Usa el ejecutor interactivo de Apache Beam con notebooks de JupyterLab para completar las siguientes tareas:
- Desarrollar canalizaciones de forma iterativa.
- Inspeccionar el grafo de la canalización.
- Analizar
PCollectionsindividual en un flujo de trabajo de bucle de lectura, evaluación e impresión (REPL).
Estos notebooks de Apache Beam están disponibles a través de Notebooks administrados por el usuario de Vertex AI Workbench, un servicio que aloja máquinas virtuales de notebooks preinstaladas con la ciencia de datos más reciente y marcos de trabajo de aprendizaje automático. Dataflow solo admite instancias de notebooks administrados por el usuario.
En esta guía, nos enfocamos en las funciones que presentan los notebooks de Apache Beam, pero no se muestra cómo compilar un notebook. Para obtener más información sobre Apache Beam, consulta la Guía de programación de Apache Beam.
Asistencia y limitaciones
- Los notebooks de Apache Beam solo son compatibles con Python.
- Los segmentos de canalización de Apache Beam que se ejecutan en estos notebooks se ejecutan en un entorno de prueba y no en un ejecutor de producción de Apache Beam. Para iniciar los notebooks en el servicio de Dataflow, exporta las canalizaciones creadas en el notebook de Apache Beam. Para obtener más detalles, consulta Inicia trabajos de Dataflow a partir de una canalización creada en tu notebook.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Antes de crear la instancia de notebook de Apache Beam, habilita las APIs adicionales para canalizaciones que usan otros servicios, como Pub/Sub.
Si no se especifica, la instancia de notebook se ejecuta mediante la cuenta de servicio predeterminada de Compute Engine con la función de editor de proyecto de IAM. Si el proyecto limita de forma explícita las funciones de la cuenta de servicio, asegúrate de que tenga suficiente autorización para ejecutar los notebooks. Por ejemplo, leer un tema de Pub/Sub crea una suscripción de forma implícita y tu cuenta de servicio necesita una función de editor de Pub/Sub de IAM. En cambio, leer de una suscripción de Pub/Sub solo requiere un rol de suscriptor de Pub/Sub de IAM.
Cuando termines esta guía, borra los recursos que creaste para evitar que se sigan facturando. Para obtener más información, consulta Realiza una limpieza.
Inicia una instancia de notebook de Apache Beam
En la consola de Google Cloud, ve a la página Workbench de Dataflow.
Asegúrate de estar en la pestaña Notebooks administrados por el usuario.
En la barra de herramientas, haz clic en Crear nueva.
En la sección Entorno, en Entorno, selecciona Apache Beam.
Si deseas ejecutar notebooks en una GPU, en la sección Tipo de máquina, selecciona un tipo de máquina que admita GPU y, luego, selecciona Instalar automáticamente el controlador de GPU de NVIDIA. Para obtener más información, consulta Plataformas de GPU.
En la sección Herramientas de redes, selecciona una subred para la VM del notebook.
Opcional: Si deseas configurar una instancia de notebook personalizada, consulta Crea una instancia de notebook administrada por el usuario con propiedades específicas.
Haz clic en Crear. Dataflow Workbench crea una instancia nueva de notebook de Apache Beam.
Después de crear la instancia de notebook, se activa el vínculo Abrir JupyterLab. Haga clic en Abrir JupyterLab.
Opcional: Instala dependencias
Los notebooks de Apache Beam ya tienen instaladas las dependencias de conector de Apache Beam y Google Cloud. Si la canalización contiene
conectores personalizados o PTransforms personalizados que dependen de bibliotecas de terceros,
instálalos después de crear una instancia de notebook. Para obtener más información, consulta Instala dependencias en la documentación de notebooks administrados por el usuario.
Ejemplos de notebooks de Apache Beam
Después de crear una instancia de notebook administrada por el usuario, ábrela en JupyterLab. En la pestaña Archivos en la barra lateral de JupyterLab, la carpeta Ejemplos contiene notebooks de ejemplo. Para obtener más información sobre cómo trabajar con archivos de JupyterLab, consulta Trabaja con archivos en la guía del usuario de JupyterLab.
Los siguientes notebooks están disponibles:
- Conteo de palabras
- Transmisión del conteo de palabras
- Transmisión de datos de viajes en taxi en la ciudad de Nueva York
- SQL de Apache Beam en notebooks con comparaciones a canalizaciones
- SQL de Apache Beam en notebooks con ejecutor de Dataflow
- SQL de Apache Beam en notebooks
- Conteo de palabras de Dataflow
- Flink interactivo a gran escala
- RunInference
- Usa GPU con Apache Beam
- Visualizar datos
La carpeta Instructivos contiene instructivos adicionales que explican los aspectos básicos de Apache Beam. Los siguientes instructivos están disponibles:
- Operaciones básicas
- Operaciones en términos de elementos
- Datos recopilados
- Windows
- Operaciones de E/S
- Transmisión
- Ejercicios finales
En estos notebooks, se incluye texto explicativo y bloques de código comentados para que puedas comprender los conceptos de Apache Beam y el uso de la API. Los instructivos también proporcionan ejercicios en los que practicarás los conceptos aprendidos.
En las siguientes secciones, se usa el código de ejemplo del notebook Conteo de palabras de transmisión. Los fragmentos de código de esta guía y lo que se encuentra en el notebook Conteo de palabras de transmisión pueden tener pequeñas discrepancias.
Crea una instancia de notebook
Navega hacia Archivo > Nuevo > Notebook y selecciona un kernel que sea Apache Beam 2.22 o una versión posterior.
Nota: Los notebooks de Apache Beam se compilan con la rama principal del SDK de Apache Beam. Esto implica que la versión más reciente del kernel que se muestra en la IU de los notebooks puede ser más actual que la versión de actualización más reciente del SDK.
Apache Beam está instalado en tu instancia de notebook, así que incluye los módulos interactive_runner y interactive_beam en el notebook.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
Si el notebook usa otras API de Google, agrega las siguientes instrucciones de importación:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
Configura opciones de interactividad
En la siguiente línea, se establece la cantidad de tiempo que InteractiveRunner registra los datos de una fuente ilimitada. En este ejemplo, la duración se establece en 10 minutos.
ib.options.recording_duration = '10m'
También puedes cambiar el límite de registro (en bytes) para una fuente ilimitada
con la propiedad recording_size_limit.
# Set the recording size limit to 1 GB.
ib.options.recording_size_limit = 1e9
Para descubrir más opciones interactivas, consulta la clase interactive_beam.options.
Cree su canalización.
Inicializa la canalización mediante un objeto InteractiveRunner.
options = pipeline_options.PipelineOptions(flags={})
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Set the project to the default project in your current Google Cloud environment.
