Linaje de datos de Cloud Data Fusion
Puedes usar el linaje de datos de Cloud Data Fusion para hacer lo siguiente:
Detectar la causa raíz de eventos de datos incorrectos
Realiza un análisis de impacto antes de realizar cambios en los datos.
Te recomendamos que uses la integración del linaje de recursos en Dataplex Universal Catalog. Para obtener más información, consulta Consulta el linaje en Dataplex Universal Catalog.
También puedes ver el linaje a nivel del conjunto de datos y del campo en Cloud Data Fusion Studio con la opción Metadatos, que muestra el linaje para un período seleccionado.
El linaje a nivel del conjunto de datos muestra la relación entre los conjuntos de datos y las canalizaciones.
El linaje a nivel de campo muestra las operaciones que se realizaron en un conjunto de campos en el conjunto de datos de origen para producir un conjunto diferente de campos en el conjunto de datos de destino.
A partir de la versión 6.9.2.4 de Cloud Data Fusion, si no realizas un seguimiento del linaje en Cloud Data Fusion, te recomendamos que desactives la emisión del linaje a nivel del campo en tu instancia con el método patch:
curl -X PATCH -H 'Content-Type: application/json' -H "Authorization: Bearer
$(gcloud auth print-access-token)"
'https://datafusion.googleapis.com/v1beta1/projects/PROJECT_ID/locations/REGION/instances/INSTANCE_ID?updateMask=options'
-d '{ "options": { "metadata.messaging.field.lineage.emission.enabled": "false" } }'
Reemplaza lo siguiente:
PROJECT_ID: El ID del proyecto de Google CloudREGION: Es la ubicación del proyecto de Google Cloud .INSTANCE_ID: El ID de la instancia de Cloud Data Fusion
Situación del instructivo
En este instructivo, trabajarás con dos canalizaciones:
La canalización
Shipment Data Cleansinglee los datos de envío sin procesar de un conjunto de datos de muestra pequeño y aplica transformaciones para limpiar los datos.Luego, la canalización
Delayed Shipments USAlee los datos de envío limpios, los analiza y encuentra los envíos dentro de EE.UU. que se retrasaron por más de un límite.
Estas canalizaciones de instructivos demuestran una situación típica en la que los datos sin procesar se limpian y, luego, se envían para el procesamiento posterior. Esta ruta de datos, desde datos sin procesar hasta datos de envío limpios a resultados analíticos, se puede explorar con la característica de linaje de Cloud Data Fusion.
Objetivos
- Genera linaje ejecutando canalizaciones de muestra
- Explorar linaje de nivel de conjunto de datos y campo
- Aprender a pasar información de protocolo de enlace de la canalización ascendente a la canalización descendente
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
- Cloud Data Fusion
- Cloud Storage
- BigQuery
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, Cloud Storage, Dataproc, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Crea una instancia de Cloud Data Fusion.
- Haz clic en los vínculos siguientes para descargar estos pequeños conjuntos de datos de muestra a tu máquina local:
Abre la IU de Cloud Data Fusion
Cuando usas Cloud Data Fusion, usas la Google Cloud consola y la IU independiente de Cloud Data Fusion. En la Google Cloud consola, puedes crear un Google Cloud proyecto de consola, y crear y borrar instancias de Cloud Data Fusion. En la IU de Cloud Data Fusion, puedes usar las distintas páginas, como Lineage, para acceder a las características de Cloud Data Fusion.
En la consola de Google Cloud , abre la página Instancias.
En la columna Acciones de la instancia, haz clic en el vínculo Ver instancia. La IU de Cloud Data Fusion se abrirá en una pestaña nueva del navegador.
En el panel Integrar, haz clic en Studio para abrir la página Studio de Cloud Data Fusion.
Implementa y ejecuta canalizaciones
Importa los datos de envío sin procesar. En la página Studio, haz clic en Importar o en + > Canalización > Importar y, luego, selecciona e importa la canalización de limpieza de datos de envío que descargaste en Antes de comenzar.
