 2 access token, login cookie or other valid authentication credential.
Error ini terjadi jika OS configuration management diaktifkan untuk seluruh project.
Untuk mengatasi masalah ini, nonaktifkan kebijakan Pengelola VM yang berlaku untuk seluruh project. Jika kebijakan VM Manager untuk seluruh project tidak dapat dinonaktifkan, Anda dapat mengabaikan error ini dengan aman dan mengecualikannya dari alat pemantauan log.
Kumpulan resource habis
Saat membuat resource Google Cloud, Anda mungkin melihat error berikut untuk kumpulan resource yang telah habis:
ERROR: ZONE_RESOURCE_POOL_EXHAUSTED
Error ini terjadi untuk kondisi stok habis sementara untuk resource tertentu di zona tertentu.
Untuk mengatasi masalah ini, Anda dapat menunggu atau membuat resource yang sama di zona lain. Sebagai praktik terbaik, sebaiknya distribusikan resource di beberapa zona dan region untuk menoleransi pemadaman layanan.
Error fatal telah terdeteksi oleh Java Runtime Environment
Error berikut terjadi selama startup pekerja:
A fatal error has been detected by the Java Runtime Environment
Error ini terjadi jika pipeline menggunakan Java Native Interface (JNI) untuk menjalankan kode non-Java dan kode atau binding JNI tersebut berisi error.
kesalahan kunci atribut googclient_deliveryattempt
Tugas Dataflow Anda gagal dengan salah satu error berikut:
The request contains an attribute key that is not valid (key=googclient_deliveryattempt). Attribute keys must be non-empty and must not begin with 'goog' (case-insensitive).
Atau:
Invalid extensions name: googclient_deliveryattempt
Error ini terjadi saat tugas Dataflow Anda memiliki karakteristik berikut:
- Tugas Dataflow menggunakan Streaming Engine.
- Pipeline memiliki sink Pub/Sub.
- Pipeline menggunakan langganan pull.
- Pipeline menggunakan salah satu API layanan Pub/Sub untuk memublikasikan pesan, bukan menggunakan sink I/O Pub/Sub bawaan.
- Pub/Sub menggunakan library klien Java atau C#.
- Langganan Pub/Sub memiliki topik yang dihentikan pengirimannya.
Error ini terjadi karena saat Anda menggunakan library klien Pub/Sub Java atau C#
dan topik yang dihentikan pengirimannya untuk langganan diaktifkan, upaya
pengiriman berada dalam atribut pesan googclient_deliveryattempt, bukan
kolom delivery_attempt. Untuk informasi selengkapnya, lihat Melacak upaya pengiriman di halaman "Menangani kegagalan pesan".
Untuk mengatasi masalah ini, buat satu atau beberapa perubahan berikut.
- Nonaktifkan Streaming Engine.
- Gunakan konektor
PubSubIOApache Beam bawaan, bukan Pub/Sub Service API. - Gunakan jenis langganan Pub/Sub yang berbeda.
- Hapus topik yang dihentikan pengirimannya.
- Jangan gunakan library klien Java atau C# dengan langganan pull Pub/Sub Anda. Untuk opsi lainnya, lihat Contoh kode library klien.
- Di kode pipeline, jika kunci atribut diawali dengan
goog, hapus atribut pesan sebelum memublikasikan pesan.
Hot key ... terdeteksi
Terjadi error berikut:
A hot key HOT_KEY_NAME was detected in...
Error ini terjadi jika data Anda berisi hot key. Hot key adalah kunci dengan elemen yang cukup untuk memberikan dampak negatif pada performa pipeline. Kunci-kunci ini membatasi kemampuan Dataflow untuk memproses elemen secara paralel, sehingga meningkatkan waktu eksekusi.
Untuk mencetak kunci yang dapat dibaca manusia ke log saat hot key terdeteksi di pipeline, gunakan opsi pipeline hot key.
Untuk mengatasi masalah ini, periksa apakah data Anda didistribusikan secara merata. Jika kunci memiliki banyak nilai yang tidak proporsional, pertimbangkan tindakan berikut:
- Mengenkripsi ulang data Anda. Terapkan transformasi
ParDountuk menghasilkan output key-value pair baru. - Untuk tugas Java, gunakan transformasi
Combine.PerKey.withHotKeyFanout. - Untuk tugas Python, gunakan transformasi
CombinePerKey.with_hot_key_fanout. - Aktifkan Dataflow Shuffle.
Untuk melihat hot key dalam antarmuka pemantauan Dataflow, lihat Memecahkan masalah straggler dalam tugas batch.
Spesifikasi tabel tidak valid di Data Catalog
Saat Anda menggunakan Dataflow SQL untuk membuat tugas Dataflow SQL, tugas Anda mungkin gagal dengan error berikut dalam file log:
Invalid table specification in Data Catalog: Could not resolve table in Data Catalog
Error ini terjadi jika akun layanan Dataflow tidak memiliki akses ke Data Catalog API.
Untuk mengatasi masalah ini, aktifkan Data Catalog API di project Google Cloud yang Anda gunakan untuk menulis dan menjalankan kueri.
Atau, tetapkan peran roles/datacatalog.viewer ke akun layanan Dataflow.
Grafik tugas terlalu besar
Tugas Anda mungkin gagal dengan error berikut:
The job graph is too large. Please try again with a smaller job graph,
or split your job into two or more smaller jobs.
Error ini terjadi jika ukuran grafik tugas Anda melebihi 10 MB. Kondisi tertentu dalam pipeline Anda dapat menyebabkan grafik tugas melebihi batas. Kondisi umum mencakup:
- Transformasi
Createyang menyertakan sejumlah besar data dalam memori. - Instance
DoFnbesar yang diserialisasi untuk transmisi ke pekerja jarak jauh. DoFnsebagai instance class dalam anonim yang (mungkin secara tidak sengaja) menarik data dalam jumlah besar untuk diserialisasi.- Direct acyclic graph (DAG) digunakan sebagai bagian dari loop terprogram yang menghitung daftar besar.
Untuk menghindari kondisi ini, pertimbangkan untuk menyusun ulang pipeline Anda.
Commit Kunci Terlalu Besar
Saat menjalankan tugas streaming, error berikut akan muncul dalam file log pekerja:
KeyCommitTooLargeException
Error ini terjadi dalam skenario streaming jika data dalam jumlah yang sangat besar
dikelompokkan tanpa menggunakan transformasi Combine, atau jika sejumlah besar data
dihasilkan dari satu elemen input.
Untuk mengurangi kemungkinan error ini terjadi, gunakan strategi berikut:
- Pastikan bahwa pemrosesan satu elemen tidak dapat mengakibatkan output atau modifikasi status melebihi batas.
- Jika beberapa elemen dikelompokkan berdasarkan kunci, sebaiknya perbesar ruang kunci untuk mengurangi elemen yang dikelompokkan per kunci.
- Jika elemen untuk kunci dimunculkan dengan frekuensi tinggi dalam waktu singkat, hal tersebut dapat mengakibatkan banyak GB peristiwa untuk tombol tersebut di jendela. Tulis ulang pipeline untuk mendeteksi kunci seperti ini dan hanya memunculkan output yang menunjukkan bahwa kunci sering ada di jendela tersebut.
