JupyterLab ノートブックで Apache Beam インタラクティブ ランナーを使用して、次のタスクを行います。
- パイプラインを繰り返し開発する。
- パイプライン グラフを調べる。
- read-eval-print-loop(REPL)ワークフローで個々の
PCollectionsを解析する。
これらの Apache Beam ノートブックは、Vertex AI Workbench で提供されています。最新のデータ サイエンスと ML フレームワークがプリインストールされたノートブック仮想マシンをホストするマネージド サービスです。Dataflow は、Apache Beam コンテナを使用するワークベンチ インスタンスのみをサポートします。
このガイドでは、Apache Beam ノートブックを導入することで実現する機能を中心に取り上げますが、ノートブックの作成方法については説明しません。Apache Beam の詳細については、Apache Beam プログラミング ガイドをご覧ください。
サポートと制限事項
- Apache Beam ノートブックは Python のみをサポートします。
- これらのノートブックで実行される Apache Beam パイプライン セグメントは、本番環境の Apache Beam ランナーではなく、テスト環境で実行されます。Dataflow サービスでノートブックを起動するには、Apache Beam ノートブックで作成したパイプラインをエクスポートします。詳しくは、ノートブックに作成されたパイプラインから Dataflow ジョブを起動するをご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Apache Beam ノートブック インスタンスを作成する前に、Pub/Sub など、他のサービスを使用するパイプライン用に追加の API を有効にします。
有効にしていない場合、ノートブック インスタンスは、IAM プロジェクト編集者ロールを持つデフォルトの Compute Engine サービス アカウントによって実行されます。プロジェクトがサービス アカウントのロールを明示的に制限している場合は、ノートブックを実行するための十分な権限がプロジェクトに付与されていることを確認してください。たとえば、Pub/Sub トピックから読み取る場合はサブスクリプションを暗黙的に作成するので、サービス アカウントには IAM Pub/Sub 編集者のロールが必要となります。これに対して、Pub/Sub サブスクリプションから読み取る際に必要なのは、IAM Pub/Sub サブスクライバーのロールのみです。
このガイドを完了したら、今後課金が発生しないように、作成したリソースを削除します。詳しくは、クリーンアップをご覧ください。
Apache Beam ノートブック インスタンスを起動する
Google Cloud コンソールで、Dataflow の [ワークベンチ] ページに移動します。
[インスタンス] タブが表示されていることを確認します。
ツールバーで、[ 新規作成] をクリックします。
[環境] セクションの [環境] で、[コンテナ] を [Apache Beam] に設定します。Apache Beam ノートブックでサポートされているのは JupyterLab 3.x のみです。
省略可: GPU でノートブックを実行する場合は、[マシンタイプ] セクションで GPU をサポートするマシンタイプを選択します。詳細については、GPU プラットフォームをご覧ください。
[ネットワーキング] セクションで、ノートブック VM のサブネットワークを選択します。
省略可: カスタム ノートブック インスタンスを設定する場合は、カスタム コンテナを使用してインスタンスを作成するをご覧ください。
[作成] をクリックします。Dataflow Workbench に、新しい Apache Beam ノートブック インスタンスが作成されます。
ノートブック インスタンスが作成されると、[JupyterLab を開く] リンクがアクティブになります。[JupyterLab を開く] をクリックします。
省略可: 依存関係をインストールする
Apache Beam ノートブックには、Apache Beam とGoogle Cloud コネクタの依存関係がすでにインストールされています。サードパーティのライブラリに依存するカスタム コネクタやカスタム PTransforms がパイプラインに含まれている場合は、ノートブック インスタンスを作成した後にインストールできます。
Apache Beam ノートブックの例
ノートブック インスタンスを作成した後、JupyterLab で開きます。JupyterLab サイドバーの [Files] タブの Examples フォルダには、いくつかのサンプル ノートブックが含まれています。JupyterLab ファイルの操作の詳細については、JupyterLab ユーザーガイドのファイルの操作をご覧ください。
次のノートブックを使用できます。
- Word Count
- Streaming Word Count
- Streaming NYC Taxi Ride Data
- Apache Beam SQL in notebooks with comparisons to pipelines
- Apache Beam SQL in notebooks with the Dataflow Runner
- Apache Beam SQL in notebooks
- Dataflow Word Count
- Interactive Flink at Scale
- RunInference
- Use GPUs with Apache Beam
- データを可視化する
Tutorials フォルダには、Apache Beam の基礎を説明する追加のチュートリアルが含まれています。次のチュートリアルが利用可能です。
- 基本オペレーション
- 要素ごとのオペレーション
- 集計
- ウィンドウ
- I/O オペレーション
- ストリーミング
- 最終演習
これらのノートブックには、Apache Beam のコンセプトと API の使用方法の理解を助ける説明テキストとコメント付きのコードブロックが含まれています。また、チュートリアルでは、学習したコンセプトを実践的に練習できます。
以降のセクションでは、Streaming Word Count ノートブックのサンプルコードを使用します。このガイドのコード スニペットと Streaming Word Count ノートブックのコード スニペットは、若干異なる場合があります。
ノートブック インスタンスを作成する
[File] > [New] > [Notebook] に移動し、Apache Beam 2.22 以降のカーネルを選択します。
Apache Beam ノートブックは、Apache Beam SDK のマスター ブランチに対して作成されます。つまり、ノートブック UI に表示される最新バージョンのカーネルが、最新バージョンの SDK よりも新しい可能性があります。
Apache Beam はノートブック インスタンスにインストールされているため、ノートブックには interactive_runner モジュールと interactive_beam モジュールが含まれます。
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
ノートブックで他の Google API を使用している場合は、次の import ステートメントを追加します。
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
インタラクティブ オプションを設定する
以下の行は、InteractiveRunner が無制限のソースからデータを記録するまでの時間を設定しています。この例では、期間は 10 分に設定されています。
ib.options.recording_duration = '10m'
recording_size_limit プロパティを使用して、無制限のソースの記録サイズの上限(バイト単位)を変更することもできます。
# Set the recording size limit to 1 GB.
ib.options.recording_size_limit = 1e9
その他のインタラクティブ オプションについては、interactive_beam.options クラスをご覧ください。
パイプラインを作成する
InteractiveRunner オブジェクトを使用して、パイプラインを初期化します。
options = pipeline_options.PipelineOptions(flags={})
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Set the project to the default project in your current Google Cloud environment.