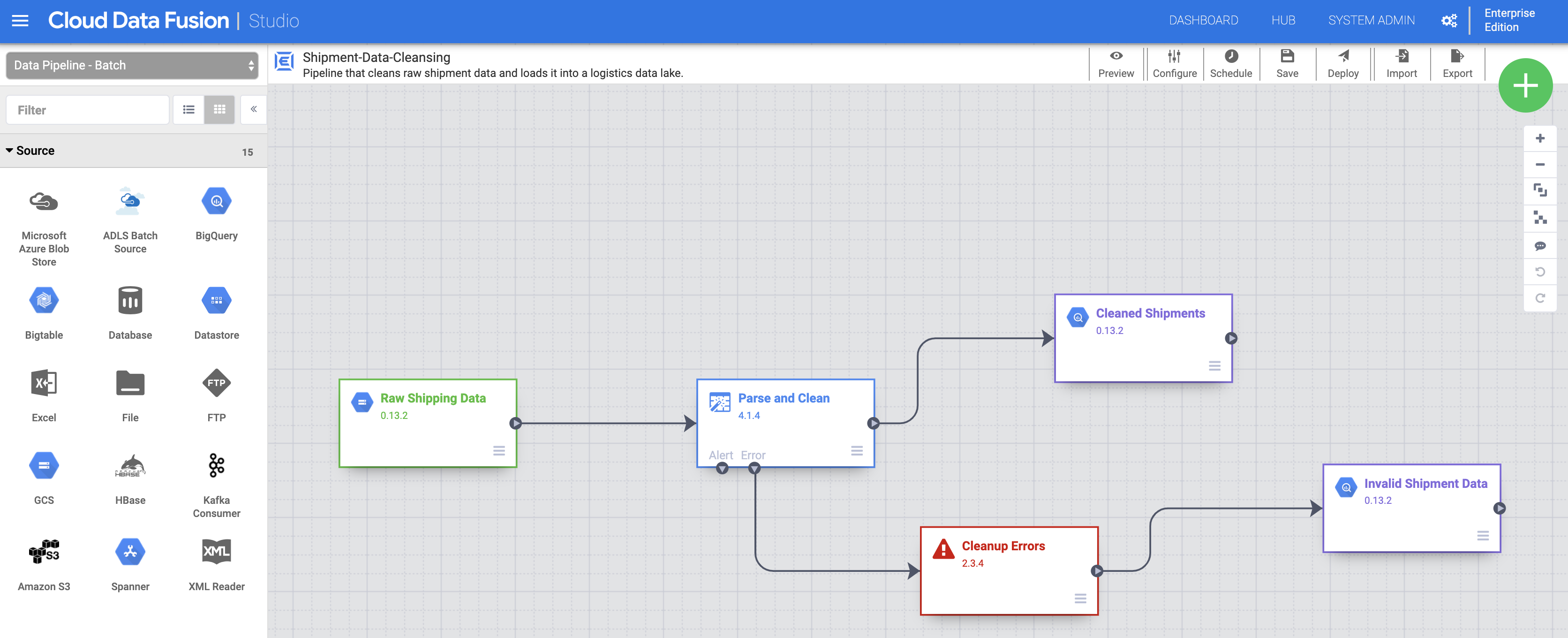
Implementa la canalización. Haz clic en Implementar en la parte superior derecha de la página Studio. Después de la implementación, se abrirá la página de Canalización.
Ejecutar la canalización. Haga clic en Ejecutar en la parte superior central de la página Canalización.
Importa, implementa y ejecuta los datos y la canalización de envíos retrasados. Después de que el estado de Limpieza de datos de envío muestre el estado Correcto, aplica los pasos anteriores para los datos de envíos retrasados de EE.UU. que descargaste en Antes de comenzar. Regresa a la página Studio para importar los datos y, luego, implementa y ejecuta esta segunda canalización desde la página Canalización. Después de que la segunda canalización se complete correctamente, continúa con los pasos restantes.
Descubre conjuntos de datos
Debes descubrir un conjunto de datos antes de explorar su linaje. Selecciona Metadatos del panel de navegación izquierdo de la IU de Cloud Data Fusion para abrir la página de Búsqueda de metadatos. Dado que el conjunto de datos de limpieza de datos de envío especificó Cleaned-Shipments como el conjunto de datos de referencia, inserta envío en el cuadro de búsqueda. Los resultados de la búsqueda incluyen este conjunto de datos.
