Cette page explique comment identifier et résoudre les erreurs de mémoire saturée (OOM, Out Of Memory) dans Dataflow.
Trouver les erreurs de mémoire saturée
Pour déterminer si votre pipeline manque de mémoire, utilisez l'une des méthodes suivantes.
- Sur la page Informations sur les tâches, dans le volet Journaux, affichez l'onglet Diagnostic. Cet onglet affiche les erreurs liées à des problèmes de mémoire et leur fréquence.
- Dans l'interface de surveillance de Dataflow, utilisez le graphique Utilisation de la mémoire pour surveiller la capacité et l'utilisation de la mémoire des nœuds de calcul.
- Sur la page Informations sur les tâches, dans le volet Journaux, sélectionnez Journaux des nœuds de calcul pour rechercher les erreurs de mémoire insuffisante dans les journaux des nœuds de calcul.
Des erreurs de mémoire insuffisante peuvent également apparaître dans les journaux système. Pour les afficher, accédez à l'explorateur de journaux et utilisez la requête suivante:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID " "out of memory" OR "OutOfMemory" OR "Shutting down JVM"Remplacez JOB_ID par l'ID de votre tâche.
Pour les tâches Java, le moniteur de mémoire Java génère régulièrement des métriques de récupération de mémoire. Si la fraction de temps de processeur utilisée pour la récupération de mémoire dépasse un seuil de 50% pendant une période prolongée, le SDK harness échoue. Un message d'erreur semblable à l'exemple suivant peut s'afficher:
Shutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = ...Cette erreur peut se produire lorsque la mémoire physique est toujours disponible et indique généralement que l'utilisation de la mémoire du pipeline est inefficace. Pour résoudre ce problème, optimisez votre pipeline.
Le moniteur de mémoire Java est configuré par l'interface
MemoryMonitorOptions.
Si votre job présente une utilisation élevée de la mémoire ou des erreurs de mémoire insuffisante, suivez les recommandations de cette page pour optimiser l'utilisation de la mémoire ou augmenter la quantité de mémoire disponible.
Résoudre les erreurs de mémoire insuffisante
Les modifications apportées à votre pipeline Dataflow peuvent résoudre les erreurs de mémoire insuffisante ou réduire l'utilisation de la mémoire. Les modifications possibles incluent les actions suivantes :
- Optimiser votre pipeline
- Réduire le nombre de threads
- Utiliser un type de machine avec davantage de mémoire par processeur virtuel
Le schéma suivant illustre le workflow de dépannage Dataflow décrit sur cette page.
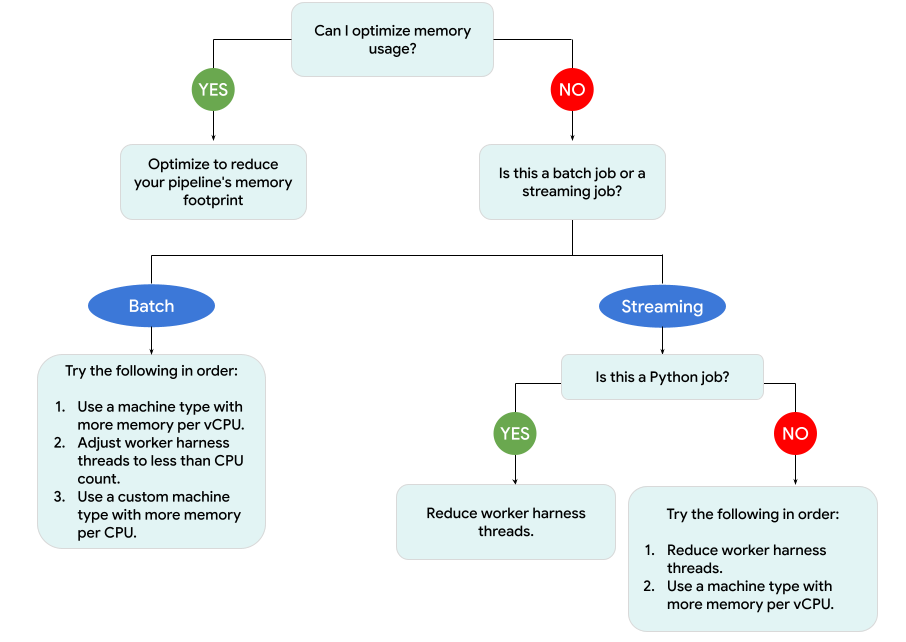
Essayez les mesures d'atténuation suivantes:
- Si possible, optimisez votre pipeline pour réduire l'utilisation de la mémoire.
