Cloud Profiler adalah profiler statistik dengan overhead rendah yang terus mengumpulkan informasi penggunaan CPU dan alokasi memori dari aplikasi produksi Anda. Untuk mengetahui detail selengkapnya, lihat Konsep pembuatan profil. Untuk memecahkan masalah atau memantau performa pipeline, gunakan integrasi Dataflow dengan Cloud Profiler untuk mengidentifikasi bagian kode pipeline yang paling banyak menggunakan resource.
Untuk mengetahui tips pemecahan masalah dan strategi proses debug untuk membangun atau menjalankan pipeline Dataflow, lihat Memecahkan masalah dan melakukan proses debug pada pipeline.
Sebelum memulai
Pahami konsep pembuatan profil dan pelajari antarmuka Profiler. Untuk mengetahui informasi tentang cara mulai menggunakan antarmuka Profiler, lihat Memilih profil yang akan dianalisis.
Cloud Profiler API harus diaktifkan untuk project Anda sebelum tugas Anda dimulai.
Fitur ini diaktifkan secara otomatis saat pertama kali Anda membuka halaman Profiler.
Atau, Anda dapat mengaktifkan Cloud Profiler API menggunakan alat command line Google Cloud CLI gcloud atau konsol Google Cloud .
Untuk menggunakan Cloud Profiler, project Anda harus memiliki kuota yang cukup.
Selain itu, akun layanan worker
untuk tugas Dataflow harus memiliki
izin yang sesuai untuk Profiler. Misalnya, untuk membuat profil, akun layanan pekerja harus memiliki izin cloudprofiler.profiles.create, yang disertakan dalam peran IAM Cloud Profiler Agent (roles/cloudprofiler.agent).
Untuk mengetahui informasi selengkapnya, lihat Kontrol akses dengan IAM.
Mengaktifkan Cloud Profiler untuk pipeline Dataflow
Cloud Profiler tersedia untuk pipeline Dataflow yang ditulis di Apache Beam SDK untuk Java dan Python, versi 2.33.0 atau yang lebih baru. Pipeline Python harus menggunakan Dataflow Runner v2. Cloud Profiler dapat diaktifkan pada waktu mulai pipeline. Overhead CPU dan memori yang diamortisasi diperkirakan kurang dari 1% untuk pipeline Anda.
Java
Untuk mengaktifkan pembuatan profil CPU, mulai pipeline dengan opsi berikut.
--dataflowServiceOptions=enable_google_cloud_profiler
Untuk mengaktifkan pembuatan profil heap, mulai pipeline dengan opsi berikut. Pembuatan profil heap memerlukan Java 11 atau yang lebih tinggi.
--dataflowServiceOptions=enable_google_cloud_profiler
--dataflowServiceOptions=enable_google_cloud_heap_sampling
Python
Untuk menggunakan Cloud Profiler, pipeline Python Anda harus berjalan dengan Runner v2 Dataflow.
Untuk mengaktifkan pembuatan profil CPU, mulai pipeline dengan opsi berikut. Pemrofilan heap belum didukung untuk Python.
--dataflow_service_options=enable_google_cloud_profiler
Go
Untuk mengaktifkan pembuatan profil CPU dan heap, mulai pipeline dengan opsi berikut.
--dataflow_service_options=enable_google_cloud_profiler
Jika Anda men-deploy pipeline dari template Dataflow dan ingin mengaktifkan Cloud Profiler,
tentukan flag enable_google_cloud_profiler dan
enable_google_cloud_heap_sampling sebagai eksperimen tambahan.
Konsol
Jika menggunakan template yang disediakan Google, Anda dapat menentukan tanda di halaman Buat tugas dari template Dataflow di kolom Eksperimen tambahan.
gcloud
Jika Anda menggunakan Google Cloud CLI untuk menjalankan
template, baik gcloud
dataflow jobs run maupun gcloud dataflow flex-template run, bergantung pada
jenis template, gunakan opsi --additional-experiments
untuk menentukan flag.
API
Jika Anda menggunakan REST
API untuk menjalankan template, bergantung pada jenis template, tentukan flag menggunakan
kolom additionalExperiments lingkungan runtime, baik RuntimeEnvironment atau FlexTemplateRuntimeEnvironment.
Melihat data pembuatan profil
Jika Cloud Profiler diaktifkan, link ke halaman Profiler akan ditampilkan di halaman tugas.
