このページでは、Dataflow パイプラインの開発で使用するベスト プラクティスの概要を説明します。このベスト プラクティスを使用すると、次のようなメリットがあります。
- パイプラインのオブザーバビリティとパフォーマンスの改善
- デベロッパーの生産性向上
- パイプラインのテスト容易性の向上
このページの Apache Beam コード例では Java を使用していますが、Apache Beam Java、Python、Go SDK にも適用されます。
検討事項
パイプラインを設計する際は、次の点を検討してください。
- パイプラインの入力データはどこに格納するのか。入力データは何セットあるのか。
- データはどのような形式か。
- データにはどのような処理を行うのか。
- パイプラインの出力データの送信先はどこにするのか。
- Dataflow ジョブで Assured Workloads を使用するのか。
テンプレートを使用する
パイプライン開発のスピードを上げるには、Apache Beam コードを記述してパイプラインを構築するのではなく、可能な限り Dataflow テンプレートを使用します。テンプレートには次のメリットがあります。
- テンプレートを再利用できる。
- テンプレートを使用することで、特定のパイプライン パラメータを変更して、各ジョブをカスタマイズできる。
- 権限を付与することで、誰でもそのテンプレートを使用してパイプラインをデプロイできる。たとえば、デベロッパーがテンプレートからジョブを作成し、後で同じ組織内のデータ サイエンティストがそのテンプレートをデプロイできます。
Google 提供のテンプレートを使用することも、独自のテンプレートを作成することもできます。Google 提供のテンプレートには、パイプラインのステップとしてカスタム ロジックを追加できるものもあります。たとえば、Pub/Sub to BigQuery テンプレートには、Cloud Storage に保存されている JavaScript ユーザー定義関数(UDF)を実行するためのパラメータが含まれています。
Google 提供のテンプレートは Apache License 2.0 のオープンソースであるため、新しいパイプラインのベースとして使用できます。テンプレートはコードサンプルとしても役立ちます。GitHub リポジトリにあるテンプレート コードをご覧ください。
Assured Workloads
Assured Workloads は、Google Cloud のユーザーにセキュリティとコンプライアンスの要件を適用する際に役立ちます。たとえば、主権管理のある EU リージョンとサポートは、EU 在住のユーザーに対してデータ所在地とデータ主権の保証を適用する際に役立ちます。これらの機能を提供するため、Dataflow の一部の機能が制限または限定されています。Dataflow で Assured Workloads を使用する場合は、パイプラインがアクセスするすべてのリソースを組織の Assured Workloads プロジェクトまたはフォルダに配置する必要があります。次のようなリソースが該当します。
- Cloud Storage バケット
- BigQuery データセット
- Pub/Sub トピックとサブスクリプション
- Firestore データセット
- I/O コネクタ
Dataflow では、2024 年 3 月 7 日以降に作成されたストリーミング ジョブの場合、すべてのユーザーデータが CMEK で暗号化されます。
2024 年 3 月 7 日より前に作成されたストリーミング ジョブの場合、ウィンドウ処理、グループ化、結合などの鍵ベースのオペレーションで使用されるデータ鍵は CMEK 暗号化で保護されません。ジョブでこの暗号化を有効にするには、ジョブをドレインまたはキャンセルしてから、再起動します。詳細については、パイプライン状態アーティファクトの暗号化をご覧ください。
パイプライン間でデータを共有する
パイプライン間でデータや処理コンテキストを共有するための Dataflow 固有のパイプライン間通信メカニズムはありません。Cloud Storage のような永続ストレージ、または App Engine のようなメモリ内キャッシュを使用して、パイプライン インスタンス間でデータを共有できます。
ジョブをスケジュールする
パイプライン実行は、次の方法で自動化できます。
- Cloud Scheduler を使用する。
- Apache Airflow の Dataflow Operator(Cloud Composer ワークフローに含まれる Google Cloud Operator のいずれか)を使用する。
- Compute Engine でカスタム(cron)ジョブプロセスを実行する。
パイプライン コードの作成に関するベスト プラクティス
以降のセクションでは、Apache Beam コードを記述してパイプラインを作成する際のベスト プラクティスについて説明します。
Apache Beam コードの構造
