Le générateur de jobs est une interface utilisateur visuelle permettant de créer et d'exécuter des pipelines Dataflow dans la console Google Cloud , sans avoir à écrire de code.
L'image suivante montre des détails provenant de l'interface utilisateur du générateur de jobs. Dans cette image, l'utilisateur crée un pipeline pour lire les données depuis Pub/Sub et les écrire dans BigQuery :
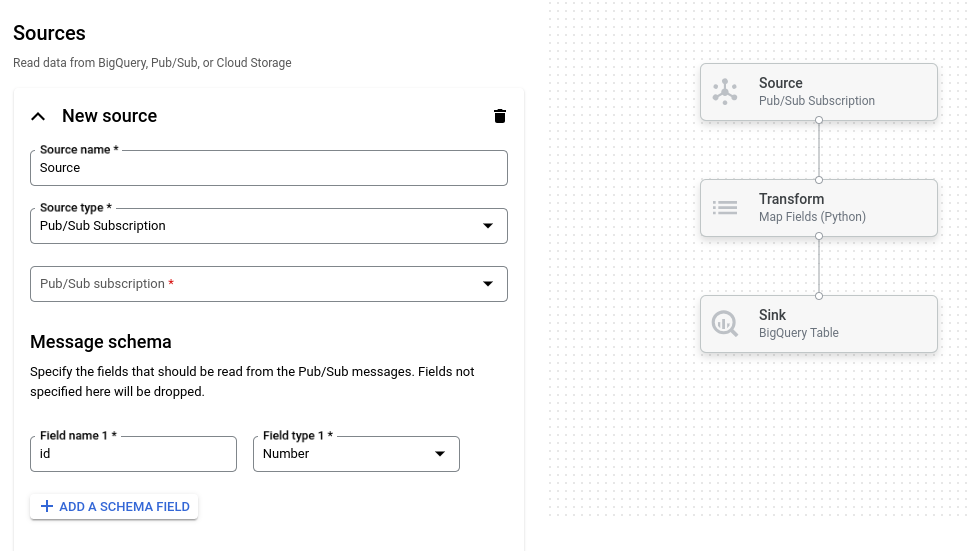
Présentation
Le générateur de tâches prend en charge la lecture et l'écriture des types de données suivants :
- Messages Pub/Sub
- Données de table BigQuery
- Fichiers CSV, JSON et texte dans Cloud Storage
- Données de table PostgreSQL, MySQL, Oracle et SQL Server
Il est compatible avec les transformations de pipeline, y compris le filtrage, le mappage, SQL, group-by, join et explode (aplatissement de tableau).
Avec le générateur de jobs, vous pouvez :
- Diffuser des données en streaming depuis Pub/Sub vers BigQuery avec des transformations et une agrégation par fenêtre
- Écrire des données de Cloud Storage vers BigQuery
- Utiliser la gestion des exceptions pour filtrer les données erronées (file d'attente de lettres mortes)
- Manipuler ou agréger des données à l'aide de SQL avec la transformation SQL
- Ajouter, modifier ou supprimer des champs de données avec des transformations de mappage
- Planifier des jobs par lot récurrents
Le générateur de jobs peut également enregistrer les pipelines en tant que fichiers Apache Beam YAML et charger les définitions de pipeline à partir de fichiers Beam YAML. Cette fonctionnalité vous permet de concevoir votre pipeline dans le générateur de tâches, puis de stocker le fichier YAML dans Cloud Storage ou dans un dépôt de gestion des sources pour le réutiliser. Les définitions de job YAML peuvent également être utilisées pour lancer des jobs à l'aide de gcloud CLI.
Envisageons d'utiliser le générateur de tâches pour les cas d'utilisation suivants :
- Vous souhaitez créer un pipeline rapidement sans écrire de code.
- Vous souhaitez enregistrer un pipeline au format YAML pour le réutiliser.
- Votre pipeline peut être exprimé à l'aide des sources, des récepteurs et des transformations compatibles.
- Aucun modèle fourni par Google ne correspond à votre cas d'utilisation.
Exécuter un exemple de job
L'exemple Word Count est un pipeline par lots qui lit du texte de Cloud Storage, segmente les lignes en mots individuels et compte le nombre de fois où chacun de ces mots apparaît.
Si le bucket Cloud Storage ne se trouve pas dans votre périmètre de service, créez une règle de sortie qui autorise l'accès au bucket.
Pour exécuter le pipeline "Word Count" (Nombre de mots), procédez comme suit :
Accédez à la page Jobs de la console Google Cloud .
Cliquez sur Créer un job à partir d'un modèle.
Dans le panneau latéral, cliquez sur Générateur de tâches.
Cliquez sur Charger des plans.
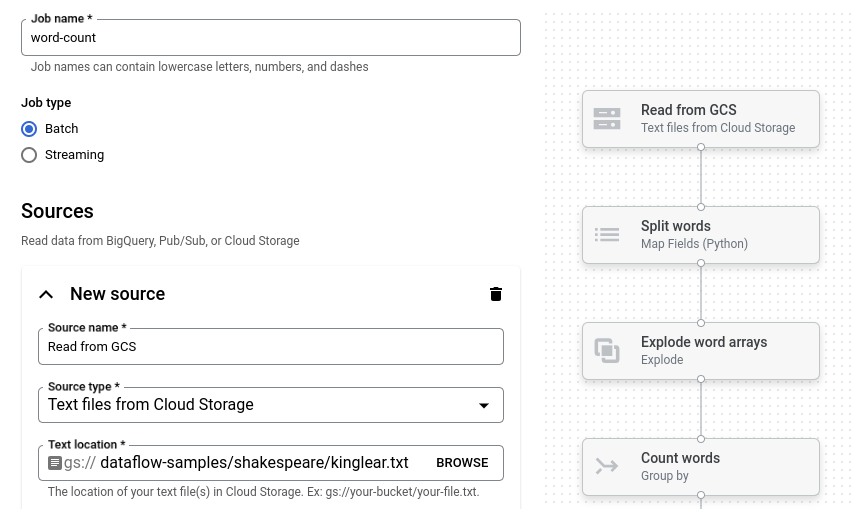
Cliquez sur Nombre de mots. Le générateur de jobs est renseigné avec une représentation graphique du pipeline.
Pour chaque étape du pipeline, le générateur de jobs affiche une fiche qui spécifie les paramètres de configuration de cette étape. Par exemple, la première étape lit les fichiers texte à partir de Cloud Storage. L'emplacement des données sources est prérempli dans la zone Emplacement du texte.
Recherchez la fiche intitulée Nouveau récepteur. Vous devrez peut-être faire défiler la page.
Dans la zone Emplacement du texte, saisissez le préfixe du chemin d'accès Cloud Storage pour les fichiers texte de sortie.
Cliquez sur Run Job (Exécuter la tâche). Le générateur de jobs crée un job Dataflow, puis accède au graphique de job. Au démarrage du job, le graphique de job affiche une représentation graphique du pipeline. Cette représentation graphique est semblable à celle affichée dans le générateur de jobs. À chaque étape du pipeline, l'état est mis à jour dans le graphique de job.
Le panneau Informations sur le job affiche l'état général du job. Si le job se termine correctement, le champ État du job est défini sur Succeeded.
Étapes suivantes
- Utiliser l'interface de surveillance des jobs Dataflow
- Créez un job personnalisé dans le générateur de jobs.
- Enregistrez et chargez les définitions de job YAML dans le générateur de jobs.
- Apprenez-en plus sur YAML Beam.