Neste tutorial, mostramos como criar um pipeline reutilizável que lê dados do Cloud Storage, realiza verificações de qualidade de dados e grava no Cloud Storage.
Os pipelines reutilizáveis têm uma estrutura de pipeline regular, mas é possível alterar a configuração de cada nó de pipeline com base nas configurações fornecidas por um servidor HTTP. Por exemplo, um pipeline estático pode ler dados do Cloud Storage, aplicar transformações e gravar em uma tabela de saída do BigQuery. Se você quiser que a transformação e a tabela de saída do BigQuery sejam alteradas com base no arquivo do Cloud Storage que o pipeline lê, crie um pipeline reutilizável.
Objetivos
- Use o plug-in Argument Setter do Cloud Storage para permitir que o pipeline leia entradas diferentes em cada execução.
- Use o plug-in Argument Setter do Cloud Storage para permitir que o pipeline realize diferentes verificações de qualidade em cada execução.
- Grave os dados de saída de cada execução no Cloud Storage.
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
- Cloud Data Fusion
- Cloud Storage
Para gerar uma estimativa de custo baseada na sua projeção de uso,
use a calculadora de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, Cloud Storage, BigQuery, and Dataproc APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Crie uma instância do Cloud Data Fusion.
No console do Google Cloud , abra a página Instâncias.
Na coluna Ações da instância, clique no link Visualizar instância. A interface da Web do Cloud Data Fusion é aberta em uma nova guia do navegador.
Navegar até a interface da Web do Cloud Data Fusion
