O Cloud Profiler é um criador de perfil estatístico de baixa sobrecarga. Ele coleta continuamente informações de uso de CPU e de alocação de memória dos aplicativos em produção. Para mais detalhes, consulte Conceitos da criação de perfil. Para solucionar problemas ou monitorar o desempenho do pipeline, use a integração do Dataflow com o Cloud Profiler para identificar as partes do código do pipeline que mais consomem recursos.
Para dicas de solução de problemas e estratégias de depuração para criar ou executar seu pipeline do Dataflow, consulte Solução de problemas e pipelines de depuração.
Antes de começar
Entenda os conceitos de criação de perfil e se familiarize com a interface do Criador de perfil. Para saber como começar a usar a interface do Criador de perfil, consulte Selecionar os perfis para analisar.
A API Cloud Profiler precisa estar ativada no projeto para que o job seja iniciado.
Ela é ativada automaticamente na primeira vez que você visita a página
do Profiler.
Se preferir, ative a API Cloud Profiler usando a
ferramenta de linha de comando gcloud da CLI do Google Cloud ou o console do Google Cloud.
Para usar o Cloud Profiler, seu projeto precisa ter cota suficiente.
Além disso,
a conta de serviço do worker
do Dataflow precisa ter as permissões apropriadas para o Profiler. Por exemplo, para criar
perfis, a conta de serviço do worker precisa ter a permissão
cloudprofiler.profiles.create, que está incluída no papel do IAM de agente do Cloud Profiler
(roles/cloudprofiler.agent).
Saiba mais em Controle de acesso com o IAM.
Ativar o Cloud Profiler para pipelines do Dataflow
O Cloud Profiler está disponível para pipelines do Dataflow escritos no SDK do Apache Beam para Java e Python, versão 2.33.0 ou posterior. Os pipelines do Python precisam usar o Dataflow Runner v2. O Cloud Profiler pode ser ativado no horário de início do pipeline. A sobrecarga amortizada da CPU e da memória precisa ser inferior a 1% para os pipelines.
Java
Para ativar a criação de perfil da CPU, inicie o pipeline com a opção a seguir.
--dataflowServiceOptions=enable_google_cloud_profiler
Para ativar a criação de perfil de alocação por heap, inicie o pipeline com as seguintes opções. A criação desse perfil requer o Java 11 ou mais recente.
--dataflowServiceOptions=enable_google_cloud_profiler
--dataflowServiceOptions=enable_google_cloud_heap_sampling
Python
Para usar o Cloud Profiler, o pipeline do Python precisa ser executado com o Dataflow Runner v2.
Para ativar a criação de perfil da CPU, inicie o pipeline com a opção a seguir. A criação de perfil por heap ainda não é compatível com Python.
--dataflow_service_options=enable_google_cloud_profiler
Go
Para ativar a criação de perfil de alocação heap e CPU, inicie o pipeline com a opção a seguir.
--dataflow_service_options=enable_google_cloud_profiler
Se você implantar os pipelines com base em modelos do Dataflow e quiser ativar o Cloud Profiler,
especifique as sinalizações enable_google_cloud_profiler e
enable_google_cloud_heap_sampling como experimentos adicionais.
Console
Se você usa um modelo fornecido pelo Google, pode especificar as sinalizações na página Criar job usando um modelo no campo Outros experimentos.
gcloud
Se você usa a CLI do Google Cloud para executar
modelos gcloud
dataflow jobs run ou gcloud dataflow flex-template run, dependendo
do tipo, use a opção --additional-experiments para especificar as sinalizações.
API
Se você usar a API
REST para executar modelos, dependendo do tipo, especifique as sinalizações usando o campo
additionalExperiments do ambiente de execução, RuntimeEnvironment ou FlexTemplateRuntimeEnvironment.
Ver os dados de criação de perfil
Se o Cloud Profiler estiver ativado, um link para a página do Profiler será mostrado na página do job.
