Halaman ini menjelaskan cara menemukan dan menyelesaikan error kehabisan memori (OOM) di Dataflow.
Menemukan error kehabisan memori
Untuk menentukan apakah pipeline Anda kehabisan memori, gunakan salah satu metode berikut.
- Di halaman Jobs details, di panel Logs, lihat tab Diagnostics. Tab ini menampilkan error yang terkait dengan masalah memori dan seberapa sering error terjadi.
- Di antarmuka pemantauan Dataflow, gunakan diagram Penggunaan memori untuk memantau kapasitas dan penggunaan memori pekerja.
- Di halaman Jobs details, di panel Logs, pilih Worker logs untuk menemukan error kehabisan memori di log pekerja.
Error kurang memori juga dapat muncul di log sistem. Untuk melihatnya, buka Logs Explorer dan gunakan kueri berikut:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID" "out of memory" OR "OutOfMemory" OR "Shutting down JVM"Ganti JOB_ID dengan ID tugas Anda.
Untuk tugas Java, Java Memory Monitor secara berkala melaporkan metrik pengumpulan sampah. Jika fraksi waktu CPU yang digunakan untuk pengumpulan sampah melebihi nilai minimum 50% untuk jangka waktu yang lama, harness SDK akan gagal. Anda mungkin melihat error yang mirip dengan contoh berikut:
Shutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = ...Error ini dapat terjadi saat memori fisik masih tersedia, dan biasanya menunjukkan bahwa penggunaan memori pipeline tidak efisien. Untuk mengatasi masalah ini, optimalkan pipeline Anda.
Java Memory Monitor dikonfigurasi oleh antarmuka
MemoryMonitorOptions.
Jika tugas Anda memiliki penggunaan memori yang tinggi atau error kehabisan memori, ikuti rekomendasi di halaman ini untuk mengoptimalkan penggunaan memori atau meningkatkan jumlah memori yang tersedia.
Mengatasi error kurang memori
Perubahan pada pipeline Dataflow Anda dapat mengatasi error kehabisan memori atau mengurangi penggunaan memori. Kemungkinan perubahan mencakup tindakan berikut:
- Mengoptimalkan alur kerja Anda
- Kurangi jumlah thread
- Gunakan jenis mesin dengan memori yang lebih besar per vCPU