Ao usar o Cloud Data Fusion, você usa o console Google Cloud e a interface da Web separada do Cloud Data Fusion. No console do Google Cloud , é possível criar um projeto do console Google Cloud e criar e excluir instâncias do Cloud Data Fusion. Na interface da Web do Cloud Data Fusion, é possível usar as várias páginas, como o Pipeline Studio ou o Administrador, para usar os recursos do Cloud Data Fusion.
Implantar o plug-in Argument Setter do Cloud Storage
Na interface da Web do Cloud Data Fusion, acesse a página Studio.
No menu Ações, clique em Definidor de argumentos do GCS.
Ler do Cloud Storage
- Na interface da Web do Cloud Data Fusion, acesse a página Studio.
- Clique em arrow_drop_down Origem e selecione Cloud Storage. O nó de uma origem do Cloud Storage aparece no pipeline.
No nó do Cloud Storage, clique em Propriedades.
No campo Nome de referência, insira um nome.
No campo Caminho, digite
${input.path}. Essa macro controla o caminho de entrada do Cloud Storage nas diferentes execuções do pipeline.No painel direito "Esquema de saída", remova o campo offset do esquema de saída clicando no ícone de lixeira na linha do campo "offset".
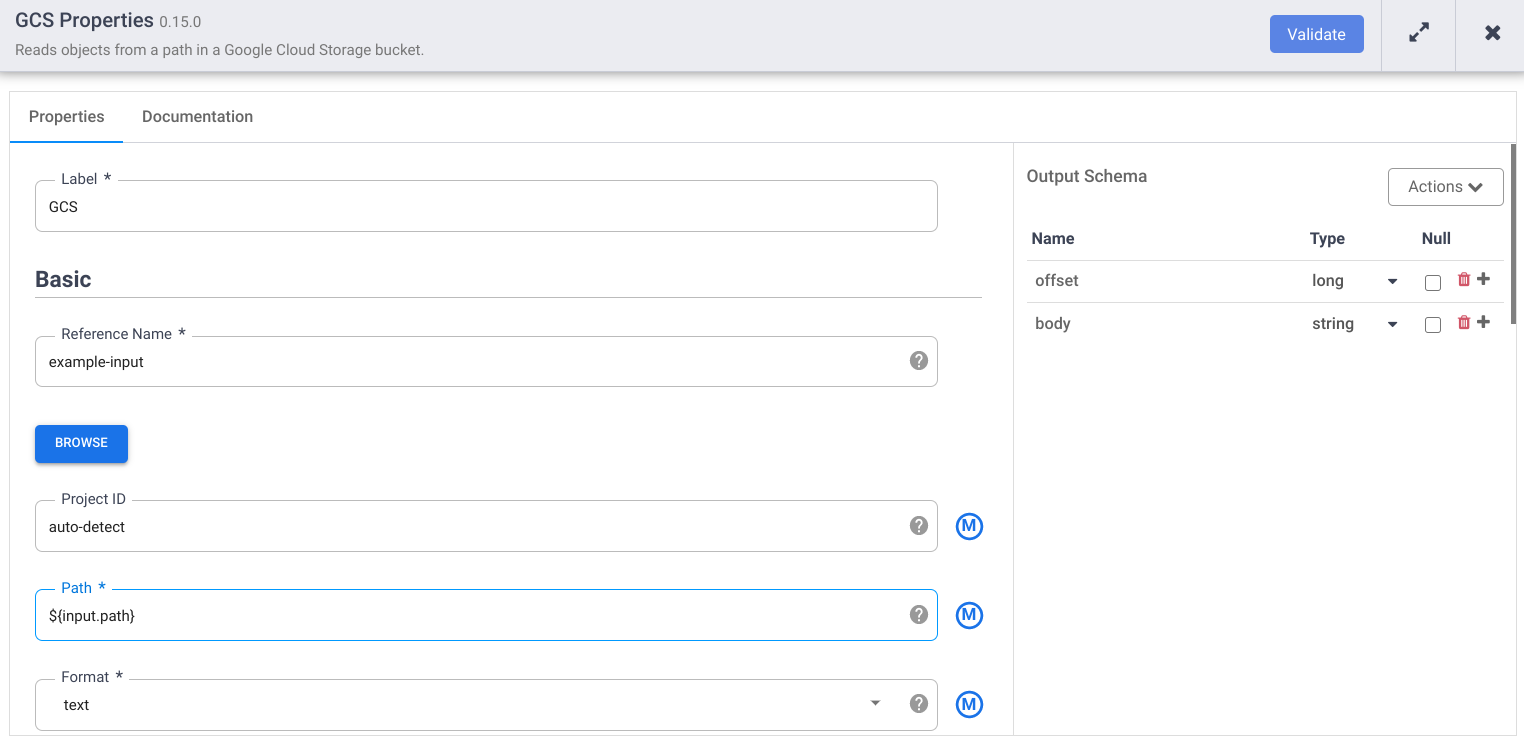
Clique em Validar e corrija os erros.
Clique em para sair da caixa de diálogo Propriedades.
Transformar os dados
- Na interface da Web do Cloud Data Fusion, acesse seu pipeline de dados na página Studio.
- No menu suspenso Transformar arrow_drop_down, selecione Wrangler.
- Na tela do Pipeline Studio, arraste uma seta do nó do Cloud Storage para o nó do Administrador.
- Acesse o nó do Wrangler no pipeline e clique em Propriedades.
- Em Nome do campo de entrada, digite
body. - No campo Receita, digite
${directives}. Essa macro controla a lógica de transformação nas diferentes execuções do pipeline.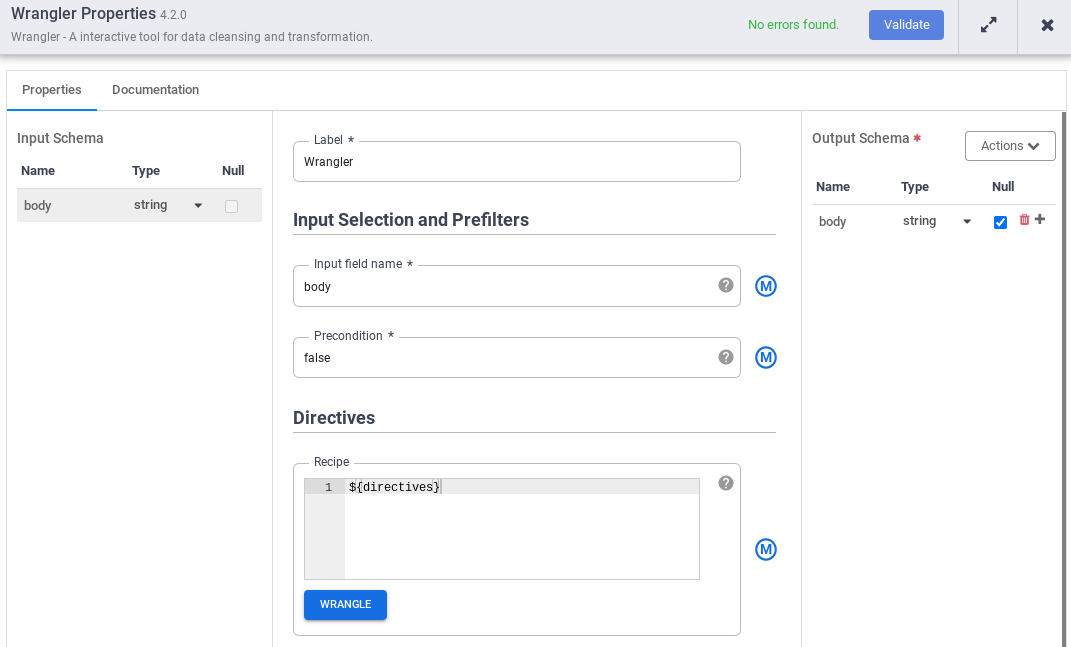
- Clique em Validar e corrija os erros.