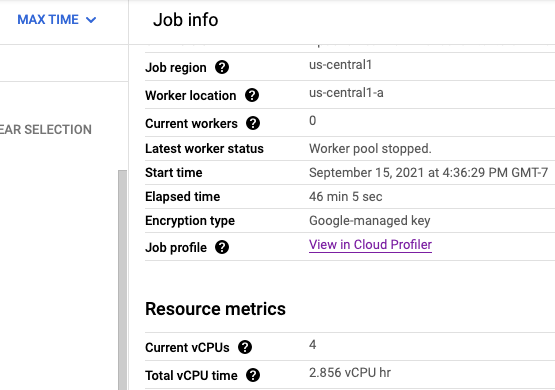
Di halaman Profiler, Anda juga dapat menemukan data pembuatan profil untuk pipeline Dataflow. Service adalah nama tugas Anda dan Version adalah ID tugas Anda.

Menggunakan Cloud Profiler
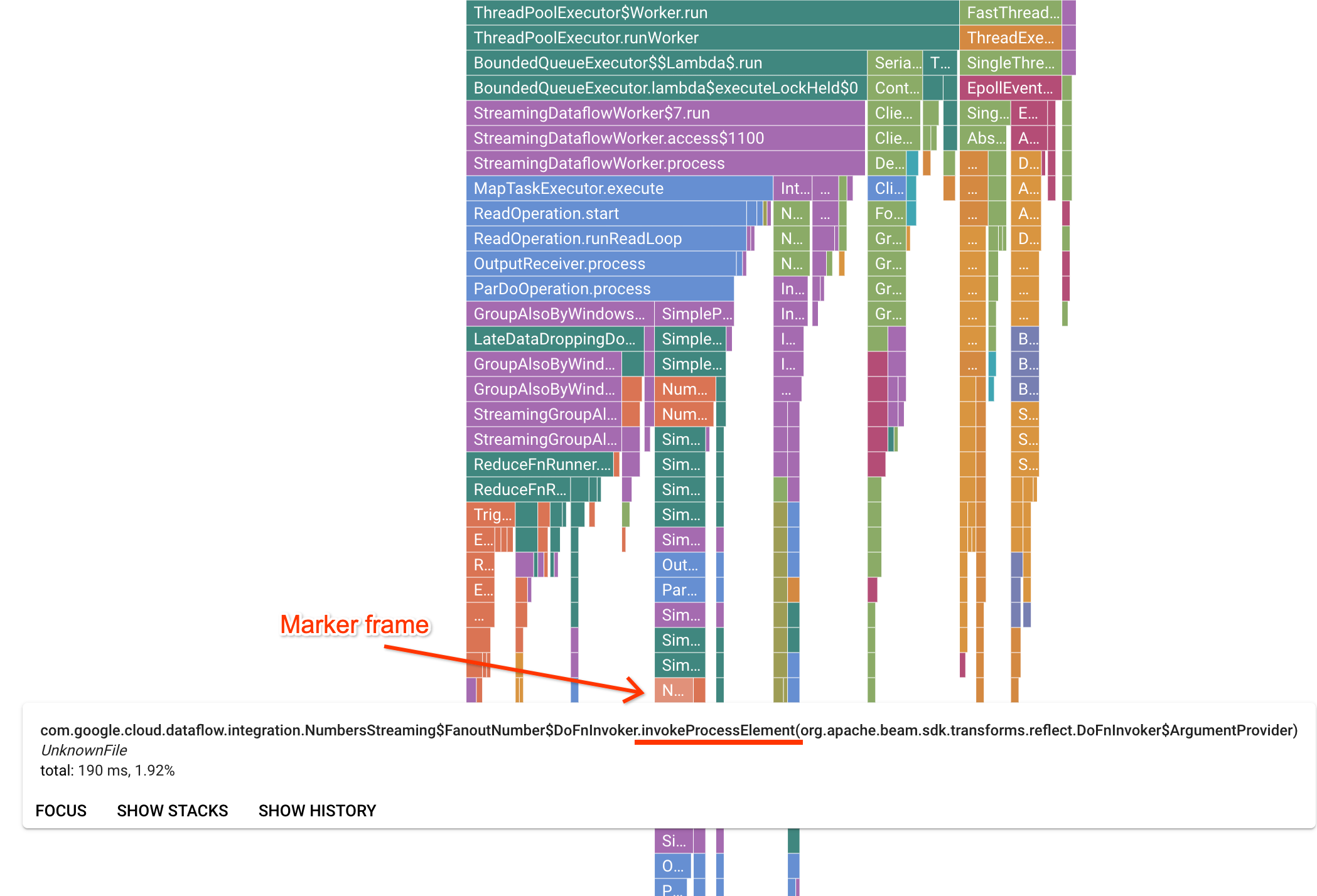
Halaman Profiler berisi grafik flame yang menampilkan statistik untuk setiap frame yang berjalan di pekerja. Dalam arah horizontal, Anda dapat melihat berapa lama waktu yang dibutuhkan setiap frame untuk dieksekusi dalam hal waktu CPU. Dalam arah vertikal, Anda dapat melihat stack trace dan kode yang berjalan secara paralel. Stack trace didominasi oleh kode infrastruktur runner. Untuk tujuan proses debug, kita biasanya tertarik dengan eksekusi kode pengguna, yang biasanya ditemukan di dekat tips bawah grafik. Kode pengguna dapat diidentifikasi dengan mencari frame penanda, yang merepresentasikan kode runner yang diketahui hanya