- Gunakan transformasi
Combineruang sublinear untuk operasi komutatif dan atribusi. Jangan gunakan penggabung jika tidak mengurangi ruang. Misalnya, penggabung untuk string yang hanya menambahkan string secara bersamaan lebih buruk daripada tidak menggunakan penggabung.
Menolak pesan senilai lebih dari 7168 ribu
Saat Anda menjalankan tugas Dataflow yang dibuat dari template, tugas mungkin gagal dengan error berikut:
Error: CommitWork failed: status: APPLICATION_ERROR(3): Pubsub publish requests are limited to 10MB, rejecting message over 7168K (size MESSAGE_SIZE) to avoid exceeding limit with byte64 request encoding.
Error ini terjadi saat pesan yang ditulis ke antrean mati melebihi batas ukuran 7168 K. Sebagai solusinya, aktifkan Streaming Engine, yang memiliki batas ukuran yang lebih tinggi. Untuk mengaktifkan Streaming Engine, gunakan opsi pipeline berikut.
Java
--enableStreamingEngine=true
Python
--enable_streaming_engine=true
Request Entity Too Large
Saat mengirimkan tugas, salah satu error berikut akan muncul di jendela konsol atau terminal Anda:
413 Request Entity Too Large
The size of serialized JSON representation of the pipeline exceeds the allowable limit
Failed to create a workflow job: Invalid JSON payload received
Failed to create a workflow job: Request payload exceeds the allowable limit
Jika Anda mengalami error tentang payload JSON saat mengirimkan tugas, representasi JSON dari pipeline Anda melebihi ukuran permintaan maksimum sebesar 20 MB.
Ukuran tugas Anda terikat dengan representasi JSON dari pipeline. Pipeline yang lebih besar berarti permintaan yang lebih besar. Dataflow memiliki batasan yang membatasi permintaan sebesar 20 MB.
Untuk memperkirakan ukuran permintaan JSON dari pipeline Anda, jalankan pipeline dengan opsi berikut:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Output tugas Anda sebagai JSON tidak didukung di Go.
Perintah ini menulis representasi JSON dari tugas Anda ke file. Ukuran file yang diserialisasi adalah perkiraan yang baik untuk ukuran permintaan. Ukuran sebenarnya sedikit lebih besar karena beberapa informasi tambahan yang disertakan dalam permintaan ini.
Kondisi tertentu dalam pipeline Anda dapat menyebabkan representasi JSON melebihi batas. Kondisi umum mencakup:
- Transformasi
Createyang menyertakan sejumlah besar data dalam memori. - Instance
DoFnbesar yang diserialisasi untuk transmisi ke pekerja jarak jauh. DoFnsebagai instance class dalam anonim yang (mungkin secara tidak sengaja) menarik data dalam jumlah besar untuk diserialisasi.
Untuk menghindari kondisi ini, pertimbangkan untuk menyusun ulang pipeline Anda.
Opsi pipeline SDK atau daftar file staging melebihi batas ukuran
Saat menjalankan pipeline, salah satu error berikut terjadi:
SDK pipeline options or staging file list exceeds size limit.
Please keep their length under 256K Bytes each and 512K Bytes in total.
Atau:
Value for field 'resource.properties.metadata' is too large: maximum size
Error ini terjadi jika pipeline tidak dapat dimulai karena batas metadata Compute Engine terlampaui. Batas ini tidak dapat diubah. Dataflow menggunakan metadata Compute Engine untuk opsi pipeline. Batas ini didokumentasikan dalam batasan metadata kustom Compute Engine.
Skenario berikut dapat menyebabkan representasi JSON melebihi batas:
- Ada terlalu banyak file JAR untuk tahap.
- Kolom permintaan
sdkPipelineOptionsterlalu besar.
Untuk memperkirakan ukuran permintaan JSON dari pipeline Anda, jalankan pipeline dengan opsi berikut:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Output tugas Anda sebagai JSON tidak didukung di Go.
Ukuran file output dari perintah ini harus kurang dari 256 KB. Ukuran 512 KB pada pesan error mengacu pada ukuran total file output dan opsi metadata kustom untuk instance VM Compute Engine.
Anda bisa mendapatkan perkiraan kasar opsi metadata kustom untuk instance VM dari menjalankan tugas Dataflow dalam project tersebut. Pilih tugas Dataflow mana pun yang sedang berjalan. Ambil instance VM, lalu buka halaman detail instance VM Compute Engine untuk VM tersebut guna memeriksa bagian metadata kustom. Panjang total metadata kustom dan file tidak boleh lebih dari 512 KB. Anda tidak dapat memperkirakan tugas yang gagal secara akurat karena VM tidak dijalankan untuk tugas yang gagal.
Jika daftar JAR Anda mencapai batas 256 KB, tinjau dan kurangi file JAR yang tidak diperlukan. Jika masih terlalu besar, coba jalankan tugas Dataflow menggunakan JAR uber. Untuk contoh yang menunjukkan cara membuat dan menggunakan JAR uber, lihat Membangun dan men-deploy Uber JAR.
Jika kolom permintaan sdkPipelineOptions terlalu besar, sertakan opsi berikut
saat Anda menjalankan pipeline. Opsi pipeline sama untuk Java, Python, dan Go.
--experiments=no_display_data_on_gce_metadata
Kunci acak terlalu besar
Error berikut muncul di file log pekerja:
Shuffle key too large
Error ini terjadi jika kunci serial yang dimunculkan ke (Co-)GroupByKey tertentu terlalu besar setelah coder terkait diterapkan. Dataflow memiliki batas untuk kunci acak serial.
Untuk mengatasi masalah ini, kurangi ukuran kunci atau gunakan coder yang lebih hemat ruang.
Jumlah total objek BoundedSource ... lebih besar dari batas yang diizinkan
Salah satu error berikut mungkin terjadi saat menjalankan tugas dengan Java:
Total number of BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Atau:
Total size of the BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Java
Error ini dapat terjadi jika Anda membaca dari file yang sangat banyak menggunakan
TextIO, AvroIO, BigQueryIO melalui EKSPOR, atau beberapa sumber berbasis
file lainnya. Batas khusus ini bergantung pada detail sumber, tetapi
batasnya ada puluhan ribu file dalam satu pipeline. Misalnya,
skema penyematan dalam AvroIO.Read memungkinkan lebih sedikit file.
Error ini juga dapat terjadi jika Anda membuat sumber data kustom untuk
pipeline dan metode splitIntoBundles sumber menampilkan daftar
objek BoundedSource yang menghabiskan lebih dari 20 MB saat diserialisasi.
Batas yang diizinkan untuk ukuran total objek BoundedSource
yang dihasilkan oleh operasi splitIntoBundles() sumber kustom Anda adalah
20 MB.
Untuk mengatasi keterbatasan ini, lakukan salah satu perubahan berikut:
Aktifkan Runner V2. Runner v2 mengonversi sumber menjadi DoFn yang dapat dipisahkan yang tidak memiliki batas pemisahan sumber ini.
Ubah subclass
BoundedSourcekustom Anda agar ukuran total objekBoundedSourceyang dihasilkan lebih kecil dari batas 20 MB. Misalnya, sumber Anda mungkin pada awalnya menghasilkan lebih sedikit pemisahan, dan mengandalkan Keseimbangan Ulang Pekerjaan Dinamis untuk membagi input lebih lanjut sesuai permintaan.