# The project is used to create a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
p = beam.Pipeline(InteractiveRunner(), options=options)
Lee y visualiza los datos
En el siguiente ejemplo, se muestra una canalización de Apache Beam que crea una suscripción al tema de Pub/Sub determinado y realiza operaciones de lectura desde la suscripción.
words = p | "read" >> beam.io.ReadFromPubSub(topic="projects/pubsub-public-data/topics/shakespeare-kinglear")
La canalización cuenta las palabras por ventanas desde la fuente. Crea un sistema de ventanas fijo de 10 segundos de duración por ventana.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
Una vez que los datos se organizaron en ventanas, las palabras se cuentan por ventana.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
Con el método show(), se visualiza la PCollection resultante en el notebook.
ib.show(windowed_word_counts, include_window_info=True)
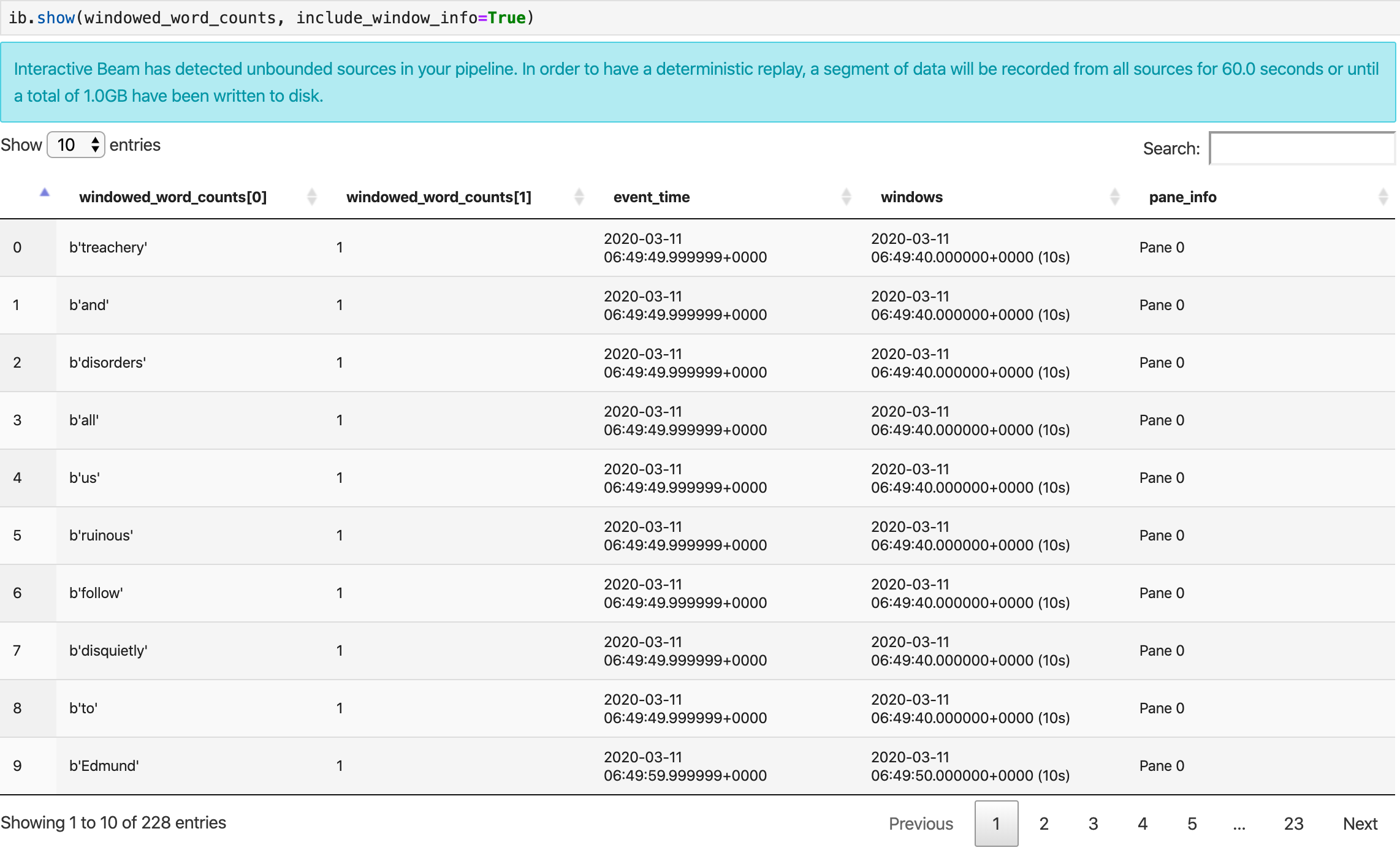
Puedes solicitar el permiso del conjunto de resultados desde show(), mediante la configuración de dos parámetros opcionales: n y duration.
- Establece
npara limitar el conjunto de resultados a fin de mostrar como máximoncantidad de elementos, alrededor de 20. Si no se establecen, el comportamiento predeterminado consiste en enumerar los elementos más recientes que se capturaron hasta que la grabación de origen finalizó. - Establece
durationpara limitar el conjunto de resultados a un número específico de segundos válidos de datos desde el comienzo de la grabación de la fuente. Si no se estableceduration, el comportamiento predeterminado consiste en enumerar todos los elementos hasta que finalice la grabación.
Si se configuran ambos parámetros opcionales, show() se detiene cuando se cumple cualquiera de los límites. En el siguiente ejemplo, show() muestra como máximo 20 elementos que se calculan en función de los primeros 30 segundos de datos de las fuentes registradas.
ib.show(windowed_word_counts, include_window_info=True, n=20, duration=30)
Para mostrar visualizaciones de los datos, pasa visualize_data=True al método show(). Puedes aplicar varios filtros a las visualizaciones. La siguiente visualización te permite filtrar por etiqueta y eje:
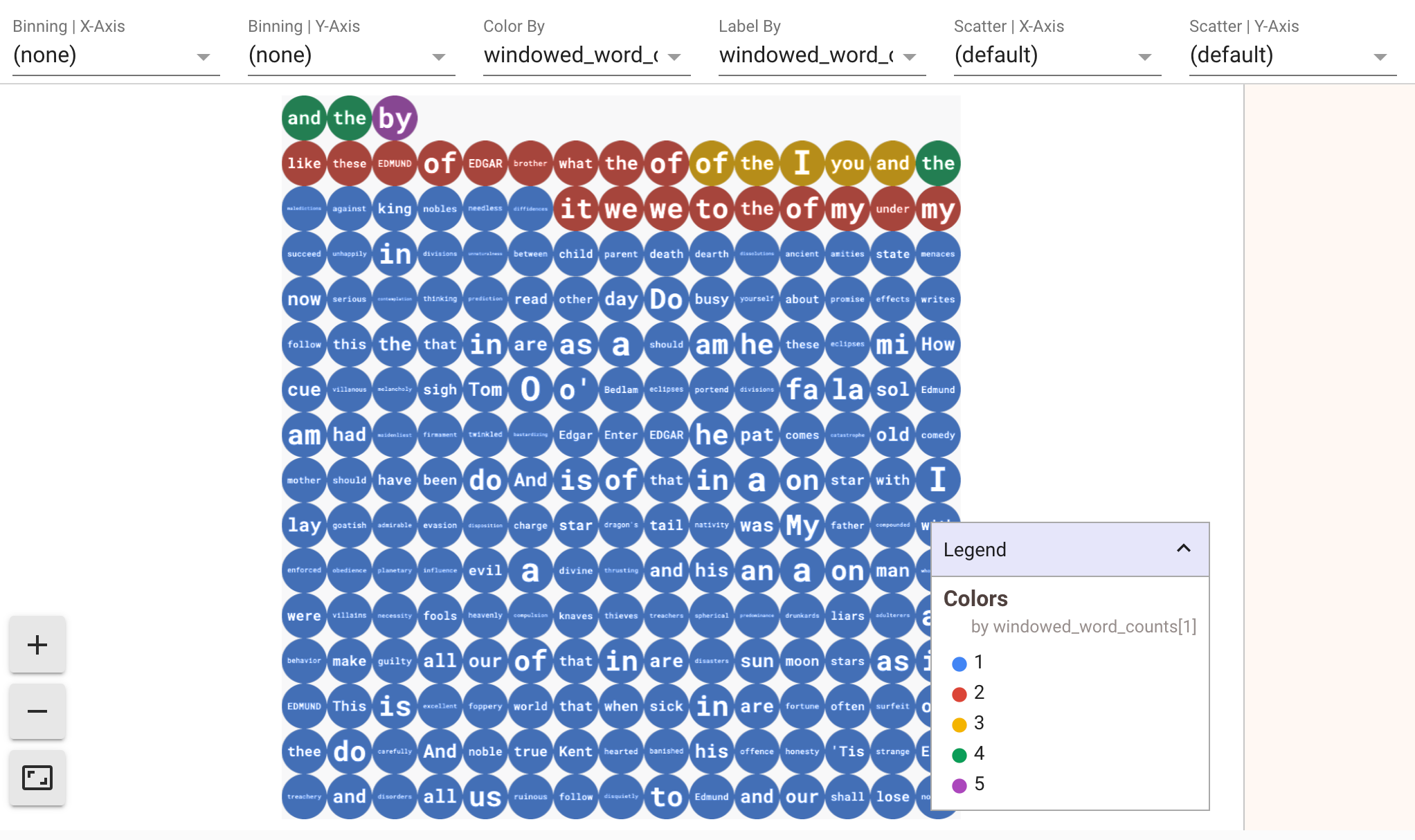
A fin de garantizar la capacidad de volver a reproducir mientras se prototipan las canalizaciones de transmisión, el método show() realiza una llamada para reutilizar los datos capturados de forma predeterminada. Para cambiar este
comportamiento y hacer que el método show() siempre recupere datos nuevos, configura
interactive_beam.options.enable_capture_replay = False. Además, si agregas una segunda fuente ilimitada al notebook, se descartarán los datos de la fuente ilimitada anterior.
