Nesta página explicamos como ativar a Programação de recursos flexível (FlexRS) para pipelines de lote escalonadas automaticamente no Dataflow.
A FlexRS reduz os custos do processamento em lote usando avançadas técnicas de programação, o serviço do Dataflow Shuffle e uma combinação de instâncias de máquinas virtuais preemptivas e VMs comuns. Ao executar VMs preemptivas e VMs comuns em paralelo, o Dataflow melhora a experiência do usuário caso o Compute Engine interrompa as instâncias de VM preemptiva durante um evento do sistema. A FlexRS ajuda a garantir que o pipeline continue a progredir e que você não perca o trabalho anterior quando o Compute Engine forçar a interrupçãodas VMs preemptivas.
Jobs com a FlexRS usam o Dataflow Shuffle baseado em serviço para mesclar e agrupar. Como resultado, os jobs da FlexRS não usam recursos de disco permanente para armazenar resultados de cálculos temporários. O uso do Dataflow Shuffle permite que a FlexRS processe melhor a preempção de uma VM de worker, porque o serviço do Dataflow não precisa redistribuir dados para os workers restantes. Cada worker do Dataflow ainda precisa de 25 GB de volume de disco permanente para armazenar a imagem da máquina e os registros temporários.
Suporte e limitações
- Oferece suporte a pipelines em lote.
- Requer o SDK do Apache Beam para Java 2.12.0 ou posterior, o SDK do Apache Beam para Python 2.12.0 ou posterior ou o SDK do Apache Beam para Go.
- Usa o Dataflow Shuffle. Ativar a FlexRS ativa automaticamente o Dataflow Shuffle.
- Não oferece suporte a GPUs.
- Não é compatível com reservas do Compute Engine.
- Os jobs da FlexRS têm um atraso no agendamento. Portanto, o FlexRS é mais adequado para cargas de trabalho com o prazo mais longo, como jobs diários ou semanais que podem ser concluídos em um determinado período.
Programação atrasada
Quando você envia um job de FlexRS, o serviço do Dataflow o coloca em uma fila e envia para execução até seis horas depois da criação dele. O Dataflow encontra o melhor horário para iniciar o job dentro desse intervalo de tempo, com base na capacidade disponível e em outros fatores.
Ao enviar um job da FlexRS, o serviço Dataflow executará as seguintes etapas:
- Retorna o ID do job imediatamente após o envio do job.
- Executa uma validação antecipada.
Usa o resultado da validação inicial para determinar o próximo passo.
- Em caso de sucesso, os job são enfileirados de acordo com o atraso de lançamento.
- Em todos os outros casos, o job falha e o serviço do Dataflow informa os erros.
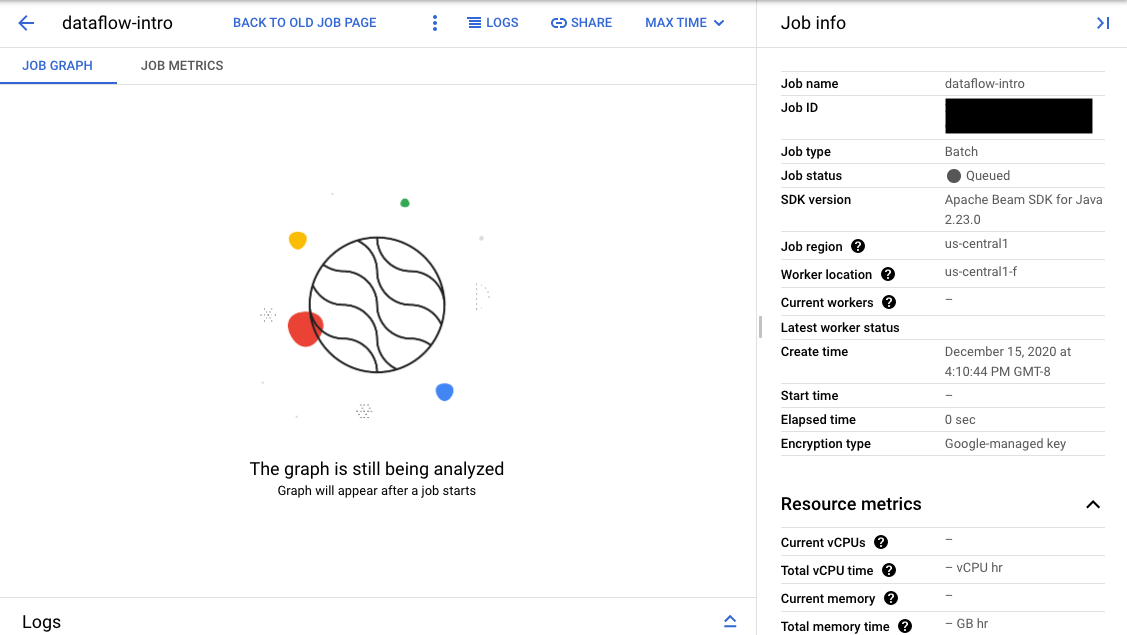
Se a validação for bem-sucedida, na interface de monitoramento do Dataflow, seu job exibirá um ID e o status
Queued. Se a validação falhar, o job exibirá o status Failed.
