Utilizza l'esecutore interattivo Apache Beam con i notebook JupyterLab per completare le seguenti attività:
- Sviluppa le pipeline in modo iterativo.
- Esamina il grafico della pipeline.
- Analizza i singoli
PCollectionsin un flusso di lavoro Read–Eval–Print Loop (REPL).
Questi blocchi note Apache Beam sono disponibili tramite Vertex AI Workbench, un servizio che ospita macchine virtuali notebook con i più recenti framework di data science e machine learning preinstallati. Dataflow supporta solo le istanze Workbench che utilizzano il contenitore Apache Beam.
Questa guida si concentra sulle funzionalità introdotte dai blocchi note Apache Beam, ma non mostra come creare un blocco note. Per saperne di più su Apache Beam, consulta la guida alla programmazione di Apache Beam.
Supporto e limitazioni
- I blocchi note Apache Beam supportano solo Python.
- I segmenti della pipeline Apache Beam eseguiti in questi blocchi note vengono eseguiti in un ambiente di test e non su un runner Apache Beam di produzione. Per avviare i blocchi note nel servizio Dataflow, esporta le pipeline create nel blocco note Apache Beam. Per maggiori dettagli, vedi Avviare job Dataflow da una pipeline creata nel notebook.
Prima di iniziare
- Sign in to your Google Cloud Platform account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Nella console Google Cloud , vai alla pagina Workbench di Dataflow.
Assicurati di trovarti nella scheda ISTANZE.
Nella barra degli strumenti, fai clic su Crea nuovo.
Nella sezione Ambiente, per Ambiente, Container deve essere Apache Beam. Per i notebook Apache Beam è supportato solo JupyterLab 3.x.
(Facoltativo) Se vuoi eseguire notebook su una GPU, nella sezione Tipo di macchina, seleziona un tipo di macchina che supporti le GPU. Per ulteriori informazioni, consulta Piattaforme GPU.
Nella sezione Networking, seleziona una subnet per la VM notebook.
(Facoltativo) Se vuoi configurare un'istanza di notebook personalizzata, consulta la sezione Creazione di un'istanza utilizzando un container personalizzato.