memanggil kode pengguna. Dalam kasus runner Beam ParDo, lapisan adaptor dinamis dibuat untuk memanggil tanda tangan metode DoFn yang disediakan pengguna. Lapisan ini dapat diidentifikasi sebagai frame dengan akhiran invokeProcessElement. Gambar berikut menunjukkan demonstrasi menemukan frame penanda.
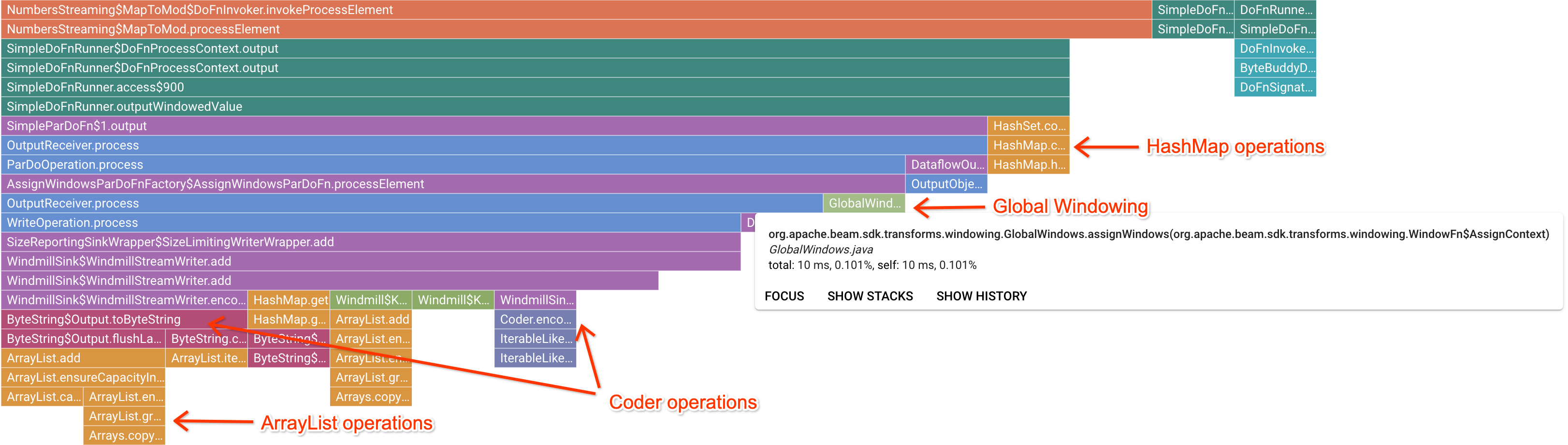
Setelah mengklik frame penanda yang menarik, grafik flame akan berfokus pada rekaman aktivitas tersebut, sehingga memberikan gambaran yang baik tentang kode pengguna yang berjalan lama. Operasi yang paling lambat dapat menunjukkan lokasi terjadinya bottleneck dan peluang untuk melakukan pengoptimalan. Dalam contoh berikut, Anda dapat melihat bahwa Global Windowing digunakan dengan ByteArrayCoder. Dalam hal ini, coder mungkin merupakan area yang baik untuk pengoptimalan karena menggunakan waktu CPU yang signifikan dibandingkan dengan operasi ArrayList dan HashMap.