- Si la tâche est une tâche par lot, procédez comme suit dans l'ordre indiqué :
- Utilisez un type de machine avec davantage de mémoire par processeur virtuel.
- Réduisez le nombre de threads à un nombre inférieur au nombre de processeurs virtuels par nœud de calcul.
- Utilisez un type de machine personnalisé avec plus de mémoire par processeur virtuel.
- Si la tâche est une tâche de streaming qui utilise Python, réduisez le nombre de threads à moins de 12.
- Si la tâche est un job de streaming qui utilise Java ou Go, procédez comme suit :
- Réduisez le nombre de threads à moins de 500 pour les jobs Runner v2 ou à moins de 300 pour les jobs qui n'utilisent pas Runner v2.
- Utilisez un type de machine avec davantage de mémoire.
Optimiser votre pipeline
Plusieurs opérations de pipeline peuvent entraîner des erreurs de mémoire saturée. Cette section fournit des options permettant de réduire l'utilisation de la mémoire de votre pipeline. Pour identifier les étapes du pipeline qui consomment le plus de mémoire, utilisez Cloud Profiler pour surveiller les performances du pipeline.
Vous pouvez suivre les bonnes pratiques suivantes pour optimiser votre pipeline :
- Utiliser des connecteurs d'E/S intégrés Apache Beam pour lire des fichiers
- Repenser les opérations lors de l'utilisation de PTransforms
GroupByKey - Réduire les données d'entrée provenant de sources externes
- Partager des objets entre les threads
- Utiliser des représentations d'éléments économes en mémoire
- Réduire la taille des entrées secondaires
Utiliser des connecteurs d'E/S intégrés Apache Beam pour lire des fichiers
N'ouvrez pas de fichiers volumineux dans un DoFn. Pour lire des fichiers, utilisez les connecteurs d'E/S intégrés Apache Beam.
Les fichiers ouverts dans un DoFn doivent tenir dans la mémoire. Étant donné que plusieurs instances DoFn s'exécutent simultanément, les fichiers volumineux ouverts dans DoFn peuvent entraîner des erreurs de mémoire insuffisante.
Repenser les opérations lors de l'utilisation de PTransforms GroupByKey
Lorsque vous utilisez une PTransform GroupByKey dans Dataflow, les valeurs de clé et de fenêtre obtenues sont traitées sur un seul thread. Étant donné que ces données sont transmises en tant que flux du service de backend Dataflow aux nœuds de calcul, il n'a pas besoin de tenir dans la mémoire des nœuds de calcul. Toutefois, si les valeurs sont collectées en mémoire, la logique de traitement peut entraîner des erreurs de mémoire insuffisante.
Par exemple, si vous disposez d'une clé contenant des données pour une fenêtre et que vous ajoutez les valeurs de clé à un objet en mémoire, tel qu'une liste, des erreurs de mémoire insuffisante peuvent se produire. Dans ce scénario, le nœud de calcul peut ne pas disposer d'une capacité de mémoire suffisante pour contenir tous les objets.
Pour en savoir plus sur les PTransforms GroupByKey, consultez la documentation Apache Beam sur Python GroupByKey et Java GroupByKey.
La liste suivante contient des suggestions pour concevoir votre pipeline afin de minimiser la consommation de mémoire lorsque vous utilisez des PTransforms GroupByKey.
- Pour réduire la quantité de données par clé et par fenêtre, évitez les clés dotées de nombreuses valeurs, également appelées clés à chaud.
- Pour réduire la quantité de données collectées par fenêtre, utilisez une taille de fenêtre plus petite.
- Si vous utilisez les valeurs d'une clé dans une fenêtre pour calculer un nombre, utilisez une transformation
Combine. N'effectuez pas le calcul dans une seule instanceDoFnaprès avoir collecté les valeurs. - Filtrez les valeurs ou les doublons avant le traitement. Pour en savoir plus, consultez la documentation sur la transformation Python
Filteret JavaFilter.
Réduire les données d'entrée provenant de sources externes
Si vous effectuez des appels à une API externe ou à une base de données pour enrichir les données, les données renvoyées doivent tenir dans la mémoire du nœud de calcul.
Si vous regroupez des appels, nous vous recommandons d'utiliser une transformation GroupIntoBatches.
Si vous rencontrez des erreurs de mémoire insuffisante, réduisez la taille de lot. Pour en savoir plus sur le regroupement en lots, consultez la documentation sur la transformation Python GroupIntoBatches et Java GroupIntoBatches.