Fai clic su Crea. Dataflow Workbench crea una nuova istanza del notebook Apache Beam.
Dopo aver creato l'istanza di blocco note, il link Apri JupyterLab diventa attivo. Fai clic su Apri JupyterLab.
- Conteggio parole
- Conteggio parole dello streaming
- Genera flussi di dati sulle corse in taxi a New York
- Apache Beam SQL nei notebook con confronti con le pipeline
- Apache Beam SQL nei notebook con Dataflow Runner
- Apache Beam SQL nei notebook
- Conteggio parole Dataflow
- Interactive Flink at Scale
- RunInference
- Utilizzare le GPU con Apache Beam
- Visualizzare i dati
- Operazioni di base
- Operazioni elemento per elemento
- Aggregazioni
- Windows
- Operazioni di I/O
- Streaming
- Esercizi finali
- Imposta
nper limitare il set di risultati in modo da mostrare al massimonelementi, ad esempio 20. Sennon è impostato, il comportamento predefinito consiste nell'elencare gli elementi più recenti acquisiti fino al termine della registrazione della fonte. - Imposta
durationper limitare il set di risultati a un numero specificato di secondi di dati a partire dall'inizio della registrazione della sorgente. Sedurationnon è impostato, il comportamento predefinito è elencare tutti gli elementi fino al termine della registrazione. Fai clic su
Interactive Beamsulla barra dei menu in alto di JupyterLab. Nel menu a discesa, individuaOpen Inspectore fai clic per aprire l'inspector.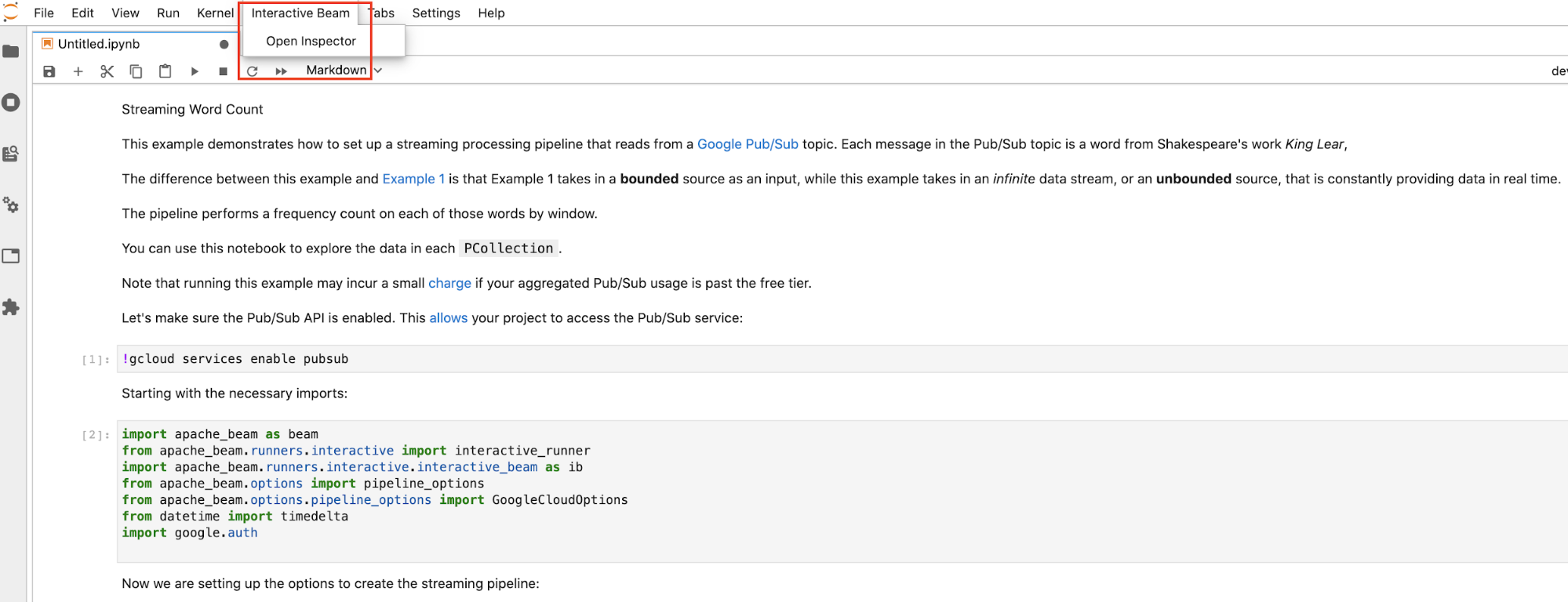
Utilizza la pagina di avvio. Se non è aperta alcuna pagina di avvio, fai clic su
File->New Launcherper aprirla. Nella pagina di avvio, individuaInteractive Beame fai clic suOpen Inspectorper aprire lo strumento di ispezione.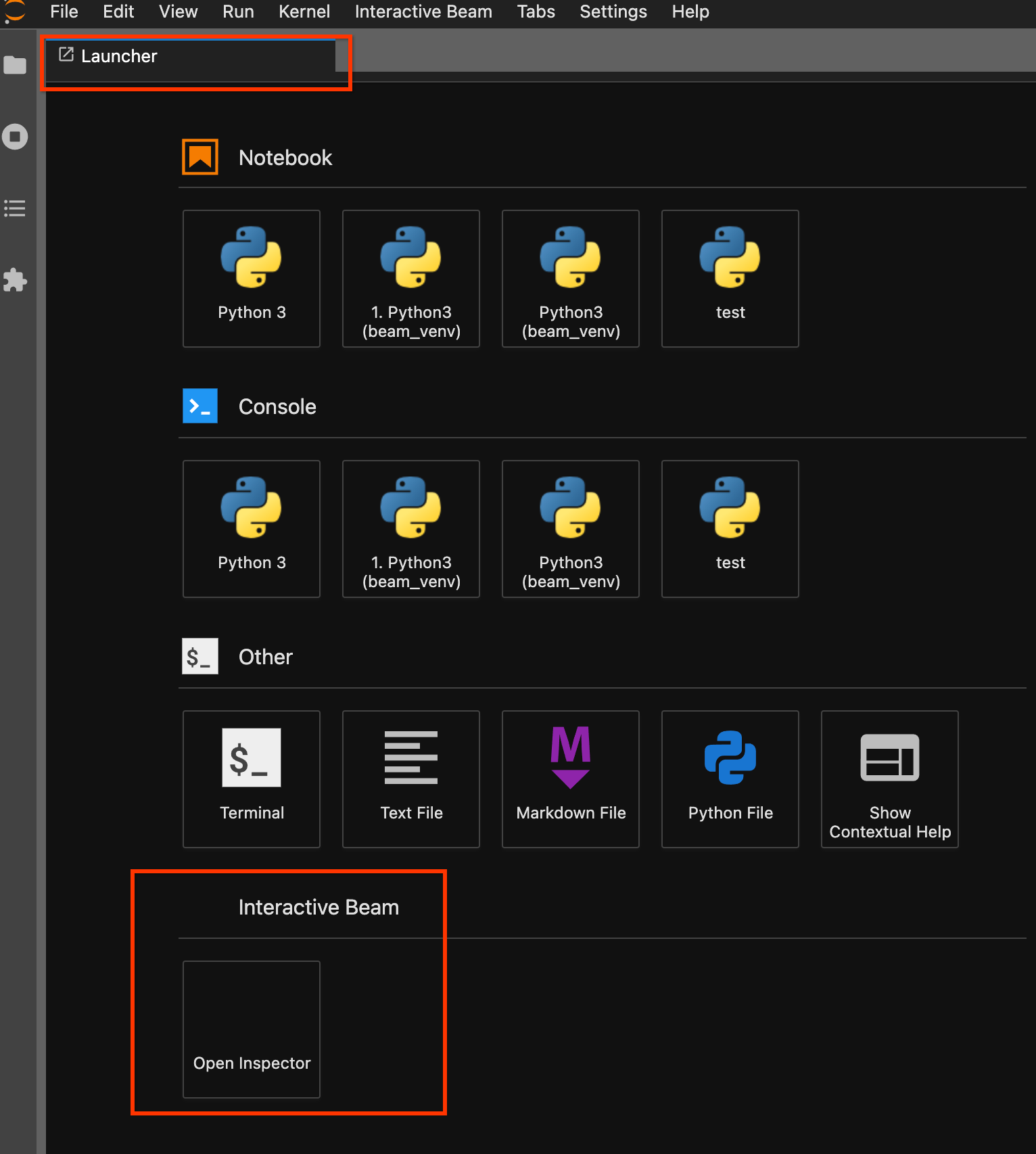
Utilizza la tavolozza dei comandi. Nella barra dei menu di JupyterLab, fai clic su
View>Activate Command Palette. Nella finestra di dialogo, cercaInteractive Beamper elencare tutte le opzioni dell'estensione. Fai clic suOpen Inspectorper aprire lo strumento di ispezione.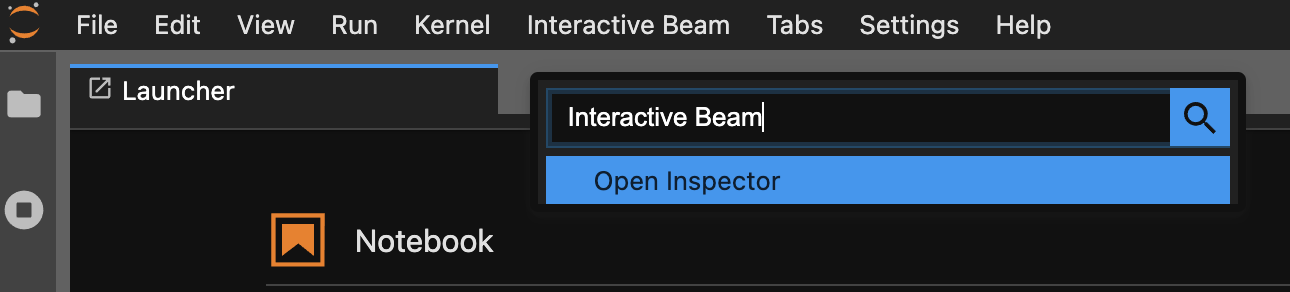
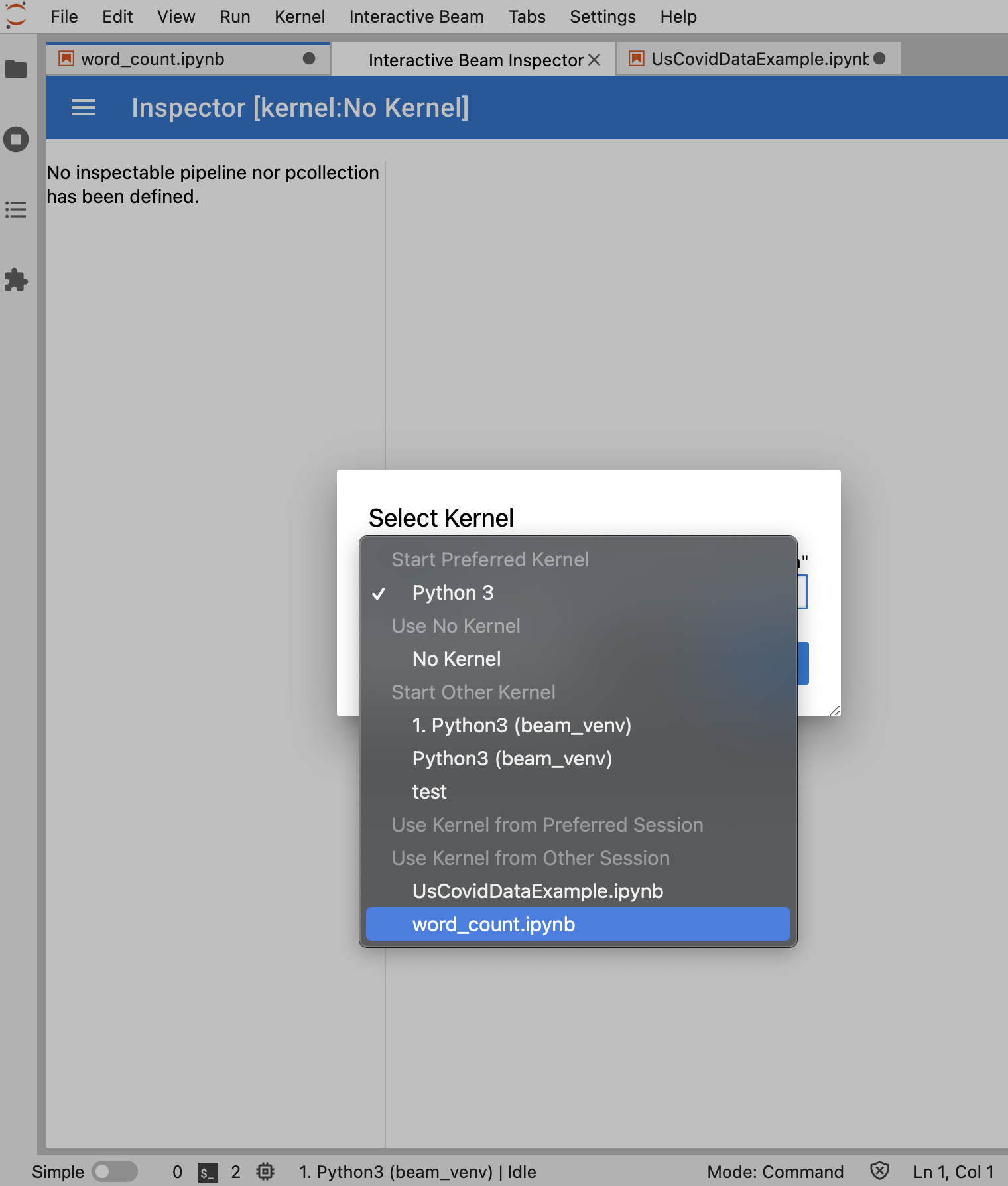
Se è aperto un solo blocco note, l'inspector si connette automaticamente.