パイプラインを作成するには、通常、汎用の並列処理 Apache Beam 変換 ParDo を使用します。ParDo 変換を適用する場合、ユーザーコードは DoFn オブジェクトの形式で指定します。DoFn は、分散処理関数を定義する Apache Beam SDK クラスです。
DoFn コードは小さな独立したエンティティと考えることができます。異なるマシンで多くのインスタンスが実行され、それぞれが互いを認識していない可能性があります。このため、DoFn 要素の並列的で分散的な性質に最適な純粋関数を作成することをおすすめします。純粋関数には次の特性があります。
- 純粋関数は、隠れ状態や外部状態に依存しません。
- 観察可能な副作用はありません。
- 決定論的です。
純粋関数モデルは厳格ではありません。コードが Dataflow サービスが保証しない事項に左右されなければ、状態情報や外部初期化データは DoFn や他の関数オブジェクトに対して有効になり得ます。
ParDo 変換を構築し、DoFn 要素を作成する場合は、次のガイドラインを考慮してください。
- 1 回限りの処理を使用する場合、Dataflow サービスは、入力
PCollection内のすべての要素がDoFnインスタンスによって 1 回だけ処理されることを保証します。 - Dataflow サービスは、
DoFnが呼び出される回数を保証しません。 - Dataflow サービスは、分散された要素がどのようにグループ化されるかを正確に保証するものではありません。どの要素が一緒に処理されるかは保証しません。
- Dataflow サービスは、パイプラインの過程で作成される
DoFnインスタンスの正確な数を保証しません。 - Dataflow サービスはフォールト トレラントであり、ワーカーに問題が発生した場合にコードを何回も再試行することがあります。
- Dataflow サービスは、コードのバックアップ コピーを作成する場合があります。手動による副作用で問題が発生する可能性があります。たとえば、コードが一意の名前を持たない一時ファイルに依存している場合や、そのようなファイルを作成する場合です。
- Dataflow サービスは、
DoFnインスタンスごとに要素の処理をシリアル化します。コードは厳密にスレッドセーフである必要はありませんが、複数のDoFnインスタンス間で共有される状態はスレッドセーフでなければなりません。
再利用可能な変換のライブラリを作成する
Apache Beam プログラミング モデルでは、変換を再利用できます。共通の変換の共有ライブラリを作成することで、再利用性やテスト容易性が向上し、異なるチームでコードを所有しやすくなります。
次の 2 つの Java サンプルコードについて考えてみましょう。どちらも支払いイベントも読み取ります。両方のパイプラインが同じ処理を実行する場合、共有ライブラリを介して同じ変換を残りの処理ステップで使用できます。
1 つ目の例は、制限のない Pub/Sub をソースとするものです。
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options)
// Initial read transform
PCollection<PaymentEvent> payments =
p.apply("Read from topic",
PubSubIO.readStrings().withTimestampAttribute(...).fromTopic(...))
.apply("Parse strings into payment events",
ParDo.of(new ParsePaymentEventFn()));
2 つ目の例は、制限付きのリレーショナル データベースをソースとするものです。
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
PCollection<PaymentEvent> payments =
p.apply(
"Read from database table",
JdbcIO.<PaymentEvent>read()
.withDataSourceConfiguration(...)
.withQuery(...)
.withRowMapper(new RowMapper<PaymentEvent>() {
...
}));
コードの再利用に関するベスト プラクティスの実装方法は、プログラミング言語やビルドツールによって異なります。たとえば、Maven を使用する場合、変換コードを独自のモジュールに分割できます。これにより、次のサンプルコードに示すように、別のパイプラインで使用可能なマルチモジュール内のサブモジュールとしてモジュールを追加できます。
// Reuse transforms across both pipelines
payments
.apply("ValidatePayments", new PaymentTransforms.ValidatePayments(...))
.apply("ProcessPayments", new PaymentTransforms.ProcessPayments(...))
...