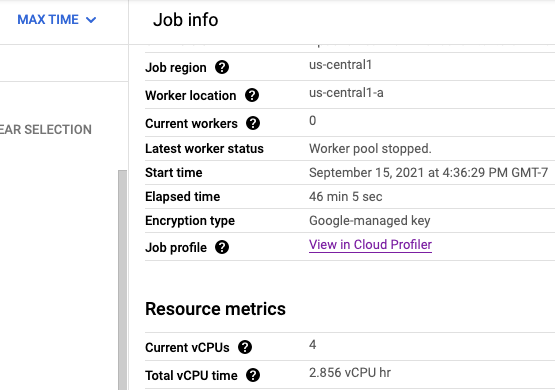
Na página do Profiler, você também encontra os dados de criação de perfil do pipeline do Dataflow. Serviço é o nome do job e Versão é o ID do job.

Como usar o Cloud Profiler
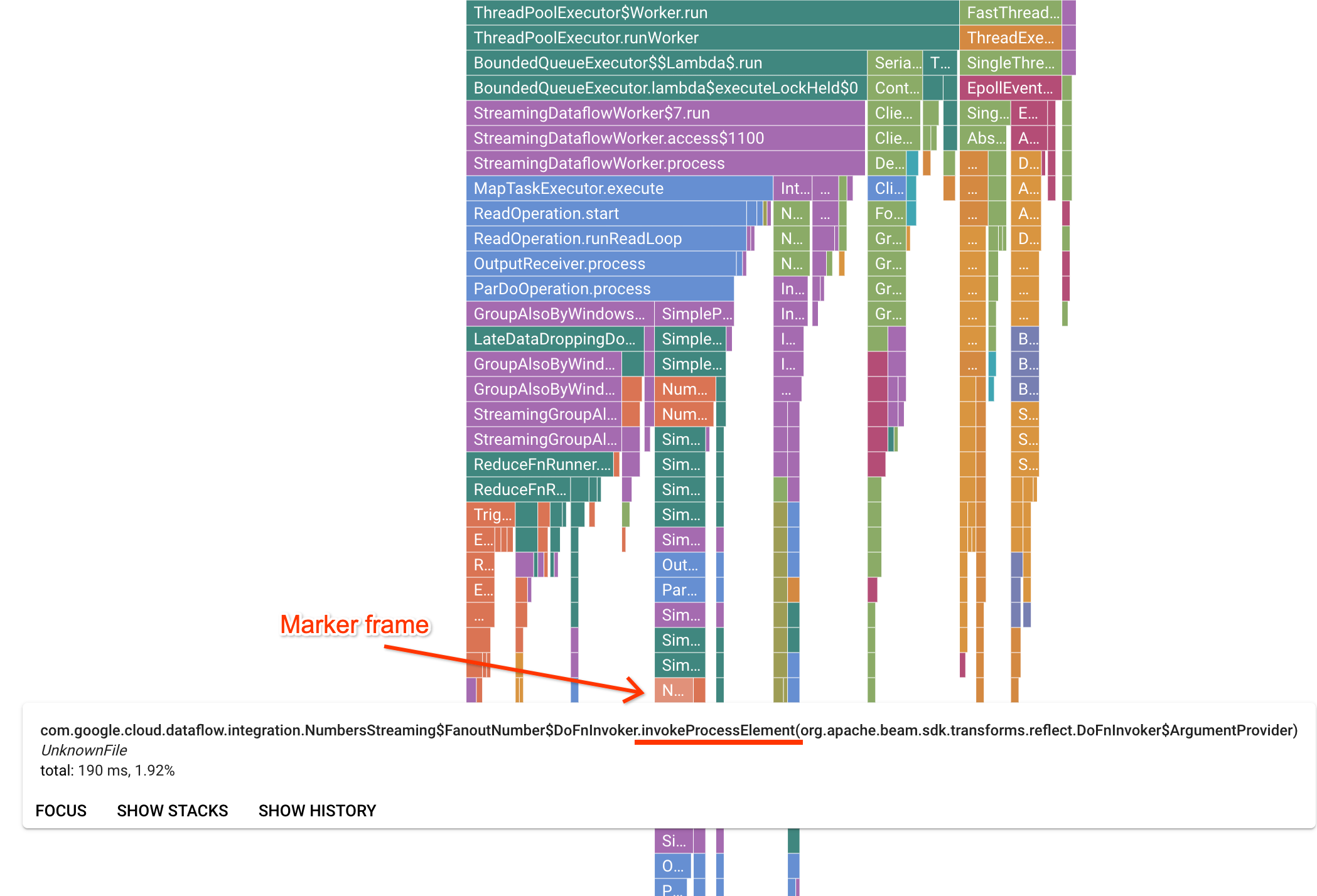
A página do Profiler contém um gráfico de chama que mostra as estatísticas de cada quadro executado em um worker. Na direção horizontal, você pode ver quanto tempo cada frame levou para ser executado em termos de tempo de CPU. Na direção vertical, é possível ver stack traces e o código em execução em paralelo. Os stack traces são dominados pelo código da infraestrutura do executor. Para fins de depuração, geralmente estamos interessados na execução do código do usuário, que, geralmente, é encontrada perto das dicas da parte inferior do gráfico. Para identificar o código do usuário, procure frames de marcadores, que representam o código do executor conhecido