NameError
Saat Anda menjalankan pipeline menggunakan layanan Dataflow, error berikut akan terjadi:
NameError
Error ini tidak terjadi saat Anda mengeksekusi secara lokal, seperti saat Anda mengeksekusi
menggunakan DirectRunner.
Error ini terjadi jika DoFn menggunakan nilai dalam namespace global yang tidak tersedia di pekerja Dataflow.
Secara default, impor, fungsi, dan variabel global yang ditentukan dalam sesi utama tidak disimpan selama serialisasi tugas Dataflow.
Untuk mengatasi masalah ini, gunakan salah satu metode berikut. Jika DoFn Anda
ditentukan dalam file utama dan mereferensikan impor serta fungsi di namespace
global, tetapkan opsi pipeline --save_main_session ke True. Perubahan ini
akan mengambil status namespace global dan memuatnya di
pekerja Dataflow.
Jika Anda memiliki objek di namespace global yang tidak dapat diacak, error pengemasan akan terjadi. Jika error berkaitan dengan modul yang seharusnya tersedia dalam distribusi Python, impor modul tersebut secara lokal, di tempat penggunaannya.
Misalnya, daripada:
import re … def myfunc(): # use re module
gunakan:
def myfunc(): import re # use re module
Atau, jika DoFn Anda mencakup beberapa file, gunakan
pendekatan berbeda untuk memaketkan alur kerja dan
mengelola dependensi.
Pemrosesan macet atau operasi sedang berlangsung
Jika Dataflow menghabiskan lebih banyak waktu untuk mengeksekusi DoFn daripada waktu yang ditentukan dalam TIME_INTERVAL tanpa menampilkan pesan, pesan berikut akan ditampilkan.
Java
Salah satu dari dua pesan log berikut, bergantung pada versinya:
Processing stuck in step STEP_NAME for at least TIME_INTERVAL
Operation ongoing in bundle BUNDLE_ID for at least TIME_INTERVAL without outputting or completing: at STACK_TRACE
Python
Operation ongoing for over TIME_INTERVAL in state STATE in step STEP_ID without returning. Current Traceback: TRACEBACK
Go
Operation ongoing in transform TRANSFORM_ID for at least TIME_INTERVAL without outputting or completing in state STATE
Perilaku ini memiliki dua kemungkinan penyebab:
- Kode
DoFnAnda lambat, atau menunggu beberapa operasi eksternal yang lambat selesai. - Kode
DoFnAnda mungkin macet, deadlock, atau sangat lambat untuk menyelesaikan pemrosesan.
Untuk menentukan mana yang terjadi, luaskan entri log Cloud Monitoring untuk melihat pelacakan tumpukan. Cari pesan yang menunjukkan bahwa kode DoFn macet
atau mengalami masalah. Jika tidak ada pesan yang muncul, masalahnya mungkin
kecepatan eksekusi kode DoFn. Pertimbangkan untuk menggunakan Cloud Profiler atau alat lain untuk menyelidiki performa kode Anda.
Jika pipeline Anda dibangun di VM Java (menggunakan Java atau Scala), Anda dapat menyelidiki penyebab kode macet. Ambil thread dump lengkap dari seluruh JVM (bukan hanya thread yang macet) dengan mengikuti langkah-langkah berikut:
- Catat nama pekerja dari entri log.
- Di bagian Compute Engine pada Konsol Google Cloud, cari instance Compute Engine dengan nama pekerja yang Anda catat.
- Gunakan SSH untuk terhubung ke instance dengan nama tersebut.
Jalankan perintah berikut:
curl http://localhost:8081/threadz
Error kuota Pub/Sub
Saat menjalankan pipeline streaming dari Pub/Sub, error berikut akan terjadi:
429 (rateLimitExceeded)
Atau:
Request was throttled due to user QPS limit being reached
Error ini terjadi jika project Anda tidak memiliki kuota Pub/Sub yang tidak mencukupi.
Untuk mengetahui apakah project Anda tidak memiliki kuota yang cukup, ikuti langkah-langkah berikut untuk memeriksa error klien:
- Buka Konsol Google Cloud.
- Pada menu di sebelah kiri, pilih APIs & services.
- Di Kotak Penelusuran, telusuri Cloud Pub/Sub.
- Klik tab Penggunaan.
- Periksa Kode Respons dan cari
(4xx)kode error klien.
Permintaan dilarang oleh kebijakan organisasi
Saat menjalankan pipeline, error berikut akan terjadi:
Error trying to get gs://BUCKET_NAME/FOLDER/FILE:
{"code":403,"errors":[{"domain":"global","message":"Request is prohibited by organization's policy","reason":"forbidden"}],
"message":"Request is prohibited by organization's policy"}
Error ini terjadi jika bucket Cloud Storage berada di luar perimeter layanan Anda.
Untuk mengatasi masalah ini, buat aturan keluar yang mengizinkan akses ke bucket di luar perimeter layanan.
Paket bertahap...tidak dapat diakses
Tugas yang sebelumnya berhasil mungkin gagal dengan error berikut:
Staged package...is inaccessible
Untuk menyelesaikan masalah ini:
- Pastikan bucket Cloud Storage yang digunakan untuk staging tidak memiliki setelan TTL yang menyebabkan paket stage akan dihapus.
Pastikan akun layanan pekerja project Dataflow Anda memiliki izin untuk mengakses bucket Cloud Storage yang digunakan untuk staging. Kesenjangan izin dapat disebabkan oleh salah satu alasan berikut:
- Bucket Cloud Storage yang digunakan untuk staging ada di project yang berbeda.
- Bucket Cloud Storage yang digunakan untuk staging dimigrasikan dari akses terperinci ke akses level bucket seragam. Karena adanya inkonsistensi antara kebijakan IAM dan ACL, memigrasikan bucket staging ke akses level bucket seragam akan melarang ACL untuk resource Cloud Storage. ACL mencakup izin yang dimiliki oleh akun layanan pekerja project Dataflow Anda melalui bucket staging.
Untuk informasi selengkapnya, baca artikel Mengakses bucket Cloud Storage di seluruh project Google Cloud.
Item tugas gagal 4 kali
Error berikut terjadi saat tugas gagal:
a work item failed 4 times
Error ini terjadi jika satu operasi menyebabkan kode pekerja gagal empat kali. Dataflow gagal melakukan tugas, dan pesan ini ditampilkan.
Anda tidak dapat mengonfigurasi ambang batas kegagalan ini. Untuk mengetahui detail selengkapnya, lihat penanganan pengecualian dan error pipeline.
Untuk mengatasi masalah ini, lihat log tugas Cloud Monitoring untuk empat kegagalan individual. Cari entri log Level error atau Tingkat Fatal di log pekerja yang menampilkan pengecualian atau error. Pengecualian atau error harus muncul minimal empat kali. Jika log hanya berisi error waktu tunggu umum yang terkait dengan pengaksesan resource eksternal, seperti MongoDB, pastikan akun layanan pekerja memiliki izin untuk mengakses subnetwork resource.
Waktu Tunggu dalam File Hasil Polling
Hal berikut terjadi saat tugas gagal:
Timeout in polling result file: PATH. Possible causes are:
1. Your launch takes too long time to finish. Please check the logs on stackdriver.
2. Service account SERVICE_ACCOUNT may not have enough permissions to pull
container image IMAGE_PATH or create new objects in PATH.