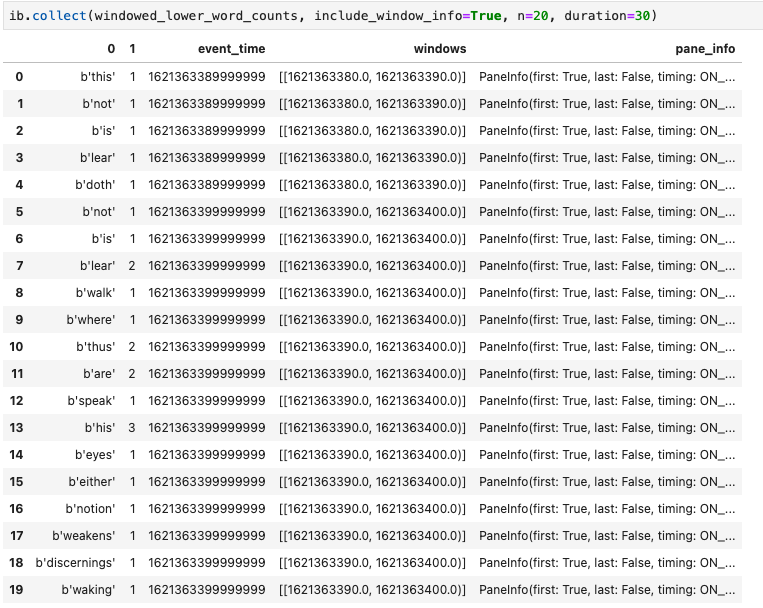
Otra visualización útil en los notebooks de Apache Beam es un DataFrame de Pandas. En el siguiente ejemplo, primero se convierten las palabras en minúsculas y, luego, se calcula la frecuencia de cada palabra.
windowed_lower_word_counts = (windowed_words
| beam.Map(lambda word: word.lower())
| "count" >> beam.combiners.Count.PerElement())
El método collect() proporciona el resultado en un DataFrame de Pandas.
ib.collect(windowed_lower_word_counts, include_window_info=True)
Editar y volver a ejecutar una celda es una práctica usual en el
desarrollo de notebooks. Cuando editas y vuelves a ejecutar una celda en un notebook de Apache Beam, la celda no deshace la acción prevista del código en la celda original. Por
ejemplo, si una celda agrega un PTransform a una canalización, volver a ejecutar esa celda
agrega un PTransform adicional a la canalización. Si deseas borrar el estado, reinicia el kernel y vuelve a ejecutar las celdas.
Visualiza los datos a través del inspector interactivo de Beam
Es posible que te distraiga la introspección de los datos de una PCollection mediante una llamada constante a show() y collect(), en especial cuando el resultado ocupa una gran parte del espacio en tu pantalla y dificulta navegar por el notebook. También puedes comparar varios PCollections en paralelo
para validar si una transformación funciona según lo previsto. Por ejemplo, cuando una PCollection
pasa por una transformación y produce la otra. Para estos casos de uso, el inspector interactivo de Beam es una solución conveniente.
El inspector interactivo de Beam se proporciona como una extensión de JupyterLab apache-beam-jupyterlab-sidepanel preinstalada en el notebook de Apache Beam. Con la extensión, puedes inspeccionar de forma interactiva el estado de las canalizaciones y los datos asociados con cada PCollection sin invocar de forma explícita show() o collect().
Existen 3 formas de abrir el inspector:
Haz clic en
Interactive Beamen la barra de menú superior de JupyterLab. En el menú desplegable, buscaOpen Inspectory haz clic en él para abrir el inspector.