Diagram berikut menunjukkan alur kerja pemecahan masalah Dataflow yang dijelaskan di halaman ini.
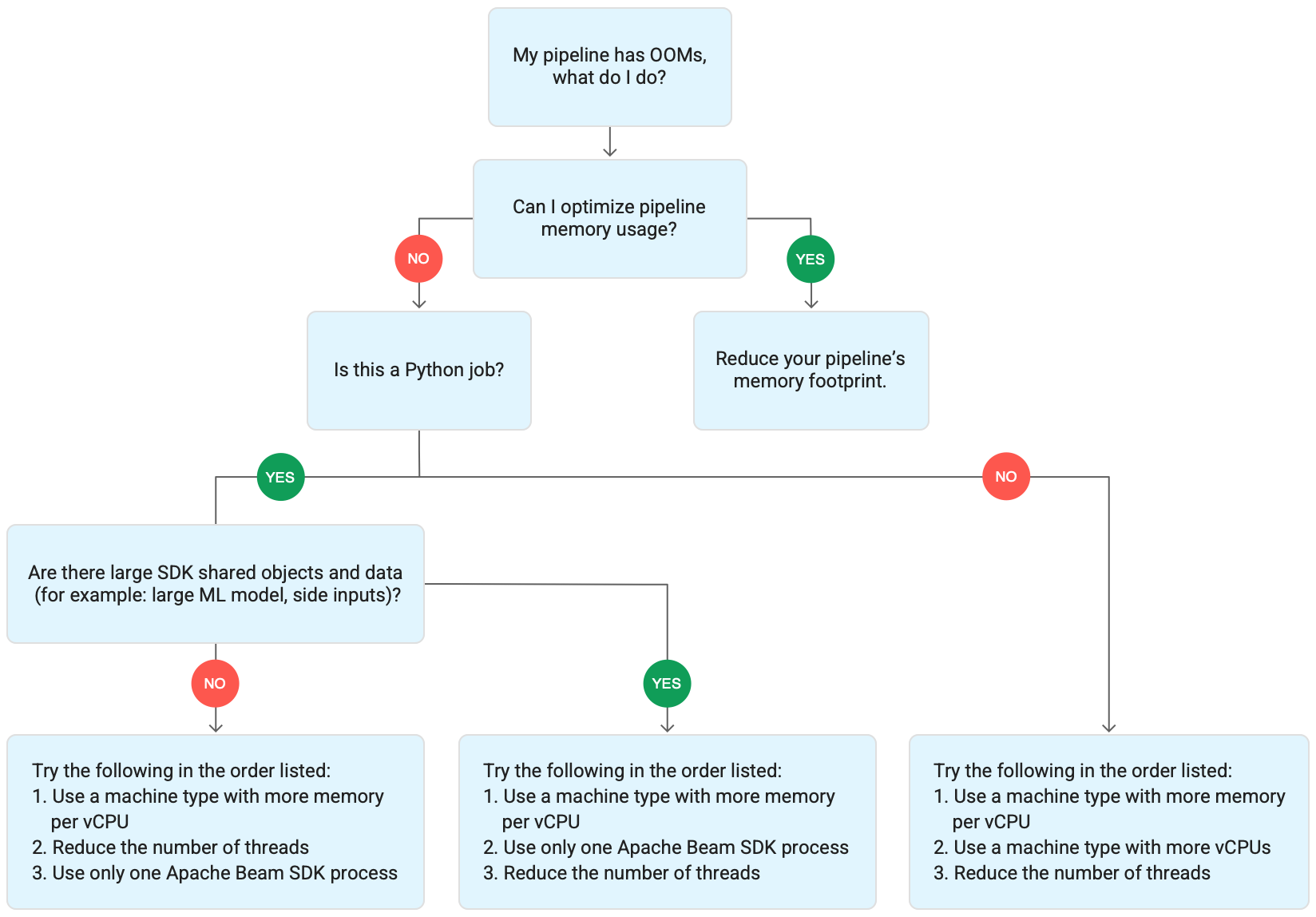
Coba mitigasi berikut:
- Jika memungkinkan, optimalkan pipeline Anda untuk mengurangi penggunaan memori.
- Jika tugas adalah tugas batch, coba langkah-langkah berikut dalam urutan yang tercantum:
- Gunakan jenis mesin dengan memori per vCPU yang lebih besar.
- Kurangi jumlah thread menjadi kurang dari jumlah vCPU per pekerja.
- Gunakan jenis mesin kustom dengan memori per vCPU yang lebih besar.
- Jika tugas adalah tugas streaming yang menggunakan Python, kurangi jumlah thread menjadi kurang dari 12.
- Jika tugas adalah tugas streaming yang menggunakan Java atau Go, coba langkah-langkah berikut:
- Kurangi jumlah thread menjadi kurang dari 500 untuk tugas Runner v2, atau kurang dari 300 untuk tugas yang tidak menggunakan Runner v2.
- Gunakan jenis mesin dengan memori yang lebih besar.
Mengoptimalkan pipeline
Beberapa operasi pipeline dapat menyebabkan error memori habis. Bagian ini menyediakan opsi untuk mengurangi penggunaan memori pipeline Anda. Untuk mengidentifikasi tahap pipeline yang paling banyak menggunakan memori, gunakan Cloud Profiler untuk memantau performa pipeline.
Anda dapat menggunakan praktik terbaik berikut untuk mengoptimalkan pipeline:
- Menggunakan konektor I/O bawaan Apache Beam untuk membaca file
- Operasi desain ulang saat menggunakan
GroupByKeyPTransforms - Mengurangi data ingress dari sumber eksternal
- Membagikan objek di seluruh rangkaian pesan
- Menggunakan representasi elemen yang hemat memori
- Mengurangi ukuran input samping
- Menggunakan DoFn yang dapat dibagi di Apache Beam
Menggunakan konektor I/O bawaan Apache Beam untuk membaca file
Jangan membuka file besar di dalam DoFn. Untuk membaca file, gunakan
konektor I/O bawaan Apache Beam.
File yang dibuka di DoFn harus sesuai dengan memori. Karena beberapa instance DoFn berjalan secara bersamaan, file besar yang dibuka di DoFn dapat menyebabkan error memori habis.
