このページでは、Dataflow でメモリ不足(OOM)エラーを確認して解決する方法について説明します。
メモリ不足エラーを確認する
パイプラインでメモリが不足しているかどうかを確認するには、次のいずれかの方法を使用します。
- ジョブの詳細ページの [ログ] で、[診断] タブを表示します。このタブには、メモリの問題に関連するエラーと、エラーの発生頻度が表示されます。
- Dataflow モニタリング インターフェースで、メモリ使用率のグラフを使用して、ワーカーのメモリ容量と使用状況をモニタリングします。
- ジョブの詳細ページの [ログ] ペインで [ワーカーログ] を選択して、ワーカーログでメモリ不足エラーを探します。
メモリ不足エラーはシステムログにも表示されることがあります。これらを表示するには、ログ エクスプローラに移動し、次のクエリを使用します。
resource.type="dataflow_step" resource.labels.job_id="JOB_ID" "out of memory" OR "OutOfMemory" OR "Shutting down JVM"JOB_ID をジョブの ID に置き換えます。
Java ジョブの場合、Java メモリモニタはガベージ コレクションの指標を定期的に報告します。ガベージ コレクションに使用される CPU 時間の割合が長時間にわたって 50% というしきい値を超えると、SDK ハーネスが失敗します。次の例のようなエラーが表示される場合があります。
Shutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = ...このエラーは、物理メモリがまだ使用可能な場合でも発生することがあり、通常、パイプラインのメモリ使用が効率的ではないことを示します。この問題を解決するには、パイプラインを最適化してください。
Java メモリモニタは
MemoryMonitorOptionsインターフェースで構成されます。
ジョブでメモリ使用量が多いか、メモリ不足エラーが発生した場合は、このページの推奨事項に従って、メモリ使用量を最適化するか、使用可能なメモリ量を増やしてください。
メモリ不足エラーを解決する
Dataflow パイプラインに変更を加えると、メモリ不足エラーが解決されたり、メモリ使用量が減少する可能性があります。考えられる変更は次のとおりです。
次の図は、このページで説明する Dataflow トラブルシューティングのワークフローを示しています。
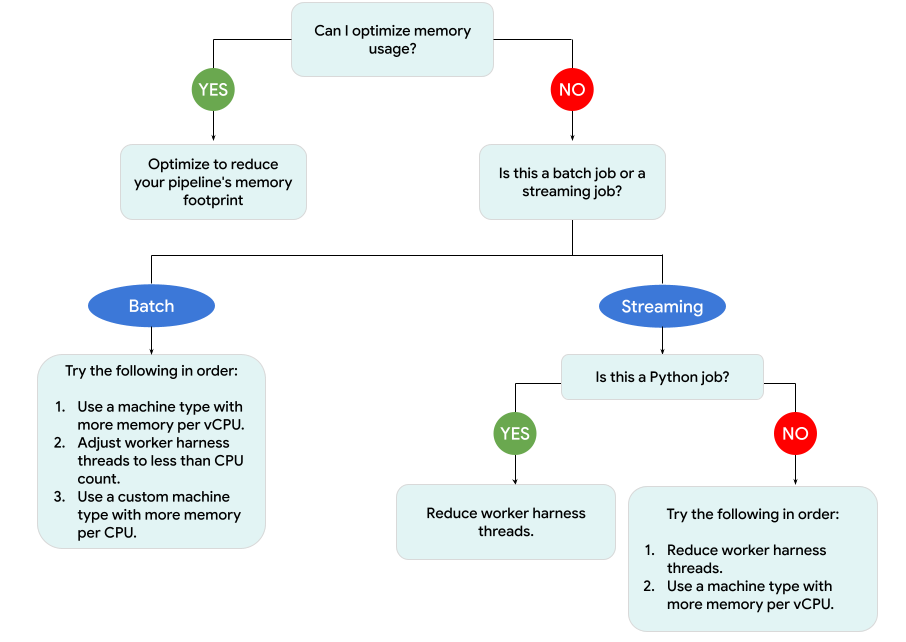
次の緩和策を試します。
- 可能であれば、メモリ使用量を削減するようにパイプラインを最適化します。
- ジョブがバッチジョブの場合は、次のことを順番に試します。
- vCPU あたりのメモリ容量が大きいマシンタイプを使用します。
- スレッド数をワーカーあたりの vCPU 数より少なくします。
- vCPU あたりのメモリ容量が大きいカスタム マシンタイプを使用します。
- ジョブが Python を使用するストリーミング ジョブの場合は、スレッド数を 12 より少なくします。
- ジョブが Java または Go を使用するストリーミング ジョブの場合は、次のことを試します。
- Runner v2 ジョブの場合は、スレッド数を 500 未満にします。Runner v2 を使用しないジョブの場合は 300 未満にします。
- メモリ容量が大きいマシンタイプを使用します。
パイプラインを最適化する
複数のパイプライン オペレーションを行うと、メモリ不足エラーが発生する可能性があります。このセクションでは、パイプラインのメモリ使用量を減らすためのオプションについて説明します。最もメモリを消費するパイプライン ステージを特定するには、Cloud Profiler を使用してパイプラインのパフォーマンスをモニタリングします。
パイプラインを最適化するには、次のベスト プラクティスに従います。
- Apache Beam の組み込み I/O コネクタを使用してファイルを読み取る
GroupByKeyPTransform の使用時のオペレーションを再設計する- 外部ソースからの上り(内向き)データを削減する
- スレッド間でオブジェクトを共有する
- メモリ効率の高い要素表現を使用する
- 副入力のサイズを小さくする
- Apache Beam の Splittable DoFns を使用する
Apache Beam の組み込み I/O コネクタを使用してファイルを読み取る