Partager des objets entre les threads
Le partage d'un objet de données en mémoire entre les instances DoFn peut améliorer l'efficacité de l'espace et de l'accès. Les objets de données créés dans n'importe quelle méthode de DoFn, y compris Setup, StartBundle, Process, FinishBundle et Teardown, sont appelés pour chaque objet DoFn. Dans Dataflow, chaque nœud de calcul peut avoir plusieurs instances DoFn. Pour une utilisation plus efficace de la mémoire, transmettez un objet de données en tant que singleton à partager sur plusieurs DoFn. Pour en savoir plus, consultez l'article de blog Réutilisation du cache via les DoFn.
Utiliser des représentations d'éléments à mémoire optimisée
Déterminez si vous pouvez utiliser des représentations pour les éléments PCollection qui utilisent moins de mémoire. Lorsque vous utilisez des codeurs dans votre pipeline, pensez non seulement à représenter les représentations d'éléments PCollection codées, mais également décodées. Les matrices creuses peuvent souvent bénéficier de ce type d'optimisation.
Réduire la taille des entrées secondaires
Si vos DoFn utilisent des entrées secondaires, réduisez la taille de l'entrée secondaire. Pour les entrées secondaires qui sont des collections d'éléments, envisagez d'utiliser des vues itérables, telles que AsIterable ou AsMultimap, plutôt que des vues qui matérialisent en totalité l'entrée secondaire, par exemple AsList.
Réduire le nombre de threads
Vous pouvez augmenter la mémoire disponible par thread en réduisant le nombre maximal de threads exécutant des instances DoFn. Cette modification réduit le parallélisme, mais rend plus de mémoire disponible pour chaque DoFn.
Le tableau suivant indique le nombre de threads par défaut créés par Dataflow:
| Type de job | SDK Python | SDK Java/Go |
|---|---|---|
| Lot | 1 thread par processeur virtuel | 1 thread par processeur virtuel |
| Streaming avec l'exécuteur v2 | 12 threads par processeur virtuel | 500 threads par VM de nœud de calcul |
| Streaming sans l'exécuteur v2 | 12 threads par processeur virtuel | 300 threads par VM de nœud de calcul |
Pour réduire le nombre de threads du SDK Apache Beam, définissez l'option de pipeline suivante:
Utilisez l'option de pipeline --numberOfWorkerHarnessThreads.
Utilisez l'option de pipeline --number_of_worker_harness_threads.
Utilisez l'option de pipeline --number_of_worker_harness_threads.
Pour les tâches par lot, définissez la valeur sur un nombre inférieur au nombre de processeurs virtuels.
Pour les jobs traités par flux, commencez par réduire la valeur à la moitié de la valeur par défaut. Si cette étape ne résout pas le problème, continuez à réduire la valeur de moitié, en observant les résultats à chaque étape. Par exemple, si vous utilisez Python, essayez les valeurs 6, 3 et 1.
Utilisez un type de machine avec davantage de mémoire par processeur virtuel
Pour sélectionner un nœud de calcul disposant de plus de mémoire par processeur virtuel, utilisez l'une des méthodes suivantes.
- Utilisez un type de machine à haute capacité de mémoire dans la famille de machines à usage général. Les types de machines à haute capacité de mémoire disposent de plus de mémoire par processeur virtuel que les types de machines standards. L'utilisation d'un type de machine à haute capacité de mémoire augmente la mémoire disponible pour chaque nœud de calcul et la mémoire disponible par thread, car le nombre de processeurs virtuels reste le même. Par conséquent, l'utilisation d'un type de machine à haute capacité de mémoire peut être un moyen économique de sélectionner un nœud de calcul disposant de plus de mémoire par processeur virtuel.
- Pour plus de flexibilité lors de la spécification du nombre de processeurs virtuels et de la quantité de mémoire, vous pouvez utiliser un type de machine personnalisé. Avec les types de machines personnalisés, vous pouvez augmenter la mémoire par incréments de 256 Mo. Ces types de machines sont tarifés différemment des types de machines standards.
- Certaines familles de machines vous permettent d'utiliser des types de machines personnalisés avec extension de mémoire. L'extension de mémoire permet d'augmenter le ratio mémoire par vCPU. Le coût est plus élevé.
Pour définir les types de nœuds de calcul, utilisez l'option de pipeline suivante. Pour en savoir plus, consultez les pages Définir les options de pipeline et Options de pipeline.
Utilisez l'option de pipeline --workerMachineType.