詳細については、Apache Beam ドキュメントの次のページをご覧ください。
- Apache Beam 変換のユーザーコードの作成に関する要件
PTransformスタイルガイド: 新しい再利用可能なPTransformコレクションの作成者向けのスタイルガイド
エラー処理にデッドレター キューを使用する
パイプラインでは要素を処理できない場合があります。データに関する問題がよくある原因です。たとえば、不適切な形式の JSON が要素に含まれているため、解析に失敗することがあります。
DoFn.ProcessElement メソッド内で例外をキャッチし、エラーをログに記録して要素をドロップすることはできますが、この方法ではデータが失われるため、手動処理やトラブルシューティングでデータが検査できなくなります。
代わりに、デッドレター キュー(未処理のメッセージ キュー)というパターンを使用します。DoFn.ProcessElement メソッドで例外をキャッチして、エラーをログに記録します。失敗した要素を削除するのではなく、分岐出力によって別の PCollection オブジェクトに書き込みます。その後、これらの要素はデータシンクに書き込まれるので、後で検査したり、別の変換を使用して処理できます。
次の Java コードの例では、デッドレター キュー パターンの実装方法を示します。
TupleTag<Output> successTag = new TupleTag<>() {};
TupleTag<Input> deadLetterTag = new TupleTag<>() {};
PCollection<Input> input = /* ... */;
PCollectionTuple outputTuple =
input.apply(ParDo.of(new DoFn<Input, Output>() {
@Override
void processElement(ProcessContext c) {
try {
c.output(process(c.element()));
} catch (Exception e) {
LOG.severe("Failed to process input {} -- adding to dead-letter file",
c.element(), e);
c.sideOutput(deadLetterTag, c.element());
}
}).withOutputTags(successTag, TupleTagList.of(deadLetterTag)));
// Write the dead-letter inputs to a BigQuery table for later analysis
outputTuple.get(deadLetterTag)
.apply(BigQueryIO.write(...));
// Retrieve the successful elements...
PCollection<Output> success = outputTuple.get(successTag);
// and continue processing ...
Cloud Monitoring を使用して、パイプラインのデッドレター キューにさまざまなモニタリング ポリシーとアラート ポリシーを適用します。たとえば、デッドレター変換によって処理される要素の数とサイズを可視化し、特定のしきい値条件が満たされたときにトリガーするアラートを構成できます。
スキーマ ミューテーションを処理する
失敗した要素を別の PCollection オブジェクトに書き込むデッドレター パターンを使用すると、予期しない(しかし有効な)スキーマを持つデータを処理できます。場合によっては、変異したスキーマを反映した要素を、有効な要素として自動的に処理したいことがあります。たとえば、要素のスキーマに新しいフィールドの追加などのミューテーションが反映される場合、変更に合わせてデータシンクのスキーマを適応できます。
自動スキーマ ミューテーションは、デッドレター パターンによって使用される分岐出力アプローチに依存します。しかし、この場合、追加のスキーマが発生するたびに宛先スキーマを変更する変換がトリガーされます。このアプローチの例については、 Google Cloud ブログの Square Enix とストリーミング パイプラインで JSON スキーマの変更を処理する方法をご覧ください。
データセットの結合方法を決定する
データセットの結合は、データ パイプラインの一般的なユースケースです。副入力または CoGroupByKey 変換を使用して、パイプラインで結合を行えます。それぞれにメリットとデメリットがあります。
副入力を使用すると、データ拡充やキーによるルックアップなど、一般的なデータ処理に関する問題を柔軟に解決できます。PCollection オブジェクトとは異なり、副入力は変更可能で、実行時に決定できます。たとえば、副入力の値はパイプラインの別のブランチによって計算することも、リモート サービスを呼び出して決定することもできます。