Usa la página del selector. Si no hay una página de lanzamiento abierta, haz clic en
File->New Launcherpara abrirla. En la página del selector, buscaInteractive Beamy haz clic enOpen Inspectorpara abrir el inspector.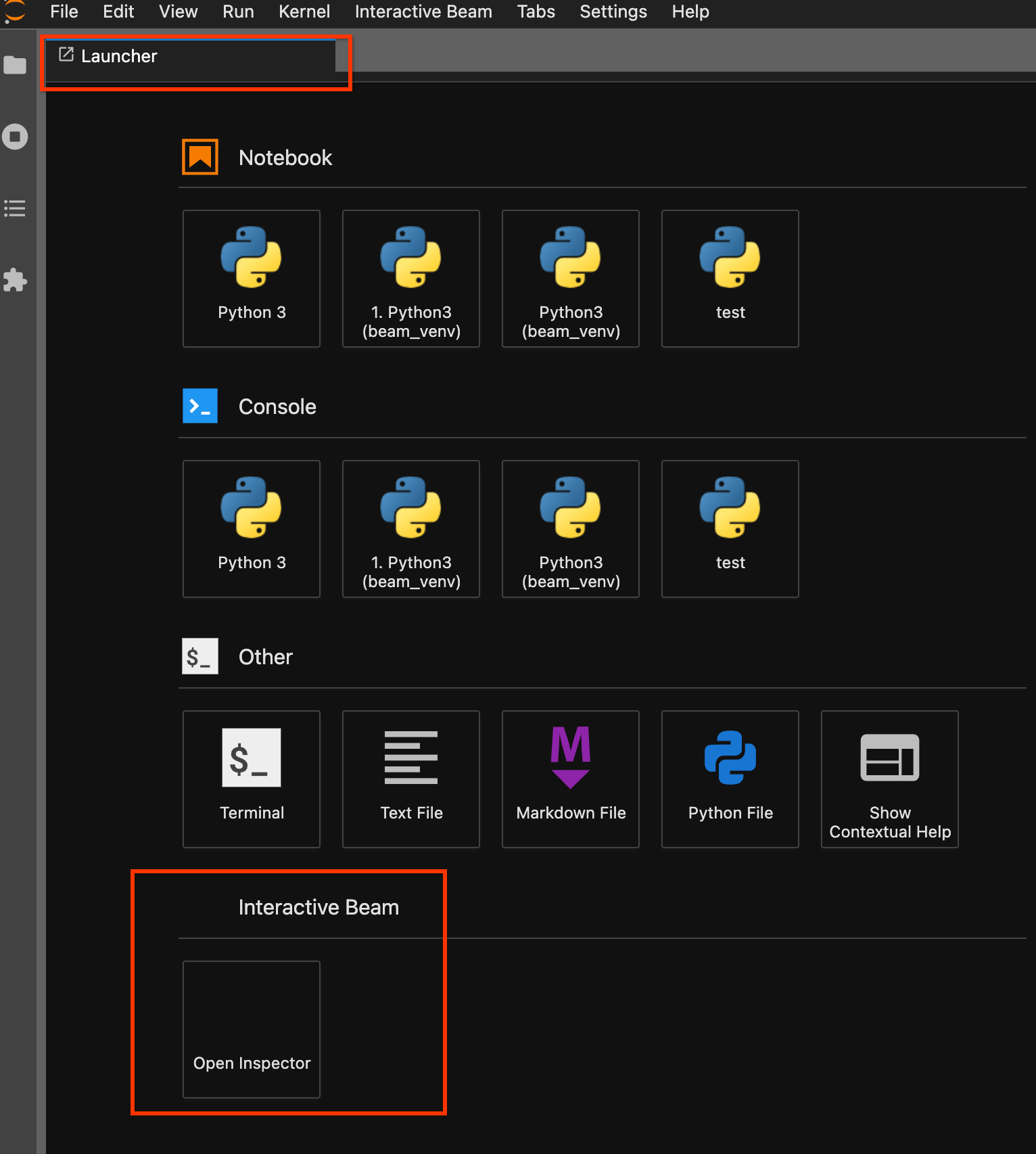
Usa la paleta de comandos. En la barra de menú de JupyterLab, haz clic en
View>Activate Command Palette. En el cuadro de diálogo, buscaInteractive Beampara enumerar todas las opciones de la extensión. Haz clic enOpen Inspectorpara abrir el inspector.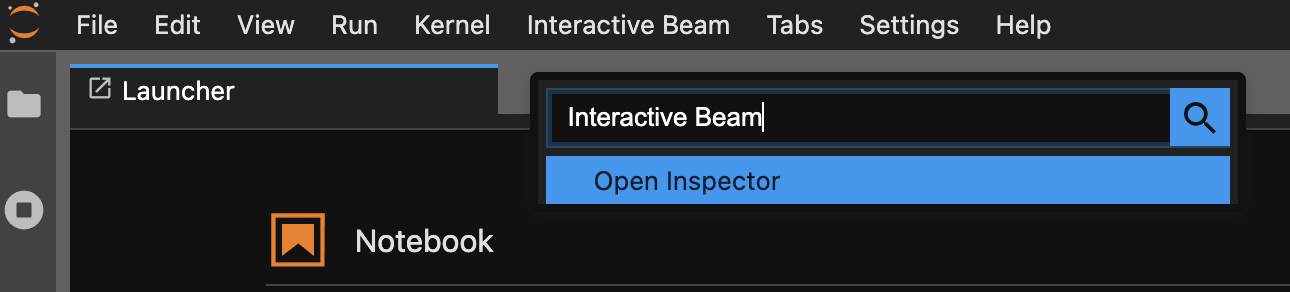
Cuando el inspector está a punto de abrirse, haz lo siguiente:
Si hay exactamente un notebook abierto, el inspector se conectará automáticamente a él.
Si no hay ningún notebook abierto, aparecerá un cuadro de diálogo que te permitirá seleccionar un kernel.
Si hay varios notebooks abiertos, aparecerá un cuadro de diálogo que te permitirá seleccionar la sesión del notebook.
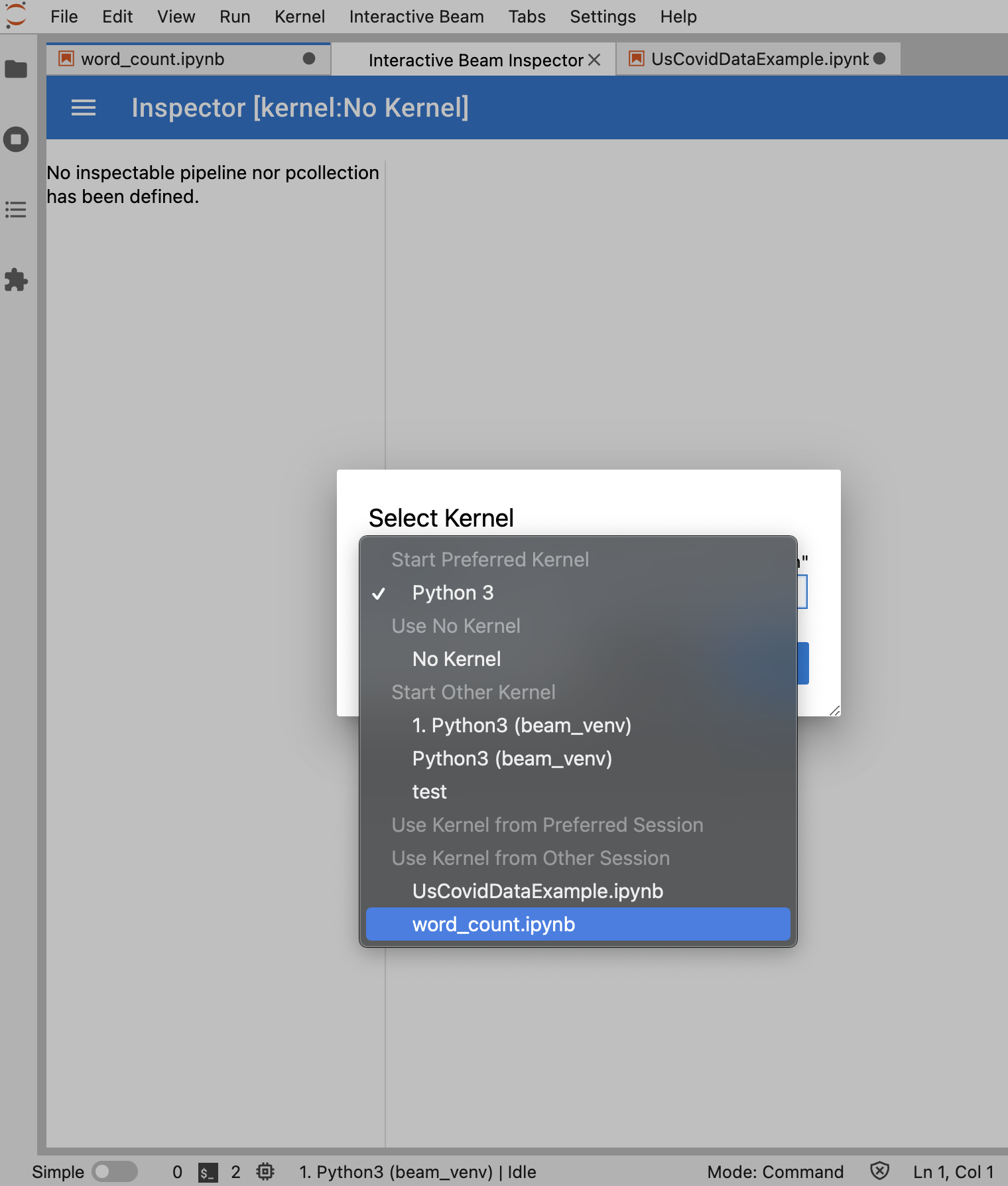
Se recomienda abrir, al menos, un notebook y seleccionar un kernel para él antes de abrir el inspector. Si abres un inspección con un kernel antes de abrir cualquier notebook, más adelante cuando abras un notebook para conectarte al inspector, deberás seleccionar Interactive Beam Inspector Session de Use
Kernel from Preferred Session. Un inspección y un notebook se conectan cuando comparten la misma sesión, no cuando hay diferentes sesiones creadas desde el mismo kernel. Si seleccionas el mismo kernel desde Start Preferred Kernel, se creará una sesión nueva que es independiente de las sesiones existentes de inspecciones o notebooks abiertos.
