Linhagem de dados do Cloud Data Fusion
Pode usar a linhagem de dados do Cloud Data Fusion para fazer o seguinte:
Detetar a causa principal de eventos de dados incorretos.
Faça uma análise de impacto antes de fazer alterações aos dados.
Recomendamos que use a integração da linhagem de recursos no catálogo universal do Dataplex. Para mais informações, consulte o artigo Veja a linhagem no catálogo universal do Dataplex.
Também pode ver a linhagem ao nível do conjunto de dados e do campo no Cloud Data Fusion Studio através da opção Metadados, que mostra a linhagem para um intervalo de tempo selecionado.
A linhagem ao nível do conjunto de dados mostra a relação entre conjuntos de dados e pipelines.
A linhagem ao nível do campo mostra as operações que foram realizadas num conjunto de campos no conjunto de dados de origem para produzir um conjunto de campos diferente no conjunto de dados de destino.
A partir do Cloud Data Fusion 6.9.2.4, se não acompanhar a linhagem no Cloud Data Fusion, recomendamos que desative a emissão de linhagem ao nível do campo na sua instância através do método patch:
curl -X PATCH -H 'Content-Type: application/json' -H "Authorization: Bearer
$(gcloud auth print-access-token)"
'https://datafusion.googleapis.com/v1beta1/projects/PROJECT_ID/locations/REGION/instances/INSTANCE_ID?updateMask=options'
-d '{ "options": { "metadata.messaging.field.lineage.emission.enabled": "false" } }'
Substitua o seguinte:
PROJECT_ID: o Google Cloud ID do projetoREGION: a localização do Google Cloud projetoINSTANCE_ID: o ID da instância do Cloud Data Fusion
Cenário do tutorial
Neste tutorial, vai trabalhar com dois pipelines:
O pipeline
Shipment Data Cleansinglê dados de envio não processados de um pequeno conjunto de dados de amostra e aplica transformações para limpar os dados.Em seguida, o pipeline
Delayed Shipments USAlê os dados de envio limpos, analisa-os e encontra envios nos EUA que foram atrasados mais do que um limite.
Estes pipelines de tutoriais demonstram um cenário típico em que os dados não processados são limpos e, em seguida, enviados para processamento a jusante. Este rasto de dados, desde os dados não processados aos dados de envio limpos e ao resultado analítico, pode ser explorado através da funcionalidade de linhagem do Cloud Data Fusion.
Objetivos
- Produza a linhagem executando pipelines de exemplo
- Explore a linhagem ao nível do conjunto de dados e do campo
- Saiba como transmitir informações de sincronização do pipeline a montante para o pipeline a jusante
Custos
Neste documento, usa os seguintes componentes faturáveis do Google Cloud:
- Cloud Data Fusion
- Cloud Storage
- BigQuery
Para gerar uma estimativa de custos com base na sua utilização projetada,
use a calculadora de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, Cloud Storage, Dataproc, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Crie uma instância do Cloud Data Fusion.
- Clique nos seguintes links para transferir estes pequenos conjuntos de dados de amostra para o seu computador local:
Abra a IU do Cloud Data Fusion
Quando usa o Cloud Data Fusion, usa a Google Cloud consola e a IU do Cloud Data Fusion separada. Na Google Cloud consola, pode criar um Google Cloud projeto da consola e criar e eliminar instâncias do Cloud Data Fusion. Na IU do Cloud Data Fusion, pode usar as várias páginas, como Linha de descendência, para aceder às funcionalidades do Cloud Data Fusion.
Na Google Cloud consola, abra a página Instâncias.
Na coluna Ações da instância, clique no link Ver instância. A IU do Cloud Data Fusion é aberta num novo separador do navegador.
No painel Integrar, clique em Studio para abrir a página Studio do Cloud Data Fusion.
Implemente e execute pipelines
Importe os dados de envio não processados. Na página Studio, clique em Importar ou clique em + > Pipeline > Importar e, de seguida, selecione e importe a pipeline de limpeza de dados de envio que transferiu em Antes de começar.