Mendesain ulang operasi saat menggunakan PTransform GroupByKey
Saat Anda menggunakan PTransform GroupByKey di Dataflow, nilai
per kunci dan per jendela yang dihasilkan diproses pada satu thread. Karena data ini diteruskan sebagai aliran dari layanan backend Dataflow ke pekerja, data ini tidak perlu muat di memori pekerja. Namun, jika nilai dikumpulkan dalam memori, logika pemrosesan dapat menyebabkan error kehabisan memori.
Misalnya, jika Anda memiliki kunci yang berisi data untuk jendela, dan Anda menambahkan nilai kunci ke objek dalam memori, seperti daftar, error kehabisan memori mungkin terjadi. Dalam skenario ini, pekerja mungkin tidak memiliki kapasitas memori yang cukup untuk menampung semua objek.
Untuk mengetahui informasi selengkapnya tentang PTransform GroupByKey, lihat dokumentasi Apache Beam
Python GroupByKey
dan Java GroupByKey.
Daftar berikut berisi saran untuk mendesain pipeline Anda guna meminimalkan
penggunaan memori saat menggunakan PTransform GroupByKey.
- Untuk mengurangi jumlah data per kunci dan per periode, hindari kunci dengan banyak nilai, yang juga dikenal sebagai kunci aktif.
- Untuk mengurangi jumlah data yang dikumpulkan per-periode, gunakan ukuran periode yang lebih kecil.
- Jika Anda menggunakan nilai kunci dalam jendela untuk menghitung angka, gunakan
transformasi
Combine. Jangan lakukan penghitungan dalam satu instanceDoFnsetelah mengumpulkan nilai. - Filter nilai atau duplikat sebelum diproses. Untuk mengetahui informasi selengkapnya, lihat dokumentasi transformasi
Python
Filterdan JavaFilter.
Mengurangi data masuk dari sumber eksternal
Jika Anda melakukan panggilan ke API eksternal atau database untuk pengayaan data, data yang ditampilkan harus sesuai dengan memori pekerja.
Jika Anda menggabungkan panggilan, sebaiknya gunakan transformasi GroupIntoBatches.
Jika Anda mengalami error kehabisan memori, kurangi ukuran batch. Untuk mengetahui informasi selengkapnya tentang pengelompokan ke dalam batch, lihat dokumentasi transformasi Python GroupIntoBatches dan Java GroupIntoBatches.
Membagikan objek di seluruh thread
Membagikan objek data dalam memori di seluruh instance DoFn dapat meningkatkan efisiensi ruang dan akses. Objek data yang dibuat dalam metode DoFn apa pun, termasuk
Setup, StartBundle, Process, FinishBundle, dan Teardown, dipanggil
untuk setiap DoFn. Di Dataflow, setiap pekerja dapat memiliki beberapa instance.DoFn Untuk penggunaan memori yang lebih efisien, teruskan objek data sebagai singleton untuk membagikannya di beberapa DoFn. Untuk mengetahui informasi selengkapnya, lihat postingan blog
Penggunaan ulang cache di seluruh DoFns.
Menggunakan representasi elemen yang hemat memori
Evaluasi apakah Anda dapat menggunakan representasi untuk elemen PCollection yang menggunakan lebih sedikit memori. Saat menggunakan coder dalam pipeline, pertimbangkan tidak hanya representasi elemen PCollection yang dienkode, tetapi juga yang didekode. Matriks jarang sering kali dapat memperoleh manfaat dari jenis pengoptimalan ini.
Mengurangi ukuran input samping
Jika DoFn Anda menggunakan input samping, kurangi ukuran input samping. Untuk input
samping yang merupakan kumpulan elemen, pertimbangkan untuk menggunakan tampilan yang dapat diiterasi, seperti
AsIterable
atau AsMultimap, bukan tampilan yang mewujudkan seluruh input samping secara bersamaan, seperti
AsList.
Mengurangi jumlah thread
Anda dapat meningkatkan memori yang tersedia per thread dengan mengurangi jumlah maksimum
thread yang menjalankan instance DoFn. Perubahan ini mengurangi paralelisme, tetapi menyediakan lebih banyak memori untuk setiap DoFn.