- Clique em para sair da caixa de diálogo Propriedades.
Gravar no Cloud Storage
- Na interface da Web do Cloud Data Fusion, acesse seu pipeline de dados na página Studio.
- No menu suspenso Coletor arrow_drop_down, selecione Cloud Storage.
- Na tela do Pipeline Studio, arraste uma seta do nó do Administrador para o nó do Cloud Storage que você acabou de adicionar.
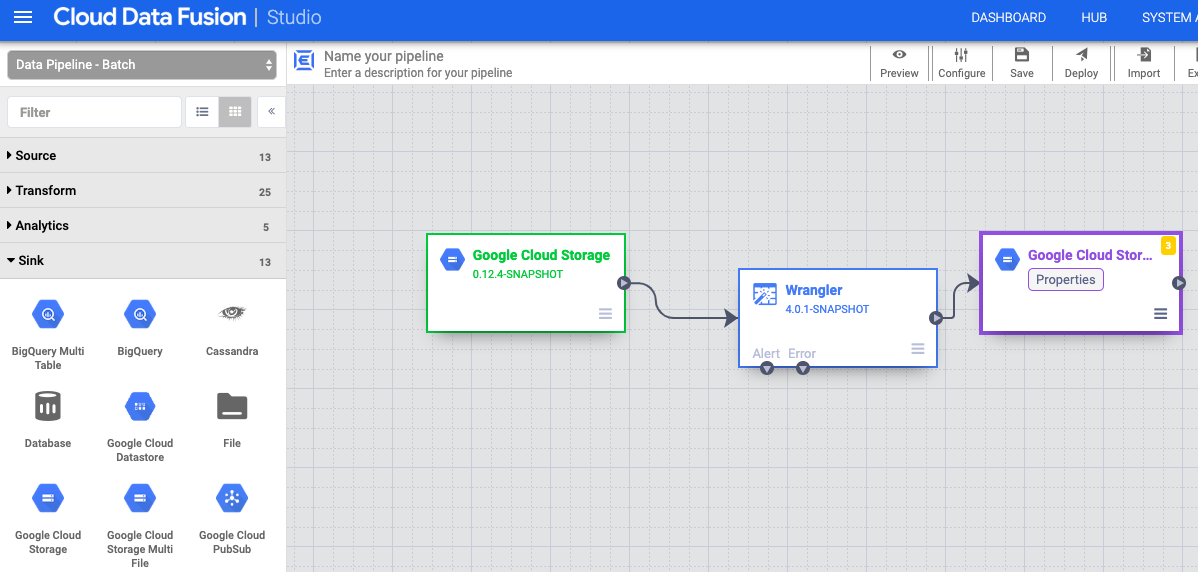
- Acesse o nó de coletor do Cloud Storage no pipeline e clique em Propriedades.
- No campo Nome de referência, insira um nome.
- No campo Caminho, insira o caminho de um bucket do Cloud Storage no projeto, onde o pipeline possa gravar os arquivos de saída. Se você não tiver um bucket do Cloud Storage, crie um.