# The project is used to create a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
p = beam.Pipeline(InteractiveRunner(), options=options)
データの読み取りと可視化
次の例は、指定された Pub/Sub トピックにサブスクリプションを作成し、そのサブスクリプションから読み取りを行う Apache Beam パイプラインを示しています。
words = p | "read" >> beam.io.ReadFromPubSub(topic="projects/pubsub-public-data/topics/shakespeare-kinglear")
パイプラインは、ソースからウィンドウごとに単語をカウントします。固定されたウィンドウを作成し、各ウィンドウの長さを 10 秒に設定します。
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
データがウィンドウ処理されると、ウィンドウごとに単語をカウントします。
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
show() メソッドは、作成された PCollection をノートブックに可視化します。
ib.show(windowed_word_counts, include_window_info=True)
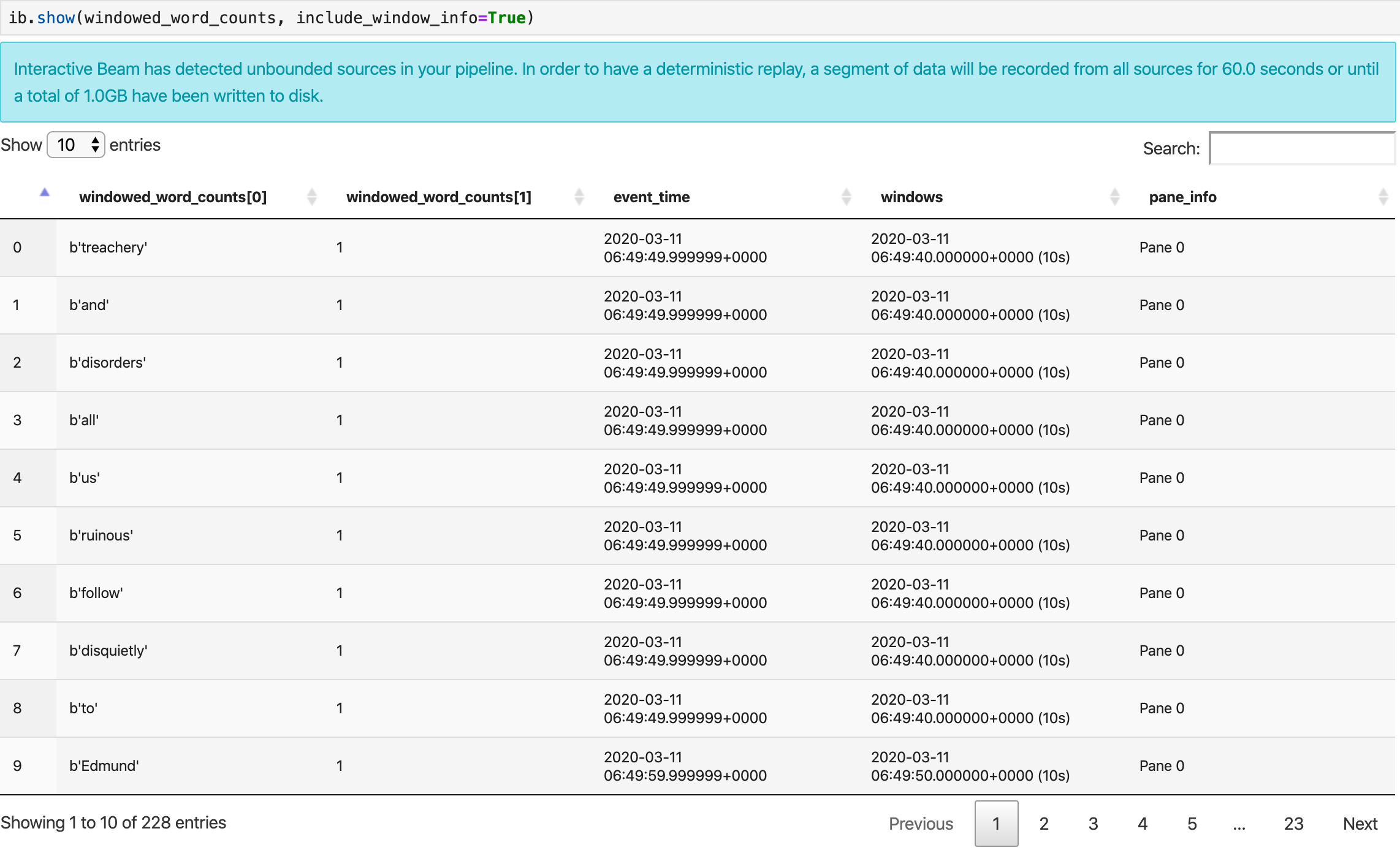
n と duration の 2 つのオプション パラメータを設定すると、show() から結果セットを絞り込むことができます。
nを設定して、結果セットが最大でnの要素数(20 など)を表示するように制限します。nが設定されていない場合、デフォルトの動作として、ソースの記録が終了するまで最新の要素が一覧表示されます。durationを設定して、結果セットをソース記録の開始から指定した秒数のデータに制限します。durationが設定されていない場合、デフォルトの動作として、記録が終了するまですべての要素が一覧表示されます。
両方のパラメータを設定した場合、いずれかがしきい値に達すると show() が停止します。次の例では、show() は記録されたソースからの最初の 30 秒に相当するデータに基づいて、計算された最大 20 個の要素を返します。
ib.show(windowed_word_counts, include_window_info=True, n=20, duration=30)
