É possível visualizar gráficos de monitoramento do escalonamento automático para jobs de streaming na interface de monitoramento do Dataflow. Esses gráficos mostram métricas ao longo da duração de um job de pipeline e incluem as seguintes informações:
- O número de instâncias de worker usadas pelo job a qualquer momento
- Os arquivos de registro de escalonamento automático
- Backlog estimado ao longo do tempo
- O uso médio da CPU ao longo do tempo
Os gráficos são alinhados verticalmente para que você possa correlacionar as métricas de utilização de backlog e CPU com eventos de escalonamento do worker.
Para mais informações sobre como o Dataflow toma decisões de escalonamento automático, consulte a documentação Recursos de ajuste automático. Para mais informações sobre o monitoramento e as métricas do Dataflow, consulte Usar a interface de monitoramento do Dataflow.
Acessar gráficos de monitoramento do escalonamento automático
É possível acessar a interface de monitoramento do Dataflow usando o Google Cloud console. Para acessar a guia de métricas Escalonamento automático, siga estas etapas:
- Faça login no console Google Cloud .
- Selecionar o projeto Google Cloud .
- Abra o Menu de navegação.
- No Google Analytics, clique em Dataflow. Uma lista de jobs do Dataflow é exibida junto com o status deles.
- Clique no job que você quer monitorar e, em seguida, na guia Escalonamento automático.
Monitorar métricas de escalonamento automático
O serviço Dataflow escolhe automaticamente o número de instâncias de worker necessárias para executar o job de escalonamento automático. O número de instâncias de worker pode mudar com o tempo de acordo com os requisitos do job.
É possível visualizar métricas de escalonamento automático na guia Escalonamento automático da interface do Dataflow. Cada métrica é organizada nos seguintes painéis:
A barra de ações de escalonamento automático exibe o status atual do escalonamento automático e a contagem de workers.
Escalonamento automático
O gráfico de escalonamento automático mostra um gráfico de série temporal do número atual de workers, da meta de workers e do número mínimo e máximo de workers.

Para ver os registros de escalonamento automático, clique em Mostrar registros de escalonamento automático.
Para ver o histórico de alterações do escalonamento automático, clique em Mais histórico. Uma tabela com informações sobre o histórico do worker do pipeline é exibida. O histórico inclui eventos de escalonamento automático, incluindo se o número de workers atingiu a contagem mínima ou máxima de workers.

Justificativa do escalonamento automático (somente Streaming Engine)
O gráfico Lógica de escalonamento automático mostra por que o escalonador automático aumentou ou reduziu o escalonamento ou não realizou nenhuma ação durante um determinado período.
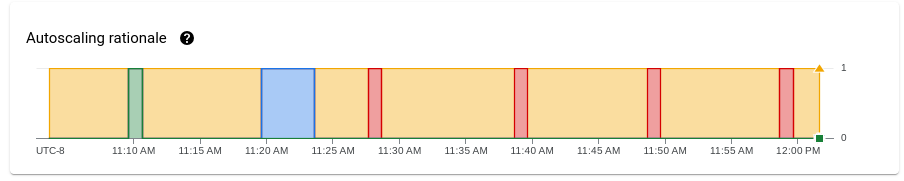
Para ver uma descrição da lógica em um ponto específico, mantenha o ponteiro do mouse sobre o gráfico.