Memecahkan masalah Cloud Profiler
Jika Anda mengaktifkan Cloud Profiler dan pipeline Anda tidak menghasilkan data pembuatan profil, salah satu kondisi berikut mungkin menjadi penyebabnya.
Pipeline Anda menggunakan Apache Beam SDK versi lama. Untuk menggunakan Cloud Profiler, Anda harus menggunakan Apache Beam SDK versi 2.33.0 atau yang lebih baru. Anda dapat melihat versi Apache Beam SDK pipeline di halaman tugas. Jika tugas Anda dibuat dari template Dataflow, template tersebut harus menggunakan versi SDK yang didukung.
Project Anda hampir kehabisan kuota Cloud Profiler. Anda dapat melihat penggunaan kuota dari halaman kuota project Anda. Error seperti
Failed to collect and upload profile whose profile type is WALLdapat terjadi jika kuota Cloud Profiler terlampaui. Layanan Cloud Profiler menolak data pembuatan profil jika Anda telah mencapai kuota. Untuk mengetahui informasi selengkapnya tentang kuota Cloud Profiler, lihat Kuota dan Batas.Tugas Anda tidak berjalan cukup lama untuk menghasilkan data bagi Cloud Profiler. Tugas yang berjalan dalam durasi singkat, seperti kurang dari lima menit, mungkin tidak memberikan data pembuatan profil yang cukup bagi Cloud Profiler untuk menghasilkan hasil.
Agen Cloud Profiler diinstal selama startup pekerja Dataflow. Pesan log yang dihasilkan oleh Cloud Profiler tersedia di jenis log dataflow.googleapis.com/worker-startup.
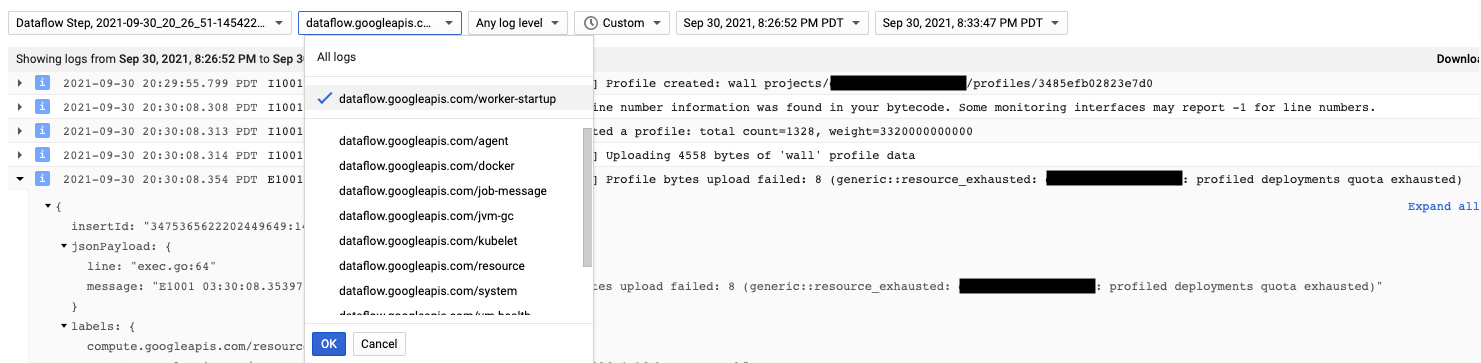
Terkadang, data pembuatan profil ada, tetapi Cloud Profiler tidak menampilkan output apa pun. Profiler akan menampilkan pesan yang mirip dengan, There were
profiles collected for the specified time range, but none match the current
filters.
Untuk mengatasi masalah ini, coba langkah-langkah pemecahan masalah berikut.
Pastikan rentang waktu dan waktu berakhir di Profiler mencakup waktu berlalu tugas.
Pastikan tugas yang benar dipilih di Profiler. Service adalah nama tugas Anda.
Pastikan opsi pipeline
job_namememiliki nilai yang sama dengan nama tugas di halaman tugas Dataflow.Jika Anda menentukan argumen service-name saat memuat agen Profiler, konfirmasi bahwa nama layanan dikonfigurasi dengan benar.