3. Transient errors occurred, please try again.
Masalah ini sering kali terkait dengan cara penginstalan dependensi Python
menggunakan file requirements.txt. Stage Apache Beam akan mendownload sumber
semua dependensi dari PyPi, termasuk sumber dependensi transitif.
Kemudian, kompilasi wheel terjadi secara implisit selama perintah download pip
untuk beberapa paket Python yang merupakan dependensi apache-beam.
Masalah waktu tunggu dapat terjadi karena file requirements.txt.
Untuk mengetahui informasi selengkapnya, lihat
pelacakan bug tim Apache Arrow terhadap masalah ini.
Solusi yang disarankan adalah menginstal apache-beam langsung di Dockerfile. Dengan cara ini, waktu tunggu
untuk file requirements.txt tidak diterapkan.
Error tugas arsip
Bagian berikut berisi error umum yang mungkin Anda alami saat mencoba mengarsipkan tugas Dataflow menggunakan API.
Tidak ada nilai yang diberikan
Saat Anda mencoba mengarsipkan tugas Dataflow dengan menggunakan API, error berikut mungkin terjadi:
The field mask specifies an update for the field job_metadata.user_display_properties.archived in job JOB_ID, but no value is provided. To update a field, please provide a field for the respective value.
Error ini terjadi karena salah satu alasan berikut:
Jalur yang ditentukan untuk kolom
updateMasktidak mengikuti format yang benar. Masalah ini dapat terjadi karena kesalahan ketik.JobMetadatatidak ditentukan dengan benar. Di kolomJobMetadata, untukuserDisplayProperties, gunakan pasangan nilai kunci"archived":"true".
Untuk mengatasi error ini, pastikan perintah yang Anda teruskan ke API sesuai dengan format yang diperlukan. Untuk detail selengkapnya, lihat Mengarsipkan tugas.
API tidak mengenali nilai ini
Saat Anda mencoba mengarsipkan tugas Dataflow dengan menggunakan API, error berikut mungkin terjadi:
The API does not recognize the value VALUE for the field job_metadata.user_display_properties.archived for job JOB_ID. REASON: Archived display property can only be set to 'true' or 'false'
Error ini terjadi jika nilai yang diberikan dalam pasangan nilai kunci tugas arsip bukan
nilai yang didukung. Nilai yang didukung untuk pasangan nilai kunci tugas arsip adalah
"archived":"true" dan "archived":"false".
Untuk mengatasi error ini, pastikan perintah yang Anda teruskan ke API sesuai dengan format yang diperlukan. Untuk detail selengkapnya, lihat Mengarsipkan tugas.
Tidak dapat memperbarui status dan mask secara bersamaan
Saat Anda mencoba mengarsipkan tugas Dataflow dengan menggunakan API, error berikut mungkin terjadi:
Cannot update both state and mask.
Error ini terjadi saat Anda mencoba memperbarui status tugas dan status arsip dalam panggilan API yang sama. Anda tidak dapat memperbarui status tugas dan parameter kueri updateMask dalam panggilan API yang sama.
Untuk mengatasi error ini, perbarui status tugas dalam panggilan API terpisah. Melakukan pembaruan pada status tugas sebelum memperbarui status arsip lowongan.
Gagal mengubah alur kerja
Saat Anda mencoba mengarsipkan tugas Dataflow dengan menggunakan API, error berikut mungkin terjadi:
Workflow modification failed.
Error ini biasanya terjadi saat Anda mencoba mengarsipkan tugas yang sedang berjalan.
Untuk mengatasi error ini, tunggu hingga tugas selesai sebelum mengarsipkannya. Tugas yang selesai memiliki salah satu status tugas berikut:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
Untuk mengetahui informasi lebih lanjut, baca bagian Mendeteksi penyelesaian tugas Dataflow.
Error image container
Bagian berikut berisi error umum yang mungkin Anda alami saat menggunakan penampung kustom serta langkah-langkah untuk mengatasi atau memecahkan masalah error. Error biasanya diawali dengan pesan berikut:
Unable to pull container image due to error: DETAILED_ERROR_MESSAGE
Izin "containeranalysis.Events.list" ditolak
Error berikut muncul di file log Anda:
Error getting old patchz discovery occurrences: generic::permission_denied: permission "containeranalysis.occurrences.list" denied for project "PROJECT_ID", entity ID "" [region="REGION" projectNum=PROJECT_NUMBER projectID="PROJECT_ID"]
Container Analysis API diperlukan untuk pemindaian kerentanan.
Untuk mengetahui informasi selengkapnya, lihat Ringkasan pemindaian OS dan Mengonfigurasi kontrol akses dalam dokumentasi Artifact Analysis.
Terjadi error saat menyinkronkan pod ... gagal ke "StartContainer"
Error berikut terjadi selama startup pekerja:
Error syncing pod POD_ID, skipping: [failed to "StartContainer" for CONTAINER_NAME with CrashLoopBackOff: "back-off 5m0s restarting failed container=CONTAINER_NAME pod=POD_NAME].
Pod adalah grup container Docker yang ditempatkan bersama dan berjalan di pekerja Dataflow. Error ini terjadi saat salah satu container Docker di pod gagal dimulai. Jika kegagalan tidak dapat dipulihkan, pekerja Dataflow tidak akan dapat dimulai, dan tugas batch Dataflow pada akhirnya akan gagal dengan error seperti berikut:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
Error ini biasanya terjadi saat salah satu container terus-menerus mengalami error selama startup.
Untuk memahami akar masalahnya, cari log yang direkam tepat sebelum kegagalan. Untuk menganalisis log, gunakan Logs Explorer. Di Logs Explorer, batasi file log ke entri log yang dikeluarkan dari pekerja dengan error startup container. Untuk membatasi entri log, selesaikan langkah-langkah berikut:
- Di Logs Explorer, temukan entri log
Error syncing pod. - Untuk melihat label yang terkait dengan entri log, luaskan entri log.
- Klik label yang terkait dengan
resource_name, lalu klik Show matching entries.
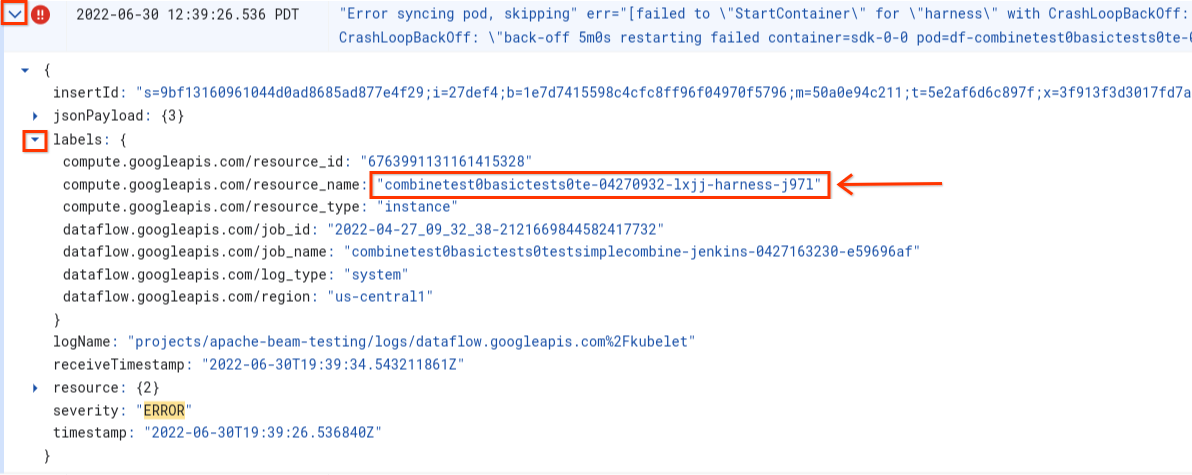
Di Logs Explorer, log Dataflow diatur menjadi beberapa stream log. Pesan Error syncing pod dimunculkan dalam log bernama
kubelet. Namun, log dari container yang gagal mungkin berada dalam aliran log yang berbeda. Setiap penampung memiliki nama. Gunakan tabel berikut untuk menentukan
aliran log yang mungkin berisi log yang relevan dengan penampung yang gagal.