DoFn 内でサイズの大きなファイルを開かないでください。ファイルを読み取るには、Apache Beam の組み込み I/O コネクタを使用します。DoFn で開いたファイルはメモリに収まる必要があります。複数の DoFn インスタンスが同時に実行されるため、DoFn でサイズが大きなファイルを開くと、メモリ不足エラーが発生することがあります。
GroupByKey PTransform の使用時のオペレーションを再設計する
Dataflow で GroupByKey PTransform を使用すると、結果として得られるキーとウィンドウごとの値が 1 つのスレッドで処理されます。このデータは、Dataflow バックエンド サービスからワーカーにストリームとして渡されるため、ワーカーメモリに収まる必要はありません。ただし、値がメモリに収集されると、処理ロジックでメモリ不足エラーが発生する可能性があります。
たとえば、ウィンドウのデータを含むキーがあり、キー値をリストなどのメモリ内オブジェクトに追加すると、メモリ不足エラーが発生することがあります。このシナリオでは、ワーカーにすべてのメモリを保持するのに十分なメモリ容量がない可能性があります。
GroupByKey PTransform の詳細については、Apache Beam Python GroupByKey と Java GroupByKey のドキュメントをご覧ください。
次のリストは、GroupByKey PTransform を使用する際のメモリ消費を最小限に抑えるようにパイプラインを設計するためのヒントを示しています。
- キーおよびウィンドウあたりのデータ量を減らすには、値が多いキー(ホットキーとも呼ばれます)を使用しないようにします。
- ウィンドウあたりのデータの収集量を減らすには、ウィンドウ サイズを小さくします。
- ウィンドウ内のキーの値を使用して数値を計算する場合は、
Combine変換を使用します。値を収集した後は、1 つのDoFnインスタンスで計算を行わないようにします。 - 処理する前に、値または重複をフィルタします。詳細については、Python
Filterと JavaFilterの変換のドキュメントをご覧ください。
外部ソースからの上り(内向き)データを削減する
データ拡充のために外部 API またはデータベースを呼び出す場合は、返されるデータがワーカーメモリに収まる必要があります。呼び出しを一括処理する場合は、GroupIntoBatches 変換を使用することをおすすめします。メモリ不足エラーが発生した場合は、バッチサイズを小さくしてください。バッチへのグループ化の詳細については、Python GroupIntoBatches と Java GroupIntoBatches の変換ドキュメントをご覧ください。
スレッド間でオブジェクトを共有する
メモリ内データ オブジェクトを DoFn インスタンス間で共有すると、スペースの使用効率とアクセス効率が向上します。DoFn の任意のメソッド(Setup、StartBundle、Process、FinishBundle、Teardown など)で作成されたデータ オブジェクトが、各 DoFn に対して呼び出されます。Dataflow では、各ワーカーに複数の DoFn インスタンスが存在する場合があります。メモリを効率的に使用するには、データ オブジェクトをシングルトンとして渡して、複数の DoFn 間で共有します。詳細については、ブログ投稿 DoFn にまたがるキャッシュの再使用をご覧ください。
メモリ効率の高い要素表現を使用する
メモリ使用量が少ない PCollection 要素の表現を使用できるかどうか検討します。パイプラインでコーダーを使用する場合は、エンコードされた PCollection 要素表現だけでなく、デコードされたものも考慮してください。多くの場合、疎行列ではこのタイプの最適化によるメリットが得られます。
副入力のサイズを小さくする
DoFn が副入力を使用している場合は、副入力のサイズを小さくします。要素のコレクションである副入力については、AsList のように副入力全体を同時に実体化するビューの代わりに、AsIterable や AsMultimap などの反復可能なビューの使用を検討してください。
スレッド数を減らす
DoFn インスタンスを実行するスレッドの最大数を減らして、スレッドごとに使用可能なメモリを増やすことができます。この変更により、並列処理数は減りますが、各 DoFn で使用できるメモリが増えます。
次の表に、Dataflow が作成するデフォルトのスレッド数を示します。
| ジョブタイプ | Python SDK | Java / Go SDK |
|---|---|---|
| バッチ | vCPU あたり 1 スレッド | vCPU あたり 1 スレッド |