Utilisez l'option de pipeline --machine_type.
Utilisez l'option de pipeline --worker_machine_type.
Comprendre l'utilisation de la mémoire Dataflow
Pour résoudre les erreurs de mémoire insuffisante, il est utile de comprendre comment les pipelines Dataflow utilisent la mémoire.
Lorsque Dataflow exécute un pipeline, le traitement est réparti sur plusieurs machines virtuelles (VM) Compute Engine, souvent appelées nœuds de calcul.
Les nœuds de calcul traitent les éléments de travail du service Dataflow et délèguent les éléments de travail aux processus du SDK Apache Beam. Un processus du SDK Apache Beam crée des instances de DoFn. DoFn est une classe du SDK Apache Beam qui définit une fonction de traitement distribué.
Dataflow lance plusieurs threads sur chaque nœud de calcul, et la mémoire de chaque nœud de calcul est partagée entre tous les threads. Un thread est une tâche exécutable unique qui s'exécute dans un processus plus important. Le nombre de threads par défaut dépend de plusieurs facteurs et varie entre les jobs par lot et de traitement en flux continu.
Si le pipeline a besoin de plus de mémoire que la quantité par défaut de mémoire disponible sur les nœuds de calcul, vous pouvez rencontrer des erreurs de mémoire insuffisante.
Les pipelines Dataflow utilisent principalement la mémoire des nœuds de calcul de trois manières :
- Mémoire opérationnelle des nœuds de calcul
- Mémoire du processus du SDK
- Utilisation de la mémoire
DoFn
Mémoire opérationnelle des nœuds de calcul
Les nœuds de calcul Dataflow ont besoin de mémoire pour leurs systèmes d'exploitation et leurs processus système. L'utilisation de la mémoire par le nœud de calcul ne dépasse généralement pas 1 Go. La consommation est généralement inférieure à 1 Go.
- Divers processus sur le nœud de calcul utilisent la mémoire pour s'assurer que votre pipeline fonctionne correctement. Chacun de ces processus peut réserver une petite quantité de mémoire pour son fonctionnement.
- Lorsque votre pipeline n'utilise pas Streaming Engine, des processus de nœud de calcul supplémentaires utilisent la mémoire.
Mémoire du processus du SDK
Les processus du SDK Apache Beam peuvent créer des objets et des données partagés entre les threads du processus. C'est ce que l'on appelle sur cette page "objets et données partagés du SDK". L'utilisation de la mémoire de ces objets et données partagés SDK est appelée "mémoire du processus du SDK". La liste suivante contient des exemples d'objets et de données partagés du SDK :
- Entrées secondaires
- Modèles de machine learning
- Objets singleton en mémoire
- Objets Python créés avec le module
apache_beam.utils.shared - Données chargées à partir de sources externes, telles que Cloud Storage ou BigQuery
Les jobs de traitement en flux continu qui n'utilisent pas Streaming Engine stockent les entrées secondaires en mémoire. Pour les pipelines Java et Go, chaque nœud de calcul dispose d'une copie de l'entrée secondaire. Pour les pipelines Python, chaque processus du SDK Apache Beam dispose d'une copie de l'entrée secondaire.
La taille des entrées secondaires qui utilisent Streaming Engine est limitée à 80 Mo. Les entrées secondaires sont stockées en dehors de la mémoire du nœud de calcul.
L'utilisation de la mémoire à partir d'objets et de données partagés du SDK augmente de manière linéaire avec le nombre de processus du SDK Apache Beam. Dans les pipelines Java et Go, un processus du SDK Apache Beam est démarré pour chaque nœud de calcul. Dans les pipelines Python, un processus du SDK Apache Beam est démarré pour chaque processeur virtuel. Les objets et données partagés du SDK sont réutilisés entre les threads du même processus du SDK Apache Beam.
Utilisation de la mémoire DoFn
DoFn est une classe du SDK Apache Beam qui définit une fonction de traitement distribué.
Chaque nœud de calcul peut exécuter des instances DoFn simultanées. Chaque thread exécute une instance de DoFn. Lors de l'évaluation de l'utilisation totale de la mémoire, du calcul de la taille de l'ensemble de travail ou de la quantité de mémoire nécessaire pour continuer à fonctionner pour une application, il peut être utile. Par exemple, si une personne DoFn utilise au maximum 5 Mo de mémoire et qu'un nœud de calcul dispose de 300 threads, l'utilisation de la mémoire DoFn peut atteindre un pic de 1,5 Go, soit le nombre d'octets mémoire multiplié par le nombre de threads. Selon la façon dont les nœuds de calcul utilisent la mémoire, un pic d'utilisation de la mémoire peut entraîner une saturation de celle-ci.