Se non è aperto alcun notebook, viene visualizzata una finestra di dialogo che consente di selezionare un kernel.
Se sono aperti più notebook, viene visualizzata una finestra di dialogo che ti consente di selezionare la sessione del notebook.
Se si tratta di un
PCollection, l'inspector esegue il rendering dei dati (dinamicamente se i dati sono ancora in arrivo perPCollectionssenza limiti) con widget aggiuntivi per ottimizzare la visualizzazione dopo aver fatto clic sul pulsanteAPPLY.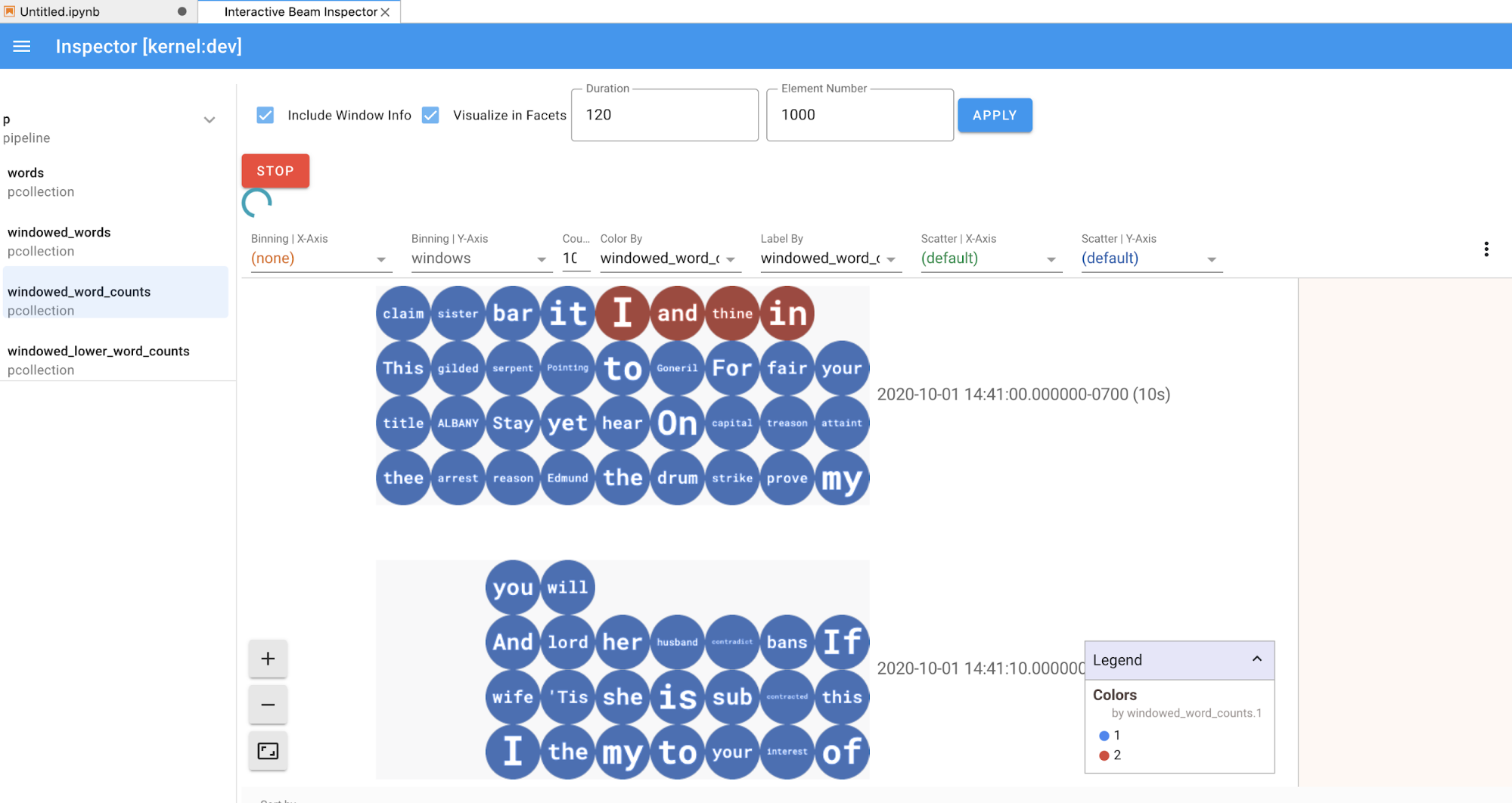
Poiché l'inspector e il notebook aperto condividono la stessa sessione del kernel, si bloccano a vicenda. Ad esempio, se il notebook è impegnato nell'esecuzione del codice, l'inspector non viene aggiornato finché il notebook non completa l'esecuzione. Al contrario, se vuoi eseguire immediatamente il codice nel notebook mentre l'inspector visualizza un
PCollectionin modo dinamico, devi fare clic sul pulsanteSTOPper interrompere la visualizzazione e rilasciare in modo preventivo il kernel nel notebook.Se si tratta di una pipeline, l'inspector mostra il grafico della pipeline.
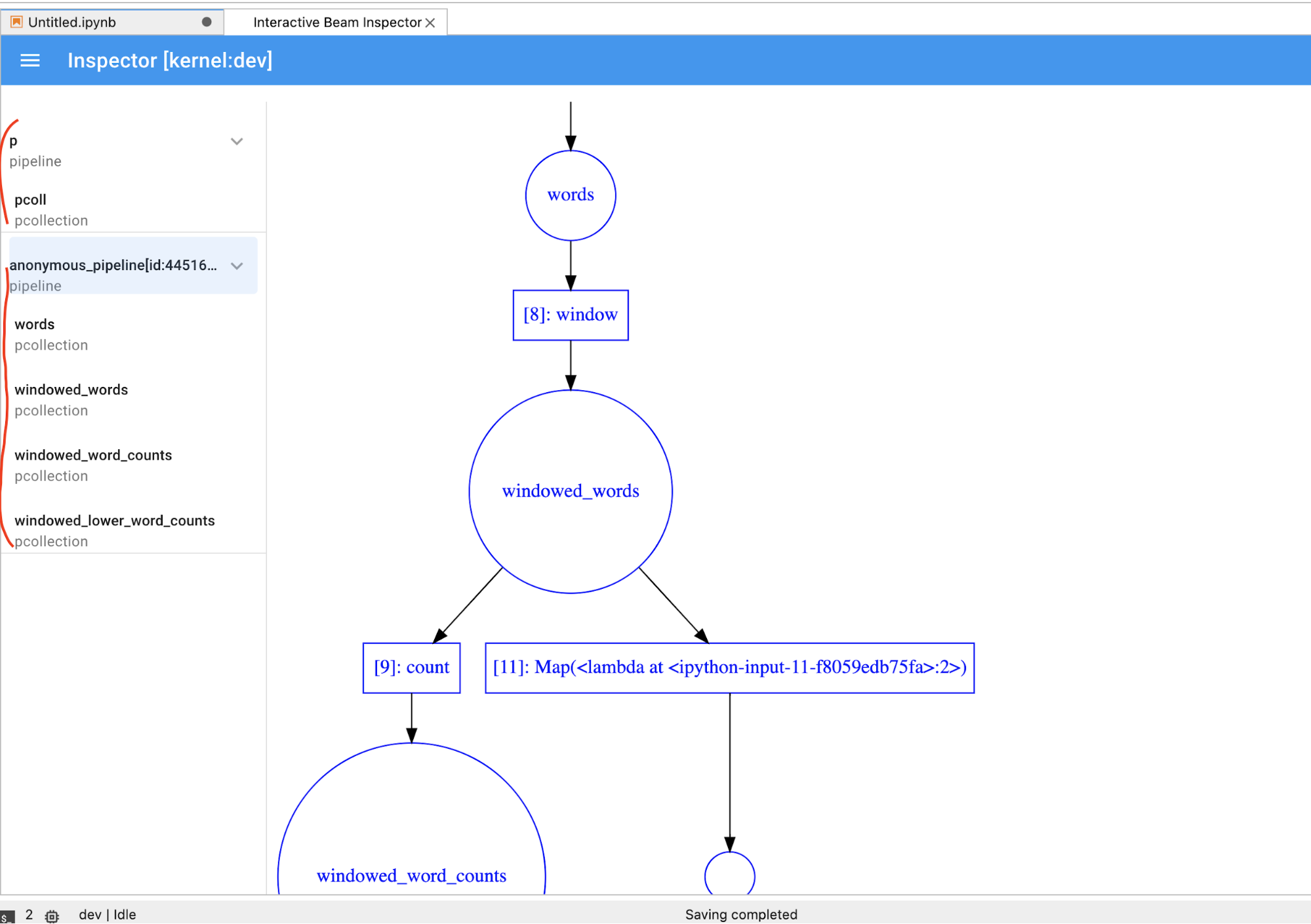
- Dimensioni totali (in byte) di tutte le registrazioni per la pipeline sul disco
- Ora di inizio del job di registrazione in background (in secondi a partire dal tempo Unix)
- Stato attuale della pipeline del job di registrazione in background
- Variabile Python per la pipeline
- (Facoltativo) Prima di utilizzare il notebook per eseguire i job Dataflow, riavvia il kernel, esegui di nuovo tutte le celle e verifica l'output. Se salti questo passaggio, gli stati nascosti nel blocco note potrebbero influire sul grafico dei job nell'oggetto pipeline.