Validação antecipada
Os jobs da FlexRS não são iniciados imediatamente após o envio. Durante a validação antecipada, o serviço Dataflow verifica os parâmetros de execução e as configurações do ambienteGoogle Cloud , como papéis do IAM e configurações de rede. O Dataflow valida o job o máximo possível no momento do envio e informa possíveis erros. Você não é cobrado por este processo de validação antecipada.
A etapa de validação antecipada não executa o código do usuário. Verifique seu código para procurar problemas usando o Apache Beam Direct Runner (em inglês) ou jobs que não são da FlexRS. Se houver mudanças no ambiente do Google Cloud entre a criação e o agendamento atrasado do job, ele poderá ser bem-sucedido durante a validação inicial, mas ainda falhará no momento do lançamento.
Ativar FlexRS
Ao criar um job da FlexRS, uma cota simultânea é usada, mesmo quando ele estiver no status Na fila. O processo de validação antecipada não verifica nem reserva outras cotas. Portanto, antes de ativar a FlexRS, verifique se você tem Google Cloud cotas de recursos de projeto suficientes para iniciar o job. Isso inclui mais cota para CPUs preemptivas, CPUs comuns e endereços IP, a menos que você desative o parâmetro IP público.
Se você não tiver cota suficiente, talvez sua conta não tenha recursos suficientes quando o job da FlexRS for implementado. O Dataflow seleciona VMs preemptivas para 90% dos workers na pool de workers por padrão. Ao planejar a cota de CPU, verifique se você tem cota de VM preemptiva suficiente. É preciso solicitar a cota de VM preemptiva explicitamente. Caso contrário, seu job da FlexRS não terá os recursos para ser executado em tempo hábil.
Preços
Os jobs do FlexRS são cobrados pelos seguintes recursos:
- CPUs comuns e preemptivas
- Recursos de memória
- Recursos do Dataflow Shuffle
- 25 GB por worker de recursos do Persistent Disk
Embora o Dataflow use tanto os workers preemptivos quanto os normais para executar o job da FlexRS, você recebe uma taxa de desconto uniforme em comparação com os preços normais do Dataflow, independentemente do tipo de worker. Os recursos do Dataflow Shuffle e do Persistent Disk não são descontados.
Para obter mais informações, leia a página Detalhes de preços do Dataflow.
Opções de pipeline
Java
Para ativar um job da FlexRS, use a seguinte opção de pipeline:
--flexRSGoal=COST_OPTIMIZED, em que a meta de custo otimizado significa que o serviço Dataflow escolhe os recursos com desconto disponíveis.--flexRSGoal=SPEED_OPTIMIZED, em que ocorre a otimização para um tempo de execução menor. Se não for especificado, o campo--flexRSGoalseráSPEED_OPTIMIZEDpor padrão, o que é o mesmo que omitir essa sinalização.
Os jobs da FlexRS afetam os seguintes parâmetros de execução:
numWorkersdefine apenas o número inicial de workers. No entanto, é possível definirmaxNumWorkerspor motivos de controle de custos.- Não é possível usar a opção
autoscalingAlgorithmcom jobs da FlexRS. - Não é possível especificar a sinalização
zonepara jobs da FlexRS. O serviço do Dataflow seleciona a zona para todos os jobs da FlexRS na região que você especificou com o parâmetroregion. - Selecione um local do Dataflow como
region. - Não é possível usar a série de máquina M2, M3 ou H3 para seu
workerMachineType.
O exemplo a seguir mostra como adicionar parâmetros aos seus parâmetros de pipeline comuns para usar a FlexRS:
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
Se omitir region, maxNumWorkers e workerMachineType, o serviço do Dataflow determinará o valor padrão.
Python
Para ativar um job da FlexRS, use a seguinte opção de pipeline:
--flexrs_goal=COST_OPTIMIZED, em que a meta de custo otimizado significa que o serviço Dataflow escolhe os recursos com desconto disponíveis.--flexrs_goal=SPEED_OPTIMIZED, em que ocorre a otimização para um tempo de execução menor. Se não for especificado, o campo--flexrs_goalseráSPEED_OPTIMIZEDpor padrão, o que é o mesmo que omitir essa sinalização.
