O Dataflow coleta métricas dos seus jobs, o que pode ajudar você a depurar erros, resolver problemas de desempenho ou otimizar seu pipeline. A interface de monitoramento do Dataflow mostra visualizações dessas métricas. Também é possível usar o Cloud Monitoring para criar alertas ou consultas do Metrics Explorer.
Acessar métricas do job
Para conferir as métricas de um job, siga estas etapas:
No Google Cloud console, acesse a página Dataflow > Jobs.
Selecione um job.
Clique na guia Métricas do job.
Selecione uma métrica para visualizar.
Para acessar mais informações nos gráficos de métricas do job, clique em Explorar dados.
Cada métrica é organizada nos seguintes painéis:
- Métricas de escalonamento automático
- Métricas de visão geral
- Métricas de streaming
- Métricas de recursos
- Métricas de entrada/saída
Suporte e limitações
Ao usar as métricas do Dataflow, esteja ciente dos detalhes a seguir.
Às vezes, os dados do job ficam indisponíveis de modo intermitente. Quando faltam dados, lacunas aparecem nos gráficos de monitoramento do job.
Alguns desses gráficos são específicos apenas para pipelines de streaming.
Para gravar dados de métricas, uma conta de serviço gerenciada pelo usuário precisa ter a permissão
monitoring.timeSeries.createda API IAM. Essa permissão está incluída no papel de worker do Dataflow.O serviço Dataflow informa o tempo de CPU reservado após a conclusão dos jobs. Para jobs ilimitados (por streaming), o tempo de CPU reservado só é informado após o cancelamento ou a falha dos jobs. Portanto, as métricas do job não incluem tempo de CPU reservado para jobs de streaming.
Métricas de escalonamento automático
O escalonamento automático horizontal permite que o Dataflow escolha o número apropriado de instâncias de worker para o job, adicionando ou removendo workers conforme necessário.
A seção Escalonamento automático da guia Métricas do job mostra o número de workers e a meta de workers ao longo do tempo. Se o job usar o Streaming Engine, ele também vai mostrar o número mínimo e máximo de workers.

Para ver o histórico de alterações do escalonamento automático, clique em Mais histórico. Uma tabela com informações sobre o histórico do worker do job é exibida.

Para ver mais informações sobre o escalonamento automático de jobs de streaming, clique na guia Escalonamento automático. Para mais informações, consulte Monitorar o escalonamento automático do Dataflow.
Métricas de visão geral
As seguintes métricas aparecem em Métricas de visão geral.
Atualização de dados
Essa métrica se aplica apenas a jobs de streaming.
A atualização de dados é a diferença entre o momento em que um elemento de dados é processado (tempo de processamento) e o carimbo de data/hora do elemento de dados (tempo do evento). Valores mais altos significam que houve um atraso maior entre o horário do evento e o horário de processamento.
O gráfico de atualização de dados mostra o valor máximo de atualização em qualquer ponto no tempo. O Dataflow processa vários elementos em paralelo. Por isso, o gráfico reflete o elemento com o maior atraso em relação ao horário do evento.
Se alguns dados de entrada ainda não tiverem sido processados, a marca-d'água de saída poderá sofrer atrasos, o que afeta a atualização de dados. Uma diferença significativa entre o tempo da marca-d'água e o horário do evento pode indicar uma operação lenta ou travada. Para mais informações, consulte Marcas-d'água e dados atrasados na documentação do Apache Beam.
O painel inclui estes quatro gráficos:
- Atualização de dados por etapas
- Atualização de dados
Na imagem a seguir, a área destacada mostra uma grande diferença entre o tempo do evento e o tempo da marca-d'água de saída, indicando uma operação lenta.