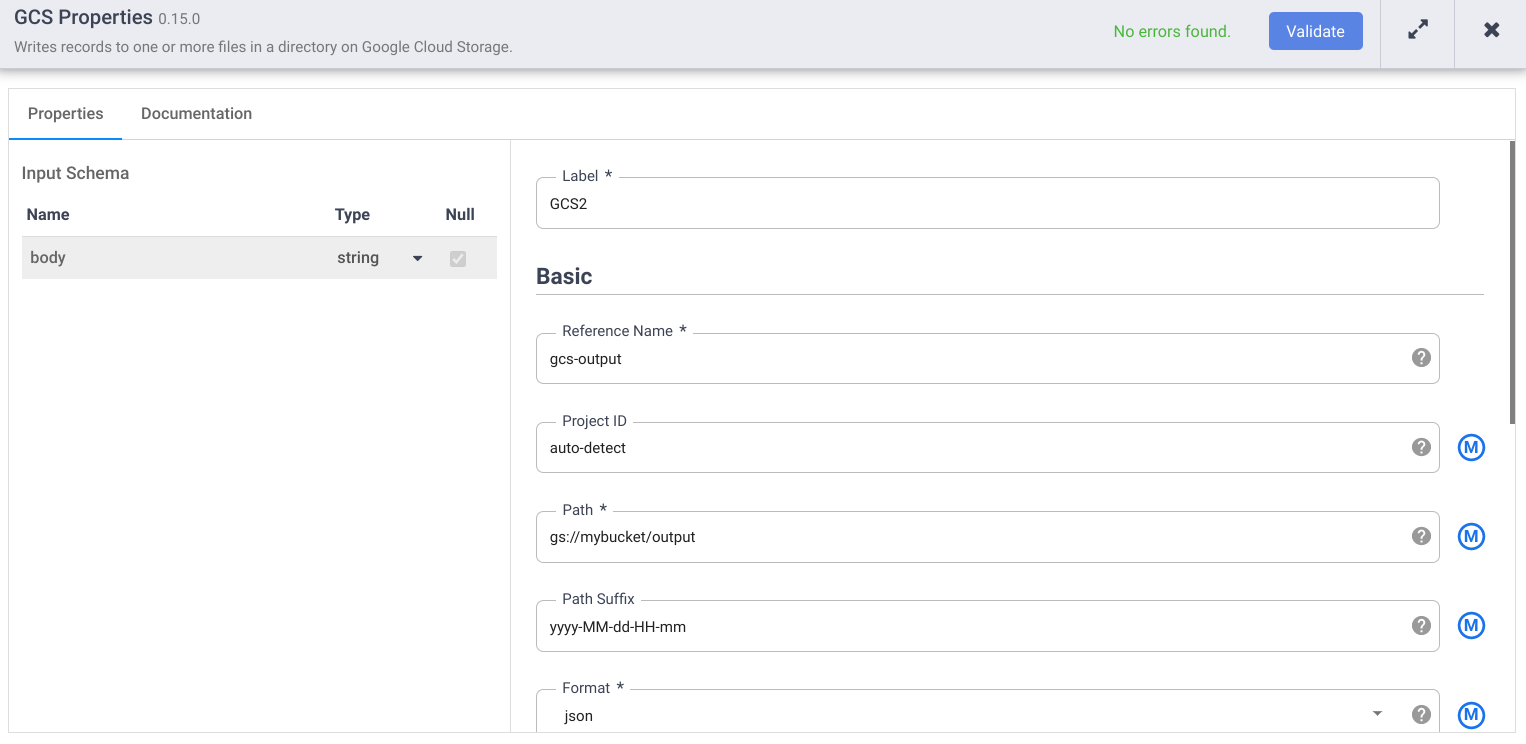
- Clique em Validar e corrija os erros.
- Clique em para sair da caixa de diálogo Propriedades.
Definir os argumentos da macro
- Na interface da Web do Cloud Data Fusion, acesse seu pipeline de dados na página Studio.
- No menu suspenso arrow_drop_down Condições e ações, clique em Definidor de argumentos do GCS.
- Na tela do Pipeline Studio, arraste uma seta do nó "Argument Setter" do Cloud Storage para o nó de origem do Cloud Storage.
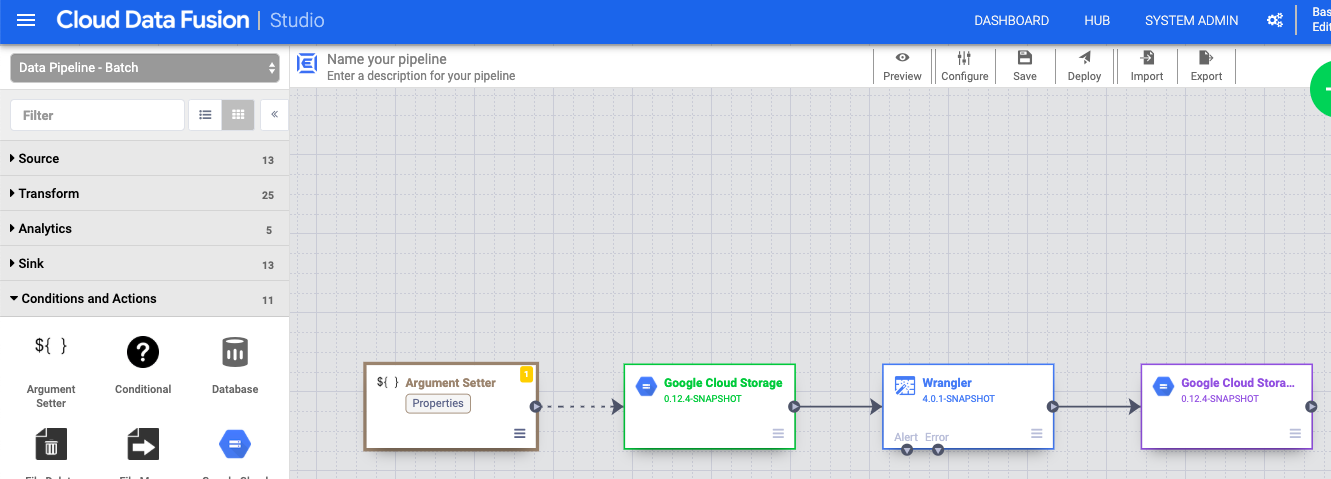
- Acesse o nó "Argument Setter" do Cloud Storage no pipeline e clique em Propriedades.