Dataflow では、データを永続ストレージ(共有ディスクと同様)に保持することで副入力をサポートしています。この構成により、すべてのワーカーが完全な副入力を利用できるようになります。
しかし、副入力のサイズは非常に大きくなる可能性があり、ワーカーのメモリに収まらないかもしれません。ワーカーで永続ストレージから常に読み取りを行う必要がある場合、サイズの大きい副入力からの読み取りでパフォーマンスの問題が発生する可能性があります。
CoGroupByKey 変換は、複数の PCollection オブジェクトを統合(フラット化)し、共通鍵を持つ要素をグループ化するコアの Apache Beam 変換です。副入力データ全体が各ワーカーで使用可能になる副入力とは異なり、CoGroupByKey はシャッフル(グループ化)オペレーションを実行してワーカー間でデータを分散します。そのため、結合する PCollection オブジェクトが非常に大きくワーカーメモリに収まらない場合は、CoGroupByKey が最適です。
以下のガイドラインに従って、副入力を使用するか CoGroupByKey を使用するかを判断してください。
- 結合する
PCollectionオブジェクトの一方がもう一方よりも非常に小さく、小さいPCollectionオブジェクトがワーカーメモリに収まる場合は、副入力を使用します。副入力全体をメモリ キャッシュに格納することで、要素をすばやく効率的に取得できます。 - パイプライン内で結合を複数回実行する必要がある
PCollectionオブジェクトがある場合は、副入力を使用します。複数のCoGroupByKey変換を使用する代わりに、複数のParDo変換で再利用できる副入力を 1 つ作成します。 - ワーカーメモリを大幅に超える
PCollectionオブジェクトの大部分を取得する必要がある場合は、CoGroupByKeyを使用します。
詳細については、Dataflow のメモリ不足エラーのトラブルシューティングをご覧ください。
要素あたりのオペレーション費用を最小限に抑える
DoFn インスタンスは、ゼロ個以上の要素で構成される極小の作業単位であるバンドルという要素のバッチを処理します。個々の要素は、すべての要素に対して実行される DoFn.ProcessElement メソッドで処理されます。DoFn.ProcessElement メソッドは要素ごとに呼び出されます。このため、このメソッドで呼び出される長時間オペレーションや計算コストの高いオペレーションは、メソッドによって処理されるすべての要素に対して実行されます。
要素のバッチに対してコストのかかるオペレーションを 1 回だけ実行する必要がある場合は、これらのオペレーションを DoFn.ProcessElement 要素ではなく、DoFn.Setup メソッドまたは DoFn.StartBundle メソッドに含めます。たとえば、次のオペレーションがあります。
DoFnインスタンスの動作の一部を制御する構成ファイルの解析。DoFn.Setupメソッドを使用してDoFnインスタンスを初期化するときに、このアクションを 1 回だけ呼び出します。バンドル内のすべての要素で再利用される有効期間の短いクライアントをインスタンス化します。たとえば、バンドル内のすべての要素が 1 つのネットワーク接続で送信されるような場合です。
DoFn.StartBundleメソッドを使用して、バンドルごとにこのアクションを 1 回呼び出します。
バッチサイズと外部サービスの同時呼び出しを制限する
外部サービスを呼び出す場合、GroupIntoBatches 変換を使用すると、呼び出しごとのオーバーヘッドを削減できます。この変換では、指定したサイズの要素のバッチを作成します。バッチ処理では、要素が個別にではなく、1 つのペイロードとして外部サービスに送信されます。
バッチ処理と組み合わせて使用することで、受信データをパーティションに分割する適切なキーを選択して、外部サービスへの並列(同時)呼び出しの最大数を制限します。パーティションの数によって並列化の最大数が決まります。たとえば、すべての要素に同じキーを設定すると、外部サービスを呼び出すためのダウンストリーム変換は同時に実行されません。
要素に対してキーを生成する場合は、次のいずれかの方法を検討してください。
- データキーとして使用するデータセットの属性(ユーザー ID など)を選択します。
- データキーを生成して、固定数のパーティションで要素をランダムに分割します。パーティションの数は、使用可能なキー値の数によって決まります。並列化のために十分なパーティションを作成する必要があります。各パーティションには、
GroupIntoBatches変換が機能するために十分な数の要素が必要です。
次の Java コードの例では、10 個のパーティションに要素をランダムに分割する方法を示します。
// PII or classified data which needs redaction.
PCollection<String> sensitiveData = ...;
int numPartitions = 10; // Number of parallel batches to create.