Tabel berikut menunjukkan jumlah thread default yang dibuat Dataflow:
| Jenis tugas | Python SDK | SDK Java/Go |
|---|---|---|
| Batch | 1 thread per vCPU | 1 thread per vCPU |
| Streaming dengan Runner v2 | 12 thread per vCPU | 500 thread per VM pekerja |
| Streaming tanpa Runner v2 | 12 thread per vCPU | 300 thread per VM pekerja |
Untuk mengurangi jumlah thread Apache Beam SDK, tetapkan opsi pipeline berikut:
Java
Gunakan opsi pipeline --numberOfWorkerHarnessThreads.
Python
Gunakan opsi pipeline --number_of_worker_harness_threads.
Go
Gunakan opsi pipeline --number_of_worker_harness_threads.
Untuk tugas batch, tetapkan nilai ke angka yang lebih kecil dari jumlah vCPU.
Untuk tugas streaming, mulailah dengan mengurangi nilai menjadi setengah dari nilai default. Jika langkah ini tidak mengurangi masalah, terus kurangi nilai sebesar setengahnya, amati hasilnya di setiap langkah. Misalnya, saat menggunakan Python, coba nilai 6, 3, dan 1.
Gunakan jenis mesin dengan memori yang lebih besar per vCPU
Untuk memilih pekerja dengan memori yang lebih besar per vCPU, gunakan salah satu metode berikut.
- Gunakan jenis mesin bermemori tinggi di kelompok mesin tujuan umum. Jenis mesin bermemori tinggi memiliki memori per vCPU yang lebih tinggi daripada jenis mesin standar. Menggunakan jenis mesin dengan memori tinggi akan meningkatkan memori yang tersedia untuk setiap pekerja dan memori yang tersedia per thread, karena jumlah vCPU tetap sama. Oleh karena itu, menggunakan jenis mesin bermemori tinggi dapat menjadi cara yang hemat biaya untuk memilih pekerja dengan lebih banyak memori per vCPU.
- Untuk fleksibilitas yang lebih besar saat menentukan jumlah vCPU dan jumlah memori, Anda dapat menggunakan jenis mesin kustom. Dengan jenis mesin kustom, Anda dapat meningkatkan memori dalam kelipatan 256 MB. Jenis mesin ini memiliki harga yang berbeda dengan jenis mesin standar.
- Beberapa kelompok mesin memungkinkan Anda menggunakan jenis mesin kustom dengan memori tambahan. Memori yang diperluas memungkinkan rasio memori per vCPU yang lebih tinggi. Biayanya lebih tinggi.
Untuk menetapkan jenis pekerja, gunakan opsi pipeline berikut. Untuk mengetahui informasi selengkapnya, lihat Menyetel opsi pipeline dan Opsi pipeline.
Java
Gunakan opsi pipeline --workerMachineType.
Python
Gunakan opsi pipeline --machine_type.
Go
Gunakan opsi pipeline --worker_machine_type.
Gunakan hanya satu proses Apache Beam SDK
Untuk pipeline streaming Python dan pipeline Python yang menggunakan Runner v2, Anda dapat memaksa Dataflow untuk memulai hanya satu proses Apache Beam SDK per pekerja. Sebelum mencoba opsi ini, coba selesaikan masalah menggunakan metode lain terlebih dahulu. Untuk mengonfigurasi VM pekerja Dataflow agar hanya memulai satu proses Python yang di-container, gunakan opsi pipeline berikut:
--experiments=no_use_multiple_sdk_containers
Dengan konfigurasi ini, pipeline Python membuat satu proses Apache Beam SDK per pekerja. Konfigurasi ini mencegah objek dan data bersama direplikasi beberapa kali untuk setiap proses Apache Beam SDK. Namun, hal ini membatasi penggunaan resource komputasi yang tersedia di worker secara efisien.
Mengurangi jumlah proses SDK Apache Beam menjadi satu tidak selalu mengurangi jumlah total thread yang dimulai di pekerja. Selain itu, memiliki semua thread dalam satu proses Apache Beam SDK dapat menyebabkan pemrosesan lambat atau menyebabkan pipeline macet. Oleh karena itu, Anda mungkin juga harus mengurangi jumlah thread, seperti yang dijelaskan di bagian Mengurangi jumlah thread di halaman ini.