| Nama container | Nama log |
|---|---|
| sdk, sdk0, sdk1, sdk-0-0, dan yang serupa | buruh kapal |
| harness | harness, harness-startup |
| python, java-batch, java-streaming | pekerja-startup, pekerja |
| artefak | artefak |
Saat Anda membuat kueri Logs Explorer, pastikan kueri tersebut menyertakan nama log yang relevan di antarmuka builder kueri atau tidak memiliki batasan pada nama log.
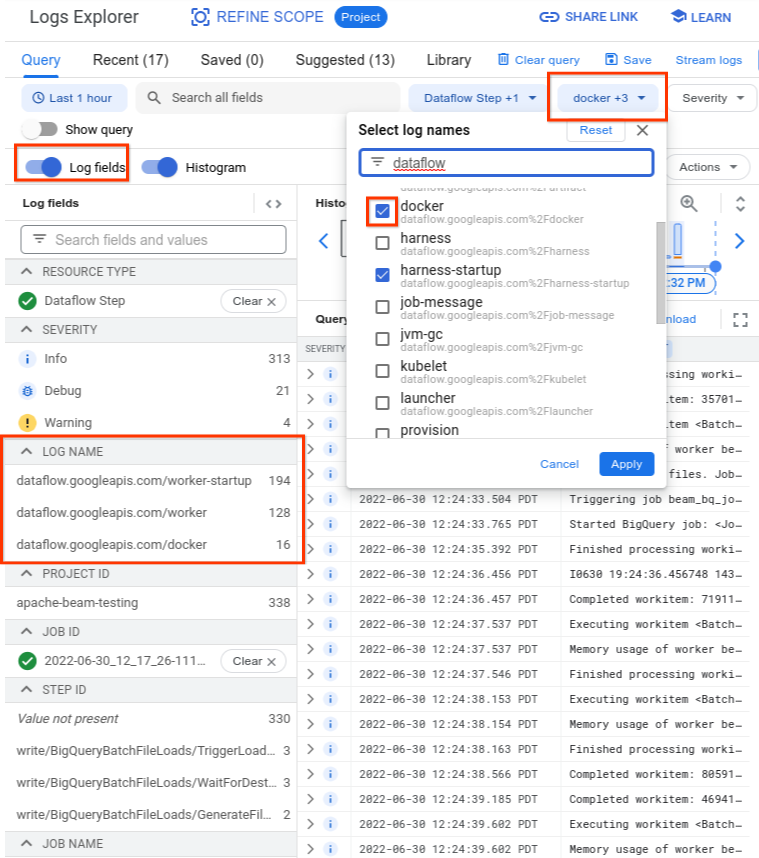
Setelah Anda memilih log yang relevan, hasil kueri mungkin terlihat seperti contoh berikut:
resource.type="dataflow_step"
resource.labels.job_id="2022-06-29_08_02_54-JOB_ID"
labels."compute.googleapis.com/resource_name"="testpipeline-jenkins-0629-DATE-cyhg-harness-8crw"
logName=("projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fdocker"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker-startup"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker")
Karena log yang melaporkan gejala kegagalan container terkadang dilaporkan sebagai INFO, sertakan log INFO dalam analisis Anda.
Penyebab umum kegagalan container mencakup hal-hal berikut:
- Pipeline Python Anda memiliki dependensi tambahan yang diinstal saat runtime, dan penginstalan tidak berhasil. Anda mungkin melihat error seperti
pip install failed with error. Masalah ini mungkin terjadi karena persyaratan yang bertentangan, atau karena konfigurasi jaringan yang dibatasi yang mencegah pekerja Dataflow mengambil dependensi eksternal dari repositori publik melalui internet. Pekerja gagal di tengah proses pipeline berjalan karena error kehabisan memori. Anda mungkin melihat error seperti salah satu dari berikut ini:
java.lang.OutOfMemoryError: Java heap spaceShutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = 24453/42043/42043 MB, GC last/max = 58.97/99.89 %, #pushbacks=82, gc thrashing=true. Heap dump not written.
Untuk men-debug masalah kehabisan memori, lihat Memecahkan masalah Dataflow kehabisan memori.
Dataflow tidak dapat mengambil image container. Untuk mengetahui informasi selengkapnya, lihat Permintaan pull gambar gagal dengan error.
Container yang digunakan tidak kompatibel dengan arsitektur CPU VM pekerja. Di log startup harness, Anda mungkin melihat error seperti berikut:
exec /opt/apache/beam/boot: exec format error. Untuk memeriksa arsitektur image container, jalankandocker image inspect $IMAGE:$TAGdan cari kata kunciArchitecture. Jika tertulisError: No such image: $IMAGE:$TAG, Anda mungkin perlu menarik gambar terlebih dahulu dengan menjalankandocker pull $IMAGE:$TAG. Untuk mengetahui informasi tentang cara membuat image multi-arsitektur, lihat Membuat image container multi-arsitektur.
Setelah Anda mengidentifikasi error yang menyebabkan penampung gagal, coba atasi error tersebut, lalu kirim ulang pipeline.
Permintaan pengambilan gambar gagal dengan error
Selama startup pekerja, salah satu error berikut akan muncul dalam log pekerja atau tugas:
Image pull request failed with error
pull access denied for IMAGE_NAME
manifest for IMAGE_NAME not found: manifest unknown: Failed to fetch
Get IMAGE_NAME: Service Unavailable
Error ini terjadi jika pekerja tidak dapat memulai karena pekerja tidak dapat menarik image container Docker. Masalah ini terjadi dalam skenario berikut:
- URL gambar penampung SDK kustom salah
- Pekerja tidak memiliki kredensial atau akses jaringan ke image jarak jauh
Untuk menyelesaikan masalah ini:
- Jika Anda menggunakan gambar penampung kustom dengan tugas Anda, pastikan URL gambar Anda sudah benar dan memiliki tag atau ringkasan yang valid. Pekerja Dataflow juga memerlukan akses ke image.
- Pastikan bahwa gambar publik dapat diambil secara lokal dengan menjalankan
docker pull $imagedari mesin yang tidak diautentikasi.
Untuk gambar pribadi atau pekerja pribadi:
- Jika Anda menggunakan Container Registry untuk menghosting image container, sebaiknya gunakan Artifact Registry. Mulai 15 Mei 2023, Container Registry tidak digunakan lagi. Jika menggunakan Container Registry, Anda dapat beralih ke Artifact Registry. Jika image Anda berada di project yang berbeda dengan yang digunakan untuk menjalankan tugas Google Cloud, konfigurasikan kontrol akses untuk akun layanan Google Cloud default.