Il est difficile d'estimer le nombre d'instances créées par Dataflow DoFn. Le nombre dépend de divers facteurs, tels que le SDK, le type de machine, etc. De plus, la fonction DoFn peut être utilisée par plusieurs threads à la suite.
Le service Dataflow ne garantit pas le nombre de fois qu'une fonction DoFn est appelée, ni le nombre exact d'instances DoFn créées au cours de l'exécution d'un pipeline.
Toutefois, le tableau suivant donne un aperçu du niveau de parallélisme attendu et estime une limite supérieure pour le nombre d'instances DoFn.
| Lot | Flux sans Streaming Engine | Streaming Engine | |
|---|---|---|---|
| Parallélisme |
1 processus par processeur virtuel 1 thread par processus 1 thread par processeur virtuel
|
1 processus par processeur virtuel 12 threads par processus 12 threads par processeur virtuel |
1 processus par processeur virtuel 12 threads par processus 12 threads par processeur virtuel
|
Nombre maximal d'instances DoFn simultanées (tous ces nombres sont susceptibles d'être modifiés à tout moment). |
1 DoFn par thread 1
|
1 DoFn par thread 12
|
1 DoFn par thread 12
|
| Lot | Streaming Appliance et Streaming Engine sans exécuteur v2 | Streaming Engine avec l'exécuteur v2 | |
|---|---|---|---|
| Parallélisme |
1 processus par VM de nœud de calcul 1 thread par processeur virtuel
|
1 processus par VM de nœud de calcul 300 threads par processus 300 threads par VM de nœud de calcul
|
1 processus par VM de nœud de calcul 500 threads par processus 500 threads par VM de nœud de calcul
|
Nombre maximal d'instances DoFn simultanées (tous ces nombres sont susceptibles d'être modifiés à tout moment). |
1 DoFn par thread 1
|
1 DoFn par thread
300
|
1 DoFn par thread
500
|
Par exemple, lorsque vous utilisez le SDK Python avec un worker Dataflow n1-standard-2, les éléments suivants s'appliquent:
- Jobs par lot: Dataflow lance un processus par processeur virtuel (deux dans ce cas). Chaque processus utilise un thread, et chaque thread crée une instance
DoFn. - Tâches de streaming avec Streaming Engine: Dataflow démarre un processus par processeur virtuel (deux au total). Toutefois, chaque processus peut générer jusqu'à 12 threads, chacun avec sa propre instance DoFn.
Lorsque vous concevez des pipelines complexes, il est important de comprendre le cycle de vie de DoFn.
Assurez-vous que vos fonctions DoFn sont sérialisables et évitez de modifier l'argument d'élément directement dans celles-ci.
Lorsque vous disposez d'un pipeline multilingue et que plusieurs SDK Apache Beam s'exécutent sur le nœud de calcul, celui-ci utilise le degré de parallélisme de thread par processus le plus faible possible.
Différences entre Java, Go et Python
Java, Go et Python gèrent les processus et la mémoire différemment. Par conséquent, l'approche à adopter lors du dépannage des erreurs de mémoire insuffisante varie selon que votre pipeline utilise Java, Go ou Python.
Pipelines Java et Go
Dans les pipelines Java et Go :
- Chaque nœud de calcul démarre un processus du SDK Apache Beam.
- Les objets et données partagés du SDK, tels que les entrées secondaires et les caches, sont partagés entre tous les threads du nœud de calcul.
- La mémoire utilisée par les objets et les données partagés du SDK n'évolue généralement pas en fonction du nombre de processeurs virtuels sur le nœud de calcul.
Pipelines Python
Dans les pipelines Python :
- Chaque nœud de calcul démarre un processus du SDK Apache Beam par processeur virtuel.
- Les objets et données partagés du SDK, tels que les entrées et les caches secondaires, sont partagés entre tous les threads de chaque processus du SDK Apache Beam.
- Le nombre total de threads sur le nœud de calcul évolue de façon linéaire en fonction du nombre de processeurs virtuels. Par conséquent, la mémoire utilisée par les objets et données partagés du SDK augmente de manière linéaire avec le nombre de processeurs virtuels.
- Les threads qui effectuent le travail sont répartis sur plusieurs processus. Les nouvelles unités de travail sont attribuées à un processus sans éléments de travail ou au processus ayant actuellement le moins d'éléments de travail attribués.