Anda juga dapat memaksa pekerja untuk hanya menggunakan satu proses Apache Beam SDK dengan menggunakan jenis mesin dengan hanya satu vCPU.
Memahami penggunaan memori Dataflow
Untuk memecahkan masalah error kurang memori, sebaiknya pahami cara pipeline Dataflow menggunakan memori.
Saat menjalankan pipeline, pemrosesan Dataflow didistribusikan di beberapa virtual machine (VM) Compute Engine, yang sering disebut worker.
Pekerja memproses item kerja dari layanan Dataflow
dan mendelegasikan item kerja ke proses Apache Beam SDK. Proses Apache Beam
SDK membuat instance
DoFns. DoFn adalah class Apache Beam SDK yang menentukan fungsi pemrosesan terdistribusi.
Dataflow meluncurkan beberapa thread di setiap pekerja, dan memori setiap pekerja dibagikan ke semua thread. Thread adalah satu tugas yang dapat dieksekusi dan berjalan dalam proses yang lebih besar. Jumlah thread default bergantung pada beberapa faktor dan bervariasi antara tugas batch dan streaming.
Jika pipeline Anda memerlukan lebih banyak memori daripada jumlah memori default yang tersedia di pekerja, Anda mungkin mengalami error kehabisan memori.
Pipeline Dataflow terutama menggunakan memori pekerja dengan tiga cara:
Memori operasional pekerja
Pekerja Dataflow memerlukan memori untuk sistem operasi dan proses sistemnya. Penggunaan memori pekerja biasanya tidak lebih besar dari 1 GB. Penggunaan biasanya kurang dari 1 GB.
- Berbagai proses pada pekerja menggunakan memori untuk memastikan pipeline Anda berfungsi dengan baik. Setiap proses ini dapat mencadangkan sejumlah kecil memori untuk operasinya.
- Jika pipeline Anda tidak menggunakan Streaming Engine, proses pekerja tambahan akan menggunakan memori.
Memori proses SDK
Pemrosesan Apache Beam SDK dapat membuat objek dan data yang dibagikan antar-thread dalam proses, yang disebut di halaman ini sebagai objek dan data bersama SDK. Penggunaan memori dari objek dan data bersama SDK ini disebut sebagai memori proses SDK. Daftar berikut mencakup contoh objek dan data bersama SDK:
- Input samping
- Model machine learning
- Objek singleton dalam memori
- Objek Python yang dibuat dengan modul
apache_beam.utils.shared - Data yang dimuat dari sumber eksternal, seperti Cloud Storage atau BigQuery
Tugas streaming yang tidak menggunakan Streaming Engine menyimpan input samping di memori. Untuk pipeline Java dan Go, setiap pekerja memiliki satu salinan input samping. Untuk pipeline Python, setiap proses Apache Beam SDK memiliki satu salinan input samping.
Tugas streaming yang menggunakan Streaming Engine memiliki batas ukuran input samping sebesar 80 MB. Input samping disimpan di luar memori pekerja.
Penggunaan memori dari objek dan data bersama SDK tumbuh secara linear dengan jumlah proses Apache Beam SDK. Dalam pipeline Java dan Go, satu proses Apache Beam SDK dimulai per pekerja. Di pipeline Python, satu proses Apache Beam SDK dimulai per vCPU. Objek dan data bersama SDK digunakan kembali di seluruh thread dalam proses Apache Beam SDK yang sama.
Penggunaan memori DoFn
DoFn adalah class Apache Beam SDK yang menentukan fungsi pemrosesan terdistribusi.
Setiap pekerja dapat menjalankan instance DoFn serentak. Setiap thread menjalankan satu instance DoFn. Saat mengevaluasi total penggunaan memori, menghitung ukuran set kerja, atau jumlah memori yang diperlukan agar aplikasi dapat terus berfungsi, mungkin akan membantu. Misalnya, jika DoFn individu menggunakan memori maksimum 5 MB dan pekerja memiliki 300 thread, penggunaan memori DoFn dapat mencapai 1,5 GB, atau jumlah byte memori dikalikan dengan jumlah thread. Bergantung pada cara pekerja menggunakan memori, lonjakan penggunaan memori dapat menyebabkan pekerja kehabisan memori.