por chamar apenas o código do usuário. No caso do executor do Beam ParDo, uma camada de adaptador dinâmico é criada para invocar a assinatura do método DoFn fornecida pelo usuário. Essa camada pode ser identificada como um frame com o sufixo invokeProcessElement. A imagem a seguir mostra como encontrar um frame de marcador.
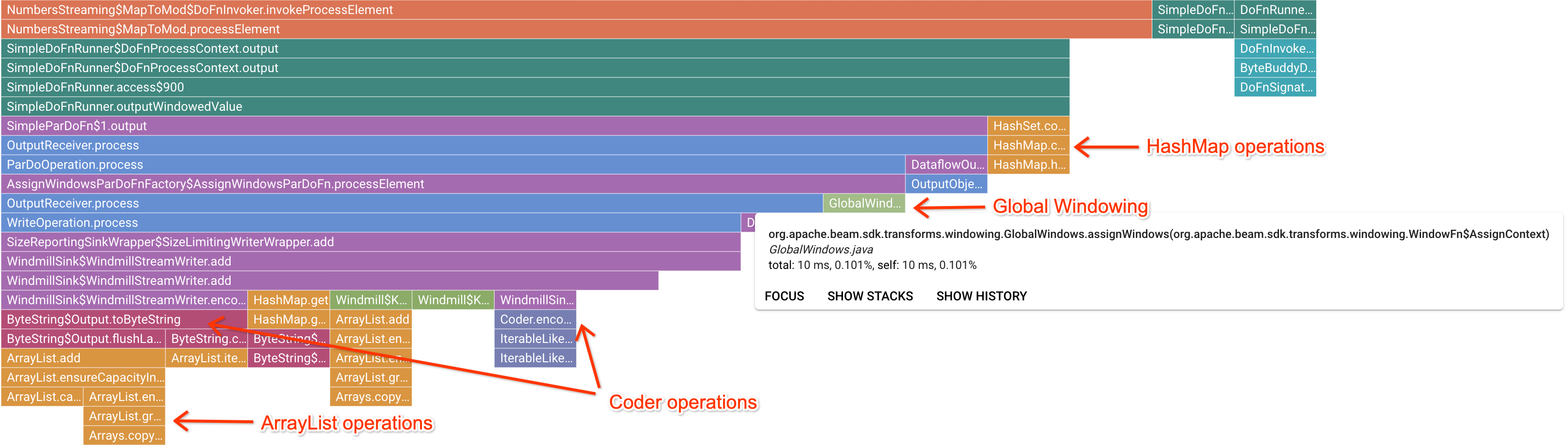
Após clicar em um frame de marcador interessante, o gráfico em degradê se concentra no stack trace, dando uma boa noção de um código de usuário de longa duração. As operações mais lentas podem indicar onde os gargalos se formaram e apresentam oportunidades de otimização. No exemplo a seguir, é possível ver que a gestão de janelas global está sendo usada com um ByteArrayCoder. Nesse caso, o codificador pode ser uma boa área para otimização, já que está ocupando um tempo de CPU significativo em comparação com as operações ArrayList e HashMap.