- Attiva l'API Dataflow.
Aggiungi la seguente istruzione di importazione:
from apache_beam.runners import DataflowRunnerInserisci le opzioni della pipeline.
# Set up Apache Beam pipeline options. options = pipeline_options.PipelineOptions() # Set the project to the default project in your current Google Cloud # environment. _, options.view_as(GoogleCloudOptions).project = google.auth.default() # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://<change me>/dataflow' # Set the staging location. This location is used to stage the # Dataflow pipeline and SDK binary. options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location # Set the temporary location. This location is used to store temporary files # or intermediate results before outputting to the sink. options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location # If and only if you are using Apache Beam SDK built from source code, set # the SDK location. This is used by Dataflow to locate the SDK # needed to run the pipeline. options.view_as(pipeline_options.SetupOptions).sdk_location = ( '/root/apache-beam-custom/packages/beam/sdks/python/dist/apache-beam-%s0.tar.gz' % beam.version.__version__)Puoi modificare i valori dei parametri. Ad esempio, puoi modificare il valore di
regiondaus-central1.Esegui la pipeline con
DataflowRunner. Questo passaggio esegue il job sul servizio Dataflow.runner = DataflowRunner() runner.run_pipeline(p, options=options)pè un oggetto pipeline di Creazione della pipeline.Crea o collega un Persistent Disk. Segui le istruzioni per utilizzare
sshper connetterti alla VM dell'istanza notebook ed emettere comandi nella Cloud Shell aperta.Prendi nota della directory in cui è montato il Persistent Disk, ad esempio
/mnt/myDisk.Modifica i dettagli della VM dell'istanza notebook per aggiungere una voce a
Custom metadata: chiave -container-custom-params; valore --v /mnt/myDisk:/mnt/myDisk.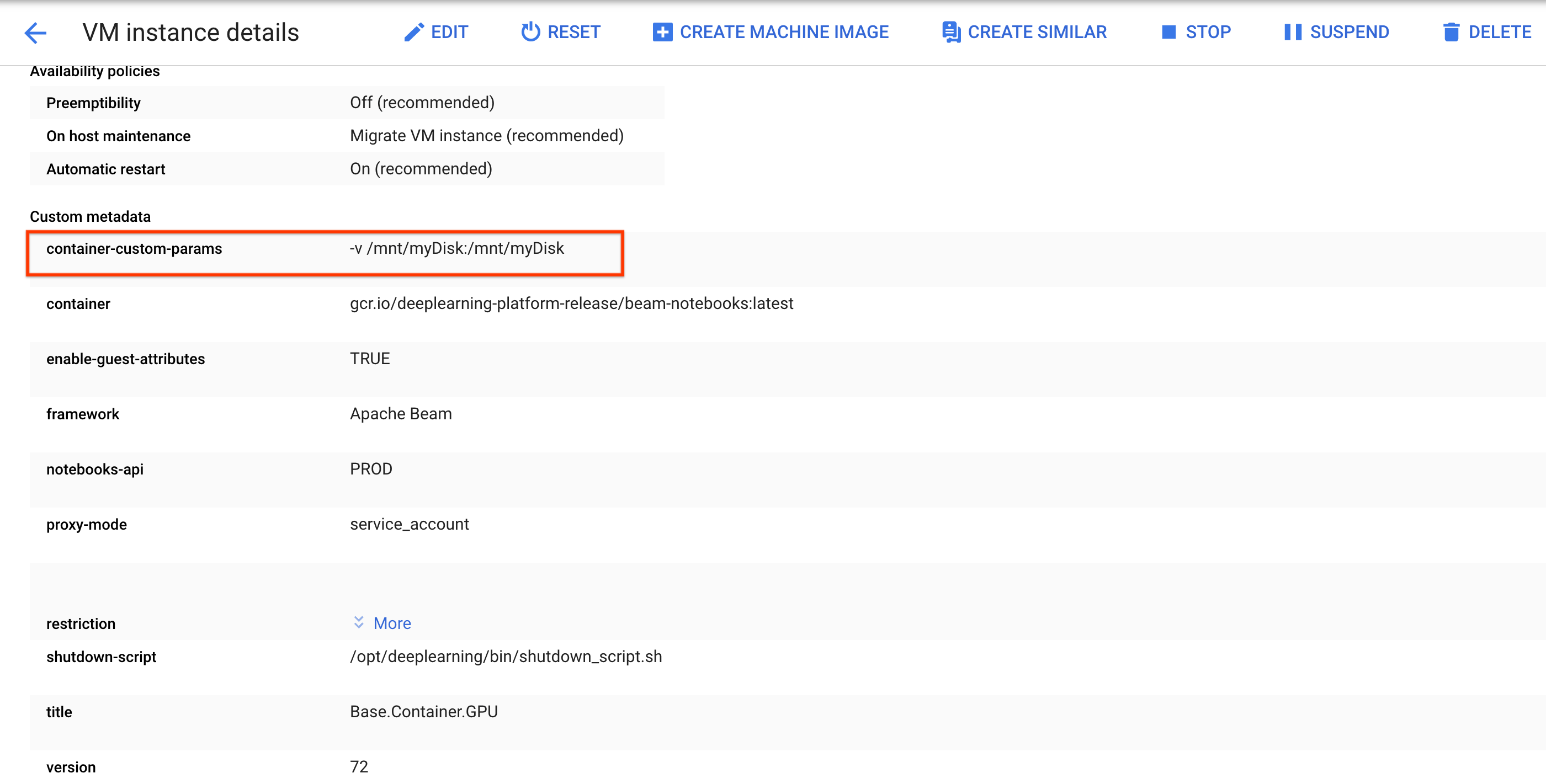
Fai clic su Salva.
Per aggiornare queste modifiche, reimposta l'istanza del blocco note.