Os seguintes problemas podem causar valores altos para essa métrica:
- Gargalos de desempenho: se o pipeline tiver fases com alta latência do sistema ou registros indicando transformações travadas, o pipeline pode ter problemas de desempenho que podem aumentar a atualização de dados. Para investigar mais, consulte Resolver problemas de jobs de streaming lentos ou travados.
- Gargalos da fonte de dados: se as origens de dados tiverem backlogs crescentes, os carimbos de data/hora dos eventos dos seus elementos poderão divergir da marca-d'água enquanto aguardam o processamento. Os backlogs grandes geralmente são causados por gargalos de desempenho
ou problemas de fonte de dados que são detectados da melhor forma pelo monitoramento das fontes usadas
pelo pipeline.
- Fontes não ordenadas, como o Pub/Sub, podem produzir marcas-d'água travadas, mesmo com uma taxa alta de saída. Essa situação ocorre porque os elementos não são gerados na ordem do carimbo de data/hora, e a marca d'água se baseia no carimbo de data/hora mínimo não processado.
- Novas tentativas frequentes: se houver algum erro indicando que há falha no processamento de elementos e novas tentativas, talvez os carimbos de data/hora mais antigos de elementos repetidos estejam aumentando a atualização de dados. A lista de erros comuns do Dataflow pode ajudar na solução de problemas.
Para jobs de streaming atualizados recentemente, as informações sobre o estado do job e a marca-d'água podem não estar disponíveis. A operação de atualização faz várias mudanças que levam alguns minutos para serem propagadas até a interface de monitoramento do Dataflow. Tente atualizar a interface de monitoramento cinco minutos depois de atualizar o job.
Latência do sistema
Essa métrica se aplica apenas a jobs de streaming.
A latência do sistema é o número máximo atual de segundos que um item de dados ficou processando ou aguardando processamento. A métrica inclui quanto tempo os elementos aguardam dentro de uma fonte. Por exemplo, se um destino de saída parar de aceitar solicitações de gravação por um período, os dados poderão se acumular na origem, fazendo com que a latência do sistema aumente. Se as operações de gravação forem retomadas e o pipeline conseguir acompanhar, a latência do sistema voltará ao nível de base.
Os casos a seguir são considerações extras:
- Para várias fontes e coletores, a latência do sistema é o tempo máximo que um elemento aguarda dentro de uma fonte antes de ser gravado em todos os coletores.
- Às vezes, uma fonte não fornece um valor do período de tempo em que um elemento aguarda dentro da fonte. Além disso, o elemento pode não ter metadados para definir o horário do evento. Nesse cenário, a latência do sistema é calculada desde o momento em que o pipeline recebe o elemento pela primeira vez.
O painel inclui estes quatro gráficos:
- Latência do sistema por etapas
- Latência do sistema

Capacidade
A capacidade é o volume de dados processados a qualquer momento. O painel inclui os seguintes gráficos:
- Capacidade de processamento por etapa em elementos por segundo
- Capacidade de processamento por etapa em bytes por segundo

Contagem do registro de erros do worker
A contagem de registros de erros do worker mostra a taxa de erros observada em todos os workers a qualquer momento.

Métricas de streaming
As seguintes métricas aparecem em Métricas de streaming.
Backlog
Essa métrica se aplica apenas a jobs de streaming.
O painel Pendente fornece informações sobre os elementos que estão aguardando o processamento. O painel inclui estes quatro gráficos:
- Segundos de backlog (somente mecanismo de streaming)
- Bytes do backlog (com e sem o Streaming Engine)
O gráfico de segundos de backlog mostra uma estimativa do tempo em segundos necessário para consumir o backlog atual se nenhum dado novo chegar e a capacidade de processamento não for alterada. O tempo estimado do backlog é calculado a partir da capacidade de processamento e dos bytes do backlog da fonte de entrada que ainda precisam ser processadas. Essa métrica é usada pelo recurso de escalonamento automático de streaming para determinar quando fazer o escalonamento vertical ou horizontal.

O gráfico Bytes de backlog mostra a quantidade de entradas não processadas conhecidas de um estágio em bytes. Esta métrica compara os bytes restantes a serem consumidos por cada estágio em relação aos estágios upstream. Para que essa métrica seja informada com precisão, cada origem ingerida pelo pipeline precisa ser configurada corretamente. Origens nativas, como o Pub/Sub e o BigQuery, já são compatíveis imediatamente. No entanto, algumas origenspersonalizadas precisam de implementação extra. Para mais detalhes, consulte escalonamento automático para fontes ilimitadas personalizadas.

Processando
Essa métrica se aplica apenas a jobs de streaming.
Quando você executa um pipeline do Apache Beam no serviço Dataflow, as tarefas do pipeline são executadas em VMs de worker. O painel Processamento fornece informações sobre o tempo de processamento das tarefas nas VMs de worker. O painel inclui estes quatro gráficos:
- Mapa de calor de latência do processamento de usuários
- Latências de processamento de usuários por estágio
O mapa de calor de latências de processamento mostra as latências máximas de operações do usuário nas distribuições de percentis 50, 95 e 99. Use o mapa de calor para ver se alguma operação de cauda longa está causando alta latência geral do sistema ou impactando negativamente a atualização geral de dados.
Para corrigir um problema de upstream antes que ele se torne um problema de downstream, defina uma política de alertas para altas latências no percentil 50.