データの可視化を表示するには、visualize_data=True を show() メソッドに渡します。可視化には複数のフィルタを適用できます。次の可視化では、ラベルと軸でフィルタリングできます。
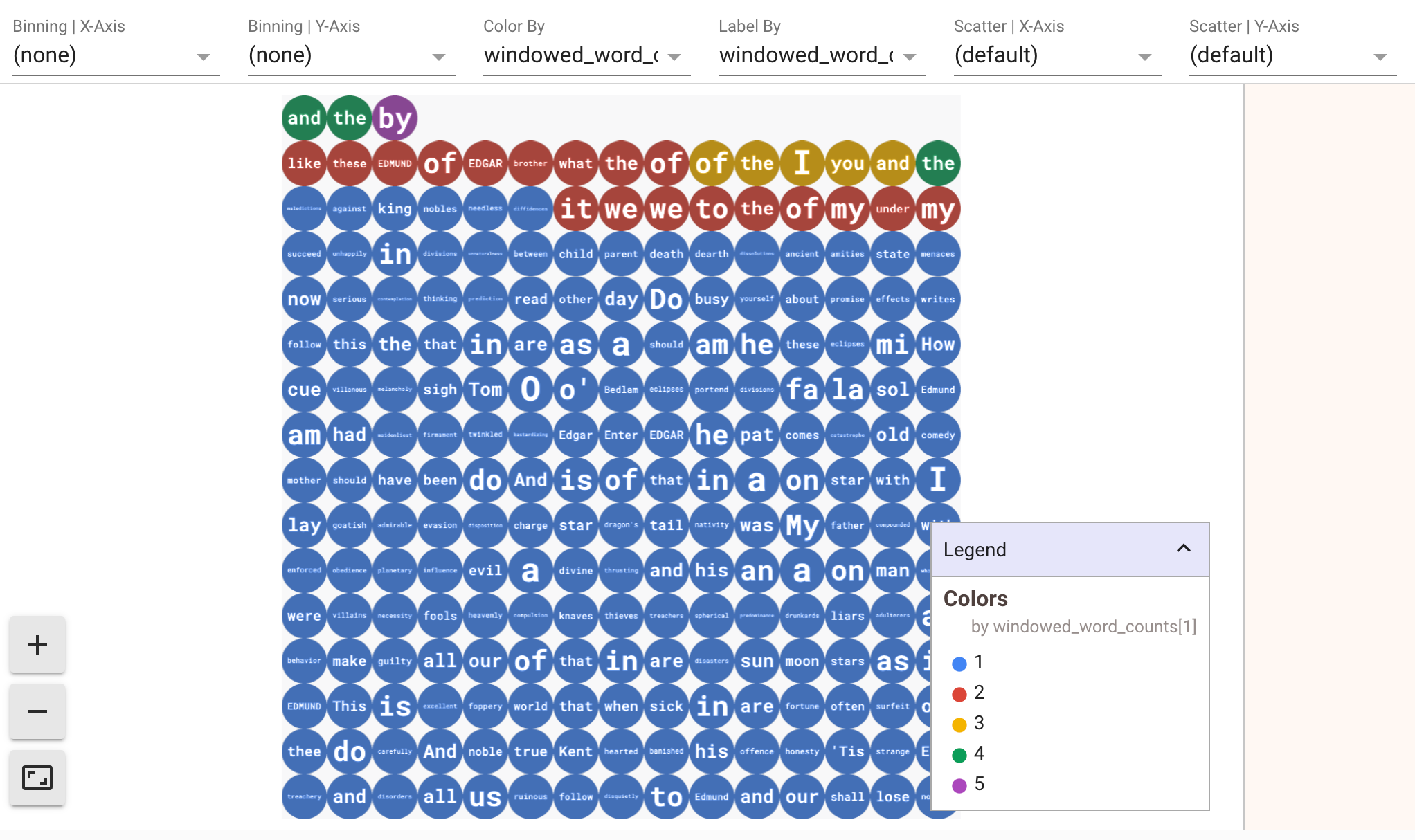
ストリーミング パイプラインのプロトタイピングと同時に再現性を確保するため、show() メソッド呼び出しはデフォルトでキャプチャしたデータを再利用します。この動作を変更し、show() メソッドが常に新しいデータを取得するようにするには、interactive_beam.options.enable_capture_replay = False を設定します。また、2 つ目の無制限ソースをノートブックに追加すると、元の無制限ソースのデータは破棄されます。
Apache Beam ノートブックの可視化では、Pandas DataFrame も役立ちます。次の例では、最初に単語を小文字に変換してから、各単語の頻度を計算します。
windowed_lower_word_counts = (windowed_words
| beam.Map(lambda word: word.lower())
| "count" >> beam.combiners.Count.PerElement())
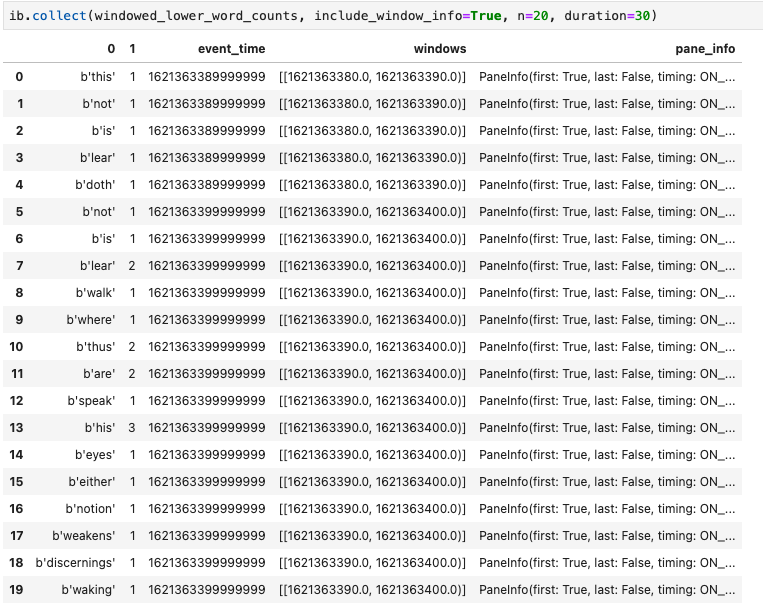
collect() メソッドにより、Pandas DataFrame の出力を取得できます。
ib.collect(windowed_lower_word_counts, include_window_info=True)
ノートブックの開発では、セルの編集と再実行が一般的です。Apache Beam ノートブックでセルを編集して再実行した場合、元のセルでのコード処理は元に戻りません。たとえば、セルがパイプラインに PTransform を追加した場合、そのセルを再実行すると、さらに PTransform がパイプラインに追加されます。状態をクリアするには、カーネルを再起動してセルを再実行します。
Interactive Beam インスペクタでデータを可視化する
show() と collect() を絶え間なく呼び出すことで、PCollection のデータの取り込みを邪魔してしまう場合があります。特に出力が画面スペースの多くを占有し、ノートブックの操作が困難になることがあります。また、複数の PCollections を並べて比較し、変換が意図したとおりに機能するかどうか検証することもできます。たとえば、一方の PCollection が変換を行い、もう一方が生成される場合などです。これらのユースケースでは、Interactive Beam インスペクタのほうが便利です。