Puedes abrir varios inspecciones para un notebook abierto y organizar los inspecciones si arrastras y sueltas sus pestañas libremente en el lugar de trabajo.
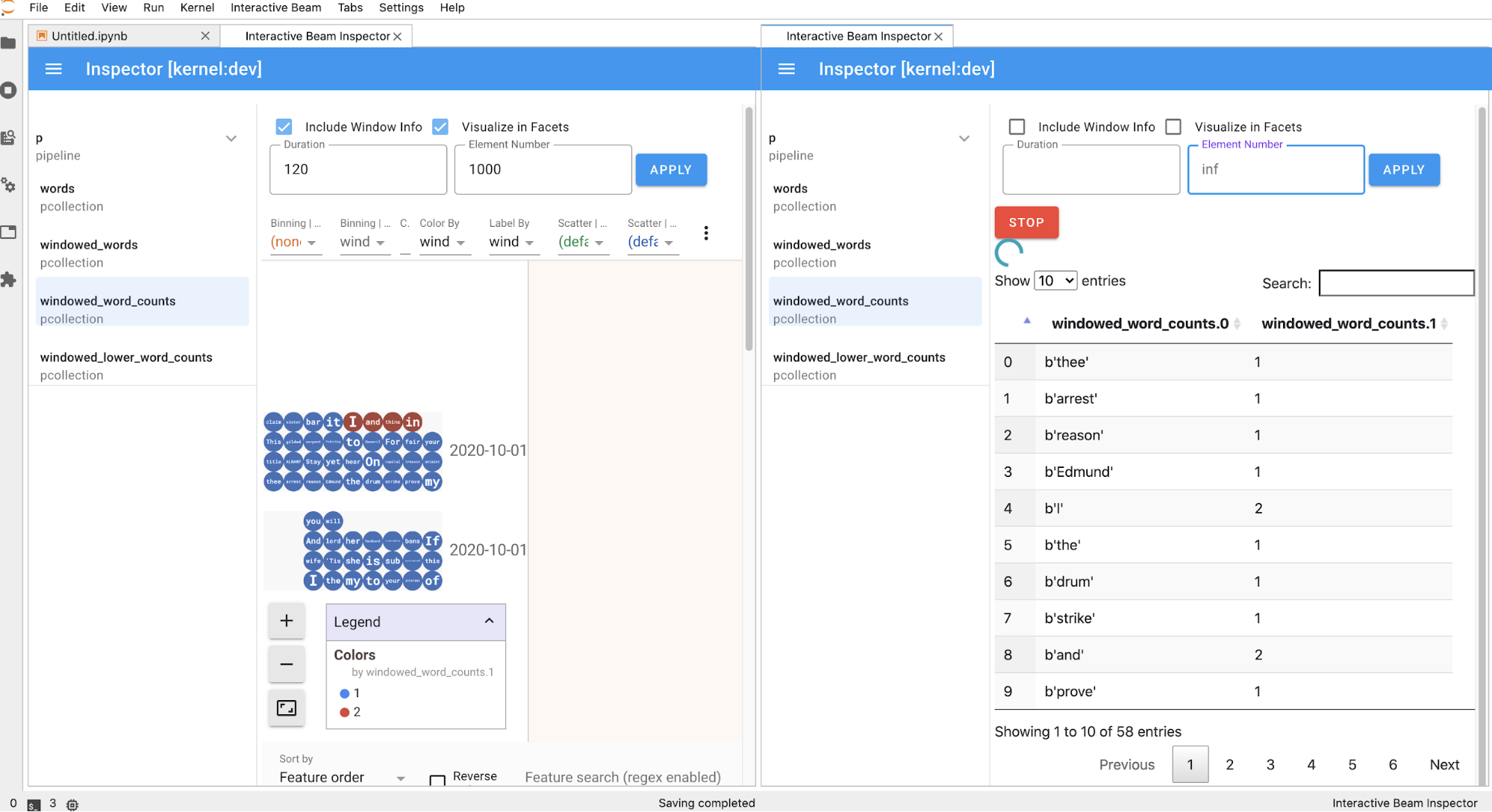
La página del inspector se actualiza de forma automática cuando ejecutas celdas en el
notebook. En la página, se enumeran las canalizaciones y los PCollections definidos en el
notebook conectado. Las PCollections se organizan según las canalizaciones a las que pertenecen.
Para contraerlas, haz clic en la canalización del encabezado.