O gráfico Latências de processamento de usuários por estágio mostra o 99º percentil de todas as tarefas que os workers estão processando por estágio. Se o código do usuário estiver causando um gargalo, este gráfico mostrará qual etapa contém o gargalo. Use as etapas a seguir para depurar o pipeline:
Use o gráfico para encontrar uma etapa com uma latência muito alta.
Na página "Detalhes do job", na guia Detalhes da execução, em Visualização de gráfico, selecione Fluxo de trabalho da fase. No gráfico Fluxo de trabalho da fase, encontre a fase que tem uma latência excepcionalmente alta.
Para encontrar as operações de usuário associadas, clique no nó dessa etapa no gráfico.
Para encontrar mais detalhes, navegue até o Cloud Profiler e use o Cloud Profiler para depurar o stack trace no período correto. Procure as operações de usuário identificadas na etapa anterior.

Paralelismo
Essa métrica se aplica apenas a jobs do Streaming Engine.
O gráfico Processamento paralelo mostra o número aproximado de chaves em uso para o processamento de dados de cada estágio. O Dataflow é escalonável com base no paralelismo de um pipeline.
Quando o Dataflow executa um pipeline, o processamento é distribuído por várias máquinas virtuais (VMs) do Compute Engine, também conhecidas como workers. O serviço Dataflow carrega em paralelo e distribui automaticamente a lógica de processamento em seu pipeline para os workers. O processamento de qualquer chave é serializado para que o número total de chaves em um estágio represente o paralelismo máximo disponível no estágio.
As métricas de paralelismo podem ser úteis para encontrar teclas de atalho ou gargalos em pipelines lentos ou travados.

Persistência
Essa métrica se aplica apenas a jobs de streaming.
O painel Persistência contém informações sobre a taxa em que o armazenamento permanente é gravado e lido por uma etapa específica do pipeline em bytes por segundo. Os bytes lidos e gravados incluem operações de estado do usuário e estado para embaralhamentos persistentes, duplicar remoção, entradas secundárias e rastreamento de marca-d'água. Os codificadores de pipeline e o armazenamento em cache afetam bytes lidos e gravados. Bytes de armazenamento podem ser diferentes de bytes processados devido a armazenamento interno e armazenamento em cache.
O painel inclui estes quatro gráficos:
- Gravação de armazenamento
- Leitura de armazenamento

Cópias
Essa métrica se aplica apenas a jobs de streaming.
O gráfico Cópias mostra o número de mensagens processadas por uma fase específica que foram filtradas como cópias.
O Dataflow é compatível com muitas origens e coletores que garantem a entrega de at least once. A desvantagem da exibição de at least once é que ela pode resultar em cópias.
O Dataflow garante a entrega exactly once, o que significa que as cópias são filtradas automaticamente.
Os estágios downstream são salvos do reprocessamento dos mesmos elementos, o que garante que o estado e as saídas não sejam afetados.
Para otimizar o pipeline para recursos e desempenho, reduza o número de cópias produzidas em cada estágio.

Temporizadores
Essa métrica se aplica apenas a jobs de streaming.
O painel Cronômetros fornece informações sobre o número de cronômetros pendentes e o número de cronômetros já processados em uma etapa específica do pipeline. Como as janelas dependem dos timers, essa métrica permite monitorar o progresso das janelas.
O painel inclui estes quatro gráficos:
- Cronômetros pendentes por estágio
- Cronômetros em processamento por estágio
Esses gráficos mostram a taxa de pendência ou processamento de janelas em um momento específico. O gráfico Cronômetros pendentes por estágio indica quantas janelas estão atrasadas devido a gargalos. O gráfico Cronômetros em processamento por etapa indica quantas janelas estão coletando elementos.
Esses gráficos exibem todos os cronômetros de job. Portanto, se os cronômetros forem usados em outro lugar no código, esses cronômetros também aparecerão nesses gráficos.