Interactive Beam インスペクタは、Apache Beam ノートブックにプリインストールされている JupyterLab 拡張機能 apache-beam-jupyterlab-sidepanel として提供されています。この拡張機能を使用すると、show() や collect() を明示的に呼び出すことなく、各 PCollection に関連付けられたパイプラインとデータの状態をインタラクティブに検査できます。
インスペクタを開く方法は 3 つあります。
JupyterLab のトップメニュー バーで [
Interactive Beam] をクリックします。プルダウンで [Open Inspector] をクリックしてインスペクタを開きます。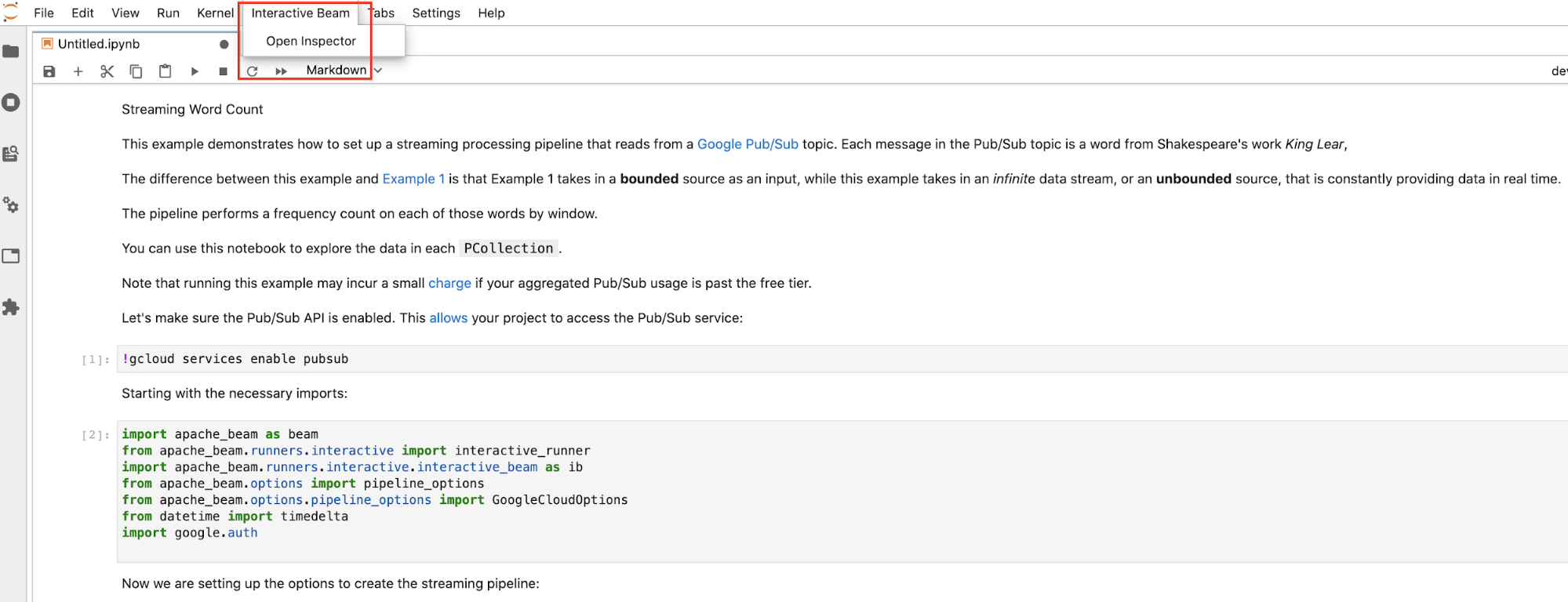
ランチャー ページを使用します。ランチャー ページが開いていない場合は、[
File] -> [New Launcher] の順にクリックして開きます。ランチャー ページでInteractive Beamを探して [Open Inspector] をクリックし、インスペクタを開きます。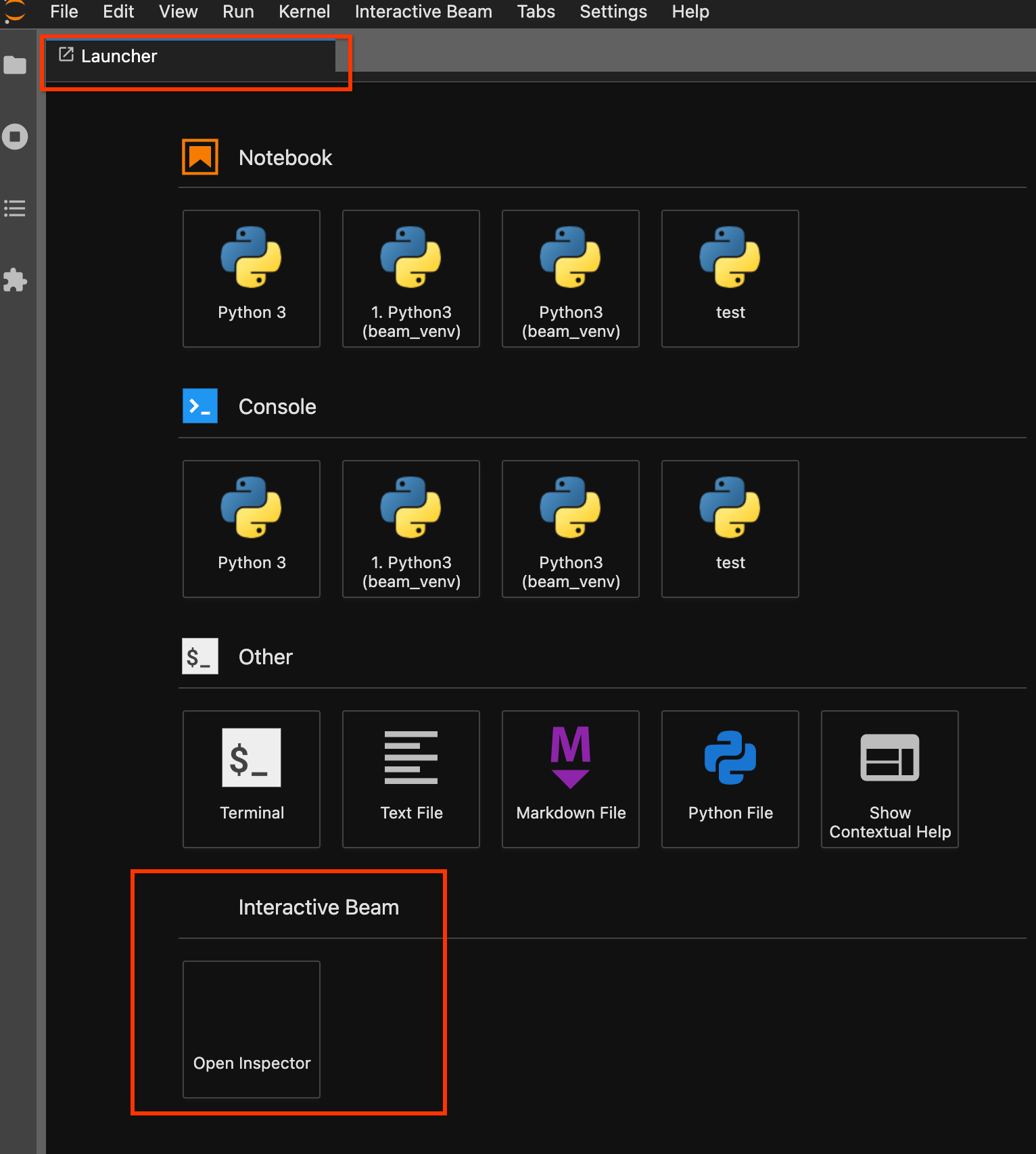
コマンド パレットを使用します。JupyterLab のメニューバーで、[
View] > [Activate Command Palette] をクリックします。ダイアログでInteractive Beamを検索して、拡張機能のすべてのオプションを一覧表示します。[Open Inspector] をクリックしてインスペクタを開きます。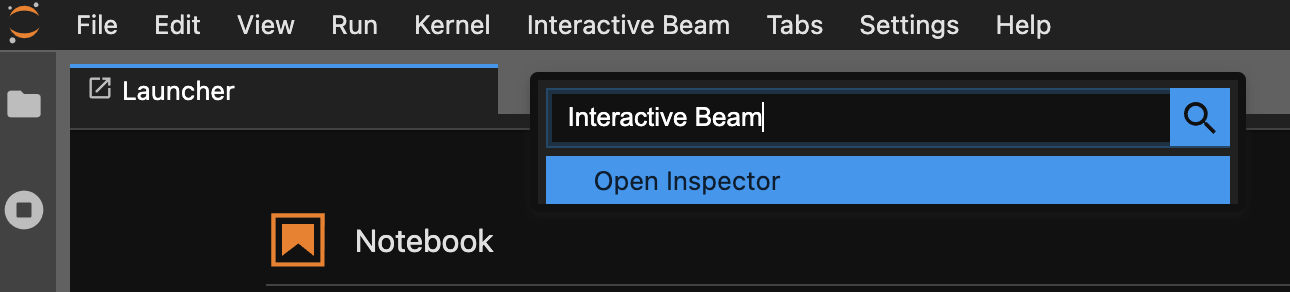
インスペクタが開くときに:
開いているノートブックが 1 つだけの場合、インスペクタは自動的にそのノートブックに接続します。
ノートブックが開いていない場合は、カーネルを選択するためのダイアログが表示されます。
複数のノートブックが開いている場合は、ノートブック セッションを選択するためのダイアログが表示されます。
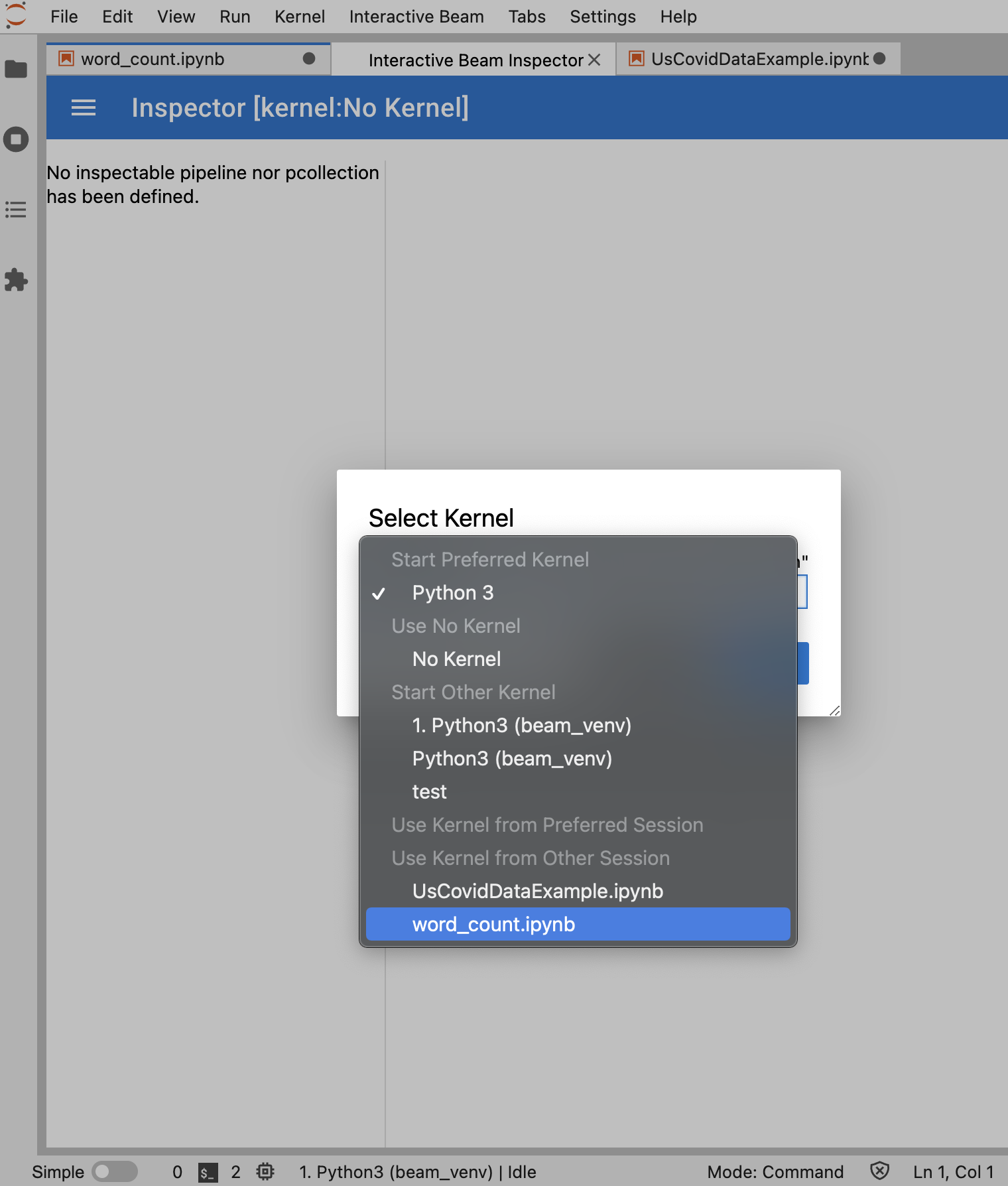
インスペクタを開く前に、少なくとも 1 つのノートブックを開いて、そのカーネルを選択することをおすすめします。ノートブックを開く前にカーネルでインスペクタを開く場合は、後でノートブックを開いてインスペクタに接続するときに、Use