Os jobs da FlexRS afetam os seguintes parâmetros de execução:
num_workersdefine apenas o número inicial de workers. No entanto, é possível definirmax_num_workerspor motivos de controle de custos.- Não é possível usar a opção
autoscalingAlgorithmcom jobs da FlexRS. - Não é possível especificar a sinalização
zonepara jobs da FlexRS. O serviço do Dataflow seleciona a zona para todos os jobs da FlexRS na região que você especificou com o parâmetroregion. - Selecione um local do Dataflow como
region. - Não é possível usar a série de máquina M2, M3 ou H3 para seu
machine_type.
O exemplo a seguir mostra como adicionar parâmetros aos seus parâmetros de pipeline comuns para usar a FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Se você omitir region, max_num_workers e machine_type, o serviço do Dataflow determinará o valor padrão.
Go
Para ativar um job da FlexRS, use a seguinte opção de pipeline:
--flexrs_goal=COST_OPTIMIZED, em que a meta de custo otimizado significa que o serviço Dataflow escolhe os recursos com desconto disponíveis.--flexrs_goal=SPEED_OPTIMIZED, em que ocorre a otimização para um tempo de execução menor. Se não for especificado, o campo--flexrs_goalseráSPEED_OPTIMIZEDpor padrão, o que é o mesmo que omitir essa sinalização.
Os jobs da FlexRS afetam os seguintes parâmetros de execução:
num_workersdefine apenas o número inicial de workers. No entanto, é possível definirmax_num_workerspor motivos de controle de custos.- Não é possível usar a opção
autoscalingAlgorithmcom jobs da FlexRS. - Não é possível especificar a sinalização
zonepara jobs da FlexRS. O serviço do Dataflow seleciona a zona para todos os jobs da FlexRS na região que você especificou com o parâmetroregion. - Selecione um local do Dataflow como
region. - Não é possível usar a série de máquina M2, M3 ou H3 para seu
worker_machine_type.
O exemplo a seguir mostra como adicionar parâmetros aos seus parâmetros de pipeline comuns para usar a FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Se omitir region, max_num_workers e machine_type, o serviço do Dataflow determinará o valor padrão.
Modelos do Dataflow
Alguns modelos do Dataflow não aceitam a opção de pipeline da FlexRS. Como alternativa, use a seguinte opção de pipeline.
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
Monitorar jobs da FlexRS
É possível monitorar o status do job da FlexRS no console Google Cloud em dois locais:
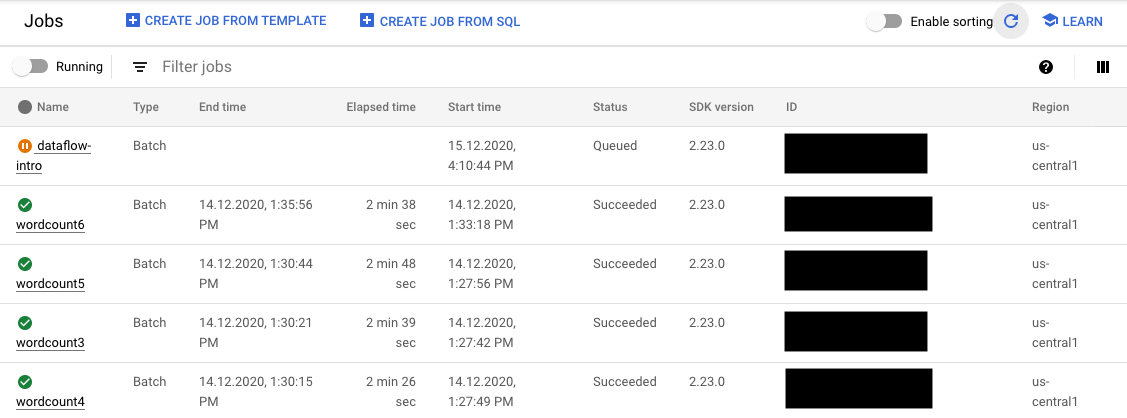
- A página Jobs que mostra todos os seus jobs.
- A página da Interface de monitoramento do job que você enviou.
Na página Jobs, os jobs que não foram iniciados mostram o status Na fila.
Na página Interface de monitoramento, os jobs que estão aguardando na fila exibem a mensagem "O gráfico aparecerá depois que um job é iniciado" na guia Gráfico do job.