A interface de monitoramento do Dataflow fornece uma representação gráfica de cada job: o gráfico de jobs. O gráfico do job também fornece um resumo e um registro do job, além de informações sobre cada etapa do pipeline.
Para conferir o gráfico de um job, siga estas etapas:
No Google Cloud console, acesse a página Dataflow > Jobs.
Selecione um job.
Clique na guia Gráfico de jobs.
Por padrão, a página do gráfico de jobs exibe a Visualização de gráfico. Para acessar seu job gráfico como uma tabela, em Visualização das etapas do job, selecione Visualização da tabela. Visualização em tabela contém as mesmas informações em um formato diferente. A visualização em tabela útil nos seguintes cenários:
- Seu job tem muitos estágios, o que dificulta a navegação no gráfico.
- Você quer classificar as etapas do job por uma propriedade específica. Por exemplo, você pode classificar a tabela por tempo decorrido para identificar etapas lentas.
Visualização em gráfico
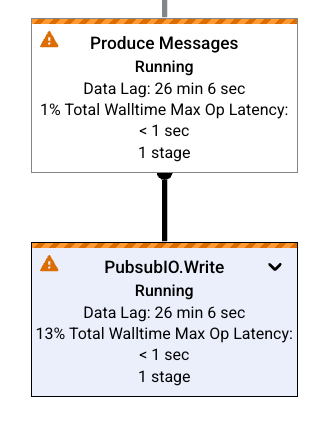
O gráfico do job representa cada transformação no pipeline como uma caixa. A imagem a seguir mostra um gráfico de job com três transformações: Read PubSub Events, 5m Window e Write File(s).

Cada caixa contém as seguintes informações:
Status: um dos seguintes:
- Em execução: a etapa está em execução.
- Em fila: a etapa em que um job do FlexRS entra na fila.
- Com êxito: a etapa foi concluída com sucesso.
- Parado: a etapa foi interrompida porque o job parou.
- Desconhecido: a etapa não informou o status.
- Com falha: a etapa não foi concluída.
O número de estágios do job que executam esta etapa
Se uma etapa representar uma transformação composta, expanda-a para ver as subtransformações. Para expandir a etapa, clique na seta Expandir nó.
Nomes de transformação
O Dataflow tem algumas maneiras diferentes para chegar ao nome da transformação mostrado no gráfico do job de monitoramento: Os nomes de transformação são usados em locais visíveis publicamente, incluindo a interface de monitoramento do Dataflow, os arquivos de registros e as ferramentas de depuração. Não use nomes de transformação que incluam informações de identificação pessoal, como nomes de usuário ou nomes de organizações.
Java
- O Dataflow pode usar um nome já atribuído quando você aplica a transformação. O primeiro
argumento fornecido para o método
applyé o nome da transformação. - O Dataflow pode inferir o nome da transformação, seja do nome da classe, se você criou uma transformação personalizada, ou do nome do objeto de função
DoFn, se você estiver usando uma transformação básica, comoParDo.
Python
- O Dataflow pode usar um nome já atribuído quando você aplica a transformação. Para definir o nome da transformação, especifique o argumento
labeldela. - O Dataflow pode inferir o nome da transformação, seja do nome da classe, se você criar uma transformação personalizada, ou do nome do objeto de função
DoFn, se você usar uma transformação básica, comoParDo.
Go
- O Dataflow pode usar um nome já atribuído quando você aplica a transformação. É possível definir o nome de transformação especificando
Scope. - O Dataflow pode inferir o nome de transformação, seja do nome da estrutura se você estiver usando um
DoFnestrutural ou do nome da função se estiver usando umDoFnfuncional.
Conferir informações da etapa
Quando você clica em uma etapa no gráfico de job, o painel Informações da etapa mostra mais detalhes sobre ela. Para mais informações, consulte Informações da etapa do job.
Gargalos
Se o Dataflow detectar um gargalo, o gráfico de jobs vai mostrar um símbolo de alerta nas etapas afetadas. Para saber a causa do gargalo, clique na etapa para abrir o painel Informações da etapa. Para mais informações, consulte Solução de problemas de gargalos.
Exemplos de gráficos de jobs
Esta seção mostra alguns exemplos de código de pipeline e os gráficos de job correspondentes.
Gráfico básico do job
Código do pipeline:Java// Read the lines of the input text. p.apply("ReadLines", TextIO.read().from(options.getInputFile())) // Count the words. .apply(new CountWords()) // Write the formatted word counts to output. .apply("WriteCounts", TextIO.write().to(options.getOutput())); Python( pipeline # Read the lines of the input text. | 'ReadLines' >> beam.io.ReadFromText(args.input_file) # Count the words. | CountWords() # Write the formatted word counts to output. | 'WriteCounts' >> beam.io.WriteToText(args.output_path)) Go// Create the pipeline. p := beam.NewPipeline() s := p.Root() // Read the lines of the input text. lines := textio.Read(s, *input) // Count the words. counted := beam.ParDo(s, CountWords, lines) // Write the formatted word counts to output. textio.Write(s, *output, formatted) |
Gráfico do job:

|
Gráfico de jobs com transformações compostas
As transformações compostas contêm várias subtransformações aninhadas. No gráfico do job, as transformações compostas são expansíveis. Para expandir a transformação e conferir as subtransformações, clique na seta.
Código do pipeline:Java// The CountWords Composite Transform // inside the WordCount pipeline. public static class CountWords extends PTransform<PCollection<String>, PCollection<String>> { @Override public PCollection<String> apply(PCollection<String> lines) { // Convert lines of text into individual words. PCollection<String> words = lines.apply( ParDo.of(new ExtractWordsFn())); // Count the number of times each word occurs. PCollection<KV<String, Long>> wordCounts = words.apply(Count.<String>perElement()); return wordCounts; } } Python# The CountWords Composite Transform inside the WordCount pipeline. @beam.ptransform_fn def CountWords(pcoll): return ( pcoll # Convert lines of text into individual words. | 'ExtractWords' >> beam.ParDo(ExtractWordsFn()) # Count the number of times each word occurs. | beam.combiners.Count.PerElement() # Format each word and count into a printable string. | 'FormatCounts' >> beam.ParDo(FormatCountsFn())) Go// The CountWords Composite Transform inside the WordCount pipeline. func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection { s = s.Scope("CountWords") // Convert lines of text into individual words. col := beam.ParDo(s, &extractFn{SmallWordLength: *smallWordLength}, lines) // Count the number of times each word occurs. return stats.Count(s, col) } |
Gráfico do job:

|
No código do pipeline, é possível usar o seguinte código para invocar sua transformação composta:
result = transform.apply(input);
Transformações compostas invocadas dessa maneira omitem o aninhamento esperado e podem aparecer expandidas na interface de monitoramento do Dataflow. O pipeline também gera avisos ou erros sobre nomes únicos estáveis no ambiente de execução do pipeline.
Para evitar esses problemas, chame a transformação usando o formato recomendado:
result = input.apply(transform);
A seguir
- Ver informações detalhadas da etapa do job
- Ver as fases do job na guia Detalhes da execução
- Resolver problemas do pipeline