Sulit untuk memperkirakan jumlah instance
DoFn
yang dibuat Dataflow. Jumlahnya bergantung pada berbagai faktor, seperti SDK,
jenis mesin, dan sebagainya. Selain itu, DoFn dapat digunakan oleh beberapa thread secara berurutan.
Layanan Dataflow tidak menjamin berapa kali DoFn dipanggil,
juga tidak menjamin jumlah pasti instance DoFn yang dibuat selama pipeline.
Namun, tabel berikut memberikan beberapa insight tentang tingkat paralelisme yang dapat Anda harapkan dan memperkirakan batas atas jumlah instance DoFn.
Beam Python SDK
| Batch | Streaming tanpa Streaming Engine | Streaming Engine | |
|---|---|---|---|
| Keparalelan |
1 proses per vCPU 1 thread per proses 1 thread per vCPU
|
1 proses per vCPU 12 thread per proses 12 thread per vCPU |
1 proses per vCPU 12 thread per proses 12 thread per vCPU
|
Jumlah maksimum instance DoFn serentak (Semua angka ini dapat berubah kapan saja.) |
1 DoFn per rangkaian pesan
1
|
1 DoFn per rangkaian pesan
12
|
1 DoFn per rangkaian pesan
12
|
Beam Java/Go SDK
| Batch | Streaming Appliance dan Streaming Engine tanpa runner v2 | Streaming Engine dengan runner v2 | |
|---|---|---|---|
| Keparalelan |
1 proses per VM pekerja 1 thread per vCPU
|
1 proses per VM pekerja 300 thread per proses 300 thread per VM pekerja
|
1 proses per VM pekerja 500 thread per proses 500 thread per VM pekerja
|
Jumlah maksimum instance DoFn serentak (Semua angka ini dapat berubah kapan saja.) |
1 DoFn per rangkaian pesan
1
|
1 DoFn per rangkaian pesan
300
|
1 DoFn per rangkaian pesan
500
|
Misalnya, saat menggunakan Python SDK dengan pekerja Dataflow n1-standard-2, hal berikut berlaku:
- Tugas batch: Dataflow meluncurkan satu proses per vCPU (dua dalam kasus ini). Setiap proses menggunakan satu thread, dan setiap thread membuat satu instance
DoFn. - Tugas streaming dengan Streaming Engine: Dataflow memulai satu proses per vCPU (total dua). Namun, setiap proses dapat memunculkan hingga 12 thread, yang masing-masing memiliki instance DoFn sendiri.
Saat mendesain pipeline yang kompleks, penting untuk memahami
siklus proses DoFn.
Pastikan fungsi DoFn Anda dapat diserialisasi, dan hindari memodifikasi argumen elemen secara langsung di dalamnya.
Jika Anda memiliki pipeline multi-bahasa, dan lebih dari satu Apache Beam SDK berjalan di pekerja, pekerja akan menggunakan paralelisme thread per proses dengan tingkat terendah yang memungkinkan.
Perbedaan Java, Go, dan Python
Java, Go, dan Python mengelola proses dan memori secara berbeda. Akibatnya, pendekatan yang harus Anda lakukan saat memecahkan masalah error kehabisan memori bervariasi berdasarkan apakah pipeline Anda menggunakan Java, Go, atau Python.
Pipeline Java dan Go
Di pipeline Java dan Go:
- Setiap pekerja memulai satu proses Apache Beam SDK.
- Objek dan data bersama SDK, seperti input samping dan cache, dibagikan di antara semua thread pada pekerja.
- Memori yang digunakan oleh objek dan data bersama SDK biasanya tidak diskalakan berdasarkan jumlah vCPU pada pekerja.
Pipeline Python
Di pipeline Python:
- Setiap pekerja memulai satu proses Apache Beam SDK per vCPU.
- Objek dan data bersama SDK, seperti input samping dan cache, dibagikan di antara semua thread dalam setiap proses Apache Beam SDK.
- Jumlah total thread pada pekerja diskalakan secara linear berdasarkan jumlah vCPU. Akibatnya, memori yang digunakan oleh objek dan data bersama SDK tumbuh secara linear dengan jumlah vCPU.
- Thread yang melakukan pekerjaan didistribusikan di seluruh proses. Unit tugas baru akan ditetapkan ke proses tanpa item tugas, atau ke proses dengan item tugas paling sedikit yang saat ini ditetapkan.