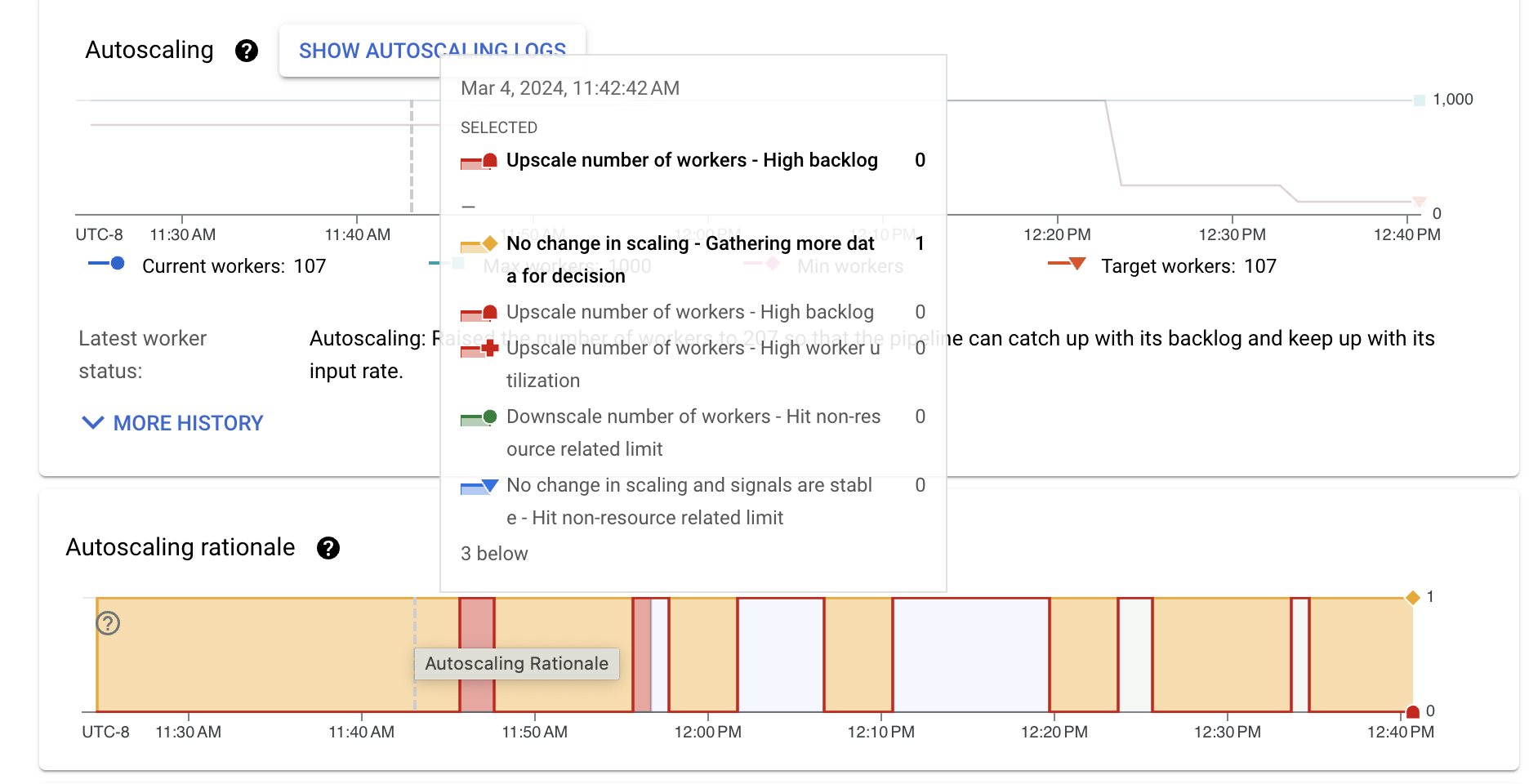
A tabela a seguir lista as ações de escalonamento e as possíveis justificativas de escalonamento.
| Ação de escalonamento | Justificativa | Descrição |
|---|---|---|
| Nenhuma mudança no escalonamento | Como coletar mais dados para tomar decisões | O escalonador automático não tem sinais suficientes para escalonar verticalmente. Por exemplo, o status do pool de workers mudou recentemente; ou as métricas de backlog ou de utilização estão oscilando. |
| Sem mudança no escalonamento, sinais estáveis | Atingiu o limite não relacionado a recursos | O escalonamento é restrito por um limite, como o paralelismo de chave ou os workers mínimos e máximos configurados. |
| Baixo backlog e alto uso de workers | O escalonamento automático do pipeline convergiu para um valor estável, dado o tráfego e a configuração atuais. Nenhuma mudança de escalonamento é necessária. | |
| Escalonar verticalmente | Backlog alto | Escalonamento vertical para reduzir o backlog. |
| Alta utilização de workers | Como escalonar verticalmente para alcançar a meta de uso da CPU. | |
| Atingir um limite não relacionado a recursos | O número mínimo de workers foi atualizado, e o número atual está abaixo do mínimo configurado. | |
| Diminuir a escala | Baixa utilização de workers | Redução para alcançar a meta de uso da CPU. |
| Atingir um limite não relacionado a recursos | O número máximo de workers foi atualizado, e o número atual está acima do máximo configurado. |
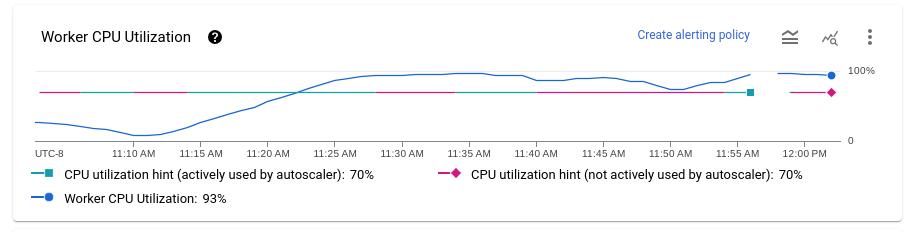
Utilização de CPU de workers
O uso da CPU é a quantidade de CPU usada dividida pela quantidade de CPU disponível para processamento. O gráfico Utilização média da CPU mostra a utilização média da CPU para todos os workers ao longo do tempo, a dica de utilização do worker e se o Dataflow usou ativamente o Dataflow como um alvo.