Kernel from Preferred Session から Interactive Beam Inspector Session を選択する必要があります。同じカーネルから作成された異なるセッションではなく、同じセッションを共有している場合は、インスペクタとノートブックが接続されます。Start Preferred Kernel から同じカーネルを選択すると、開いているノートブックまたはインスペクタの既存のセッションから独立した新しいセッションが作成されます。
開いたノートブックに複数のインスペクタを開き、ワークスペースでタブを自由にドラッグ&ドロップすることでインスペクタを並べ替えることができます。
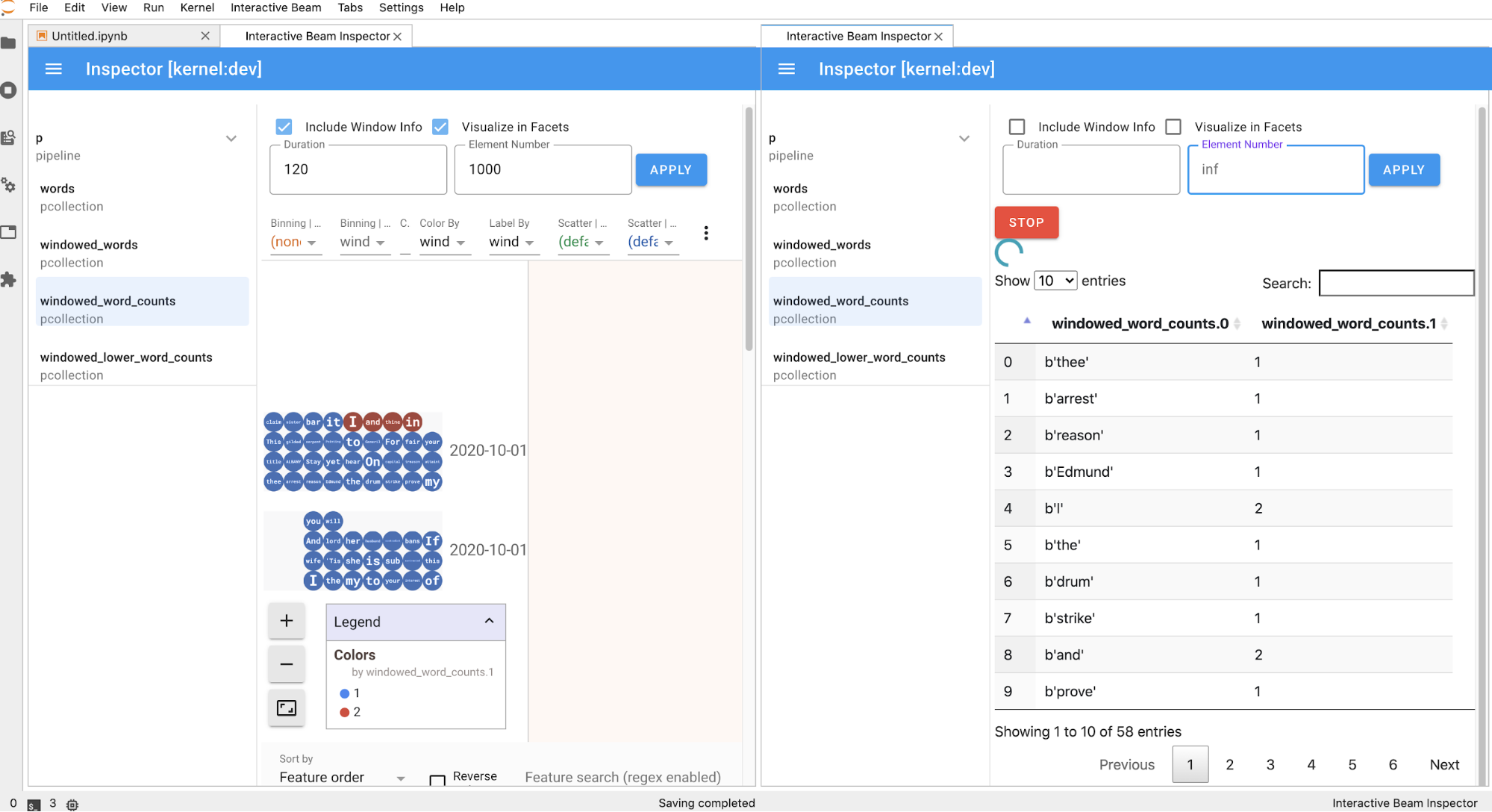
ノートブックでセルを実行すると、インスペクタ ページが自動的に更新されます。このページには、接続されたノートブックで定義されているパイプラインと PCollections が一覧表示されます。PCollections は、それが属するパイプラインごとに整理されています。ヘッダー パイプラインをクリックすると、折りたたむことができます。
パイプラインと PCollections リスト内のアイテムをクリックすると、対応する可視化データがインスペクタの右側にレンダリングされます。
PCollectionの場合、インスペクタは、追加のウィジェットを使用してデータをレンダリングします(データがまだ無制限のPCollectionsに送信されている場合は動的にレンダリングします)。[APPLY] ボタンをクリックすると、可視化が調整されます。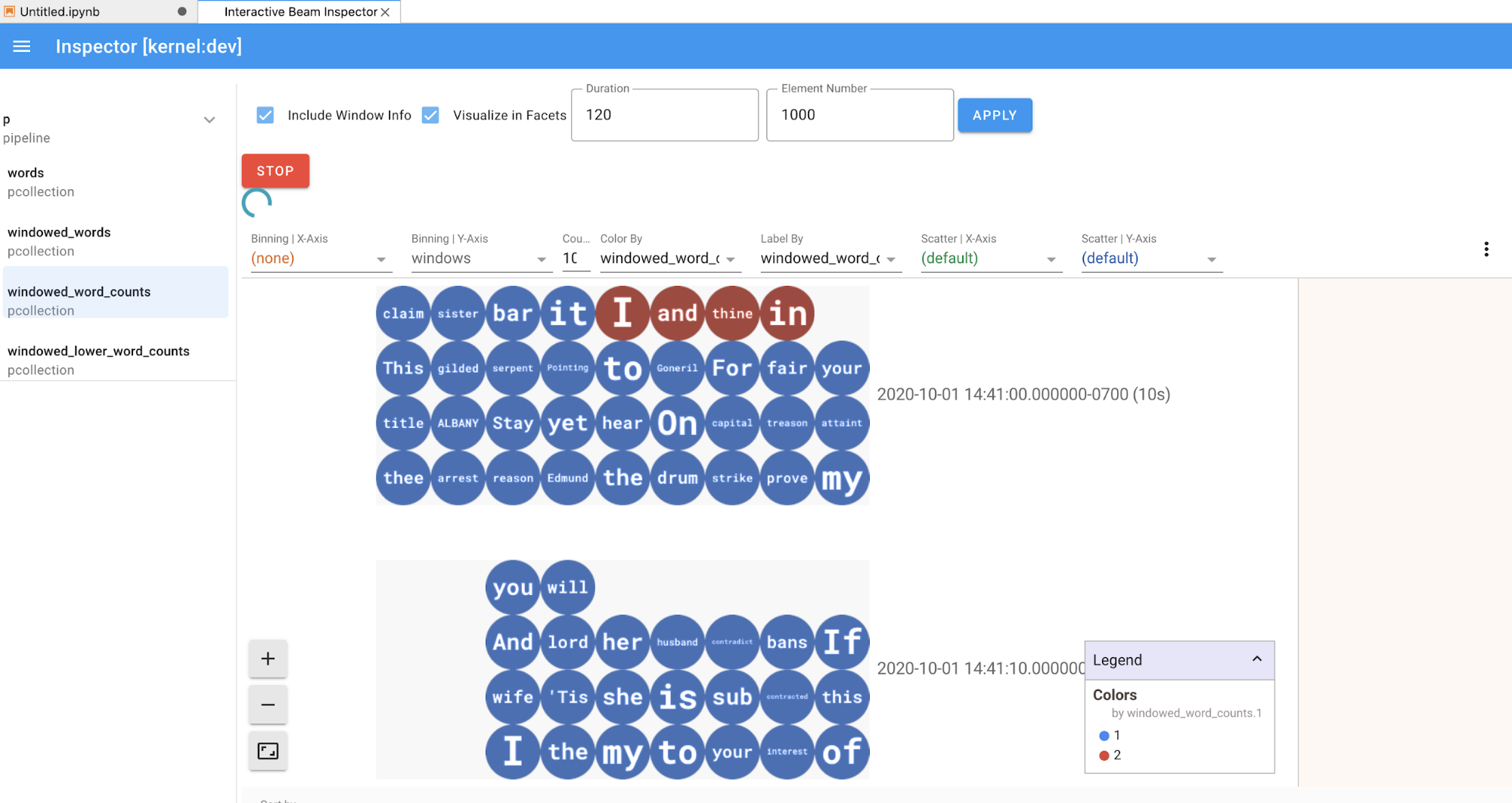
インスペクタと開いているノートブックは同じカーネル セッションを共有するため、互いの実行をブロックします。たとえば、ノートブックでコードの実行がビジー状態の場合、ノートブックがその実行を完了するまでインスペクタは更新されません。逆に、インスペクタが
PCollectionを動的に可視化しているときに、ノートブックでなんらかのコードをすぐに実行する場合は、[STOP] ボタンをクリックして可視化を停止します。これにより、処理が完了する前に、カーネルをノートブックに解放できます。パイプラインである場合は、インスペクタにパイプラインのグラフが表示されます。
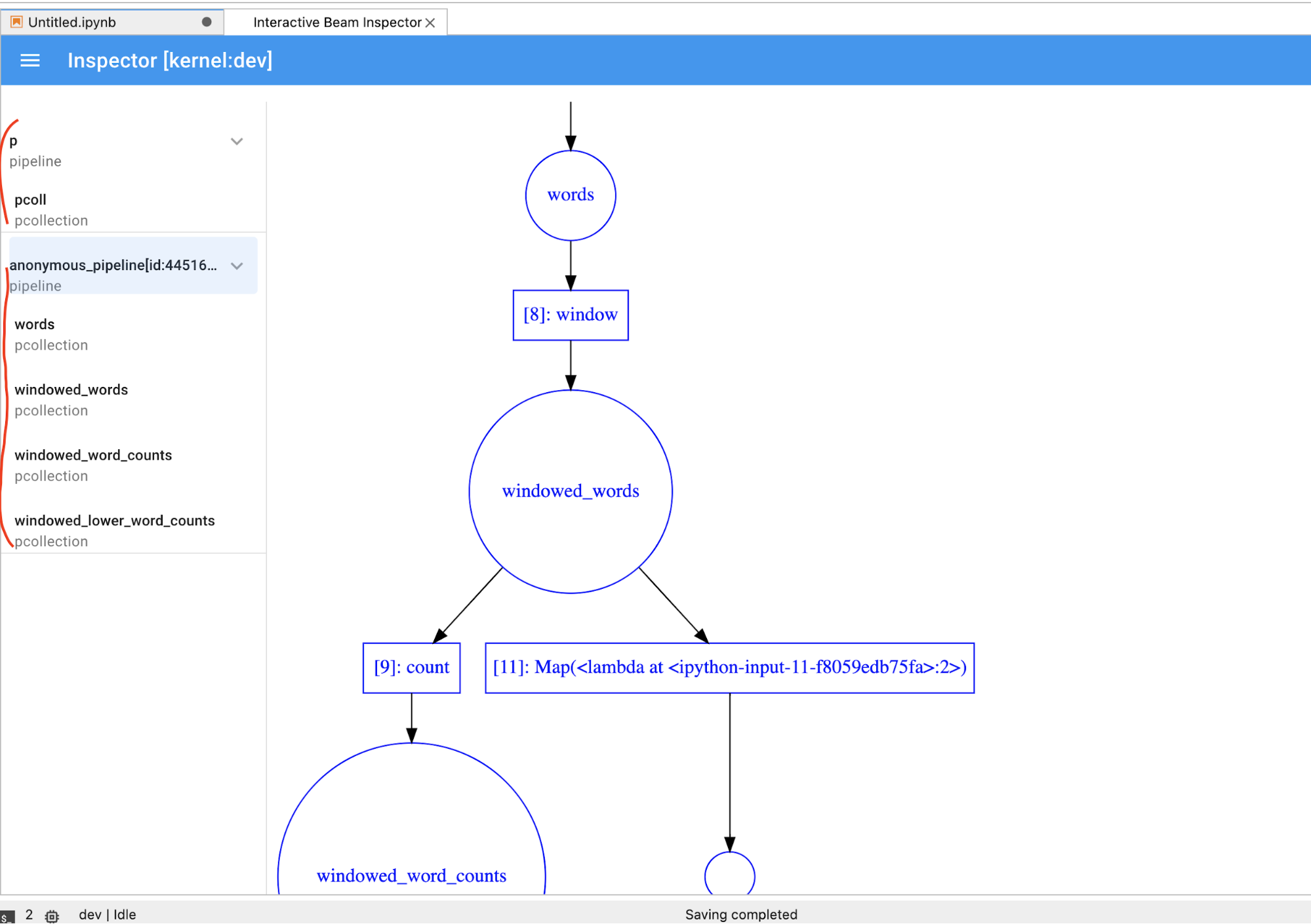
匿名パイプラインが表示される場合があります。これらのパイプラインには PCollections があります。アクセスはできますが、メイン セッションからは参照されなくなります。例:
p = beam.Pipeline()
pcoll = p | beam.Create([1, 2, 3])
p = beam.Pipeline()