PCollection<KV<Long, Iterable<String>>> batchedData =
sensitiveData
.apply("Assign data into partitions",
ParDo.of(new DoFn<String, KV<Long, String>>() {
Random random = new Random();
@ProcessElement
public void assignRandomPartition(ProcessContext context) {
context.output(
KV.of(randomPartitionNumber(), context.element()));
}
private static int randomPartitionNumber() {
return random.nextInt(numPartitions);
}
}))
.apply("Create batches of sensitive data",
GroupIntoBatches.<Long, String>ofSize(100L));
// Use batched sensitive data to fully utilize Redaction API,
// which has a rate limit but allows large payloads.
batchedData
.apply("Call Redaction API in batches", callRedactionApiOnBatch());
不適切に融合された手順によるパフォーマンスの問題を特定する
Dataflow は、変換およびそのパイプラインの作成に使用したデータに基づいて、パイプラインを表すステップのグラフを作成します。これはパイプライン実行グラフと呼ばれます。
パイプラインをデプロイするときに、Dataflow でパイプライン実行グラフを変更することでパフォーマンスを改善できます。たとえば、Dataflow で融合最適化というプロセスを使用して一部のオペレーションを融合することで、パイプライン内のすべての中間 PCollection オブジェクトの書き込みに伴うパフォーマンスとコストへの影響を回避できます。
場合によっては、Dataflow がパイプライン内でオペレーションを融合する最適な方法の選択を誤り、Dataflow サービスが利用可能なワーカーを十分に利用できなくなる可能性があります。このような場合は、オペレーションが融合されないようにできます。
次の Apache Beam コードの例について考えてみましょう。GenerateSequence 変換では、小規模な制限付き PCollection オブジェクトが作成され、2 つのダウンストリーム ParDo 変換によって処理されます。
Find Primes Less-than-N 変換は計算コストが高く、値の数が多くなると実行に時間がかかる可能性があります。対照的に、Increment Number 変換は、おそらく迅速に完了します。
import com.google.common.math.LongMath;
...
public class FusedStepsPipeline {
final class FindLowerPrimesFn extends DoFn<Long, String> {
@ProcessElement
public void processElement(ProcessContext c) {
Long n = c.element();
if (n > 1) {
for (long i = 2; i < n; i++) {
if (LongMath.isPrime(i)) {
c.output(Long.toString(i));
}
}
}
}
}
public static void main(String[] args) {
Pipeline p = Pipeline.create(options);
PCollection<Long> sequence = p.apply("Generate Sequence",
GenerateSequence
.from(0)
.to(1000000));
// Pipeline branch 1
sequence.apply("Find Primes Less-than-N",
ParDo.of(new FindLowerPrimesFn()));
// Pipeline branch 2
sequence.apply("Increment Number",
MapElements.via(new SimpleFunction<Long, Long>() {
public Long apply(Long n) {
return ++n;
}
}));
p.run().waitUntilFinish();
}
}
次の図は、Dataflow モニタリング インターフェースのパイプラインのグラフ表現を示しています。
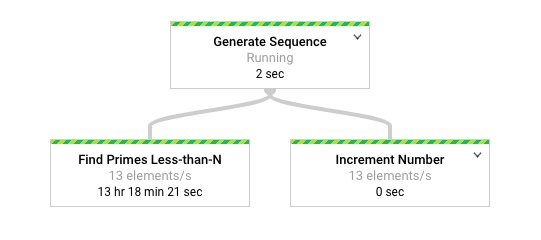
Dataflow モニタリング インターフェースでは、両方の変換で同じ遅い処理速度(1 秒あたり 13 要素)が発生していることを示しています。Increment Number 変換で要素が迅速に処理されることを期待したものの、そうではなく、Find Primes Less-than-N と同じ処理レートに拘束されているように見えます。
この理由は、Dataflow がステップを 1 つのステージに融合していて、個別に実行できないためです。詳細情報は、gcloud dataflow jobs describe コマンドを使用して表示できます。
gcloud dataflow jobs describe --full job-id --format json
結果の出力で、融合されたステップの説明は ComponentTransform 配列内の ExecutionStageSummary オブジェクトにあります。
...
"executionPipelineStage": [
{
"componentSource": [
...
],
"componentTransform": [
{
"name": "s1",
"originalTransform": "Generate Sequence/Read(BoundedCountingSource)",
"userName": "Generate Sequence/Read(BoundedCountingSource)"
},
{
"name": "s2",
"originalTransform": "Find Primes Less-than-N",
"userName": "Find Primes Less-than-N"
},
{
"name": "s3",
"originalTransform": "Increment Number/Map",
"userName": "Increment Number/Map"
}
],
"id": "S01",
"kind": "PAR_DO_KIND",
"name": "F0"
}
...