Para los elementos de las listas de PCollections y canalizaciones, cuando se hace clic, el inspector renderiza las visualizaciones correspondientes en el lado derecho:
Si se trata de una
PCollection, el inspector renderiza sus datos (de forma dinámica si los datos aún ingresan paraPCollectionsno delimitadas) con widgets adicionales para ajustar la visualización después de hacer clic en el botónAPPLY.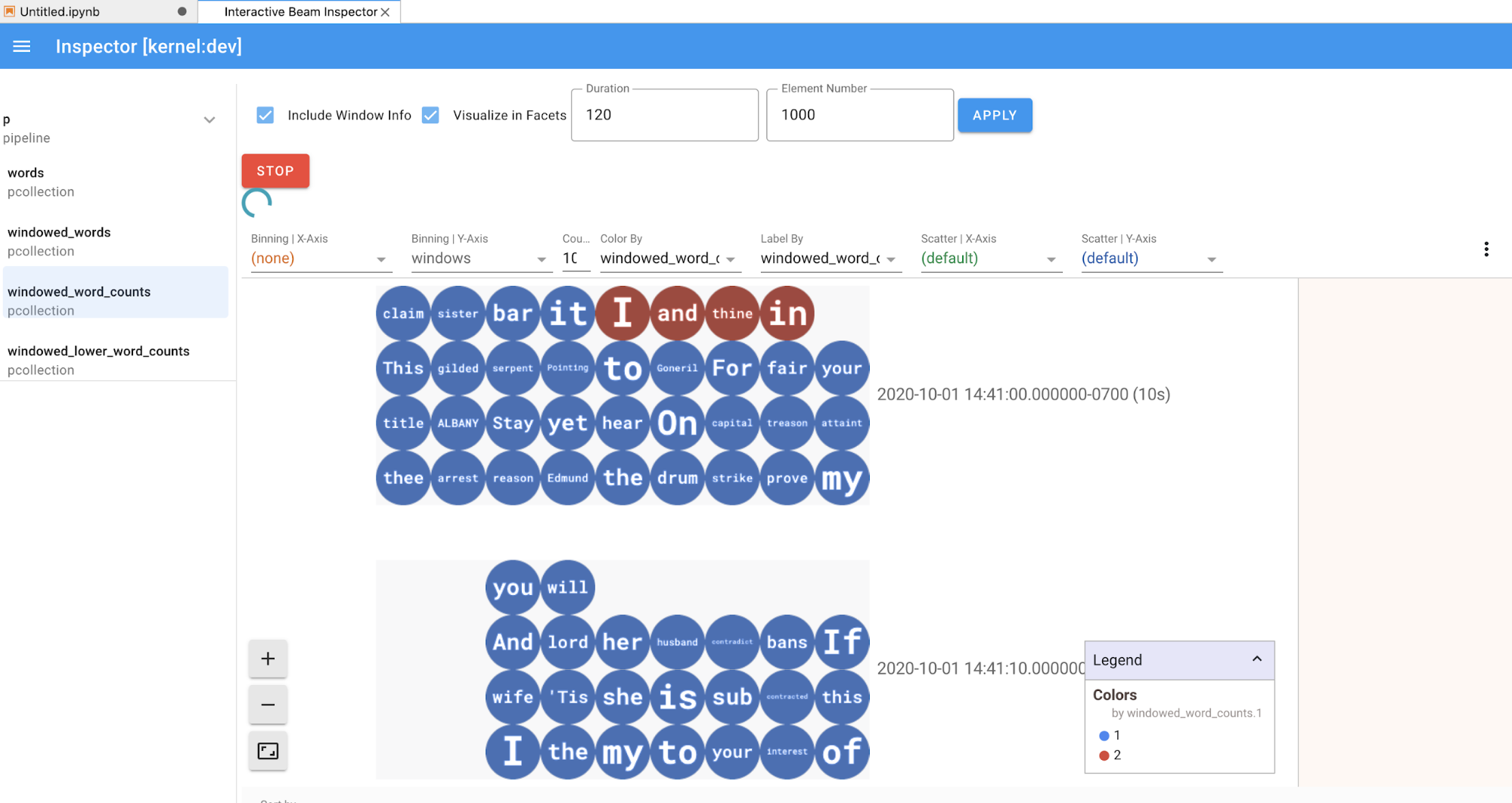
Dado que el inspector y el notebook abierto comparten la misma sesión de kernel, se bloquearán entre sí para evitar que se ejecuten. Por ejemplo, si el notebook está ocupado ejecutando código, el inspector no se actualizará hasta que el notebook complete esa ejecución. Por el contrario, si deseas ejecutar código de inmediato en tu notebook mientras el inspector visualiza una
PCollectionde forma dinámica, debes hacer clic en el botónSTOPpara detener la visualización y liberar el kernel de forma interrumpible al notebook.Si es una canalización, el inspector muestra el grafo de la canalización.
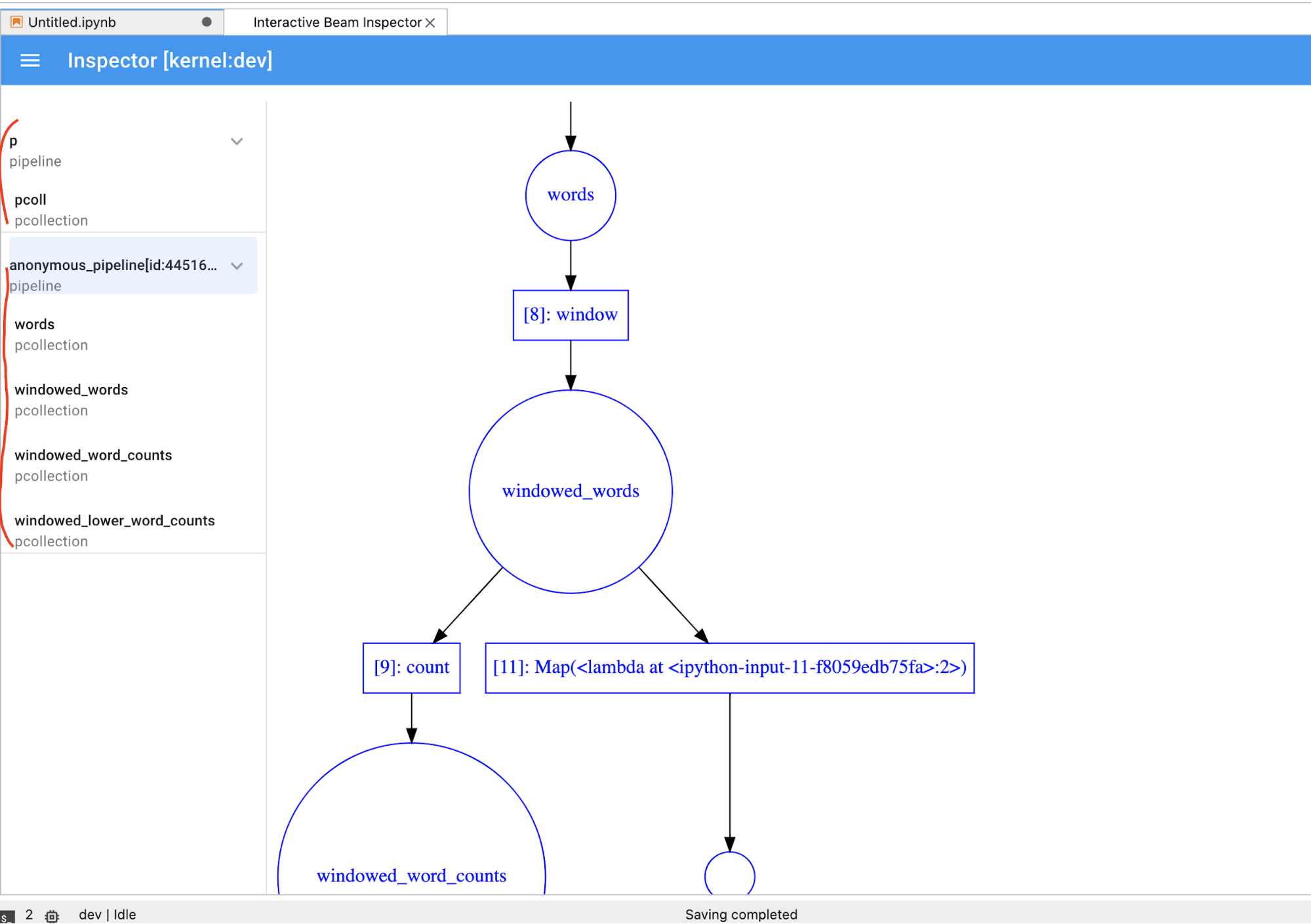
Es posible que notes canalizaciones anónimas. Esas canalizaciones tienen
PCollections a las que puedes acceder, pero la sesión principal
ya no hace referencia a ellas. Por ejemplo:
p = beam.Pipeline()
pcoll = p | beam.Create([1, 2, 3])
p = beam.Pipeline()
En el ejemplo anterior, se crea una canalización vacía p y una canalización anónima que
contiene un pcoll PCollection. Puedes acceder a la canalización anónima
con pcoll.pipeline.
Puedes activar o desactivar la canalización y la lista PCollection para ahorrar espacio para
las visualizaciones grandes.