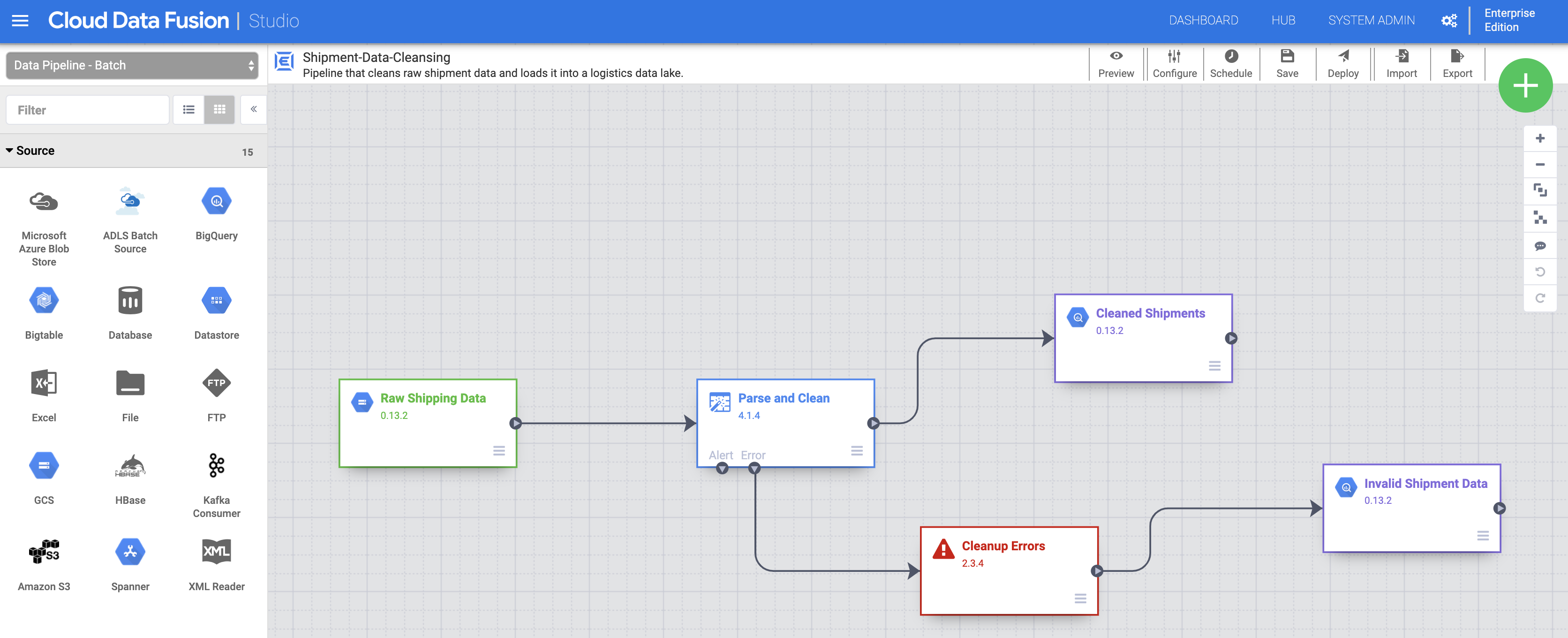
Implemente a conduta. Clique em Implementar na parte superior direita da página do Studio. Após a implementação, é aberta a página Pipeline.
Execute a conduta. Clique em Executar na parte superior central da página Pipeline.
Importe, implemente e execute os dados e o pipeline de envios atrasados. Depois de o estado da limpeza de dados de envio mostrar Concluído, aplique os passos anteriores aos dados de envios atrasados dos EUA que transferiu em Antes de começar. Regresse à página do Studio para importar os dados e, em seguida, implemente e execute este segundo pipeline a partir da página Pipeline. Depois de o segundo pipeline ser concluído com êxito, avance para os passos restantes.
Descubra conjuntos de dados
Tem de descobrir um conjunto de dados antes de explorar a respetiva linhagem. Selecione Metadados no painel de navegação do lado esquerdo da IU do Cloud Data Fusion para abrir a página de pesquisa de metadados. Uma vez que o conjunto de dados de limpeza de dados de envio especificou Cleaned-Shipments como o conjunto de dados de referência, insira shipment na caixa de pesquisa. Os resultados da pesquisa incluem este conjunto de dados.