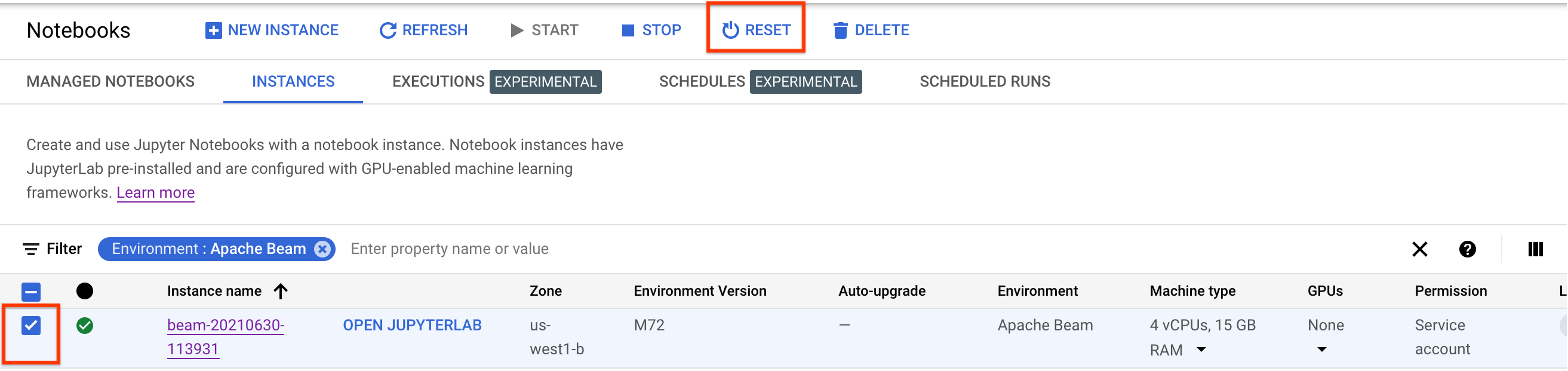
Dopo il ripristino, fai clic su Apri JupyterLab. Potrebbe essere necessario del tempo prima che la UI JupyterLab diventi disponibile. Dopo la visualizzazione dell'interfaccia utente, apri un terminale ed esegui questo comando:
ls -al /mntDovrebbe essere elencata la directory/mnt/myDisk.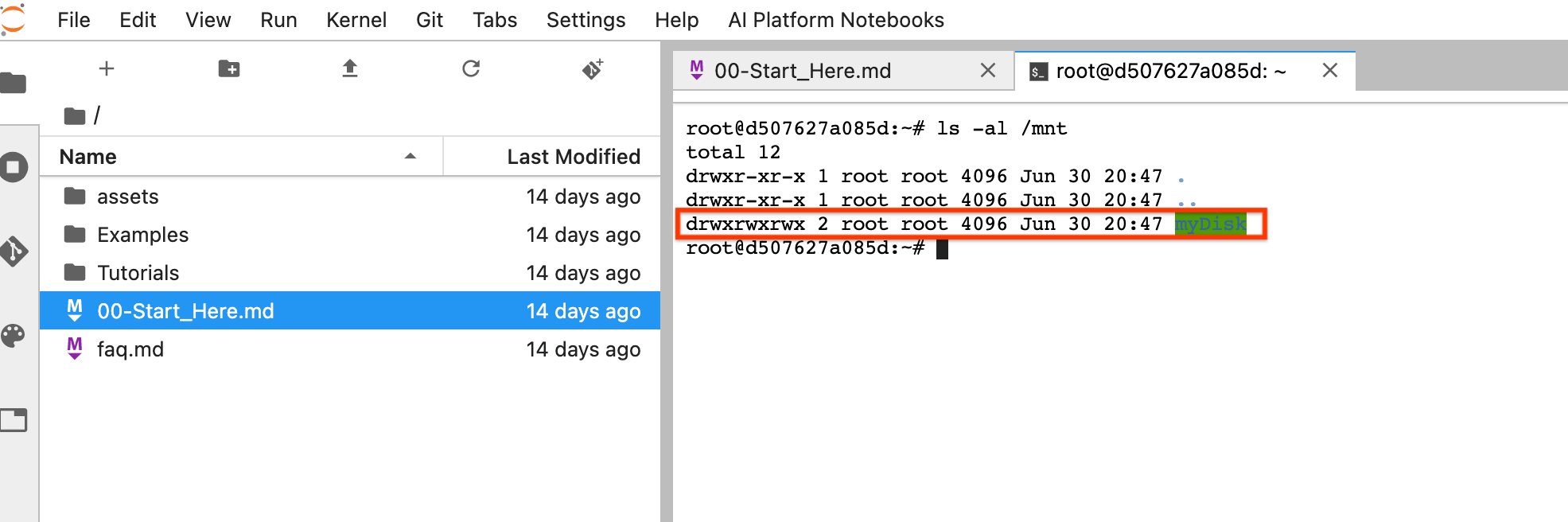
- Scopri le funzionalità avanzate che puoi utilizzare con i notebook Apache Beam. Le funzionalità avanzate includono i seguenti flussi di lavoro:
Prima di creare l'istanza del notebook Apache Beam, attiva API aggiuntive per le pipeline che utilizzano altri servizi, come Pub/Sub.
Se non viene specificato, l'istanza notebook viene eseguita dal service account Compute Engine predefinito con il ruolo Editor progetto IAM. Se il progetto limita esplicitamente i ruoli del account di servizio, assicurati che disponga comunque di autorizzazioni sufficienti per eseguire i notebook. Ad esempio, la lettura da un argomento Pub/Sub crea implicitamente una sottoscrizione e il tuo service account ha bisogno di un ruolo IAM Editor Pub/Sub. Al contrario, la lettura da una sottoscrizione Pub/Sub richiede solo un ruolo IAM Sottoscrittore Pub/Sub.
Al termine di questa guida, per evitare l'addebito di ulteriori costi, elimina le risorse create. Per maggiori dettagli, vedi Pulizia.
Avvia un'istanza notebook Apache Beam
(Facoltativo) Installa le dipendenze
I notebook Apache Beam sono già dotati di Apache Beam e delle dipendenze del connettoreGoogle Cloud installate. Se la pipeline contiene
connettori personalizzati o PTransforms personalizzati che dipendono da librerie di terze parti,
installali dopo aver creato un'istanza notebook.
Notebook Apache Beam di esempio
Dopo aver creato un'istanza di notebook, aprila in JupyterLab. Nella scheda File della barra laterale di JupyterLab, la cartella Esempi contiene blocchi note di esempio. Per ulteriori informazioni sull'utilizzo dei file JupyterLab, consulta la sezione Utilizzo dei file nella guida dell'utente di JupyterLab.
Sono disponibili i seguenti notebook:
La cartella Tutorial contiene tutorial aggiuntivi che spiegano i principi fondamentali di Apache Beam. Sono disponibili i seguenti tutorial:
Questi blocchi note includono testo esplicativo e blocchi di codice commentati per aiutarti a comprendere i concetti di Apache Beam e l'utilizzo dell'API. I tutorial forniscono anche esercizi per mettere in pratica i concetti.
Le sezioni seguenti utilizzano il codice di esempio del blocco note Streaming Word Count. Gli snippet di codice in questa guida e quelli presenti nel notebook Conteggio parole in streaming potrebbero presentare piccole discrepanze.
Crea un'istanza di notebook
Vai a File > Nuovo > Blocco note e seleziona un kernel Apache Beam 2.22 o versioni successive.
I blocchi note Apache Beam sono creati in base al ramo master dell'SDK Apache Beam. Ciò significa che l'ultima versione del kernel mostrata nell'interfaccia utente dei notebook potrebbe essere più recente dell'ultima versione rilasciata dell'SDK.
Apache Beam è installato nell'istanza notebook, quindi includi i moduli interactive_runner e interactive_beam nel notebook.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
Se il notebook utilizza altre API di Google, aggiungi le seguenti istruzioni di importazione:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
Impostare le opzioni di interattività
La riga seguente imposta il periodo di tempo durante il quale InteractiveRunner registra i dati da un'origine senza limiti. In questo esempio, la durata è impostata su 10 minuti.
ib.options.recording_duration = '10m'
Puoi anche modificare il limite di dimensioni di registrazione (in byte) per una sorgente senza limiti
utilizzando la proprietà recording_size_limit.
# Set the recording size limit to 1 GB.
ib.options.recording_size_limit = 1e9
Per altre opzioni interattive, consulta la classe interactive_beam.options.
Crea la tua pipeline
Inizializza la pipeline utilizzando un oggetto InteractiveRunner.
options = pipeline_options.PipelineOptions(flags={})
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Set the project to the default project in your current Google Cloud Platform environment.