| Runner v2 を使用するストリーミング | vCPU あたり 12 スレッド | ワーカー VM あたり 500 スレッド |
| Runner v2 を使用しないストリーミング | vCPU あたり 12 スレッド | ワーカー VM あたり 300 スレッド |
Apache Beam SDK スレッドの数を減らすには、次のパイプライン オプションを設定します。
Java
--numberOfWorkerHarnessThreads パイプライン オプションを使用します。
Python
--number_of_worker_harness_threads パイプライン オプションを使用します。
Go
--number_of_worker_harness_threads パイプライン オプションを使用します。
バッチジョブの場合は、vCPU 数より小さい値に設定します。
ストリーミング ジョブの場合は、まず、値をデフォルトの半分に減らします。これで問題が解決しない場合は、値をさらに半分ずつ減らしていき、結果を確認します。たとえば、Python を使用している場合は、値を 6、3、1 と減らしていきます。
vCPU あたりのメモリ容量が大きいマシンタイプを使用する
vCPU あたりのメモリが多いワーカーを選択するには、次のいずれかの方法を使用します。
- 汎用マシン ファミリーのハイメモリ マシンタイプを使用する。ハイメモリ マシンタイプでは、標準マシンタイプよりも vCPU あたりのメモリが多くなります。ハイメモリ マシンタイプを使用すると、vCPU の数が変わらないため、各ワーカーが使用できるメモリとスレッドごとに使用可能なメモリが増加します。その結果、ハイメモリ マシンタイプを使用すると、vCPU あたりのメモリ容量が多いワーカーをコスト効率の良い方法で選択できます。
- vCPU の数とメモリ容量をより柔軟に指定したい場合は、カスタム マシンタイプを使用できます。カスタム マシンタイプでは、メモリを 256 MB 単位で増やすことができます。これらのマシンタイプでは、標準マシンタイプの料金が異なります。
- 一部のマシン ファミリーでは、拡張メモリのカスタム マシンタイプを使用できます。拡張メモリを使用すると、vCPU あたりのメモリ比率を増やすことができます。費用は高くなります。
ワーカータイプを設定するには、次のパイプライン オプションを使用します。詳細については、パイプライン オプションの設定とパイプライン オプションをご覧ください。
Java
--workerMachineType パイプライン オプションを使用します。
Python
--machine_type パイプライン オプションを使用します。
Go
--worker_machine_type パイプライン オプションを使用します。
Apache Beam SDK のプロセスを 1 つだけ使用する
Python ストリーミング パイプラインと Runner v2 を使用する Python パイプラインの場合、Dataflow でワーカーごとに 1 つの Apache Beam SDK プロセスのみを開始できます。このオプションを試す前に、他の方法で問題を解決して試みてください。コンテナ化された Python プロセスを 1 つだけ起動するように Dataflow ワーカー VM を構成するには、次のパイプライン オプションを使用します。
--experiments=no_use_multiple_sdk_containers
この構成では、Python パイプラインはワーカーごとに 1 つの Apache Beam SDK プロセスを作成します。これにより、共有オブジェクトとデータが Apache Beam SDK プロセスごとに複数回複製されなくなります。ただし、ワーカーで利用可能なコンピューティング リソースの効率的な使用が制限されます。
Apache Beam SDK のプロセス数を 1 つに減らしても、ワーカーで開始されたスレッドの合計数が必ずしも減少するとは限りません。また、単一の Apache Beam SDK プロセスにすべてのスレッドが含まれていると、処理が遅くなったり、パイプラインが停止する可能性があります。また、このページのスレッド数を減らすで説明されているように、スレッド数の削減が必要になることもあります。
また、vCPU が 1 つしかないマシンタイプを使用することで、ワーカーに Apache Beam SDK プロセスを 1 つだけ使用させることもできます。
Dataflow のメモリ使用量を理解する
Dataflow パイプラインがどのようにメモリを使用するかを理解しておくと、メモリ不足エラーのトラブルシューティングに役立ちます。