Métricas de recursos
As seguintes métricas aparecem em Métricas de recursos.
Uso da CPU
O uso da CPU é a quantidade de CPU usada dividida pela quantidade de CPU disponível para processamento. Essa métrica por worker é exibida como uma porcentagem. O painel inclui estes quatro gráficos:
- Uso da CPU (todos os workers)
- Uso da CPU (estatísticas)
- Uso da CPU (Superior 4)
- Uso da CPU (Inferior 4)

Uso de memória
O uso da memória é a quantidade estimada de memória pelos workers em bytes por segundo. O painel inclui estes quatro gráficos:
- Utilização máxima da memória do worker (bytes estimados por segundo)
- Utilização da memória (bytes estimados por segundo)
O gráfico Utilização máxima da memória do worker fornece informações sobre os workers que usam mais memória no job do Dataflow em cada momento. Se, em pontos diferentes durante um job, o trabalho que usa a quantidade máxima de memória for alterado, a mesma linha no gráfico exibirá os dados de vários workers. Cada ponto de dados na linha exibe dados para o worker usando a quantidade máxima de memória naquele momento. O gráfico compara a memória estimada usada pelo worker com o limite de memória em bytes.
Use este gráfico para resolver problemas de falta de memória (OOM, na sigla em inglês). Falhas de falta de memória do worker não são mostradas neste gráfico.
O gráfico Uso de memória mostra uma estimativa da memória usada por todos os workers no job do Dataflow em comparação com o limite de memória em bytes.
Métricas de entrada e saída
Se o job de streaming do Dataflow ler ou gravar registros usando o Pub/Sub, a guia Métricas do job vai mostrar métricas de leitura ou gravação do Pub/Sub.
Todas as métricas de entrada do mesmo tipo são combinadas, e todas as métricas de saída também são combinadas. Por exemplo, todas as métricas do Pub/Sub são agrupadas em uma seção. Cada tipo de métrica é organizado em uma seção separada. Para mudar as métricas exibidas, selecione a seção à esquerda que melhor representa as métricas que você está procurando. As imagens a seguir mostram todas as seções disponíveis.

Os três gráficos a seguir são exibidos nas seções Métricas de entrada e Métricas de saída.

Solicitações por segundo
Solicitações por segundo é a taxa de solicitações de API para ler ou gravar dados pela origem ou coletor ao longo do tempo. Se essa taxa cair para zero ou diminuir significativamente por um período prolongado em relação ao comportamento esperado, o pipeline talvez esteja impedido de executar determinadas operações. Além disso, talvez não haja dados para ler. Nesse caso, analise as etapas do job que tiverem uma marca d'água de sistema alta. Examine também os registros de worker para verificar se há erros ou indicações sobre o processamento lento.

Erros de resposta por segundo de acordo com o tipo de erro
A taxa de erros de resposta por segundo por tipo de erro é a taxa de solicitações de API para ler ou gravar dados com falha por origem ou por coletor ao longo do tempo. Se esses erros ocorrerem com frequência, essas solicitações de API podem atrasar o processamento. As solicitações de API com falha precisam ser investigadas. Para ajudar a resolver esses problemas, consulte os códigos de erro de entrada e saída. Analise também qualquer documentação de código de erro específica usada pela origem ou pelo coletor, como os códigos de erro do Pub/Sub.