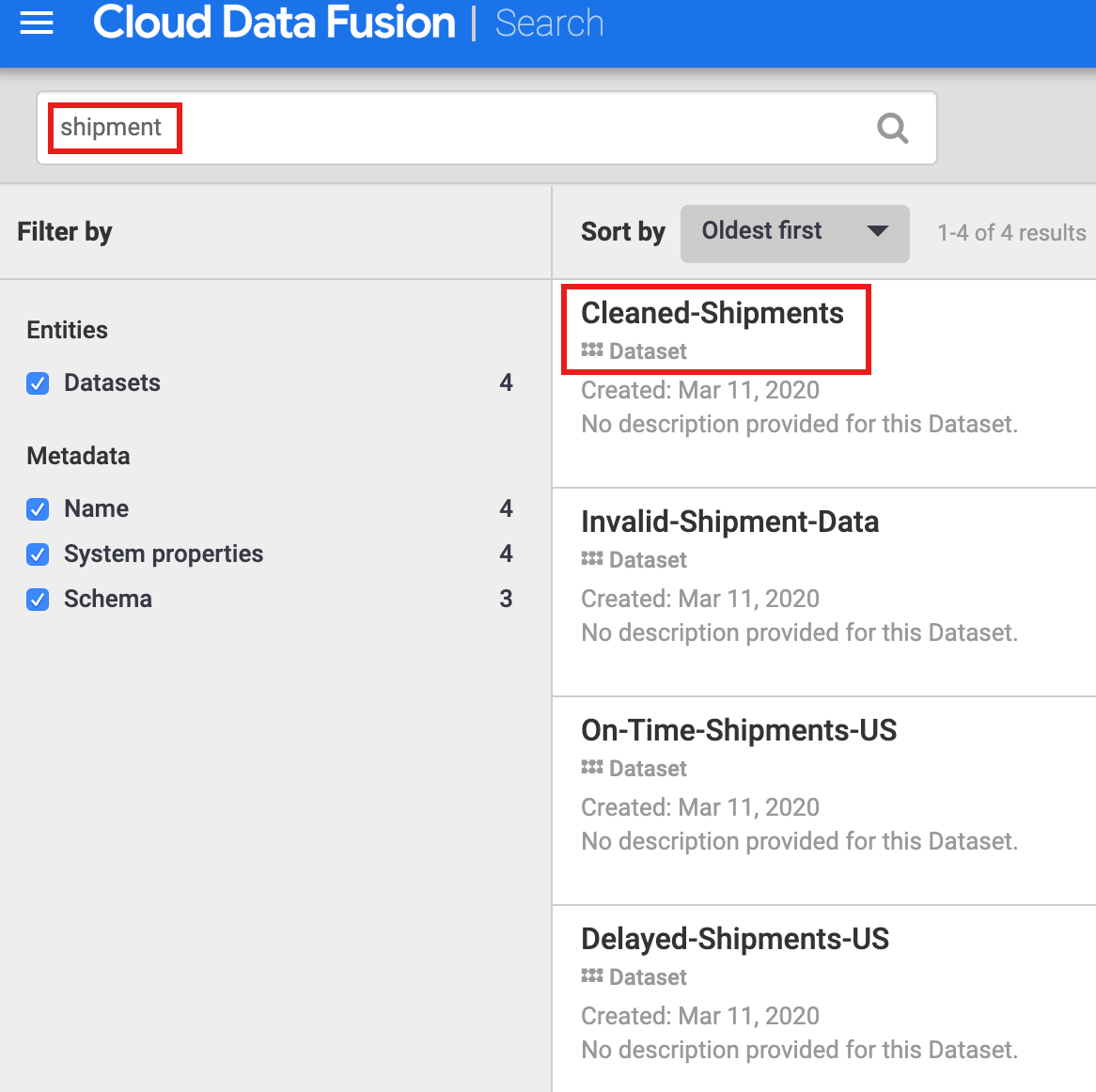
Usa etiquetas para descubrir conjuntos de datos
Una búsqueda de metadatos descubre conjuntos de datos que se usaron, procesaron o generaron mediante las canalizaciones de Cloud Data Fusion. Las canalizaciones se ejecutan en un framework estructurado que genera y recopila metadatos técnicos y operativos. Los metadatos técnicos incluyen el nombre del conjunto de datos, el tipo, el esquema, los campos, la fecha de creación y la información de procesamiento. La información técnica y el linaje de los metadatos de Cloud Data Fusion usan esta información técnica.
Cloud Data Fusion también admite la anotación de conjuntos de datos con metadatos empresariales, como etiquetas y propiedades de clave-valor, que se pueden usar como criterios de búsqueda. Por ejemplo, para agregar y buscar una anotación de etiqueta de la empresa en el conjunto de datos de envío sin procesar, haz lo siguiente:
Haz clic en el botón Propiedades del nodo de datos de envío sin procesar en la página Canalización de limpieza de datos de envío para abrir la página Propiedades de Cloud Storage.
Haz clic en Ver metadatos para abrir la página Buscar.
En Etiquetas comerciales, haz clic en + y, luego, inserta el nombre de una etiqueta (se permiten los caracteres alfanuméricos y los guiones bajos) y presiona Intro.

Explora el linaje
Linaje a nivel de conjunto de datos
Haz clic en el nombre del conjunto de datos Cleaned-Shipments que aparece en la página de búsqueda (de Descubre conjuntos de datos) y, a continuación, haz clic en la pestaña Lineage. El grafo de linaje muestra que este conjunto de datos lo generó la canalización Shipments-Data-Cleansing, que había consumido el conjunto de datos Raw_Shipping_Data.