Dataflow がパイプラインを実行すると、処理は複数の Compute Engine 仮想マシン(VM)に分散されます。多くの場合、これらの仮想マシンはワーカーと呼ばれます。ワーカーは Dataflow サービスからの作業項目を処理し、Apache Beam SDK プロセスに委任します。Apache Beam SDK プロセスは DoFn のインスタンスを作成します。DoFn は、分散処理関数を定義する Apache Beam SDK クラスです。
Dataflow は各ワーカーで複数のスレッドを起動し、各ワーカーのメモリはすべてのスレッドで共有されます。スレッドは、より大きなプロセス内で実行される単一の実行可能タスクです。デフォルトのスレッド数はさまざまな要因に依存し、バッチジョブとストリーミング ジョブの間でも異なります。
パイプラインに必要なメモリ量がワーカーで使用可能なデフォルトよりも多い場合、メモリ不足エラーが発生する可能性があります。
Dataflow パイプラインは主に、ワーカーメモリを 3 つの方法で使用します。
ワーカーの処理メモリ
Dataflow ワーカーには、オペレーティング システムとシステム プロセス用のメモリが必要です。ワーカーのメモリ使用量が 1 GB を超えることはありません。通常、使用量は 1 GB 未満です。
- パイプラインを正常に動作させるため、ワーカー上のさまざまなプロセスがメモリを使用します。各プロセスで、そのオペレーション用に少量のメモリが予約される場合があります。
- パイプラインが Streaming Engine を使用しない場合、追加のワーカー プロセスがメモリを使用します。
SDK プロセスのメモリ
Apache Beam SDK プロセスは、プロセス内のスレッド間で共有されるオブジェクトとデータを作成する場合があります。このページでは、これを SDK 共有オブジェクトおよびデータと呼びます。これらの SDK 共有オブジェクトとデータが使用するメモリは SDK プロセスメモリと呼ばれます。以下に、SDK の共有オブジェクトとデータの例を示します。
- 副入力
- ML モデル
- メモリ内シングルトン オブジェクト
apache_beam.utils.sharedモジュールで作成された Python オブジェクト- Cloud Storage や BigQuery などの外部ソースから読み込まれたデータ
Streaming Engine を使用しないストリーミング ジョブは副入力をメモリに格納します。Java と Go のパイプラインの場合、各ワーカーが副入力のコピーを 1 つずつ処理します。Python パイプラインの場合、各 Apache Beam SDK プロセスが副入力のコピーを 1 つ処理します。
Streaming Engine を使用するストリーミング ジョブの副入力サイズの上限は 80 MB です。副入力はワーカーメモリの外部に保存されます。
SDK 共有オブジェクトとデータのメモリ使用量は、Apache Beam SDK プロセスの数に比例して増加します。Java と Go のパイプラインでは、ワーカーごとに 1 つの Apache Beam SDK プロセスが開始されます。Python パイプラインでは、vCPU ごとに 1 つの Apache Beam SDK プロセスが開始されます。SDK 共有オブジェクトとデータは、同じ Apache Beam SDK プロセス内のスレッド間で再利用されます。
DoFn メモリの使用
DoFn は、分散処理関数を定義する Apache Beam SDK クラスです。各ワーカーは複数の DoFn インスタンスを並行して実行できます。各スレッドは 1 つの DoFn インスタンスを実行します。メモリ使用量の合計を評価するときに、ワーキング セットのサイズや、アプリケーションの動作継続に必要なメモリの量を計算することが有効な場合があります。たとえば、個々の DoFn が最大 5 MB のメモリを使用し、ワーカーに 300 スレッドがある場合、DoFn のメモリ使用量はピーク時に 1.5 GB(またはメモリのバイト数にスレッド数を乗算した値)になります。ワーカーがメモリを使用する方法によっては、メモリ使用量が急増し、ワーカーがメモリ不足になる可能性があります。
Dataflow が作成する DoFn のインスタンス数を推定することは困難です。この数は、SDK やマシンタイプなど、さまざまな要因によって異なります。また、DoFn は複数のスレッドで連続して使用される場合があります。Dataflow サービスは DoFn の呼び出し回数を保証しません。また、パイプラインで作成される DoFn インスタンスの正確な数も保証しません。次の表に、想定される並列処理レベルに関する分析情報を示します。これにより、DoFn インスタンス数の上限を推測できます。