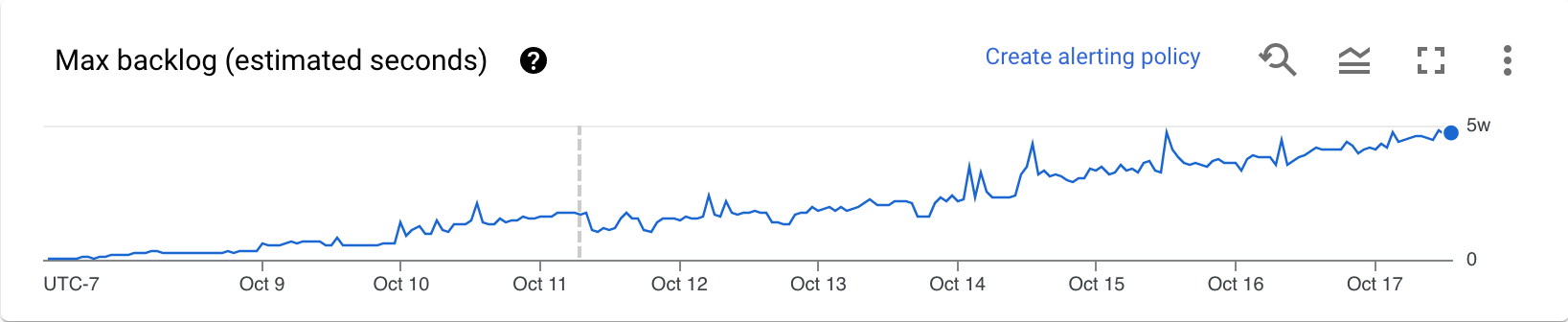
Backlog (somente mecanismo de streaming)
O gráfico Backlog máximo fornece informações sobre elementos que estão aguardando o processamento. O gráfico de segundos de backlog mostra uma estimativa do tempo em segundos necessário para consumir o backlog atual se nenhum dado novo chegar e a capacidade de processamento não for alterada. O tempo estimado do backlog é calculado a partir da capacidade de processamento e dos bytes do backlog da fonte de entrada que ainda precisam ser processadas. Essa métrica é usada pelo recurso de escalonamento automático de streaming para determinar quando fazer o escalonamento vertical ou horizontal.
Os dados deste gráfico só estão disponíveis para jobs que usam o Streaming Engine. Se o job de streaming não usar o mecanismo de streaming, o gráfico estará vazio.
Recomendações
Confira alguns comportamentos que podem ser observados no pipeline e recomendações sobre como ajustar o escalonamento automático:
Redução excessiva: Se a meta de uso da CPU for definida como muito alta, talvez você veja um padrão em que o Dataflow reduz a escala vertical, o backlog começa a crescer e o Dataflow volta a escalonar para compensar, em vez de convergir em um número estável de workers. Para atenuar esse problema, tente definir uma dica de utilização do worker menor. Observe a utilização da CPU no ponto em que o backlog começa a aumentar e defina a dica de utilização para esse valor.
Aumento lento demais. Se o escalonamento automático for muito lento, ele poderá atrasar os picos de tráfego, resultando em períodos de maior latência. Tente reduzir a dica de utilização do worker para que o Dataflow escalone mais rapidamente. Observe a utilização da CPU no ponto em que o backlog começa a aumentar e defina a dica de utilização para esse valor. Monitore a latência e o custo, porque um valor de dica menor poderá aumentar o custo total para o pipeline, se mais workers forem provisionados.
Aumento excessivo do escalonamento. Se você observar o aumento do escalonamento, resultando em aumento dos custos, considere aumentar a dica de utilização do worker. Monitore a latência para garantir que ela permaneça dentro dos limites aceitáveis para seu cenário.
Para mais informações, consulte Definir a dica de utilização do worker. Quando você testar um novo valor de dica de utilização do worker, aguarde alguns minutos até que o pipeline se estabilize após cada ajuste.
A seguir
- Ajustar o escalonamento automático horizontal para pipelines de streaming
- Resolver problemas de escalonamento automático do Dataflow