# The project is used to create a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
p = beam.Pipeline(InteractiveRunner(), options=options)
Leggere e visualizzare i dati
L'esempio seguente mostra una pipeline Apache Beam che crea una sottoscrizione all'argomento Pub/Sub specificato e legge i dati dalla sottoscrizione.
words = p | "read" >> beam.io.ReadFromPubSub(topic="projects/pubsub-public-data/topics/shakespeare-kinglear")
La pipeline conta le parole per finestra dall'origine. Crea finestre fisse di 10 secondi ciascuna.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
Dopo la suddivisione in finestre dei dati, le parole vengono conteggiate per finestra.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
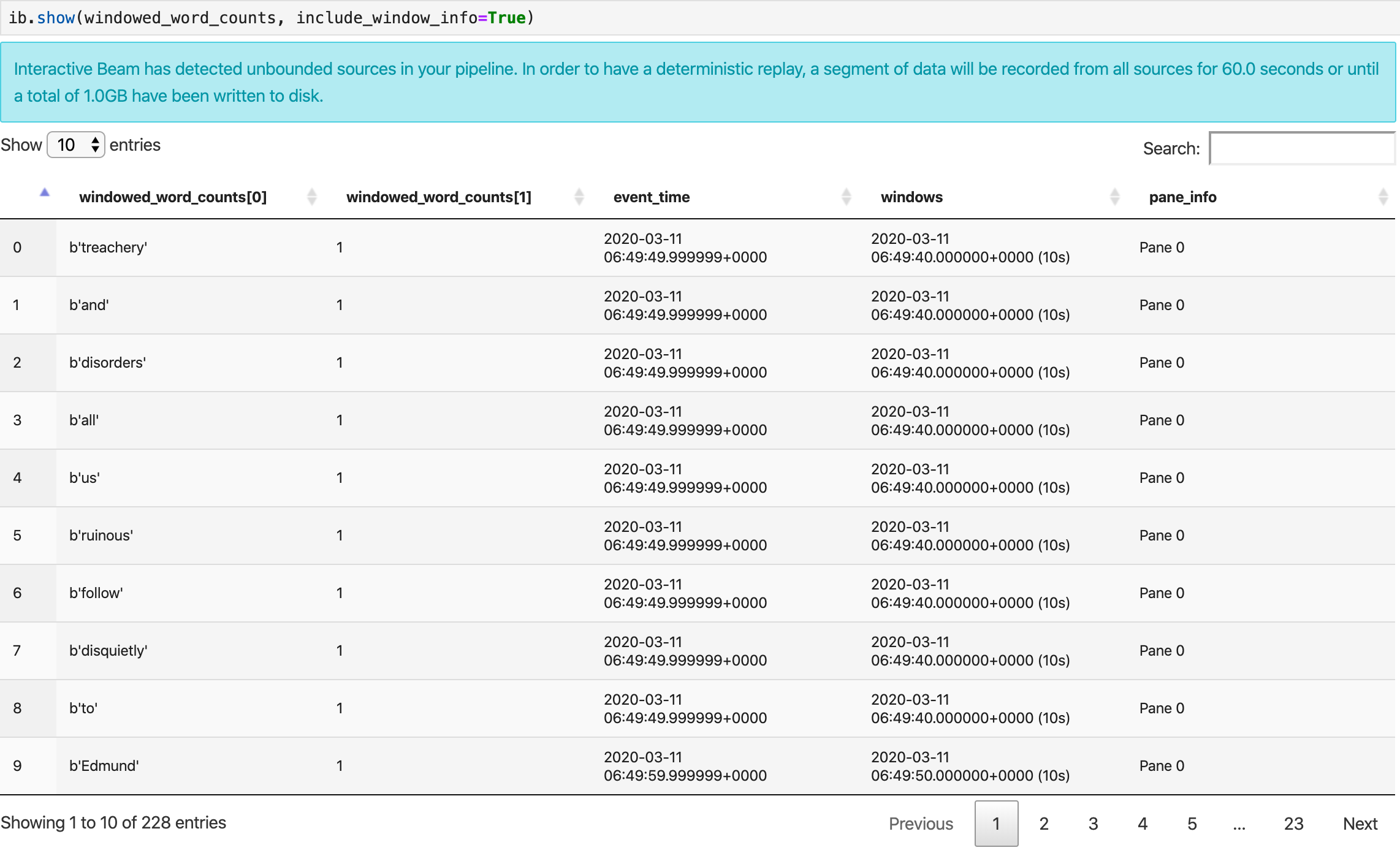
Il metodo show() visualizza il PCollection risultante nel notebook.
ib.show(windowed_word_counts, include_window_info=True)
Puoi limitare il set di risultati a partire da show() impostando due parametri
facoltativi: n e duration.
Se vengono impostati entrambi i parametri facoltativi, show() si interrompe quando viene raggiunta una delle due soglie. Nell'esempio seguente, show() restituisce al massimo 20 elementi calcolati in base ai dati dei primi 30 secondi delle fonti registrate.
ib.show(windowed_word_counts, include_window_info=True, n=20, duration=30)
Per visualizzare le visualizzazioni dei tuoi dati, passa visualize_data=True al metodo show(). Puoi applicare più filtri alle visualizzazioni. La
visualizzazione seguente consente di filtrare per etichetta e asse:
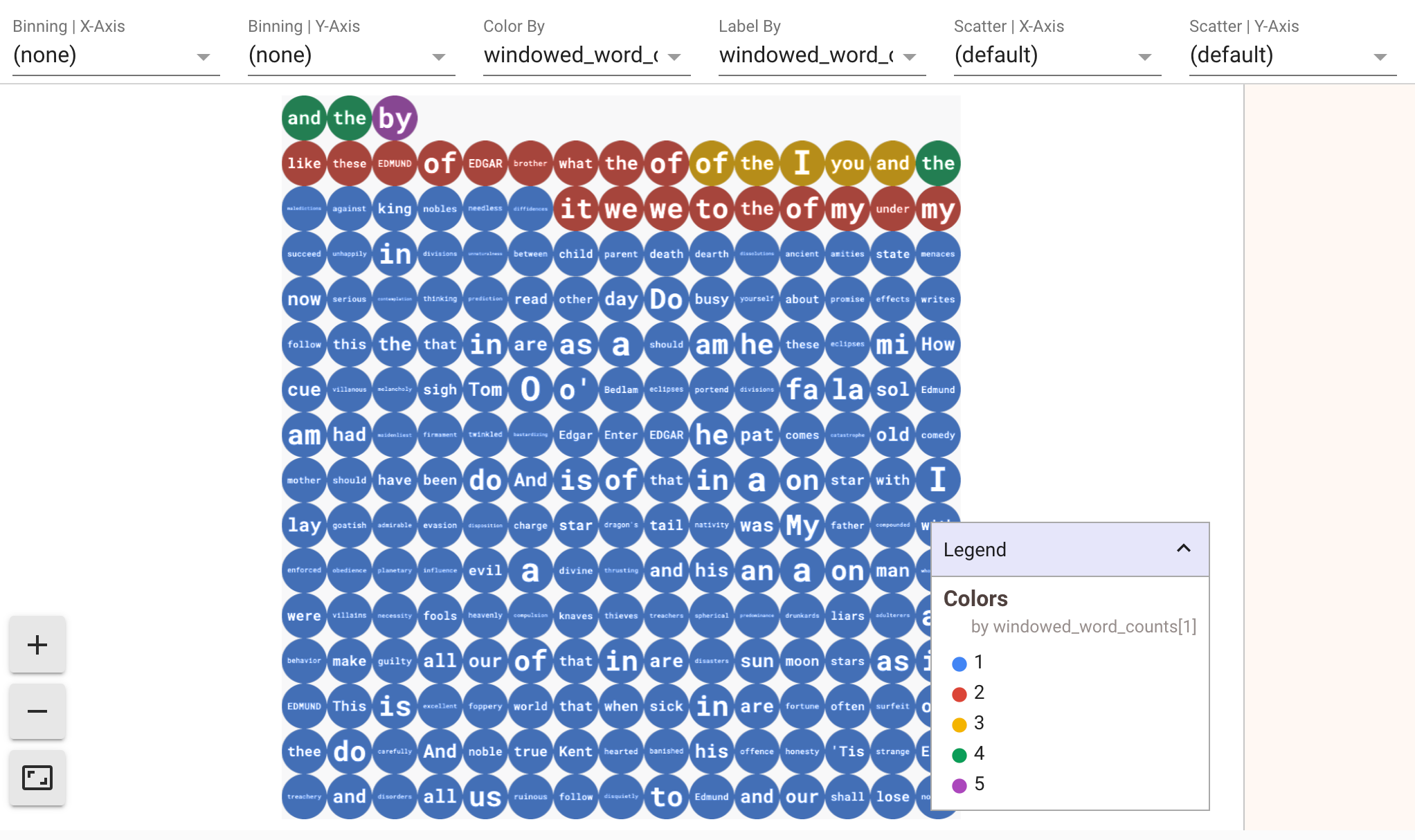
Per garantire la riproducibilità durante la prototipazione delle pipeline di streaming, le chiamate al metodo show() riutilizzano i dati acquisiti per impostazione predefinita. Per modificare questo
comportamento e fare in modo che il metodo show() recuperi sempre nuovi dati, imposta
interactive_beam.options.enable_capture_replay = False. Inoltre, se aggiungi una seconda origine senza limiti al notebook, i dati dell'origine senza limiti precedente vengono eliminati.