Beam Python SDK
| バッチ | Streaming Engine を使用しないストリーミング | Streaming Engine | |
|---|---|---|---|
| 並列処理 |
vCPU あたり 1 プロセス プロセスあたり 1 スレッド vCPU あたり 1 スレッド
|
vCPU あたり 1 プロセス プロセスあたり 12 スレッド vCPU あたり 12 スレッド |
vCPU あたり 1 プロセス プロセスあたり 12 スレッド vCPU あたり 12 スレッド
|
同時に実行可能な DoFn インスタンスの最大数(これらの数値は随時変わる可能性があります) |
スレッドあたり 1 DoFnvCPU あたり 1
|
スレッドあたり 1 DoFnvCPU あたり 12
|
スレッドあたり 1 DoFnvCPU あたり 12
|
Beam Java / Go SDK
| バッチ | Streaming Appliance と Streaming Engine(Runner v2 なし) | Streaming Engine(Runner v2 あり) | |
|---|---|---|---|
| 並列処理 |
ワーカー VM あたり 1 プロセス vCPU あたり 1 スレッド
|
ワーカー VM あたり 1 プロセス プロセスあたり 300 スレッド ワーカー VM あたり 300 スレッド
|
ワーカー VM あたり 1 プロセス プロセスあたり 500 スレッド ワーカー VM あたり 500 スレッド
|
同時に実行可能な DoFn インスタンスの最大数(これらの数値は随時変わる可能性があります) |
スレッドあたり 1 DoFnvCPU あたり 1
|
スレッドあたり 1 DoFn
ワーカー VM あたり 300
|
スレッドあたり 1 DoFn
ワーカー VM あたり 500
|
たとえば、n1-standard-2 Dataflow ワーカーで Python SDK を使用する場合、次のようになります。
- バッチジョブ: Dataflow は vCPU ごとに 1 つのプロセスを起動します(この場合は 2 つ)。各プロセスは 1 つのスレッドを使用し、スレッドごとに 1 つの
DoFnインスタンスを作成します。 - Streaming Engine を使用したストリーミング ジョブ: Dataflow は vCPU ごとに 1 つのプロセスを開始します(合計 2 つ)。ただし、各プロセスは最大 12 個のスレッドを生成でき、それぞれに独自の DoFn インスタンスがあります。
複雑なパイプラインを設計する場合は、DoFn のライフサイクルを理解することが重要です。DoFn 関数がシリアル化可能であることを確認します。また、関数内で要素引数を直接変更しないようにします。
多言語パイプラインがあり、ワーカーで複数の Apache Beam SDK が実行されている場合、ワーカーはプロセスあたりのスレッドの並列性を可能な限り低くします。
Java、Go、Python の違い
Java、Go、Python ではプロセスとメモリの管理方法が異なります。そのため、メモリ不足エラーのトラブルシューティングでとるアプローチは、パイプラインで Java、Go、Python のどれを使用しているのかによって異なります。
Java と Go のパイプライン
Java と Go のパイプライン:
- 各ワーカーが 1 つの Apache Beam SDK プロセスを開始します。
- SDK で共有されるオブジェクトとデータ(副入力やキャッシュなど)は、ワーカー上のすべてのスレッドで共有されます。
- SDK の共有オブジェクトとデータで使用されるメモリは、通常、ワーカーの vCPU 数に基づいてスケーリングされません。
Python のパイプライン
Python パイプライン:
- 各ワーカーは、vCPU ごとに 1 つの Apache Beam SDK プロセスを開始します。
- 副入力やキャッシュなどの SDK 共有オブジェクトとデータは、各 Apache Beam SDK プロセス内のすべてのスレッドで共有されます。
- ワーカーのスレッドの合計数は、vCPU の数に基づいて直線的にスケーリングされます。その結果、SDK 共有オブジェクトとメモリで使用されるメモリは、vCPU の数に比例して増加します。
- 処理を実行するスレッドはプロセス間で分散されます。新しい作業単位は、作業項目がないプロセス、または現在割り当てられている作業項目が最も少ないプロセスに割り当てられます。