Resolver problemas do Cloud Profiler
Se você ativar o Cloud Profiler e o pipeline não gerar dados de criação de perfil, a causa poderá ser uma das condições a seguir.
O pipeline usa uma versão mais antiga do SDK do Apache Beam. Para usar o Cloud Profiler, você precisa da versão 2.33.0 ou mais recente do SDK do Apache Beam. É possível visualizar a versão do SDK do Apache Beam do pipeline na página do job. Se o job for criado com base em modelos do Dataflow, os modelos vão precisar usar as versões compatíveis do SDK.
Seu projeto está quase sem cota do Cloud Profiler. Veja o uso da cota na página de cotas do seu projeto. Um erro como
Failed to collect and upload profile whose profile type is WALLpoderá ocorrer se a cota do Cloud Profiler for excedida. O serviço Cloud Profiler rejeita os dados de criação de perfil se você tiver atingido a cota. Saiba mais sobre as cotas do Cloud Profiler em Cotas e limites.Seu job não foi executado por tempo suficiente para gerar dados para o Cloud Profiler. Jobs que são executados por períodos curtos, como menos de cinco minutos, podem não fornecer dados de perfil suficientes para que o Cloud Profiler gere resultados.
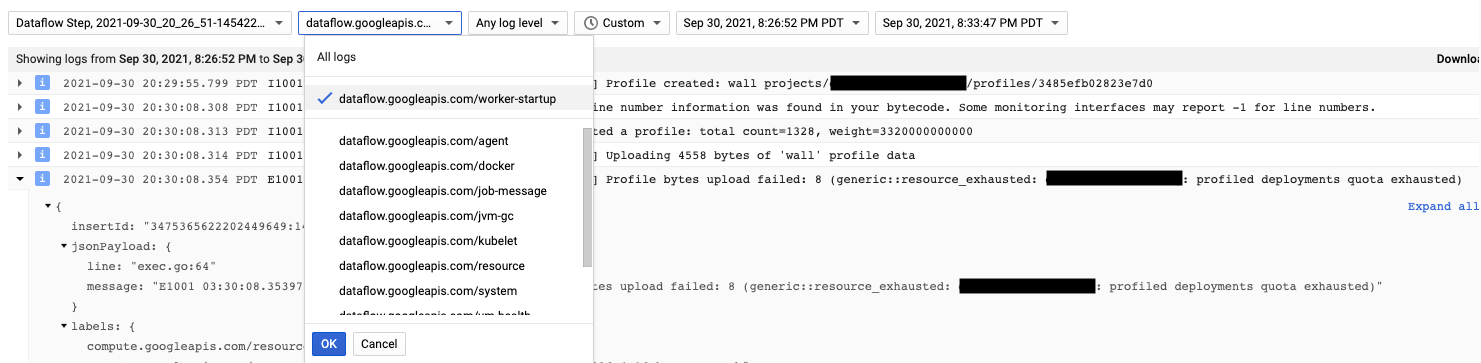
O agente do Cloud Profiler é instalado durante a inicialização do worker no Dataflow. As mensagens de registro geradas pelo Cloud Profiler estão disponíveis no tipo de registro dataflow.googleapis.com/worker-startup.
Às vezes, há dados de criação de perfil, mas o Cloud Profiler não exibe nenhuma saída. O Profiler exibe uma mensagem semelhante a There were
profiles collected for the specified time range, but none match the current
filters.
Para resolver esse problema, tente as seguintes etapas de solução de problemas:
Verifique se o período e o horário de término no Profiler incluem o tempo decorrido do job.
Confirme se o job correto está selecionado no Profiler. O Serviço é o nome do job.
Confirme se a opção
job_namedo pipeline tem o mesmo valor que o nome do job na página de jobs do Dataflow.Se você especificou um argumento service-name ao carregar o agente do Profiler, confirme se o nome do serviço está configurado corretamente.