前の例では、空のパイプライン p と、1 つの PCollection pcoll を含む匿名パイプラインを作成しています。pcoll.pipeline を使用すると、匿名パイプラインにアクセスできます。
パイプラインと PCollection リストを切り替えることで、大規模な可視化に必要なスペースを節約できます。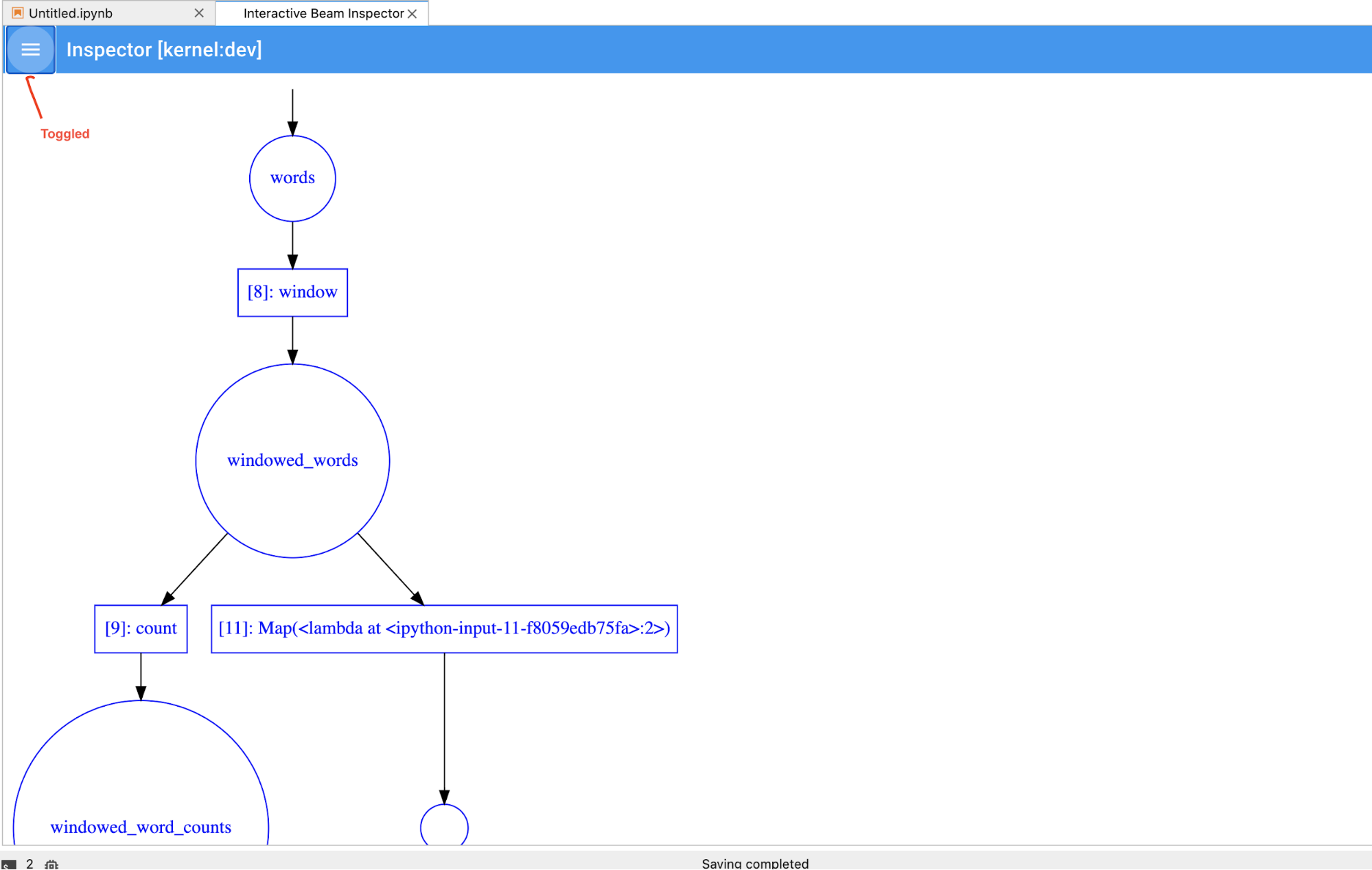
パイプラインの記録ステータスについて
可視化だけでなく、describe を呼び出すことで、ノートブック インスタンス内の 1 つまたはすべてのパイプラインの記録ステータスを調べることもできます。
# Return the recording status of a specific pipeline. Leave the parameter list empty to return
# the recording status of all pipelines.
ib.recordings.describe(p)
describe() メソッドは、次の詳細情報を提供します。
- ディスク上のパイプラインのすべての記録の合計サイズ(バイト単位)
- バックグラウンドの記録ジョブの開始時間(Unix エポックからの秒数)
- バックグラウンドの記録ジョブの現在のパイプライン ステータス
- パイプラインの Python 変数
ノートブックに作成されたパイプラインから Dataflow ジョブを起動する
- 省略可: ノートブックを使用して Dataflow ジョブを実行する前に、カーネルを再起動し、すべてのセルを再実行して出力を確認します。この手順を省略すると、ノートブックの隠れた状態がパイプライン オブジェクトのジョブグラフに影響を及ぼす可能性があります。
- Dataflow API を有効にします。
次の import ステートメントを追加します。
from apache_beam.runners import DataflowRunnerパイプライン オプションを渡します。
# Set up Apache Beam pipeline options. options = pipeline_options.PipelineOptions() # Set the project to the default project in your current Google Cloud # environment. _, options.view_as(GoogleCloudOptions).project = google.auth.default() # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://<change