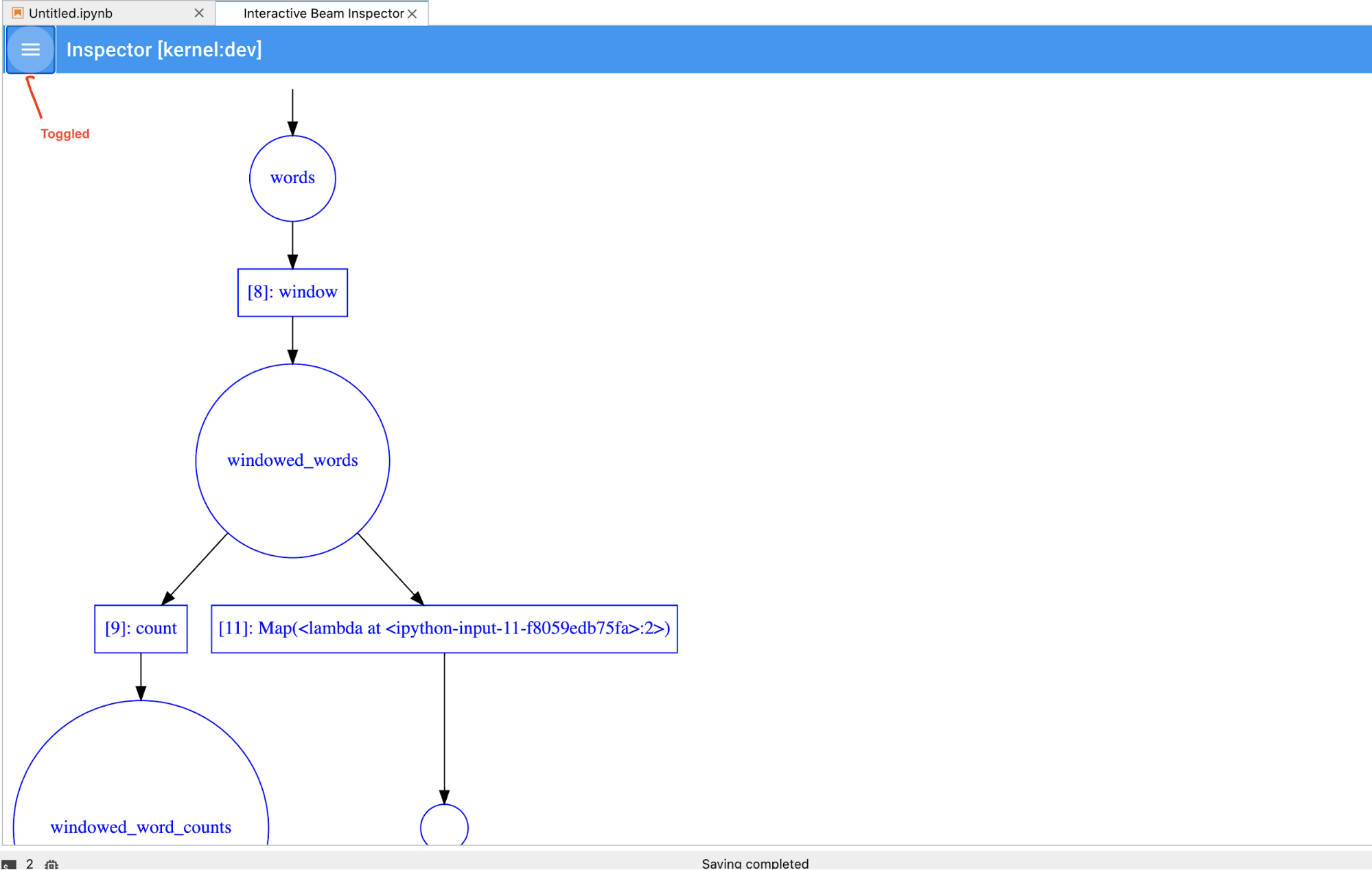
Comprende el estado de registro de una canalización
Además de las visualizaciones, también puedes inspeccionar el estado de registro de una o todas las canalizaciones en tu instancia de notebook mediante una llamada a describe.
# Return the recording status of a specific pipeline. Leave the parameter list empty to return
# the recording status of all pipelines.
ib.recordings.describe(p)
El método describe() proporciona los siguientes detalles:
- Tamaño total (en bytes) de todos los registros de la canalización en el disco
- Hora de inicio del momento en que comenzó el trabajo de registro en segundo plano (en segundos desde el ciclo de entrenamiento de Unix)
- Estado actual de la canalización del trabajo de registro en segundo plano
- Variable de Python para la canalización
Inicia trabajos de Dataflow a partir de una canalización creada en el notebook
- Opcional: Antes de usar el notebook para ejecutar trabajos de Dataflow, reinicia el kernel, vuelve a ejecutar todas las celdas y verifica el resultado (opcional). Si omites este paso, los estados ocultos en el notebook pueden afectar el grafo de trabajo en el objeto de canalización.
- Habilita la API de Dataflow.
Agrega la siguiente instrucción de importación:
from apache_beam.runners import DataflowRunnerPasa las opciones de canalización.
# Set up Apache Beam pipeline options. options = pipeline_options.PipelineOptions() # Set the project to the default project in your current Google Cloud # environment. _, options.view_as(GoogleCloudOptions).project = google.auth.default() # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://<change me>/dataflow' # Set the staging location. This location is used to stage the # Dataflow pipeline and SDK binary. options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location # Set the temporary location. This location is used to store temporary files # or intermediate results before outputting to the sink. options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location # If and only if you are using Apache Beam SDK built from source code, set # the SDK location. This is used by Dataflow to locate the SDK # needed to run the pipeline. options.view_as(pipeline_options.SetupOptions).sdk_location = ( '/root/apache-beam-custom/packages/beam/sdks/python/dist/apache-beam-%s0.tar.gz' % beam.version.__version__)Puedes ajustar los valores de los parámetros. Por ejemplo, puedes cambiar el valor
regiondeus-central1.Ejecuta la canalización con
DataflowRunner. Este paso ejecuta el trabajo en el servicio de Dataflow.runner = DataflowRunner() runner.run_pipeline(p, options=options)pes un objeto de canalización que se describe en Crea la canalización.
Para obtener un ejemplo sobre cómo realizar esta conversión en un notebook interactivo, consulta el notebook Conteo de palabras de Dataflow en la instancia de notebook.
Como alternativa, puedes exportar el notebook como una secuencia de comandos ejecutable, modificar el archivo .py generado mediante los pasos anteriores y, luego, implementar la canalización en el servicio de Dataflow.
Guarda tu notebook
Los notebooks que creas se guardan de forma local en la instancia de notebook en ejecución. Si restableces o cierras la instancia de notebook durante el desarrollo, esos notebooks nuevos se mantienen siempre que se creen en el directorio /home/jupyter.
Sin embargo, si se borra una instancia de notebook, esos notebooks también se borran.
Si quieres conservar los notebooks para usarlos en el futuro, descárgalos de forma local en tu estación de trabajo, guárdalos en GitHub o expórtalos a un formato de archivo diferente.
Guarda el notebook en discos persistentes adicionales
Si quieres mantener tu trabajo como notebooks y secuencias de comandos en varias instancias de notebook, almacénalos en el disco persistente.