- Jika menggunakan Virtual Private Cloud (VPC), pastikan pekerja dapat mengakses host repositori container kustom.
- Gunakan
sshuntuk terhubung dengan VM pekerja tugas yang berjalan dan menjalankandocker pull $imageuntuk langsung mengonfirmasi bahwa pekerja telah dikonfigurasi dengan benar.
Jika pekerja gagal beberapa kali berturut-turut karena error ini dan pekerjaan telah dimulai pada tugas, tugas dapat gagal dengan error yang mirip dengan pesan berikut:
Job appears to be stuck.
Jika Anda menghapus akses ke gambar saat tugas sedang berjalan, baik dengan menghapus gambar itu sendiri maupun mencabut Kredensial Akun Layanan pekerja Dataflow atau akses internet untuk mengakses gambar, Dataflow hanya akan mencatat error ke dalam log. Dataflow tidak gagal dalam tugas ini. Dataflow juga menghindari kegagalan pipeline streaming yang berjalan lama agar tidak kehilangan status pipeline.
Error lainnya dapat muncul karena masalah kuota repositori atau pemadaman layanan. Jika Anda mengalami masalah yang melebihi kuota Docker Hub untuk mengambil image publik atau gangguan repositori pihak ketiga secara umum, sebaiknya gunakan Artifact Registry sebagai repositori image.
SystemError: kode op tidak diketahui
Pipeline container kustom Python Anda mungkin gagal dengan error berikut segera setelah pengiriman tugas:
SystemError: unknown opcode
Selain itu, pelacakan tumpukan mungkin menyertakan
apache_beam/internal/pickler.py
Untuk mengatasi masalah ini, pastikan versi Python yang Anda gunakan secara lokal cocok dengan versi di image container hingga versi utama dan minor. Perbedaan dalam versi patch, seperti 3.6.7 versus 3.6.8, tidak menimbulkan masalah kompatibilitas. Perbedaan pada versi minor, seperti 3.6.8 versus 3.8.2, dapat menyebabkan kegagalan pipeline.
Error pekerja
Bagian berikut berisi error pekerja umum yang mungkin Anda alami dan langkah-langkah untuk menyelesaikan atau memecahkan masalah error.
Panggilan dari harness pekerja Java ke Python DoFn gagal dengan error
Jika panggilan dari harness pekerja Java ke Python DoFn gagal, pesan error
yang relevan akan ditampilkan.
Untuk menyelidiki error, luaskan entri log error Cloud Monitoring serta lihat pesan error dan traceback. Alat ini menunjukkan kode mana yang gagal, sehingga Anda dapat memperbaikinya jika perlu. Jika Anda yakin bahwa error tersebut adalah bug di Apache Beam atau Dataflow, laporkan bug tersebut.
EOFError: data marshal terlalu pendek
Error berikut muncul di log pekerja:
EOFError: marshal data too short
Error ini terkadang terjadi saat pekerja pipeline Python kehabisan ruang disk.
Untuk mengatasi masalah ini, lihat Tidak ada ruang tersisa di perangkat.
Gagal memasang disk
Saat Anda mencoba meluncurkan tugas Dataflow yang menggunakan VM C3 dengan Persistent Disk, tugas tersebut akan gagal dengan salah satu atau kedua error berikut:
Failed to attach disk(s), status: generic::invalid_argument: One or more operations had an error
Can not allocate sha384 (reason: -2), Spectre V2 : WARNING: Unprivileged eBPF is enabled with eIBRS on...
Error ini terjadi saat Anda menggunakan VM C3 dengan jenis Persistent Disk yang tidak didukung. Untuk mengetahui informasi selengkapnya, baca Jenis disk yang didukung untuk C3.
Untuk menggunakan VM C3 dengan tugas Dataflow, pilih jenis disk pekerja pd-ssd. Untuk informasi selengkapnya, lihat
Opsi tingkat pekerja.
Java
--workerDiskType=pd-ssd
Python
--worker_disk_type=pd-ssd
Go
disk_type=pd-ssd
Tidak ada ruang tersisa di perangkat
Saat tugas kehabisan kapasitas disk, error berikut mungkin muncul di log pekerja:
No space left on device
Error ini dapat terjadi karena salah satu alasan berikut:
- Penyimpanan persisten pekerja kehabisan ruang kosong, yang dapat terjadi karena
salah satu alasan berikut:
- Tugas mendownload dependensi yang besar saat runtime
- Sebuah tugas menggunakan container kustom berukuran besar
- Suatu tugas menulis banyak data sementara ke disk lokal
- Saat menggunakan Dataflow Shuffle, Dataflow menetapkan ukuran disk default yang lebih rendah. Akibatnya, error ini mungkin terjadi dengan tugas yang berpindah dari pengacakan berbasis pekerja.
- Boot disk pekerja terisi karena mencatat lebih dari 50 entri per detik.
Untuk mengatasi masalah ini, ikuti langkah-langkah pemecahan masalah berikut:
Untuk melihat resource disk yang terkait dengan satu pekerja, cari detail instance VM untuk VM pekerja yang terkait dengan tugas Anda. Bagian dari kapasitas disk digunakan oleh sistem operasi, biner, log, dan container.
Untuk meningkatkan kapasitas persistent disk atau boot disk, sesuaikan opsi pipeline ukuran disk.
Lacak penggunaan ruang disk pada instance VM pekerja dengan menggunakan Cloud Monitoring. Lihat Menerima metrik pekerja VM dari agen Monitoring untuk mendapatkan petunjuk yang menjelaskan cara menyiapkannya.
Cari masalah ruang boot disk dengan Melihat output port serial pada instance VM pekerja dan mencari pesan seperti:
Failed to open system journal: No space left on device
Jika memiliki banyak instance VM pekerja, Anda dapat membuat skrip untuk menjalankan gcloud compute instances get-serial-port-output pada semua instance tersebut sekaligus.
Anda dapat meninjau output tersebut.
Pipeline Python gagal setelah satu jam tidak aktif pekerja
Saat menggunakan Apache Beam SDK untuk Python dengan Dataflow Runner V2 pada mesin pekerja yang memiliki banyak core CPU, gunakan Apache Beam SDK 2.35.0 atau yang lebih baru. Jika tugas Anda menggunakan penampung kustom, gunakan Apache Beam SDK 2.46.0 atau yang lebih baru.
Pertimbangkan untuk membangun terlebih dahulu container Python Anda. Langkah ini dapat meningkatkan waktu startup VM dan performa penskalaan otomatis horizontal. Untuk menggunakan fitur ini, aktifkan Cloud Build API di project Anda dan kirimkan pipeline Anda dengan parameter berikut:
‑‑prebuild_sdk_container_engine=cloud_build.
Untuk mengetahui informasi selengkapnya, lihat Dataflow Runner V2.
Anda juga dapat menggunakan image container kustom dengan semua dependensi yang sudah diinstal sebelumnya.
Startup kumpulan pekerja di zona gagal menampilkan pekerja yang diinginkan
Terjadi error berikut:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers.
The project quota may have been exceeded or access control policies may be preventing the operation;
review the Cloud Logging 'VM Instance' log for diagnostics.