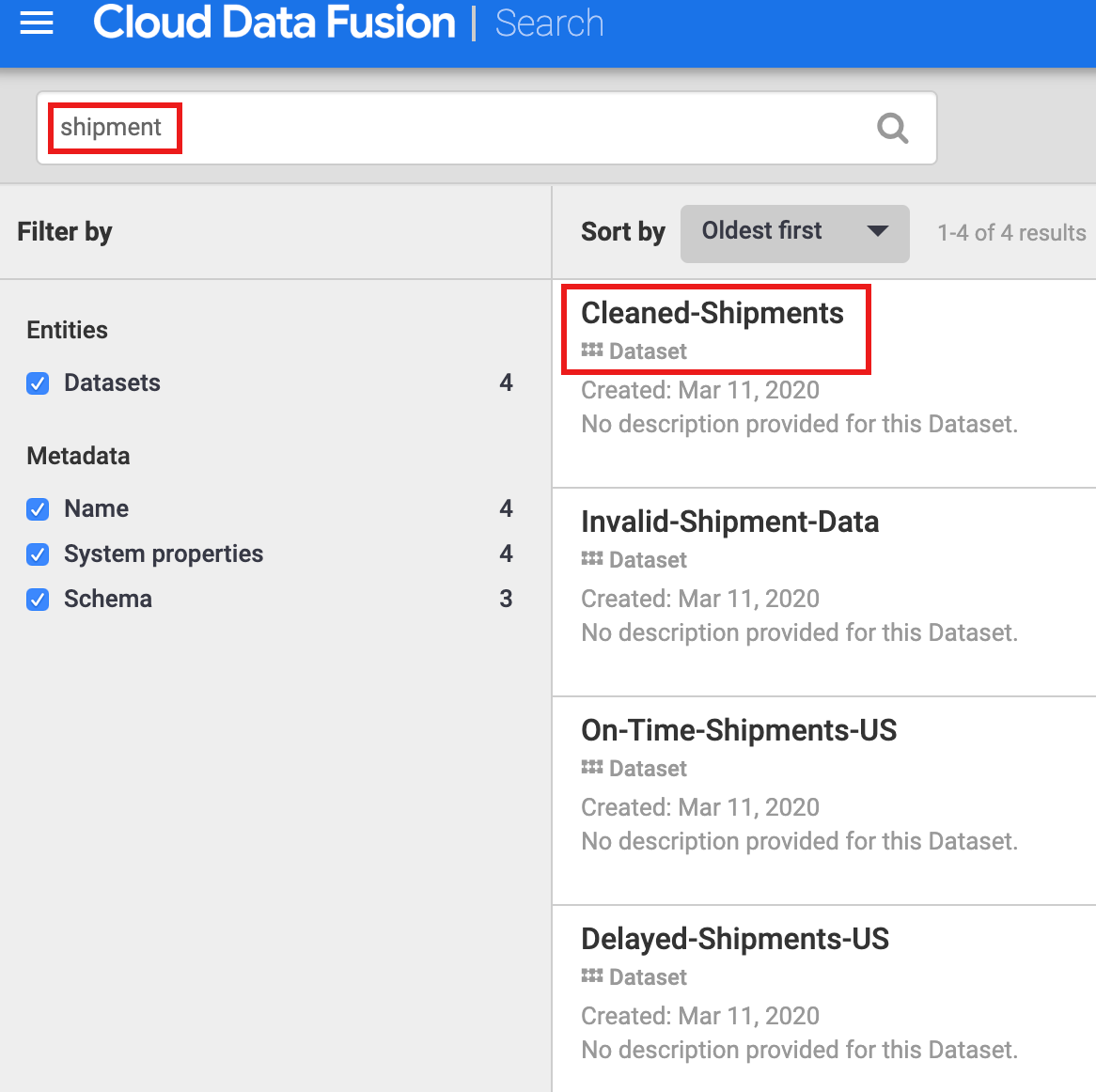
Usar etiquetas para descobrir conjuntos de dados
Uma pesquisa de metadados descobre conjuntos de dados que foram consumidos, processados ou gerados por pipelines do Cloud Data Fusion. Os pipelines são executados num framework estruturado que gera e recolhe metadados técnicos e operacionais. Os metadados técnicos incluem o nome, o tipo, o esquema, os campos, a hora de criação e as informações de processamento do conjunto de dados. Estas informações técnicas são usadas pelas funcionalidades de pesquisa de metadados e linhagem do Cloud Data Fusion.