Las flechas hacia la izquierda y hacia la derecha te permiten navegar hacia atrás y hacia delante en cualquier linaje anterior o posterior del conjunto de datos. En este ejemplo, el grafo muestra el linaje completo para el conjunto de datos Cleaned-Shipments.
Linaje a nivel del campo
El linaje de nivel de campo de Cloud Data Fusion muestra la relación entre los campos de un conjunto de datos y las transformaciones que se realizaron en un conjunto de campos para producir un conjunto de campos diferente. Al igual que el linaje de nivel de conjunto de datos, el linaje a nivel de campo está restringido, y sus resultados cambian con el tiempo.
Para continuar con el paso linaje a nivel de conjunto de datos, haz clic en el botón de Linaje a nivel de campo en la parte superior derecha del grafo de linaje a nivel de conjunto de datos limpios de envío para mostrar su grafo de linaje de nivel de campo.
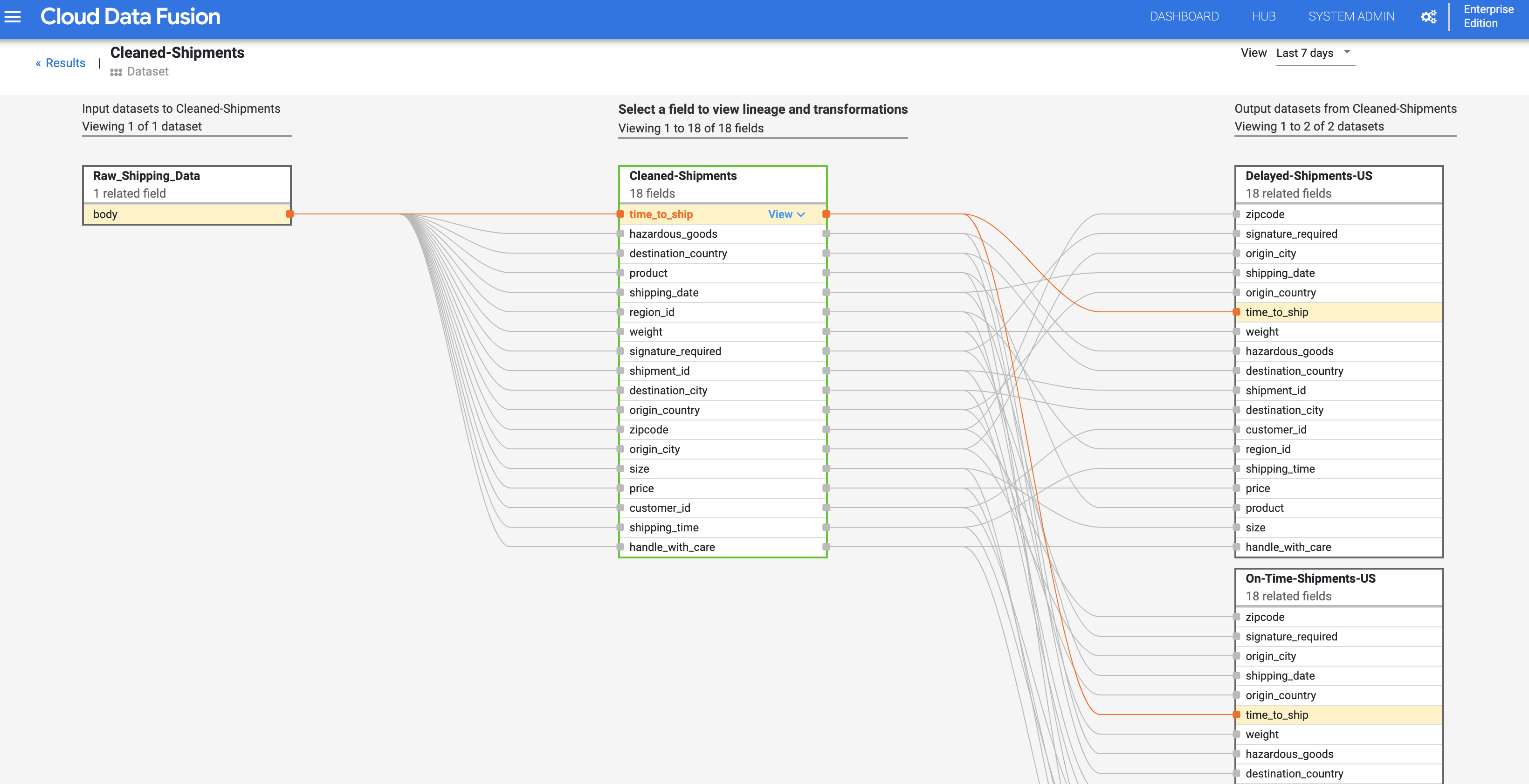
El grafo de linaje a nivel de campo muestra las conexiones entre campos. Puedes seleccionar un campo para ver su linaje. Selecciona Ver > Fijar campo para ver solo el linaje de ese campo.