このシナリオでは、Find Primes Less-than-N 変換は遅いステップであるため、このステップの前に融合を解除することが適切といえます。ステップの融合を解除する 1 つの方法は、次の Java コードの例のように、ステップの前に GroupByKey 変換を挿入してグループ化を解除することです。
sequence
.apply("Map Elements", MapElements.via(new SimpleFunction<Long, KV<Long, Void>>() {
public KV<Long, Void> apply(Long n) {
return KV.of(n, null);
}
}))
.apply("Group By Key", GroupByKey.<Long, Void>create())
.apply("Emit Keys", Keys.<Long>create())
.apply("Find Primes Less-than-N", ParDo.of(new FindLowerPrimesFn()));
これらの融合を解除するステップを組み合わせて、再利用可能な複合変換にすることもできます。
ステップの融合を解除した後、パイプラインを実行すると、Increment Number は数秒で完了し、より長時間実行される Find Primes Less-than-N 変換が別のステージで実行されます。
この例では、グループ化解除操作を適用して、ステップの融合を解除します。ほかの状況では別のアプローチも可能です。この場合、GenerateSequence 変換の連続出力による重複出力の処理は問題になりません。キーが重複している KV オブジェクトは、グループ化(GroupByKey)変換とグループ解除(Keys)変換で重複が除去され、キーが 1 つになります。グループ化オペレーションとグループ解除オペレーションの後も重複を保持するには、次の手順で Key-Value ペアを作成します。
- ランダムなキーと元の入力を値として使用する。
- ランダムキーを使用してグループ化する。
- 各キーの値を出力する。
Reshuffle 変換を使用して、周囲の変換の融合を防ぐこともできます。ただし、Reshuffle 変換の副作用として、異なる Apache Beam ランナー間の移植性はありません。
並列処理と融合の最適化の詳細については、パイプラインのライフサイクルをご覧ください。
Apache Beam 指標を使用してパイプライン分析情報を収集する
Apache Beam 指標は、実行中のパイプラインのプロパティをレポートする指標を生成するユーティリティ クラスです。Cloud Monitoring を使用する場合、Apache Beam の指標は Cloud Monitoring のカスタム指標として利用できます。
次の例では、DoFn サブクラスで使用される Apache Beam Counter 指標を示します。
このサンプルコードでは 2 つのカウンタを使用しています。一方のカウンタでは JSON 解析エラー(malformedCounter)が追跡され、もう一方のカウンタでは JSON メッセージが有効のときに空のペイロード(emptyCounter)が含まれているかどうかが追跡されます。Cloud Monitoring では、カスタム指標の名前は custom.googleapis.com/dataflow/malformedJson と custom.googleapis.com/dataflow/emptyPayload になります。カスタム指標を使用すると、Cloud Monitoring で可視化とアラート ポリシーを作成できます。
final TupleTag<String> errorTag = new TupleTag<String>(){};
final TupleTag<MockObject> successTag = new TupleTag<MockObject>(){};
final class ParseEventFn extends DoFn<String, MyObject> {
private final Counter malformedCounter = Metrics.counter(ParseEventFn.class, "malformedJson");
private final Counter emptyCounter = Metrics.counter(ParseEventFn.class, "emptyPayload");
private Gson gsonParser;
@Setup
public setup() {
gsonParser = new Gson();
}
@ProcessElement
public void processElement(ProcessContext c) {
try {
MyObject myObj = gsonParser.fromJson(c.element(), MyObject.class);
if (myObj.getPayload() != null) {
// Output the element if non-empty payload
c.output(successTag, myObj);
}
else {
// Increment empty payload counter
emptyCounter.inc();
}
}
catch (JsonParseException e) {
// Increment malformed JSON counter
malformedCounter.inc();
// Output the element to dead-letter queue
c.output(errorTag, c.element());
}
}
}
詳細
以下のページでは、パイプラインを構築する方法、データに適用する変換を選択する方法、パイプラインの入力方法と出力方法を選択する際の考慮事項を説明しています。
ユーザーコードの詳しい作成方法については、ユーザー定義関数の要件をご覧ください。