Error ini terjadi karena salah satu alasan berikut:
- Anda telah melampaui salah satu kuota Compute Engine yang diandalkan oleh pembuatan pekerja Dataflow.
- Organisasi Anda menerapkan batasan yang melarang beberapa aspek proses pembuatan instance VM, seperti akun yang digunakan, atau zona yang ditargetkan.
Untuk mengatasi masalah ini, ikuti langkah-langkah pemecahan masalah berikut:
Meninjau log Instance VM
- Buka penampil Cloud Logging
- Di menu drop-down Audited Resource, pilih VM Instance.
- Di menu drop-down All logs, pilih compute.googleapis.com/activity_log.
- Pindai log untuk menemukan entri terkait kegagalan pembuatan instance VM.
Memeriksa penggunaan kuota Compute Engine
Untuk melihat penggunaan resource Compute Engine yang dibandingkan dengan Kuota Dataflow untuk zona yang Anda targetkan, jalankan perintah berikut:
gcloud compute regions describe [REGION]Tinjau hasil resource berikut untuk melihat apakah ada resource yang melebihi kuota:
- CPU
- DISKS_TOTAL_GB
- IN_USE_ADDRESSES
- INSTANCE_GROUPS
- INSTANCE
- REGIONAL_INSTANCE_GROUP_MANAGERS
Jika perlu, minta perubahan kuota.
Meninjau batasan kebijakan organisasi Anda
- Buka halaman Kebijakan organisasi
- Tinjau batasan untuk apa pun yang mungkin membatasi pembuatan instance VM untuk akun yang Anda gunakan (secara default, akun layanan Dataflow) atau di zona yang Anda targetkan.
- Jika Anda memiliki kebijakan yang membatasi penggunaan alamat IP eksternal, nonaktifkan alamat IP eksternal untuk tugas ini. Untuk mengetahui informasi selengkapnya tentang cara menonaktifkan alamat IP eksternal, lihat Mengonfigurasi aturan akses internet dan firewall.
Waktu habis saat menunggu update dari pekerja
Jika tugas Dataflow gagal, error berikut akan terjadi:
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
Terkadang, error ini terjadi saat pekerja kehabisan memori atau ruang pertukaran. Untuk mengatasi masalah ini, sebagai langkah pertama, coba jalankan tugas lagi. Jika tugas masih gagal dan error yang sama terjadi, coba gunakan pekerja dengan memori dan ruang disk yang lebih besar. Misalnya, tambahkan opsi startup pipeline berikut:
--worker_machine_type=m1-ultramem-40 --disk_size_gb=500
Mengubah jenis pekerja dapat memengaruhi biaya yang ditagih. Untuk mengetahui informasi selengkapnya, lihat Memecahkan masalah Dataflow kehabisan memori.
Error ini juga dapat terjadi jika data Anda berisi hot key. Dalam skenario ini, penggunaan CPU tinggi pada beberapa pekerja selama sebagian besar durasi tugas. Namun, jumlah pekerja tidak mencapai jumlah maksimum yang diizinkan. Untuk mengetahui informasi selengkapnya tentang hot key dan kemungkinan solusinya, lihat Menulis pipeline Dataflow dengan mempertimbangkan skalabilitas.
Untuk solusi tambahan atas masalah ini, lihat Hot key ... terdeteksi.
Jika kode Python Anda memanggil kode C/C++ dengan menggunakan mekanisme ekstensi Python,
periksa apakah kode ekstensi melepaskan Kunci Penerjemah Global Python (GIL) di bagian kode yang sarat komputasi
yang tidak mengakses status Python.
Library yang memfasilitasi interaksi dengan ekstensi seperti Cython, dan PyBind
memiliki primitif untuk mengontrol status GIL. Anda juga dapat merilis GIL
secara manual dan mendapatkannya kembali sebelum menampilkan kontrol ke penafsir Python menggunakan makro
Py_BEGIN_ALLOW_THREADS dan Py_END_ALLOW_THREADS.
Untuk mengetahui informasi selengkapnya, lihat Status Thread dan Kunci Penerjemah Global
dalam dokumentasi Python.
Di pipeline Python, dalam konfigurasi default, Dataflow mengasumsikan bahwa setiap proses Python yang berjalan pada worker secara efisien menggunakan satu inti vCPU. Jika kode pipeline mengabaikan batasan GIL, seperti menggunakan library yang diimplementasikan di C++, elemen pemrosesan mungkin menggunakan resource dari beberapa inti vCPU, dan pekerja mungkin tidak mendapatkan resource CPU yang cukup. Untuk mengatasi masalah ini, kurangi jumlah thread pada pekerja.
Terjadi error sementara saat memublikasikan ke topik
Jika tugas streaming Anda menggunakan mode streaming minimal satu kali dan memublikasikannya ke sink Pub/Sub, error berikut akan muncul di log tugas:
There were transient errors publishing to topic
Jika tugas Anda berjalan dengan benar, error ini tidak berbahaya, dan Anda dapat mengabaikannya. Dataflow secara otomatis mencoba kembali pengiriman pesan Pub/Sub dengan penundaan backoff.
Masalah dependensi Java
Class dan library yang tidak kompatibel dapat menyebabkan masalah dependensi Java. Jika pipeline Anda memiliki masalah dependensi Java, salah satu error berikut mungkin akan terjadi:
NoClassDefFoundError: Error ini terjadi jika seluruh class tidak tersedia selama runtime.NoSuchMethodError: Error ini terjadi saat class dalam classpath menggunakan versi yang tidak berisi metode yang benar atau saat tanda tangan metode berubah.NoSuchFieldError: Error ini terjadi saat class di classpath menggunakan versi yang tidak memiliki kolom yang diperlukan selama runtime.FATAL ERROR in native method: Error ini terjadi saat dependensi bawaan tidak dapat dimuat dengan benar. Saat menggunakan JAR uber (diarsir), jangan sertakan library yang menggunakan tanda tangan (seperti Conscrypt) dalam JAR yang sama.
Jika pipeline Anda berisi kode dan setelan khusus pengguna, kode tersebut tidak boleh berisi library versi campuran. Jika Anda menggunakan library pengelolaan dependensi, sebaiknya gunakan BOM Library Google Cloud.
Jika Anda menggunakan Apache Beam SDK, untuk mengimpor BOM library yang benar,
gunakan beam-sdks-java-io-google-cloud-platform-bom:
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-google-cloud-platform-bom</artifactId>
<version>BEAM_VERSION</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle
dependencies {
implementation(platform("org.apache.beam:beam-sdks-java-google-cloud-platform-bom:BEAM_VERSION"))
}
Untuk mengetahui informasi selengkapnya, lihat Mengelola dependensi pipeline di Dataflow.
InAccessibleObjectException di JDK 17 dan yang lebih baru
Saat Anda menjalankan pipeline dengan Platform Java, Standard Edition Development Kit (JDK) versi 17 dan yang lebih baru, error berikut mungkin muncul dalam file log pekerja:
Unable to make protected METHOD accessible:
module java.MODULE does not "opens java.MODULE" to ...
Masalah ini terjadi karena mulai Java versi 9, opsi virtual machine Java modul terbuka (JVM) diperlukan untuk mengakses internal JDK. Di Java 16 dan versi yang lebih baru, opsi JVM modul terbuka selalu diperlukan untuk mengakses internal JDK.