O Cloud Data Fusion também suporta a anotação de conjuntos de dados com metadados empresariais, como etiquetas e propriedades de chave-valor, que podem ser usados como critérios de pesquisa. Por exemplo, para adicionar e pesquisar uma anotação de etiqueta de empresa no conjunto de dados de dados de envio não processados:
Clique no botão Propriedades do nó de dados de envio não processados na página de pipeline de limpeza de dados de envio para abrir a página Propriedades do Cloud Storage.
Clique em Ver metadados para abrir a página Pesquisa.
Em Etiquetas da empresa, clique em + e, de seguida, insira um nome de etiqueta (são permitidos carateres alfanuméricos e sublinhados) e prima Enter.

Explore a linhagem
Linhagem ao nível do conjunto de dados
Clique no nome do conjunto de dados Cleaned-Shipments apresentado na página de pesquisa (a partir de Descobrir conjuntos de dados) e, de seguida, clique no separador Linhagem. O gráfico de linhagem mostra que este conjunto de dados foi gerado pelo pipeline de limpeza de dados de envios, que tinha consumido o conjunto de dados Raw_Shipping_Data.
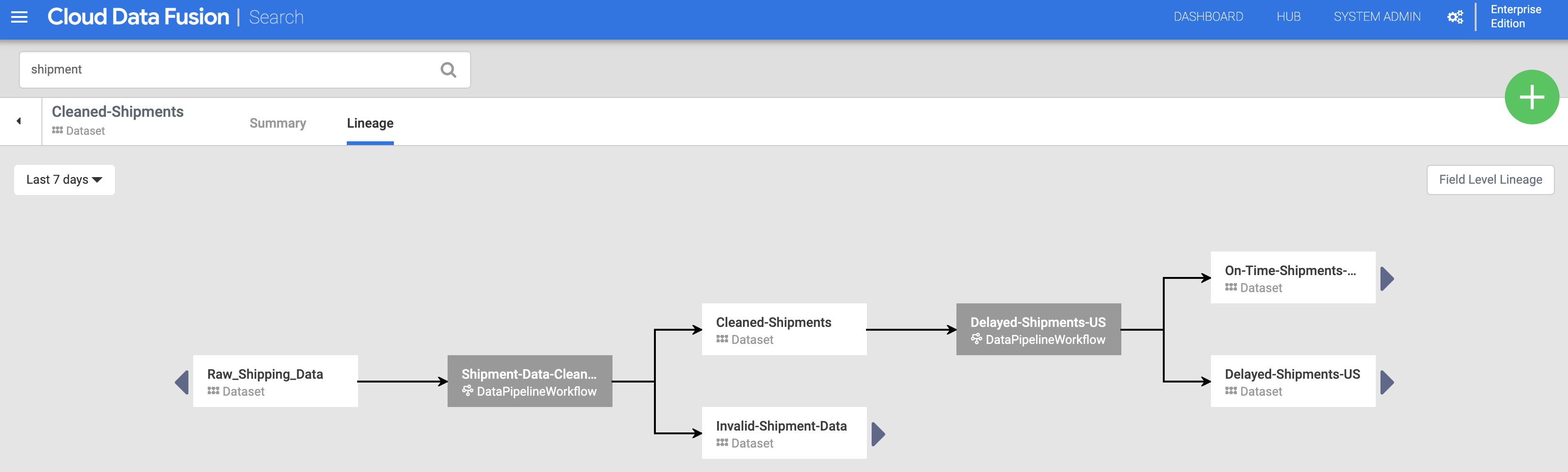
As setas para a esquerda e para a direita permitem-lhe navegar para trás e para a frente na linhagem de qualquer conjunto de dados anterior ou subsequente. Neste exemplo, o gráfico apresenta a linhagem completa do conjunto de dados Cleaned-Shipments.
Linha de descendência ao nível do campo
A linhagem ao nível do campo do Cloud Data Fusion mostra a relação entre os campos de um conjunto de dados e as transformações que foram realizadas num conjunto de campos para produzir um conjunto de campos diferente. Tal como a linhagem ao nível do conjunto de dados, a linhagem ao nível do campo está limitada no tempo e os respetivos resultados mudam com o tempo.