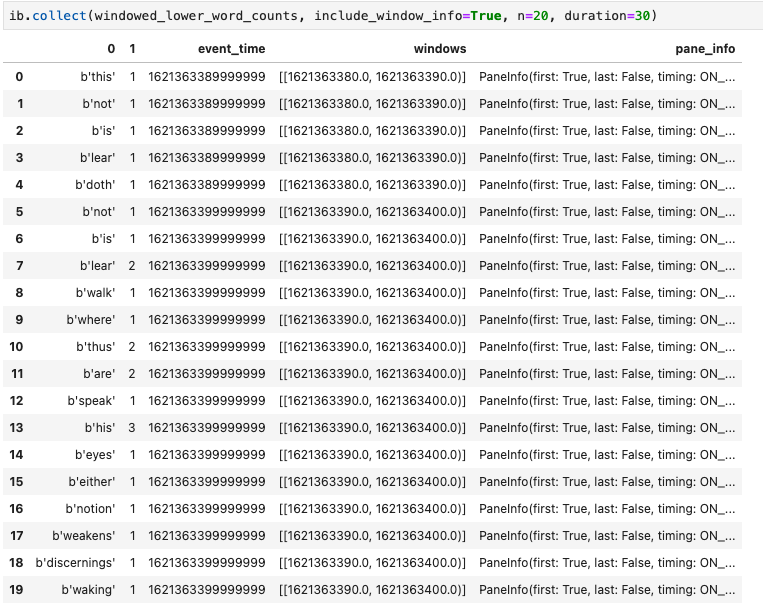
Un'altra visualizzazione utile nei blocchi note Apache Beam è un DataFrame Pandas. L'esempio seguente converte prima le parole in minuscolo e poi calcola la frequenza di ogni parola.
windowed_lower_word_counts = (windowed_words
| beam.Map(lambda word: word.lower())
| "count" >> beam.combiners.Count.PerElement())
Il metodo collect() fornisce l'output in un DataFrame Pandas.
ib.collect(windowed_lower_word_counts, include_window_info=True)
La modifica e la riesecuzione di una cella è una pratica comune nello sviluppo di notebook. Quando modifichi ed esegui nuovamente una cella in un notebook Apache Beam,
la cella non annulla l'azione prevista del codice nella cella originale. Ad esempio, se una cella aggiunge un PTransform a una pipeline, la riesecuzione della cella aggiunge un ulteriore PTransform alla pipeline. Se vuoi cancellare lo stato,
riavvia il kernel e poi esegui di nuovo le celle.
Visualizza i dati tramite lo strumento di controllo Interactive Beam
Potresti trovare distraente l'introspezione dei dati di un PCollection chiamando costantemente show() e collect(), soprattutto quando l'output occupa gran parte dello spazio sullo schermo e rende difficile la navigazione nel notebook. Potresti anche voler confrontare più PCollections affiancati per
verificare se una trasformazione funziona come previsto. Ad esempio, quando una PCollection
viene trasformata e produce l'altra. Per questi casi d'uso, lo
strumento di controllo interattivo Beam è una soluzione pratica.
Interactive Beam inspector viene fornito come estensione JupyterLab
apache-beam-jupyterlab-sidepanel
preinstallata nel notebook Apache Beam. Con l'estensione,
puoi esaminare in modo interattivo lo stato delle pipeline e dei dati associati a
ogni PCollection senza richiamare esplicitamente show() o collect().
Esistono tre modi per aprire lo strumento di ispezione:
Quando lo strumento di controllo sta per aprirsi:
Ti consigliamo di aprire almeno un notebook e selezionare un kernel prima di aprire lo strumento di ispezione. Se apri un inspector con un kernel prima di aprire qualsiasi notebook, in un secondo momento, quando apri un notebook per connetterti all'inspector, devi selezionare Interactive Beam Inspector Session da Use
Kernel from Preferred Session. Un ispettore e un blocco note sono collegati quando
condividono la stessa sessione, non sessioni diverse create dallo stesso
kernel. Selezionando lo stesso kernel da Start Preferred Kernel viene creata una
nuova sessione indipendente dalle sessioni esistenti di notebook o
ispettori aperti.
Puoi aprire più ispettori per un blocco note aperto e disporli trascinando le schede liberamente nell'area di lavoro.
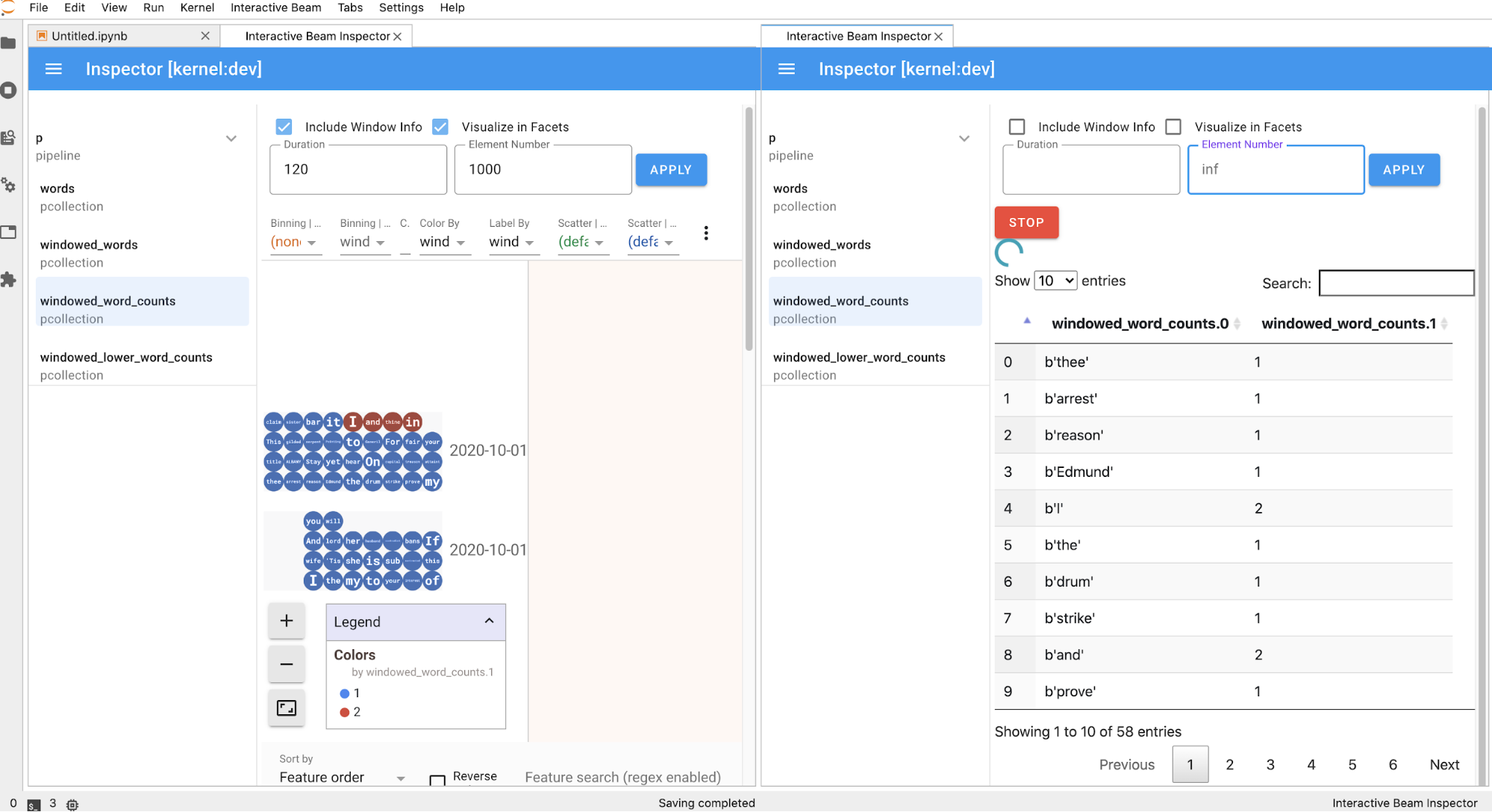
La pagina dell'ispettore si aggiorna automaticamente quando esegui le celle nel
notebook. La pagina elenca le pipeline e PCollections definiti nel
notebook collegato. PCollections sono organizzati in base alle pipeline a cui appartengono e puoi comprimerli facendo clic sull'intestazione della pipeline.