Untuk mengatasi masalah ini, saat Anda meneruskan modul ke
pipeline Dataflow untuk terbuka, gunakan format
MODULE/PACKAGE=TARGET_MODULE(,TARGET_MODULE)*
dengan opsi pipeline jdkAddOpenModules. Format ini
memungkinkan akses ke library yang diperlukan.
Misalnya, jika error-nya adalah module java.base does not "opens java.lang" to unnamed module @..., sertakan opsi pipeline berikut saat Anda menjalankan pipeline:
--jdkAddOpenModules=java.base/java.lang=ALL-UNNAMED
Untuk informasi selengkapnya, lihat
dokumentasi class
DataflowPipelineOptions.
Error konektor BigQuery
Bagian berikut berisi error umum konektor BigQuery yang mungkin Anda alami dan langkah-langkah untuk mengatasi atau memecahkan masalah error tersebut.
quotaExceeded
Saat Anda menggunakan konektor BigQuery untuk menulis ke BigQuery menggunakan streaming insert, throughput tulis lebih rendah dari yang diharapkan, dan error berikut mungkin terjadi:
quotaExceeded
Throughput yang lambat mungkin disebabkan oleh pipeline Anda melebihi kuota penyisipan streaming BigQuery yang tersedia. Jika demikian, pesan error terkait kuota dari BigQuery akan muncul di log pekerja Dataflow (cari error quotaExceeded).
Jika Anda melihat quotaExceeded error, untuk mengatasi masalah ini:
- Saat menggunakan Apache Beam SDK untuk Java, tetapkan opsi sink BigQuery
ignoreInsertIds(). - Saat menggunakan Apache Beam SDK untuk Python, gunakan opsi
ignore_insert_ids.
Dengan setelan ini, Anda memenuhi syarat untuk mendapatkan throughput penyisipan streaming BigQuery sebesar satu GB per detik per project. Untuk informasi lebih lanjut tentang peringatan yang terkait dengan penghapusan duplikat pesan otomatis, lihat dokumentasi BigQuery. Untuk meningkatkan kuota penyisipan streaming BigQuery lebih dari satu GBps, kirimkan permintaan melalui Konsol Google Cloud.
Jika Anda tidak melihat error terkait kuota di log pekerja, masalahnya mungkin karena
pemaketan default atau pengelompokan parameter terkait tidak menyediakan paralelisme
yang memadai untuk penskalaan pipeline Anda. Anda dapat menyesuaikan beberapa konfigurasi terkait konektor BigQuery Dataflow untuk mencapai performa yang diharapkan saat menulis ke BigQuery menggunakan streaming insert. Misalnya, untuk Apache Beam SDK untuk Java, sesuaikan numStreamingKeys agar sesuai dengan jumlah maksimum pekerja dan pertimbangkan untuk meningkatkan insertBundleParallelism guna mengonfigurasi konektor BigQuery agar dapat menulis ke BigQuery menggunakan lebih banyak thread paralel.
Untuk konfigurasi yang tersedia di Apache Beam SDK untuk Java, lihat BigQueryPipelineOptions, dan untuk konfigurasi yang tersedia di Apache Beam SDK untuk Python, lihat transformasi WriteToBigQuery.
rateLimitExceeded
Saat menggunakan konektor BigQuery, error berikut akan terjadi:
rateLimitExceeded
Error ini terjadi jika BigQuery terlalu banyak permintaan API yang dikirim selama durasi yang singkat. BigQuery memiliki batas kuota jangka pendek.
Pipeline Dataflow Anda mungkin akan melampaui kuota tersebut untuk sementara. Dalam skenario ini, permintaan API dari pipeline Dataflow ke BigQuery mungkin gagal, yang dapat mengakibatkan error rateLimitExceeded dalam log pekerja.
Dataflow akan mencoba kembali kegagalan tersebut, sehingga Anda dapat mengabaikan error ini dengan aman. Jika Anda yakin bahwa pipeline Anda terpengaruh oleh error rateLimitExceeded, hubungi Cloud Customer Care.
Error lain-lain
Bagian berikut berisi berbagai error yang mungkin Anda alami dan langkah-langkah untuk mengatasi atau memecahkan masalah error tersebut.
Tidak dapat mengalokasikan sha384
Tugas Anda berjalan dengan benar, tetapi Anda melihat error berikut di log tugas:
ima: Can not allocate sha384 (reason: -2)
Jika tugas Anda berjalan dengan benar, error ini tidak berbahaya, dan Anda dapat mengabaikannya. Image dasar VM pekerja terkadang menghasilkan pesan ini. Dataflow secara otomatis merespons dan mengatasi masalah pokok.
Ada permintaan fitur untuk mengubah tingkat pesan ini dari WARN menjadi INFO. Untuk mengetahui informasi selengkapnya, lihat
Menurunkan level log error peluncuran sistem Dataflow ke WARN atau INFO.
Terjadi error saat menginisialisasi prober plugin dinamis
Tugas Anda berjalan dengan benar, tetapi Anda melihat error berikut di log tugas:
Error initializing dynamic plugin prober" err="error (re-)creating driver directory: mkdir /usr/libexec/kubernetes: read-only file system
Jika tugas Anda berjalan dengan benar, error ini tidak berbahaya, dan Anda dapat mengabaikannya. Error ini terjadi saat tugas Dataflow mencoba membuat direktori tanpa izin tulis yang diperlukan, dan tugas tersebut gagal. Jika tugas Anda berhasil, direktori tidak diperlukan, atau Dataflow mengatasi masalah pokoknya.
Ada permintaan fitur untuk mengubah tingkat pesan ini dari WARN menjadi INFO. Untuk mengetahui informasi selengkapnya, lihat
Menurunkan level log error peluncuran sistem Dataflow ke WARN atau INFO.
Objek tersebut tidak ada: pipeline.pb
Saat mencantumkan tugas menggunakan opsi
JOB_VIEW_ALL, error berikut akan terjadi:
No such object: BUCKET_NAME/PATH/pipeline.pb
Error ini dapat terjadi jika Anda menghapus file pipeline.pb dari file staging untuk tugas tersebut.
Melewati sinkronisasi pod
Tugas Anda berjalan dengan benar, tetapi Anda melihat salah satu error berikut di log tugas:
Skipping pod synchronization" err="container runtime status check may not have completed yet"
Atau:
Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
Jika tugas Anda berjalan dengan benar, error ini tidak berbahaya, dan Anda dapat mengabaikannya.
Pesan container runtime status check may not have completed yet muncul saat kubelet Kubernetes melewati sinkronisasi pod karena sedang menunggu runtime container untuk diinisialisasi. Skenario ini terjadi karena berbagai alasan, seperti saat runtime container baru saja dimulai atau dimulai ulang.
Saat pesan menyertakan PLEG is not healthy: pleg has yet to be successful, kubelet menunggu generator peristiwa siklus proses pod (PLEG) menjadi responsif sebelum menyinkronkan pod. PLEG bertanggung jawab untuk menghasilkan peristiwa
yang digunakan oleh kubelet untuk melacak status pod.
Ada permintaan fitur untuk mengubah tingkat pesan ini dari WARN menjadi INFO. Untuk mengetahui informasi selengkapnya, lihat
Menurunkan level log error peluncuran sistem Dataflow ke WARN atau INFO.
Rekomendasi
Untuk panduan tentang rekomendasi yang dibuat oleh Dataflow Insights, lihat Insight.