Crea o adjunta un disco persistente. Sigue las instrucciones para usar
ssha fin de conectarte a la VM de la instancia de notebook y emitir comandos en el Cloud Shell abierto.Ten en cuenta el directorio en el que se activa el disco persistente, por ejemplo,
/mnt/myDisk.Edita los detalles de la VM de la instancia de notebook para agregar una entrada a
Custom metadata: clave -container-custom-params; valor:-v /mnt/myDisk:/mnt/myDisk.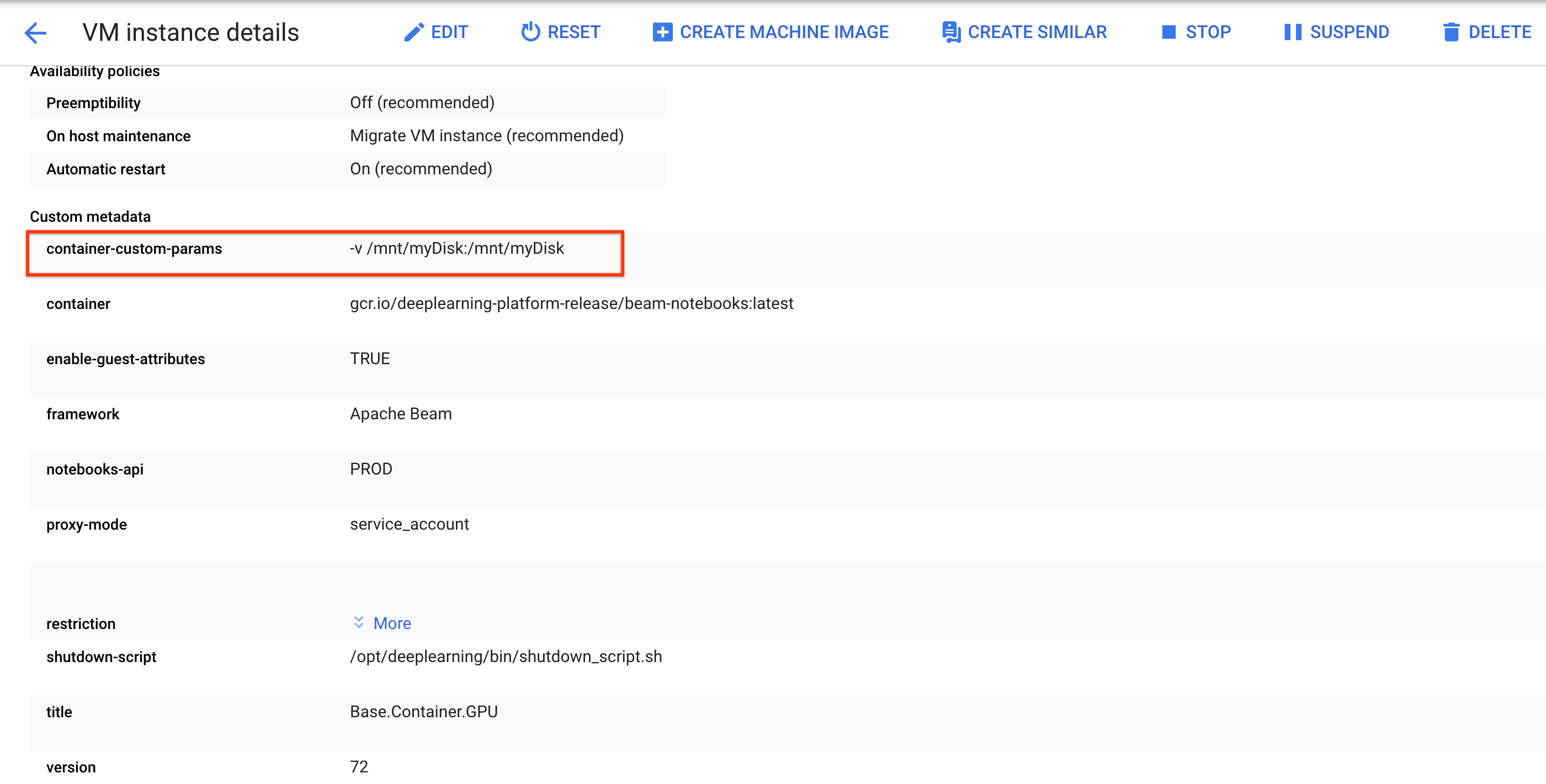
Haz clic en Guardar.
Para actualizar estos cambios, restablece la instancia de notebook.
Después del restablecimiento, haz clic en Abrir JupyterLab. La IU de JupyterLab puede tardar un tiempo en estar disponible. Después de que aparezca la IU, abre una terminal y ejecuta el siguiente comando:
ls -al /mntSe debería enumerar el directorio/mnt/myDisk.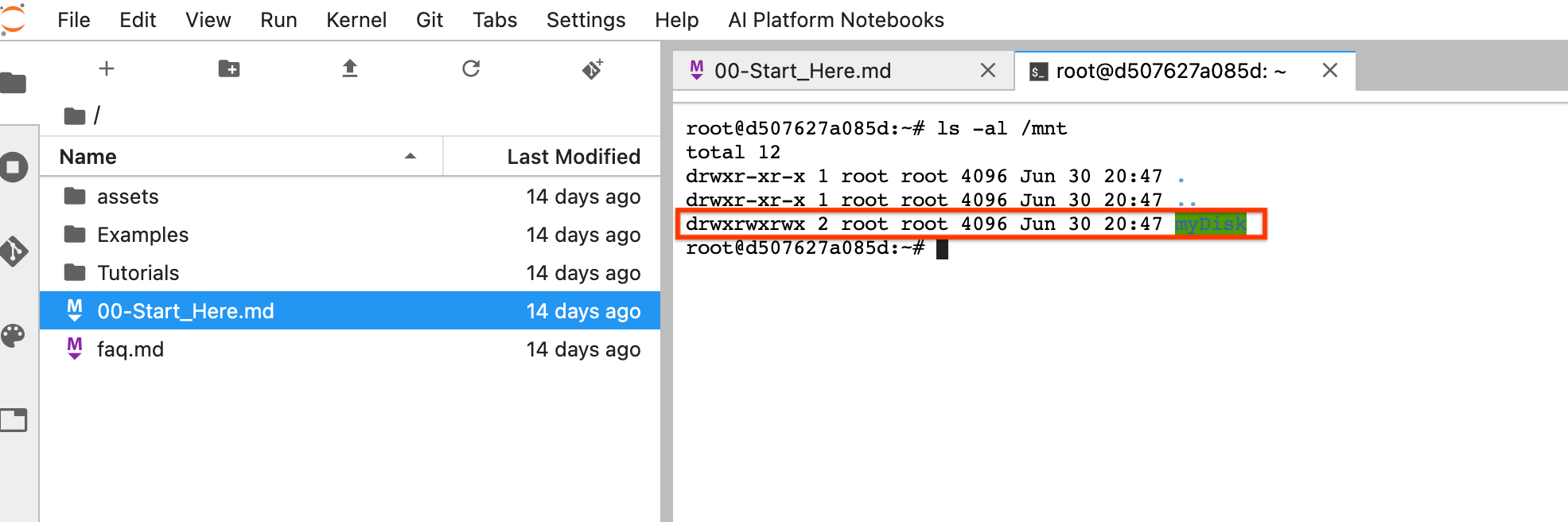
Ahora puedes guardar tu trabajo en el directorio /mnt/myDisk. Incluso si se borra la instancia de notebook,
el disco persistente existe en tu proyecto. Luego, puedes conectar este disco persistente a otras instancias de notebook.
Realiza una limpieza
Una vez que termines de usar la instancia de notebook de Apache Beam, limpia los recursos que creaste en Google Cloud. Para ello, cierra la instancia de notebook.
¿Qué sigue?
- Obtén información sobre las funciones avanzadas que puedes usar con los notebooks de Apache Beam. Las funciones avanzadas incluyen los siguientes flujos de trabajo: