Tutorial ini menunjukkan cara membuat pipeline yang dapat digunakan kembali yang membaca data dari Cloud Storage, melakukan pemeriksaan kualitas data, dan menulis ke Cloud Storage.
Pipeline yang dapat digunakan kembali memiliki struktur pipeline reguler, tetapi Anda dapat mengubah konfigurasi setiap node pipeline berdasarkan konfigurasi yang disediakan oleh server HTTP. Misalnya, pipeline statis dapat membaca data dari Cloud Storage, menerapkan transformasi, dan menulis ke tabel output BigQuery. Jika Anda ingin transformasi dan tabel output BigQuery berubah berdasarkan file Cloud Storage yang dibaca pipeline, Anda membuat pipeline yang dapat digunakan kembali.
Men-deploy plugin Cloud Storage Argument Setter
Di antarmuka web Cloud Data Fusion, buka halaman Studio.
Di menu Actions, klik GCS Argument Setter.
Membaca dari Cloud Storage
- Di antarmuka web Cloud Data Fusion, buka halaman Studio.
- Klik arrow_drop_down Sumber, lalu pilih Cloud Storage. Node untuk sumber Cloud Storage akan muncul di pipeline.
Di node Cloud Storage, klik Properties.

Di kolom Nama referensi, masukkan nama.
Di kolom Path, masukkan
${input.path}. Makro ini mengontrol jalur input Cloud Storage dalam berbagai eksekusi pipeline.Di panel Output Schema sebelah kanan, hapus kolom offset dari skema output dengan mengklik ikon sampah di baris kolom offset.

Klik Validasi dan perbaiki error yang ada.
Klik untuk keluar dari dialog Properties.
Mengubah data Anda
- Di antarmuka web Cloud Data Fusion, buka pipeline data Anda di halaman Studio.
- Di menu drop-down Transform arrow_drop_down, pilih Wrangler.
- Di kanvas Pipeline Studio, tarik panah dari node Cloud Storage
ke node Wrangler.

- Buka node Wrangler di pipeline Anda, lalu klik Properties.
- Di Nama kolom input, masukkan
body. - Di kolom Resep, masukkan
${directives}. Makro ini mengontrol logika transformasi yang akan ada di berbagai proses pipeline.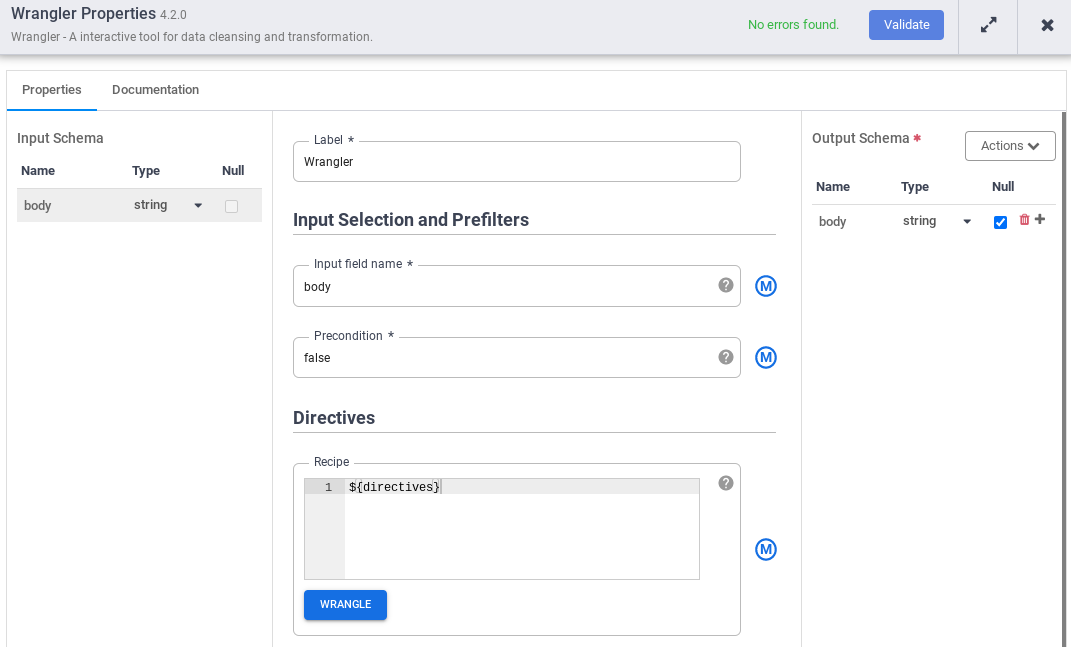
- Klik Validasi dan perbaiki error yang ada.
- Klik untuk keluar dari dialog Properties.
Menulis ke Cloud Storage
- Di antarmuka web Cloud Data Fusion, buka pipeline data Anda di halaman Studio.
- Di menu drop-down Sinkronkan arrow_drop_down, pilih Cloud Storage.
- Di kanvas Pipeline Studio, tarik panah dari node Wrangler ke node Cloud Storage yang baru saja Anda tambahkan.
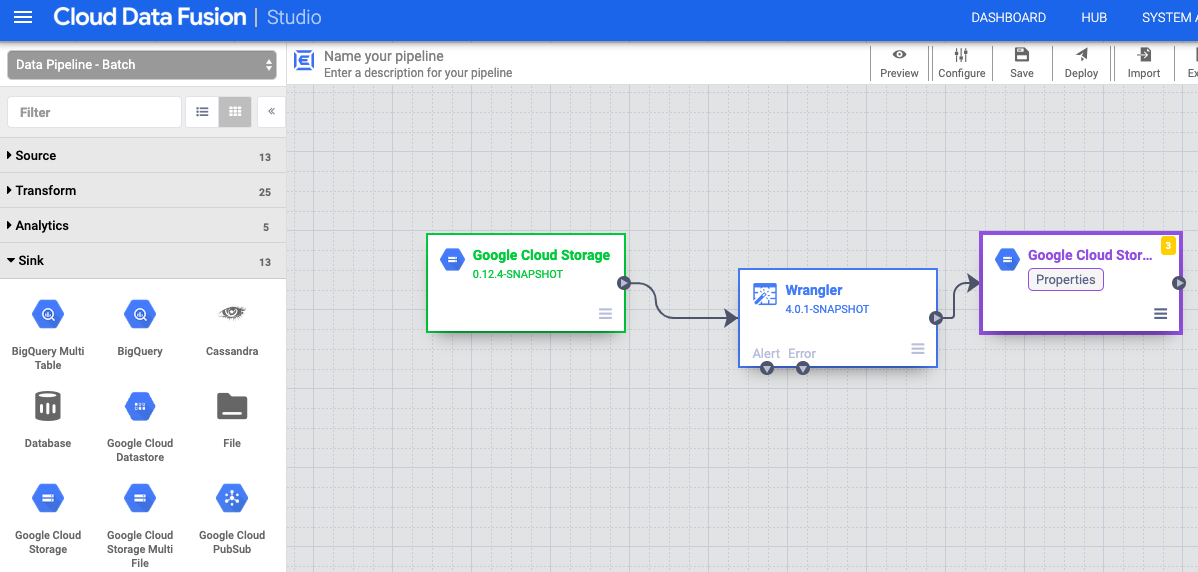
- Buka node sink Cloud Storage di pipeline Anda, lalu klik Properties.
- Di kolom Nama referensi, masukkan nama.
- Di kolom Path, masukkan jalur bucket Cloud Storage di project Anda, tempat pipeline dapat menulis file output. Jika Anda tidak memiliki bucket Cloud Storage, buat bucket.

- Klik Validasi dan perbaiki error yang ada.
- Klik untuk keluar dari dialog Properties.
Menetapkan argumen makro
- Di antarmuka web Cloud Data Fusion, buka pipeline data Anda di halaman Studio.
- Di menu drop-down arrow_drop_down Kondisi dan Tindakan, klik GCS Argument Setter.
- Di kanvas Pipeline Studio, tarik panah dari node Cloud Storage Argument Setter ke node sumber Cloud Storage.
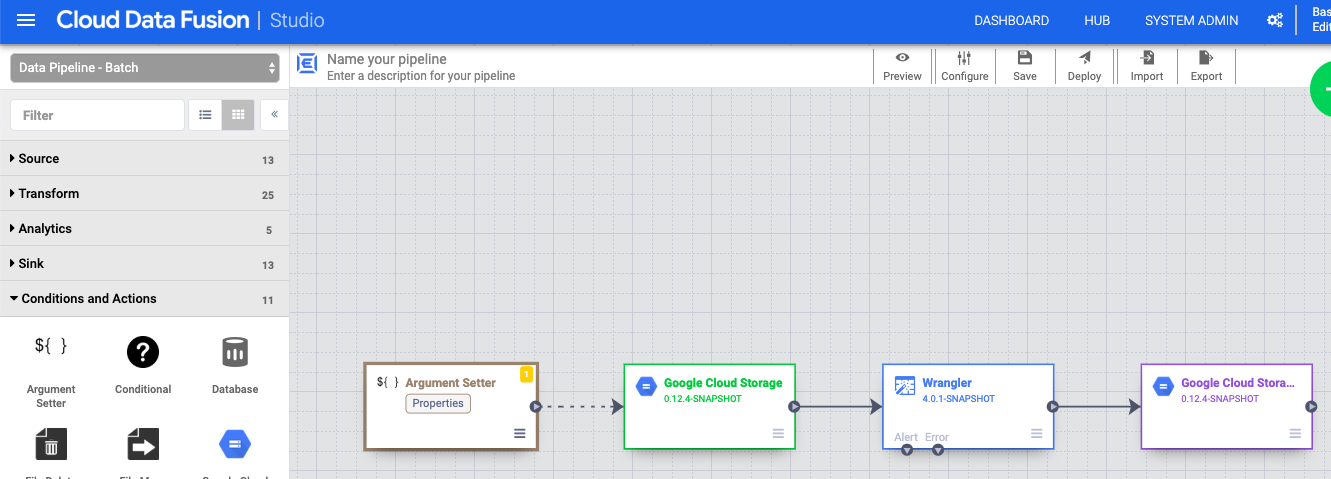
- Buka node Cloud Storage Argument Setter di pipeline Anda, lalu klik Properties.
Di kolom URL, masukkan URL berikut:
gs://reusable-pipeline-tutorial/args.jsonURL sesuai dengan objek yang dapat diakses secara publik di Cloud Storage yang berisi konten berikut:
{ "arguments" : [ { "name": "input.path", "value": "gs://reusable-pipeline-tutorial/user-emails.txt" }, { "name": "directives", "value": "send-to-error !dq:isEmail(body)" } ] }Argumen pertama dari dua argumen adalah nilai untuk
input.path. Jalurgs://reusable-pipeline-tutorial/user-emails.txtadalah objek yang dapat diakses secara publik di Cloud Storage yang berisi data pengujian berikut:alice@example.com bob@example.com craig@invalid@example.comArgumen kedua adalah nilai untuk
directives. Nilaisend-to-error !dq:isEmail(body)mengonfigurasi Wrangler untuk memfilter baris yang bukan alamat email yang valid. Misalnya,craig@invalid@example.comdikecualikan.Klik Validasi untuk memastikan tidak ada error.
Klik untuk keluar dari dialog Properties.
Men-deploy dan menjalankan pipeline
Di panel atas halaman Pipeline Studio, klik Beri nama pipeline Anda. Beri nama pipeline Anda, lalu klik Simpan.
Klik Deploy.
Untuk membuka Runtime Arguments dan melihat argumen makro (runtime)
input.pathdandirectives, klik drop-down arrow_drop_down di samping Run.Biarkan kolom nilai kosong untuk memberi tahu Cloud Data Fusion bahwa node Cloud Storage Argument Setter di pipeline akan menetapkan nilai argumen ini selama runtime.

Klik Run.