Continuando a partir do passo Relação de dependência ao nível do conjunto de dados, clique no botão Relação de dependência ao nível do campo na parte superior direita do gráfico de relação de dependência ao nível do conjunto de dados Cleaned Shipments para apresentar o respetivo gráfico de relação de dependência ao nível do campo.
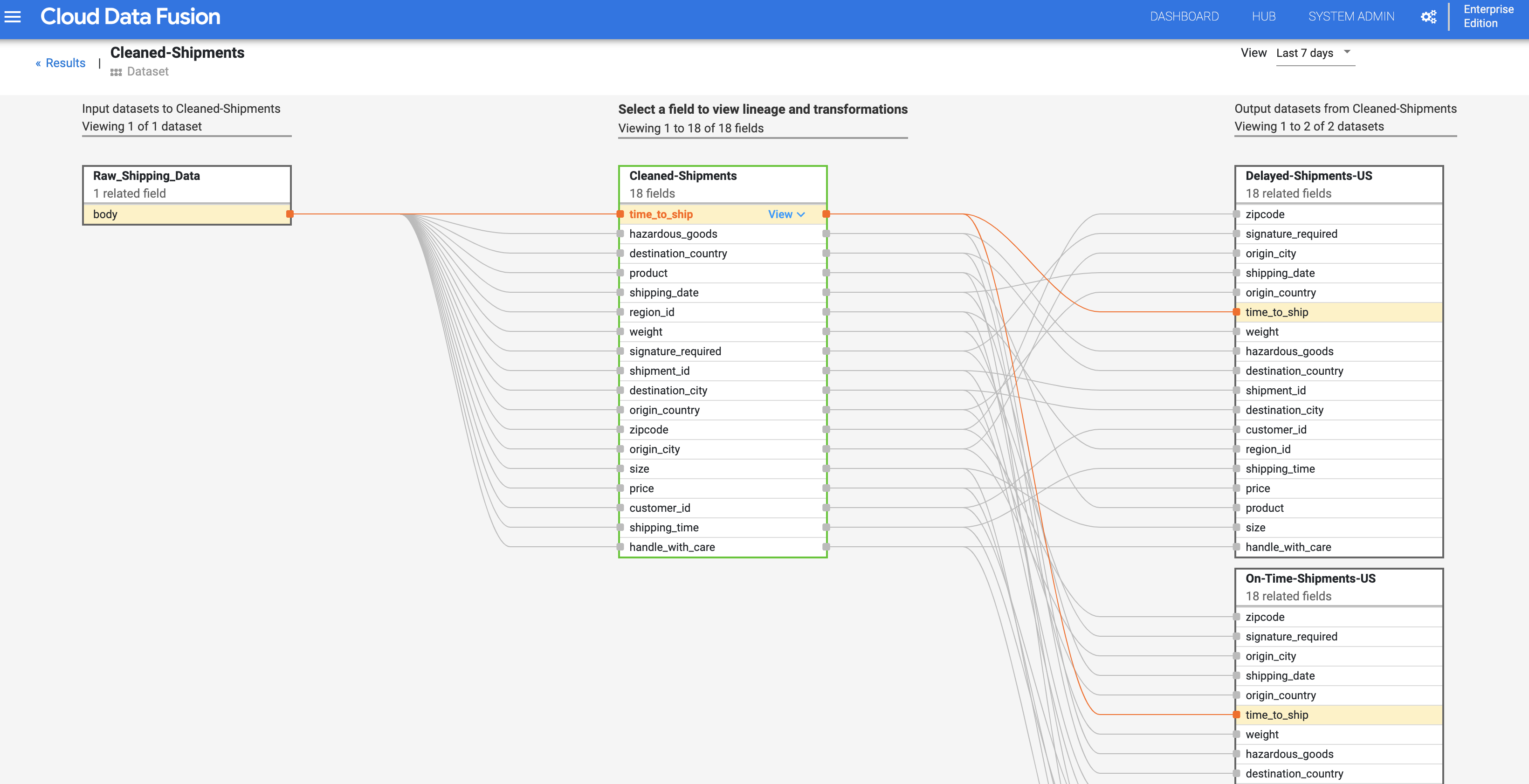
O gráfico de linhagem ao nível do campo mostra as associações entre campos. Pode selecionar um campo para ver a respetiva linhagem. Selecione Ver > Fixar campo para ver apenas a linhagem desse campo.
