Esta página explica como ativar o agendamento flexível de recursos (FlexRS) para pipelines em lote com escala automática no Dataflow.
O FlexRS reduz os custos de processamento em lote através da utilização de técnicas de agendamento avançadas, do serviço Dataflow Shuffle e de uma combinação de instâncias de máquinas virtuais (VMs) preemptíveis e VMs normais. Ao executar VMs preemptíveis e VMs normais em paralelo, o Dataflow melhora a experiência do utilizador quando o Compute Engine para instâncias de VMs preemptíveis durante um evento do sistema. O FlexRS ajuda a garantir que o pipeline continua a progredir e que não perde o trabalho anterior quando o Compute Engine interrompe as suas VMs preemptíveis.
Os trabalhos com FlexRS usam o Dataflow Shuffle baseado em serviços para juntar e agrupar. Como resultado, as tarefas FlexRS não usam recursos de disco persistente para armazenar resultados de cálculos temporários. A utilização da funcionalidade Dataflow Shuffle permite que os FlexRS processem melhor a preempção de uma VM de trabalho, uma vez que o serviço Dataflow não tem de redistribuir dados para os trabalhadores restantes. Cada worker do Dataflow continua a precisar de um pequeno volume de disco persistente de 25 GB para armazenar a imagem da máquina e os registos temporários.
Apoio técnico e limitações
- Suporta pipelines em lote.
- Requer o Apache Beam SDK para Java 2.12.0 ou posterior, o Apache Beam SDK para Python 2.12.0 ou posterior ou o Apache Beam SDK para Go.
- Usa o Dataflow Shuffle. A ativação do FlexRS ativa automaticamente o Dataflow Shuffle.
- Não suporta GPUs.
- Não suporta reservas do Compute Engine.
- As tarefas do FlexRS têm um atraso na programação. Por conseguinte, o FlexRS é mais adequado para cargas de trabalho que não sejam críticas em termos de tempo, como tarefas diárias ou semanais que podem ser concluídas num determinado período.
Agendamento atrasado
Quando envia uma tarefa FlexRS, o serviço Dataflow coloca a tarefa numa fila e envia-a para execução no prazo de seis horas após a criação da tarefa. O Dataflow encontra a melhor hora para iniciar a tarefa dentro desse período, com base na capacidade disponível e noutros fatores.
Quando envia uma tarefa FlexRS, o serviço Dataflow executa os seguintes passos:
- Devolve um ID do trabalho imediatamente após o envio do trabalho.
- Executa uma execução de validação antecipada.
Usa o resultado da validação antecipada para determinar o passo seguinte.
- Se tiver êxito, coloca a tarefa em fila para aguardar o lançamento atrasado.
- Em todos os outros casos, a tarefa falha e o serviço Dataflow comunica os erros.
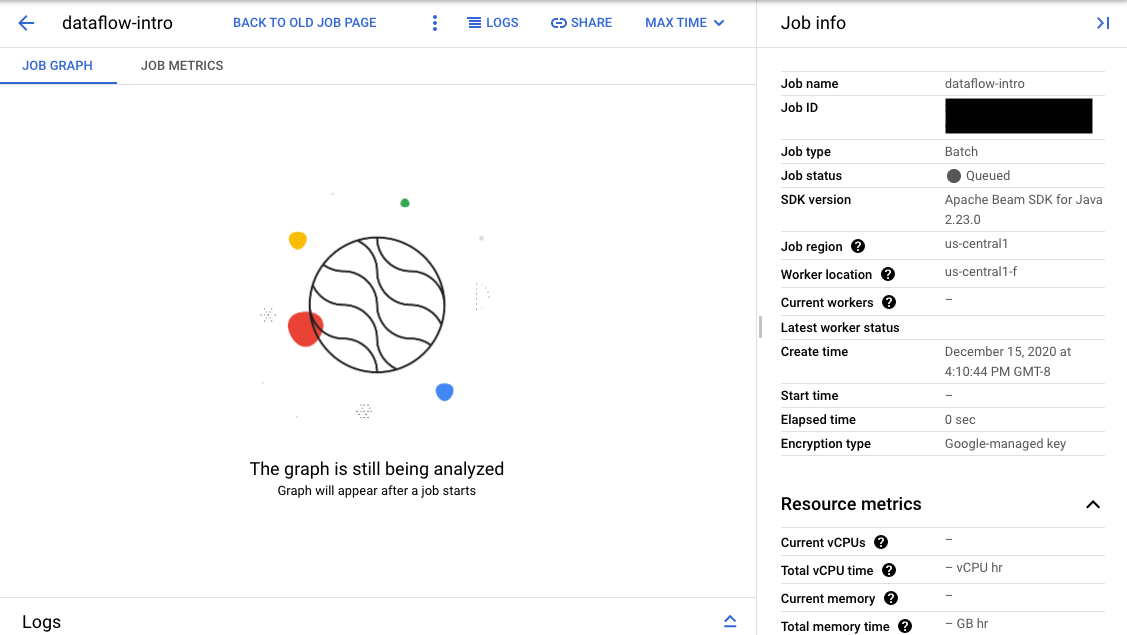
Se a validação for bem-sucedida, na interface de monitorização do fluxo de dados, a sua tarefa apresenta um ID e o estado
Queued. Se a validação falhar, o trabalho apresenta o estado Failed.