Para mais informações sobre cenários em que você pode usar essas métricas para depuração, consulte Ferramentas para depuração em "Resolver problemas de jobs lentos ou travados".
Usar o Cloud Monitoring
O Dataflow é totalmente integrado ao Cloud Monitoring. Use o Cloud Monitoring para as seguintes tarefas:
- Crie alertas quando seu job exceder um limite definido pelo usuário.
- Use o Metrics Explorer para criar consultas e ajustar o período das métricas.
- Veja métricas que não aparecem na interface de monitoramento do Dataflow.
Para instruções sobre como criar alertas e usar o Metrics Explorer, consulte Usar o Cloud Monitoring para pipelines do Dataflow.
Para acessar a lista completa de métricas do Dataflow, consulte a documentação sobre métricas do Google Cloud Platform.
Criar alertas do Cloud Monitoring
O Cloud Monitoring permite criar alertas quando o job do Dataflow excede um limite definido pelo usuário. Para criar um alerta do Cloud Monitoring a partir de um gráfico de métricas, clique em Criar política de alertas.
Se você não conseguir ver os gráficos de monitoramento ou criar alertas, talvez precise de mais permissões de monitoramento.
Ver no Metrics Explorer
Veja os gráficos de métricas do Dataflow no Metrics Explorer, onde é possível criar consultas e ajustar o período das métricas.
Para ver os gráficos do Dataflow no Metrics Explorer, na visualização Métricas do job, abra Mais opções de gráfico e clique em Ver no Metrics Explorer.
Ao ajustar o período das métricas, é possível selecionar uma duração predefinida ou um intervalo de tempo personalizado para analisar o job.
Por padrão, para jobs de streaming e jobs em lote em andamento, a exibição mostra as seis horas anteriores de métricas desse job. Para jobs de streaming interrompidos ou concluídos, a exibição padrão mostra todo o ambiente de execução da duração do job.
Métricas de E/S do Dataflow
Veja as seguintes métricas de E/S do Dataflow no Metrics Explorer:
job/pubsub/write_count: solicitações de publicação do Pub/Sub de PubsubIO.Write em jobs do Dataflow.job/pubsub/read_count: solicitações de envio do Pub/Sub de Pubsub.IO.Read em jobs do Dataflow.job/bigquery/write_count: solicitações de publicação do BigQuery do BigQueryIO.Write em jobs do Dataflow. As métricasjob/bigquery/write_countestão disponíveis em pipelines do Python usando a transformação WriteToBigQuery commethod='STREAMING_INSERTS'ativado no Apache Beam v2.28.0 ou posterior. Essa métrica está disponível para pipelines de lote e streaming.- Se o pipeline usar uma origem ou um coletor do BigQuery, use as métricas da API BigQuery Storage para resolver problemas de cota.
Métricas de DoFn
Para jobs de streaming que usam o Streaming Engine
e não usam o Runner v2, é possível conferir as seguintes
métricas para DoFns individuais definidos pelo usuário:
job/dofn_latency_average: o tempo médio de processamento de mensagens para um únicoDoFnnos últimos 3 minutos, em milissegundos.job/dofn_latency_max: o tempo máximo de processamento de mensagens para um únicoDoFnnos últimos três minutos, em milissegundos.job/dofn_latency_min: O tempo mínimo de processamento de mensagens para um únicoDoFnnos últimos 3 minutos, em milissegundos.job/dofn_latency_num_messages: o número de mensagens processadas por um únicoDoFnnos últimos três minutos.job/dofn_latency_total: o tempo total de processamento de todas as mensagens em um únicoDoFnnos últimos três minutos, em milissegundos.job/oldest_active_message_age: há quanto tempo a mensagem ativa mais antiga está sendo processada em umDoFn, em milissegundos.
Essas métricas exigem a versão 2.53.0 ou mais recente do SDK do Apache Beam. Para conferir essas métricas, use o Metrics Explorer.
Use essas métricas para descobrir quais DoFns contribuem mais para a latência de processamento nos seus jobs. Por exemplo, se um job estiver travado, use a métrica job/oldest_active_message_age para encontrar o DoFn com a mensagem ativa mais antiga. A imagem a seguir mostra um DoFn com um pico grande nessa métrica:
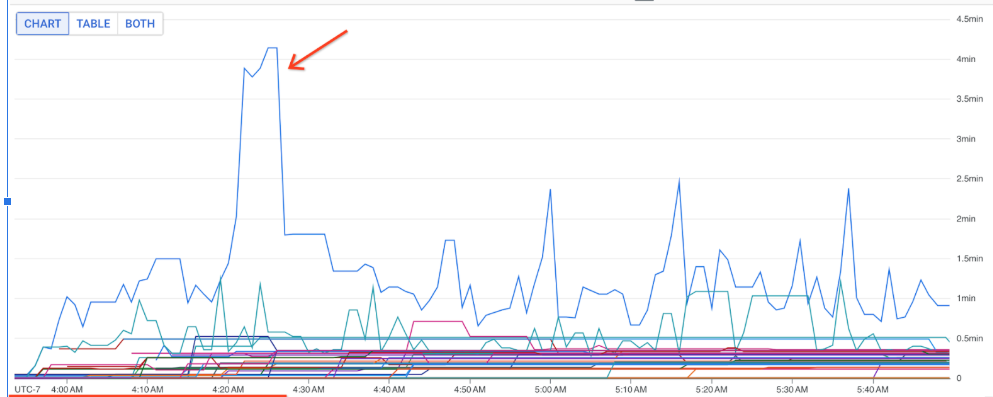
Para ver o nome do DoFn, mantenha o ponteiro sobre a linha do gráfico.
A seguir
- Resolver problemas de jobs de streaming lentos ou travados.
- Resolver problemas de jobs em lote lentos ou travados.
- Ajustar o escalonamento automático horizontal para pipelines de streaming
- Otimizar custos