Per gli elementi negli elenchi delle pipeline e PCollections, al clic, l'inspector
visualizza le visualizzazioni corrispondenti sul lato destro:
Potresti notare pipeline anonime. Queste pipeline hanno
PCollections a cui puoi accedere, ma non vengono più referenziate dalla sessione principale. Ad esempio:
p = beam.Pipeline()
pcoll = p | beam.Create([1, 2, 3])
p = beam.Pipeline()
L'esempio precedente crea una pipeline vuota p e una pipeline anonima che
contiene un PCollection pcoll. Puoi accedere alla pipeline anonima
utilizzando pcoll.pipeline.
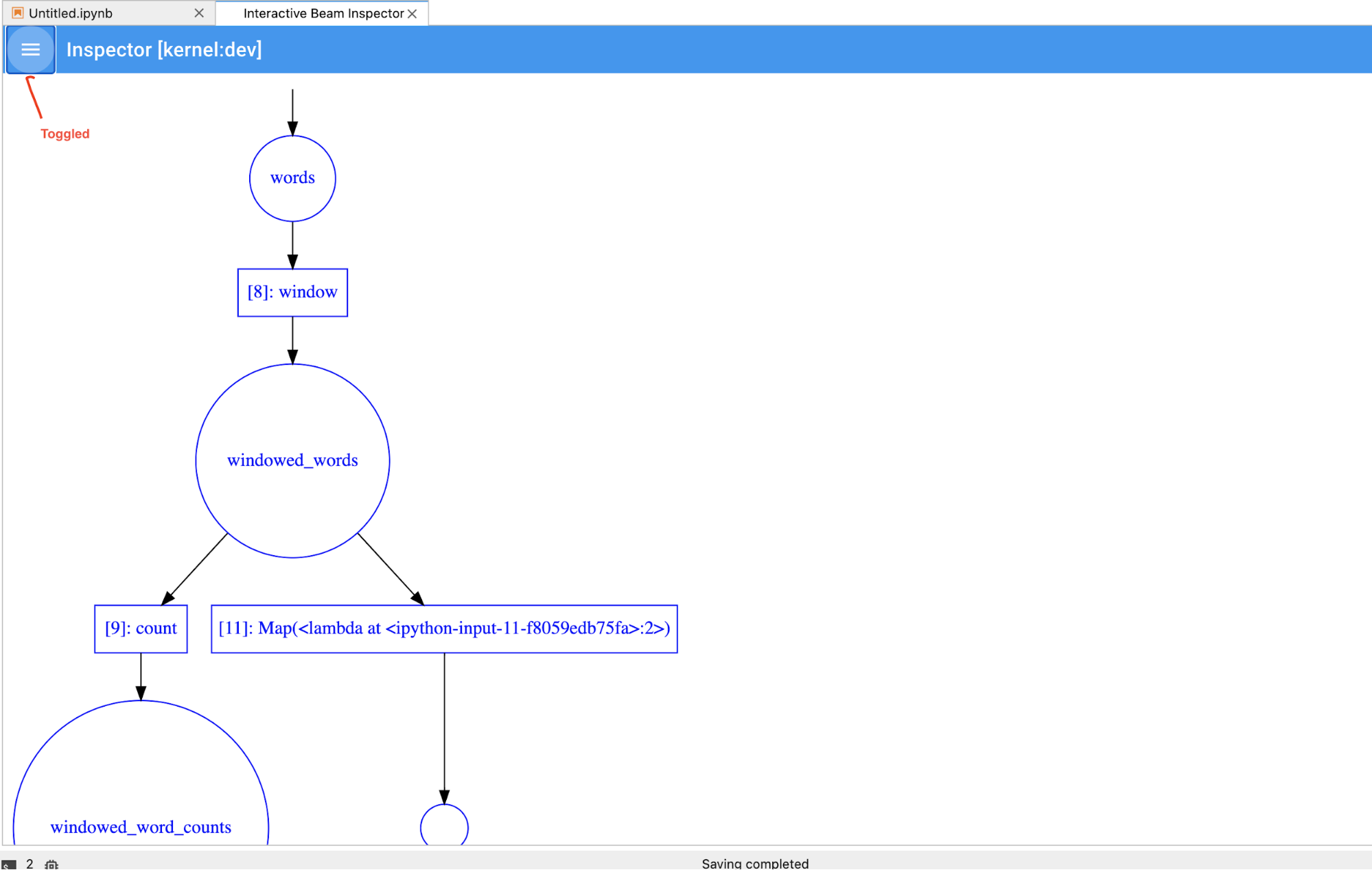
Puoi attivare/disattivare la pipeline e l'elenco PCollection per risparmiare spazio per
visualizzazioni di grandi dimensioni.
Informazioni sullo stato di registrazione di una pipeline
Oltre alle visualizzazioni, puoi anche controllare lo stato di registrazione di una o tutte le pipeline nell'istanza del notebook chiamando describe.
# Return the recording status of a specific pipeline. Leave the parameter list empty to return
# the recording status of all pipelines.
ib.recordings.describe(p)
Il metodo describe() fornisce i seguenti dettagli:
Avviare i job Dataflow da una pipeline creata nel notebook
Per un esempio di come eseguire questa conversione in un notebook interattivo, consulta il notebook Dataflow Word Count nell'istanza del notebook.
In alternativa, puoi esportare il notebook come script eseguibile, modificare il file .py generato seguendo i passaggi precedenti e poi implementare la pipeline nel servizio Dataflow.
Salvare il notebook
Notebooks che crei vengono salvati localmente nell'istanza del notebook in esecuzione. Se reimposti o arresti l'istanza del notebook durante lo sviluppo, i nuovi notebook vengono mantenuti se vengono creati nella directory /home/jupyter.
Tuttavia, se un'istanza di blocco note viene eliminata, vengono eliminati anche i relativi blocchi note.
Per conservare i notebook per un utilizzo futuro, scaricali localmente sulla tua workstation, salvali su GitHub o esportali in un formato file diverso.
Salvare il notebook su dischi permanenti aggiuntivi
Se vuoi conservare il tuo lavoro, come notebook e script, in varie istanze di notebook, archiviali in Persistent Disk.
Ora puoi salvare il tuo lavoro nella directory /mnt/myDisk. Anche se l'istanza del blocco note viene eliminata, il Persistent Disk esiste nel tuo progetto. Dopodiché potrai collegare questo Persistent Disk ad altre istanze notebook.