No campo URL, digite o seguinte URL:
gs://reusable-pipeline-tutorial/args.jsonO URL corresponde a um objeto de acesso público no Cloud Storage com o seguinte conteúdo:
{ "arguments" : [ { "name": "input.path", "value": "gs://reusable-pipeline-tutorial/user-emails.txt" }, { "name": "directives", "value": "send-to-error !dq:isEmail(body)" } ] }O primeiro dos dois argumentos é o valor de
input.path. O caminhogs://reusable-pipeline-tutorial/user-emails.txté um objeto de acesso público no Cloud Storage com os seguintes dados de teste:alice@example.com bob@example.com craig@invalid@example.comO segundo argumento é o valor de
directives. O valorsend-to-error !dq:isEmail(body)configura o Administrador para filtrar as linhas que não são um endereço de e-mail válido. Por exemplo,craig@invalid@example.comé filtrado.Clique em Validar para garantir que você não tem erros.
Clique em para sair da caixa de diálogo Propriedades.
Implantar e executar o pipeline
Na barra superior da página Pipeline Studio, clique em Nomear seu pipeline. Nomeie o pipeline e clique em Salvar.
Clique em Implantar.
Para abrir os Argumentos do ambiente de execução e conferir os argumentos
input.pathedirectivesda macro (tempo de execução), clique no menu suspenso arrow_drop_down ao lado de Executar.Deixe os campos de valor em branco para notificar o Cloud Data Fusion de que o nó do conjunto de argumentos do Cloud Storage no pipeline definirá os valores desses argumentos durante o tempo de execução.
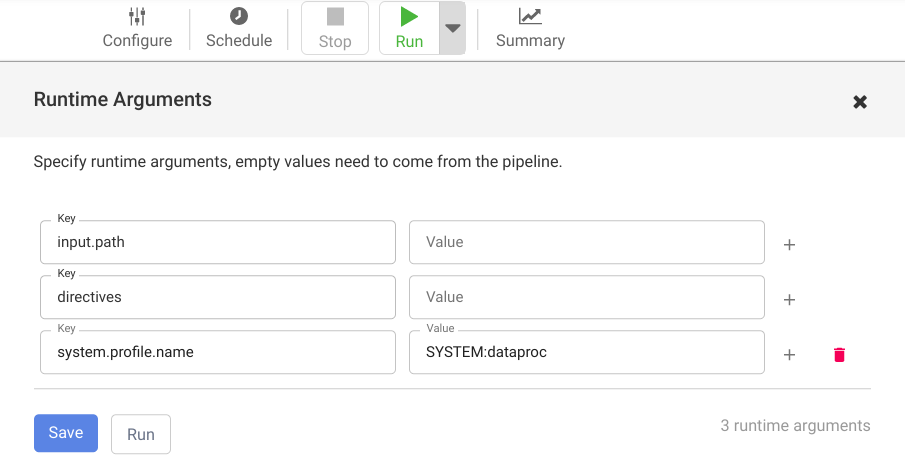
Clique em Executar.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Depois de concluir o tutorial, limpe os recursos criados no Google Cloud para que eles não consumam sua cota e você não receba cobranças por eles no futuro. Nas seções a seguir, você aprenderá a excluir e desativar esses recursos.
Excluir a instância do Cloud Data Fusion
Siga as instruções para excluir a instância do Cloud Data Fusion.
Excluir o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para o tutorial.
Para excluir o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Leia os guias de instruções.
- Veja outro tutorial