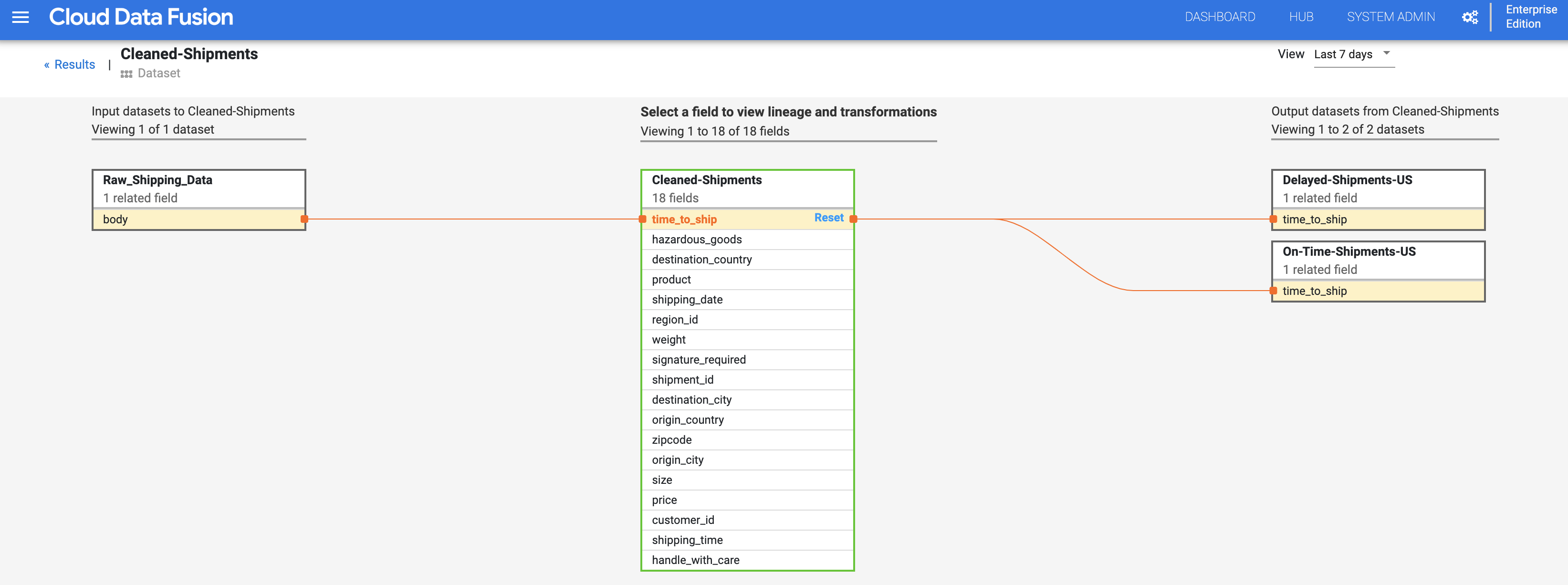
Selecione Ver > Ver impacto para fazer uma análise de impacto.

Os links de causa e efeito mostram as transformações realizadas em ambos os lados de um campo num formato de registo legível por humanos. Estas informações podem ser essenciais para relatórios e governação.
Limpar
Para evitar incorrer em custos na sua conta do Google Cloud pelos recursos usados neste tutorial, elimine o projeto que contém os recursos ou mantenha o projeto e elimine os recursos individuais.
Depois de concluir o tutorial, limpe os recursos que criou no Google Cloud para que não ocupem quota e não lhe sejam cobrados no futuro. As secções seguintes descrevem como eliminar ou desativar estes recursos.
Elimine o conjunto de dados do tutorial
Este tutorial cria um conjunto de dados logistics_demo com várias tabelas no seu projeto.
Pode eliminar o conjunto de dados da IU Web do BigQuery na Google Cloud consola.
Elimine a instância do Cloud Data Fusion
Siga as instruções para eliminar a sua instância do Cloud Data Fusion.
Elimine o projeto
A forma mais fácil de eliminar a faturação é eliminar o projeto que criou para o tutorial.
Para eliminar o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
O que se segue?
- Leia os guias de instruções
- Trabalhe noutro tutorial