Validação antecipada
As tarefas do FlexRS não são iniciadas imediatamente após o envio. Durante a validação inicial, o serviço Dataflow valida os parâmetros de execução e as definições do ambiente da Google Cloud Platform, como as funções de IAM e as configurações de rede. O Dataflow valida a tarefa o máximo possível no momento do envio da tarefa e comunica potenciais erros. Este processo de validação antecipada não está sujeito a cobrança.
O passo de validação antecipada não executa código do utilizador. Tem de validar o seu código para verificar se existem problemas através do Apache Beam Direct Runner ou tarefas não FlexRS. Se existirem Google Cloud alterações no ambiente entre a criação da tarefa e o agendamento atrasado da tarefa, a tarefa pode ser bem-sucedida durante a validação inicial, mas falhar na hora do lançamento.
Ative o FlexRS
Quando cria uma tarefa FlexRS, é usada uma quota de tarefas concorrentes, mesmo quando a tarefa está no estado Em fila. O processo de validação antecipada não valida nem reserva outras quotas. Por conseguinte, antes de ativar o FlexRS, verifique se tem quotas de recursos do projeto Google Cloud suficientes para iniciar a tarefa. Isto inclui quota adicional para CPUs preemptíveis, CPUs normais e endereços IP, a menos que desative o parâmetro de IP público.
Se não tiver quota suficiente, a sua conta pode não ter recursos suficientes quando a tarefa FlexRS for implementada. O Dataflow seleciona VMs preemptíveis para 90% dos trabalhadores no conjunto de trabalhadores por predefinição. Ao planear a quota de CPU, certifique-se de que tem uma quota de VMs preemptíveis suficiente. Pode pedir explicitamente uma quota de VMs preemptíveis. Caso contrário, a sua tarefa FlexRS não terá os recursos necessários para ser executada atempadamente.
Preços
As tarefas FlexRS são faturadas pelos seguintes recursos:
- CPUs normais e preemptíveis
- Recursos de memória
- Recursos do Dataflow Shuffle
- 25 GB por trabalhador de recursos de disco persistente
Embora o Dataflow use trabalhadores regulares e preemptíveis para executar a sua tarefa FlexRS, é-lhe faturada uma taxa com desconto uniforme em comparação com os preços normais do Dataflow, independentemente do tipo de trabalhador. Os recursos do Dataflow Shuffle e do disco persistente não têm desconto.
Para mais informações, leia a página de detalhes dos preços do Dataflow.
Opções de pipeline
Java
Para ativar uma tarefa FlexRS, use a seguinte opção de pipeline:
--flexRSGoal=COST_OPTIMIZED, onde o objetivo otimizado em função dos custos significa que o serviço Dataflow escolhe quaisquer recursos com desconto disponíveis.--flexRSGoal=SPEED_OPTIMIZED, onde é otimizado para um tempo de execução mais baixo. Se não for especificado, o campo--flexRSGoaltem a predefiniçãoSPEED_OPTIMIZED, que é o mesmo que omitir esta flag.
As tarefas FlexRS afetam os seguintes parâmetros de execução:
numWorkerssó define o número inicial de trabalhadores. No entanto, pode definirmaxNumWorkerspor motivos de controlo de custos.- Não pode usar a opção
autoscalingAlgorithmcom tarefas FlexRS. - Não pode especificar o sinalizador
zonepara tarefas FlexRS. O serviço Dataflow seleciona a zona para todas as tarefas FlexRS na região que especificou com o parâmetroregion. - Tem de selecionar uma
Localização do fluxo de dados
como
region. - Não pode usar as séries de máquinas M2, M3 ou H3 para o seu
workerMachineType.
O exemplo seguinte mostra como adicionar parâmetros aos parâmetros da pipeline normais para usar o FlexRS:
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
Se omitir region, maxNumWorkers e workerMachineType, o serviço Dataflow determina o valor predefinido.