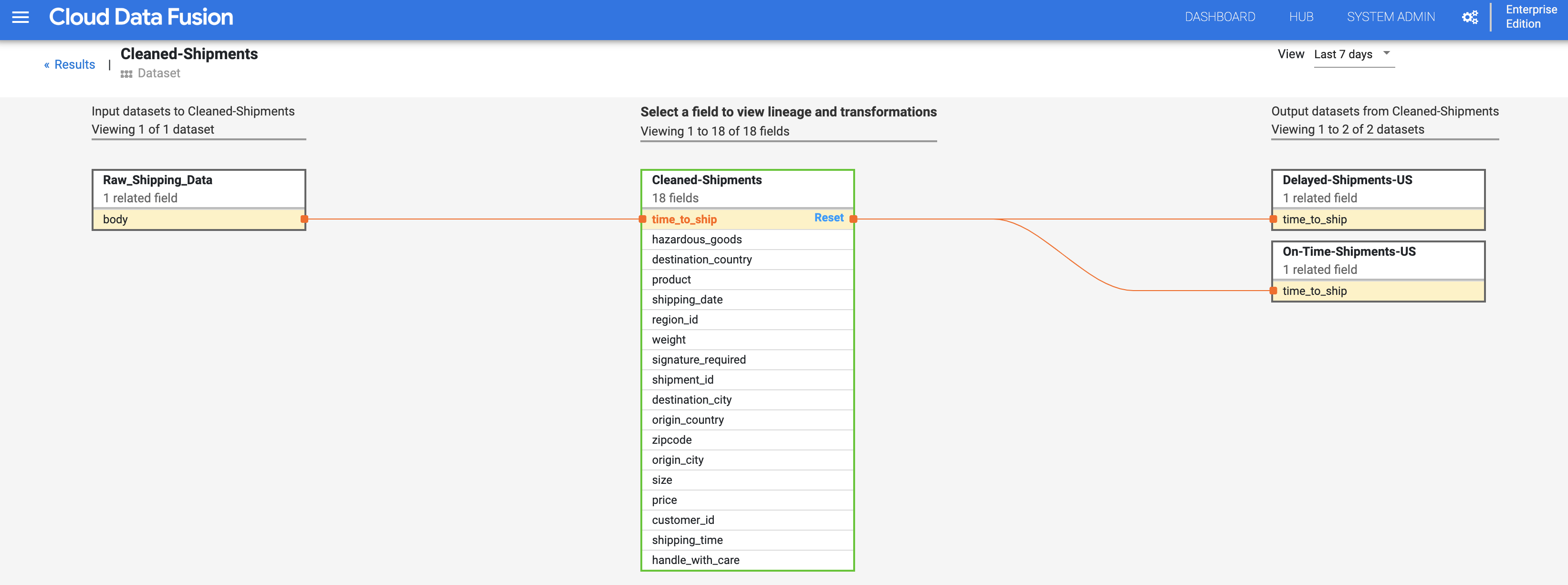
Selecciona Ver > Ver impacto para realizar un análisis de impacto.

Los vínculos de impacto y causa muestran las transformaciones que se realizan en ambos lados de un campo en un formato de registro legible. Esta información puede ser fundamental para la generación de informes y la administración.
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Una vez que terminaste el instructivo, limpia los recursos que creaste enGoogle Cloud para que no consuman tu cuota y no se te facturen en el futuro. En las siguientes secciones, se describe cómo borrar o desactivar estos recursos.
Borra el conjunto de datos del instructivo
En este instructivo, se crea un conjunto de datos logistics_demo con varias tablas en el proyecto.
Puedes borrar el conjunto de datos de la IU web de BigQuery en la Google Cloud consola.
Borra la instancia de Cloud Data Fusion
Sigue las instrucciones para borrar tu instancia de Cloud Data Fusion.
Borra el proyecto
La manera más fácil de eliminar la facturación es borrar el proyecto que creaste para el instructivo.
Para borrar el proyecto, sigue estos pasos:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
¿Qué sigue?
- Lee las guías prácticas.
- Completa otro instructivo