me>/dataflow' # Set the staging location. This location is used to stage the # Dataflow pipeline and SDK binary. options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location # Set the temporary location. This location is used to store temporary files # or intermediate results before outputting to the sink. options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location # If and only if you are using Apache Beam SDK built from source code, set # the SDK location. This is used by Dataflow to locate the SDK # needed to run the pipeline. options.view_as(pipeline_options.SetupOptions).sdk_location = ( '/root/apache-beam-custom/packages/beam/sdks/python/dist/apache-beam-%s0.tar.gz' % beam.version.__version__)パラメータ値は調整できます。たとえば、
regionの値をus-central1から変更できます。DataflowRunnerを使用してパイプラインを実行します。これにより、Dataflow サービスでジョブが実行されます。runner = DataflowRunner() runner.run_pipeline(p, options=options)pは、パイプラインの作成のパイプライン オブジェクトです。
インタラクティブ ノートブックでこの変換を実行する方法の例については、ノートブック インスタンスの Dataflow Word Count ノートブックを参照してください。
あるいは、ノートブックを実行可能スクリプトとしてエクスポートし、生成された .py ファイルを前の手順で変更してから、Dataflow サービスにパイプラインをデプロイすることもできます。
ノートブックを保存する
作成したノートブックは、実行中のノートブック インスタンスにローカルに保存されます。開発中にノートブック インスタンスをリセットまたはシャットダウンした場合、これらの新しいノートブックは、/home/jupyter ディレクトリの下に作成される限り保持されます。ただし、ノートブック インスタンスが削除されると、それらのノートブックも削除されます。
ノートブックを後で使用できるようにするには、ワークステーションにローカルにダウンロードするか、GitHub に保存するか、別のファイル形式にエクスポートします。
ノートブックを追加の永続ディスクに保存する
さまざまなノートブック インスタンスでノートブックやスクリプトなどの処理を保持する場合は、Persistent Disk に保存します。
Persistent Disk を作成するか、アタッチします。手順に沿って
sshを使用してノートブック インスタンスの VM に接続し、開いている Cloud Shell でコマンドを発行します。Persistent Disk がマウントされているディレクトリ(
/mnt/myDiskなど)をメモします。ノートブック インスタンスの VM の詳細を編集し、
Custom metadataに次のエントリを追加します: キー -container-custom-params、値 --v /mnt/myDisk:/mnt/myDisk。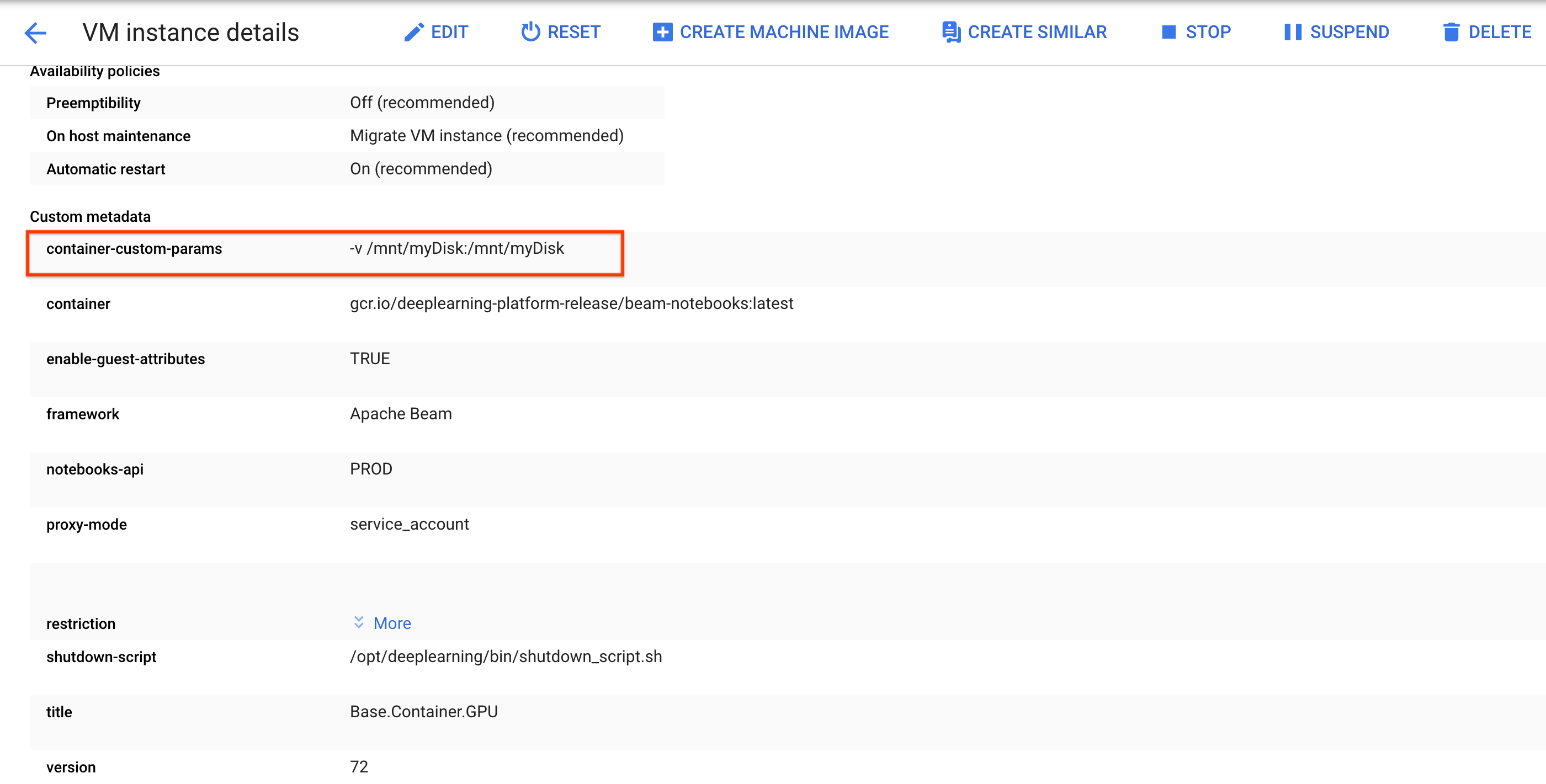
[保存] をクリックします。
これらの変更を更新するには、ノートブック インスタンスをリセットします。
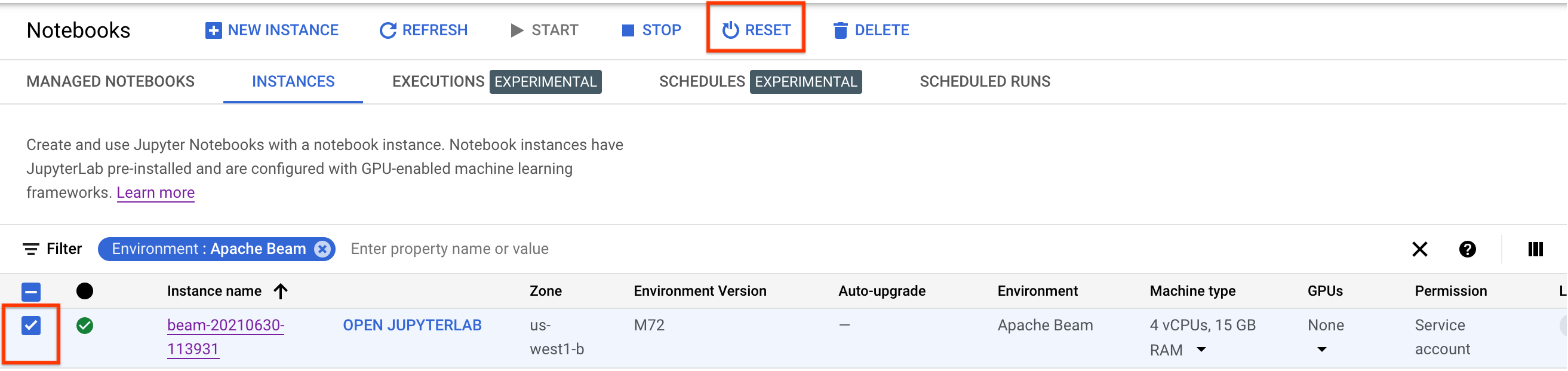
リセット後、[JupyterLab を開く] をクリックします。JupyterLab UI が利用可能になるまでに時間がかかることがあります。UI が表示されたら、ターミナルを開き、
ls -al /mntコマンドを実行します。/mnt/myDiskディレクトリが一覧表示されます。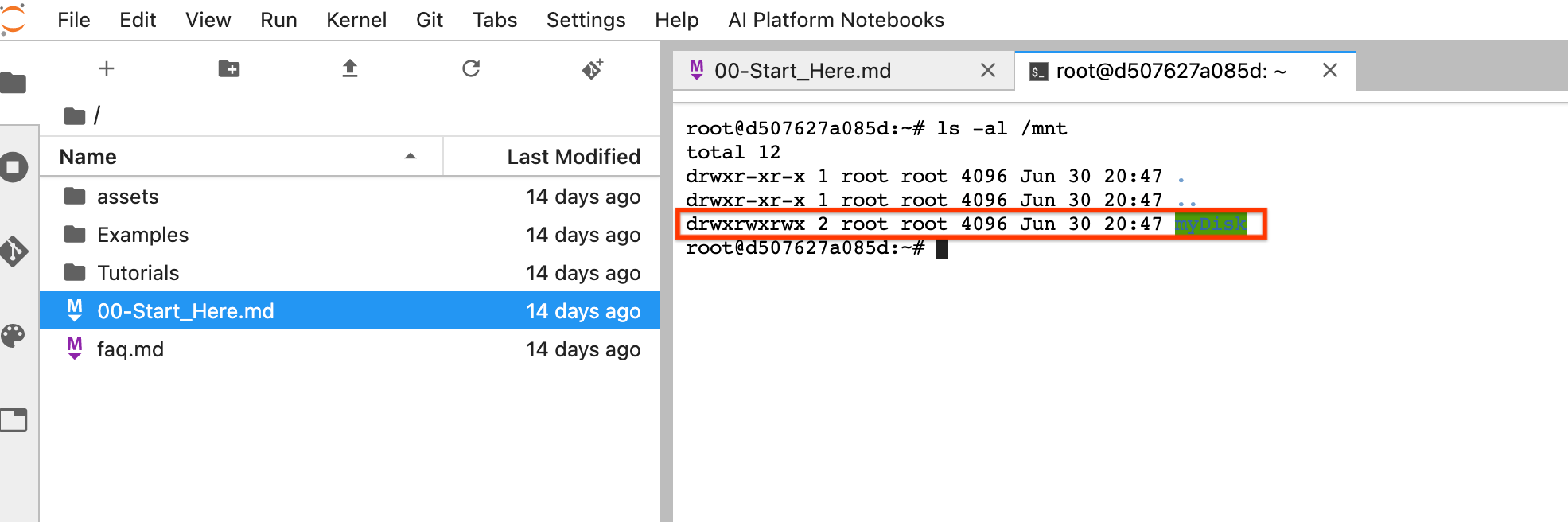
これで、作業を /mnt/myDisk ディレクトリに保存できるようになりました。ノートブック インスタンスが削除されても、Persistent Disk はプロジェクト内に存在します。この Persistent Disk は、他のノートブック インスタンスにアタッチできます。
クリーンアップ
Apache Beam ノートブック インスタンスの使用が終了したら、ノートブック インスタンスをシャットダウンして、 Google Cloud で作成したリソースをクリーンアップします。
次のステップ
- Apache Beam ノートブックで使用できる高度な機能について学習する。高度な機能には、次のワークフローあります。