Python
Para ativar uma tarefa FlexRS, use a seguinte opção de pipeline:
--flexrs_goal=COST_OPTIMIZED, onde o objetivo otimizado em função dos custos significa que o serviço Dataflow escolhe quaisquer recursos com desconto disponíveis.--flexrs_goal=SPEED_OPTIMIZED, onde é otimizado para um tempo de execução mais baixo. Se não for especificado, o campo--flexrs_goaltem a predefiniçãoSPEED_OPTIMIZED, que é o mesmo que omitir esta flag.
As tarefas FlexRS afetam os seguintes parâmetros de execução:
num_workerssó define o número inicial de trabalhadores. No entanto, pode definirmax_num_workerspor motivos de controlo de custos.- Não pode usar a opção
autoscalingAlgorithmcom tarefas FlexRS. - Não pode especificar o sinalizador
zonepara tarefas FlexRS. O serviço Dataflow seleciona a zona para todas as tarefas FlexRS na região que especificou com o parâmetroregion. - Tem de selecionar uma
Localização do fluxo de dados
como
region. - Não pode usar as séries de máquinas M2, M3 ou H3 para o seu
machine_type.
O exemplo seguinte mostra como adicionar parâmetros aos parâmetros da pipeline normais para usar o FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Se omitir region, max_num_workers e machine_type, o serviço Dataflow determina o valor predefinido.
Go
Para ativar uma tarefa FlexRS, use a seguinte opção de pipeline:
--flexrs_goal=COST_OPTIMIZED, onde o objetivo otimizado em função dos custos significa que o serviço Dataflow escolhe quaisquer recursos com desconto disponíveis.--flexrs_goal=SPEED_OPTIMIZED, onde é otimizado para um tempo de execução mais baixo. Se não for especificado, o campo--flexrs_goaltem a predefiniçãoSPEED_OPTIMIZED, que é o mesmo que omitir esta flag.
As tarefas FlexRS afetam os seguintes parâmetros de execução:
num_workerssó define o número inicial de trabalhadores. No entanto, pode definirmax_num_workerspor motivos de controlo de custos.- Não pode usar a opção
autoscalingAlgorithmcom tarefas FlexRS. - Não pode especificar o sinalizador
zonepara tarefas FlexRS. O serviço Dataflow seleciona a zona para todas as tarefas FlexRS na região que especificou com o parâmetroregion. - Tem de selecionar uma
Localização do fluxo de dados
como
region. - Não pode usar as séries de máquinas M2, M3 ou H3 para o seu
worker_machine_type.
O exemplo seguinte mostra como adicionar parâmetros aos parâmetros da pipeline normais para usar o FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Se omitir region, max_num_workers e machine_type, o serviço Dataflow determina o valor predefinido.
Modelos do Dataflow
Alguns modelos do Dataflow não suportam a opção de pipeline FlexRS. Em alternativa, use a seguinte opção de pipeline.
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
Monitorize tarefas FlexRS
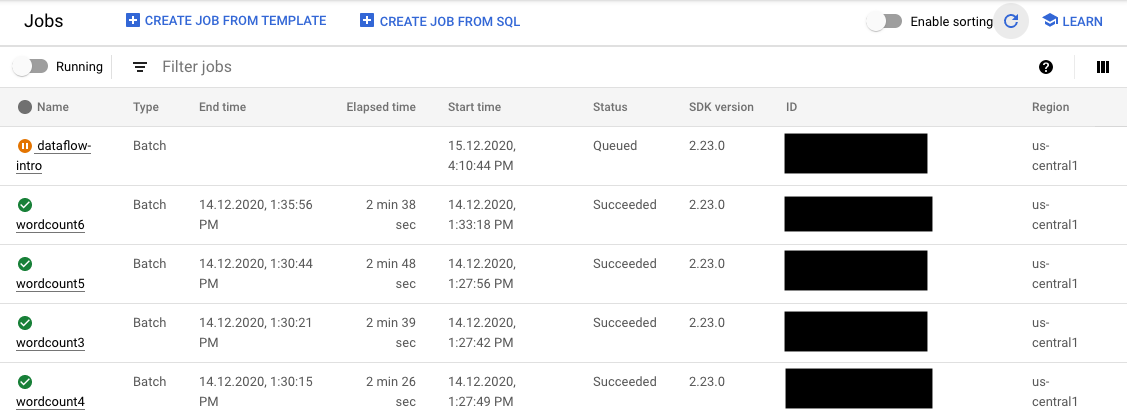
Pode monitorizar o estado da tarefa FlexRS na Google Cloud consola em dois locais:
- A página Tarefas que mostra todas as suas tarefas.
- A página Interface de monitorização do trabalho que enviou.
Na página Tarefas, as tarefas que ainda não foram iniciadas apresentam o estado Em fila.
Na página Interface de monitorização, as tarefas que estão à espera na fila apresentam a mensagem "O gráfico é apresentado após o início de uma tarefa" no separador Gráfico de tarefas.