Questa pagina descrive come attivare la replica in tempo reale dei dati dalle applicazioni SAP Google Cloud utilizzando SAP Landscape Transformation (SLT). I contenuti si applicano ai plug-in SAP SLT Replication e SAP SLT No RFC Replication, disponibili nell'hub Cloud Data Fusion. Mostra le configurazioni per il sistema di origine SAP, SLT, Cloud Storage e Cloud Data Fusion per eseguire le seguenti operazioni:
- Esegui il push dei metadati e dei dati di tabella SAP in Google Cloud utilizzando SAP SLT.
- Crea un job di replica Cloud Data Fusion che legga i dati da un bucket Cloud Storage.
La replica SAP SLT ti consente di replicare i tuoi dati in modo continuo e in tempo reale dalle origini SAP in BigQuery. Puoi configurare ed eseguire trasferimenti di dati dai sistemi SAP senza programmazione.
Il processo di replica SLT di Cloud Data Fusion è il seguente:
- I dati provengono da un sistema SAP di origine.
- SLT monitora e legge i dati e li invia a Cloud Storage.
- Cloud Data Fusion estrae i dati dal bucket di archiviazione e li scrive in BigQuery.
Puoi trasferire dati da sistemi SAP supportati, inclusi i sistemi SAP ospitati in Google Cloud.
Per ulteriori informazioni, consulta la Panoramica di SAP su Google Cloud e i dettagli sull'assistenza.
Prima di iniziare
Per utilizzare questo plug-in, devi avere conoscenze di dominio nelle seguenti aree:
- Creazione di pipeline in Cloud Data Fusion
- Gestione dell'accesso con IAM
- Configurazione di sistemi ERP (Enterprise Resource Planning) on-premise e SAP Cloud
Amministratori e utenti che eseguono le configurazioni
Le attività in questa pagina vengono eseguite da persone con i seguenti ruoli in Google Cloud o nel sistema SAP:
| Tipo di utente | Descrizione |
|---|---|
| Amministratore Google Cloud | Gli utenti a cui è assegnato questo ruolo sono amministratori degli account Google Cloud. |
| Utente Cloud Data Fusion | Gli utenti a cui è assegnato questo ruolo sono autorizzati a progettare ed eseguire
pipeline di dati. Devono disporre almeno del ruolo Visualizzatore Data Fusion
(
roles/datafusion.viewer). Se utilizzi
il controllo degli accessi basato sui ruoli, potresti avere bisogno di
altri
ruoli.
|
| Amministratore SAP | Gli utenti a cui è assegnato questo ruolo sono amministratori del sistema SAP. Hanno accesso per scaricare il software dal sito del servizio SAP. Non è un ruolo IAM. |
| Utente SAP | Gli utenti a cui è assegnato questo ruolo sono autorizzati a connettersi a un sistema SAP. Non è un ruolo IAM. |
Operazioni di replica supportate
Il plug-in SAP SLT Replication supporta le seguenti operazioni:
Modellazione dei dati: tutte le operazioni di modellazione dei dati (record insert, delete e
update) sono supportate da questo plug-in.
Definizione dei dati: come descritto nella nota SAP 2055599 (è necessario accedere all'assistenza SAP per visualizzarla), esistono limitazioni relative alle modifiche alla struttura delle tabelle del sistema di origine che vengono replicate automaticamente da SLT. Alcune operazioni di definizione dei dati non sono supportate nel plug-in (devi propagarle manualmente).
- Supportato:
- Aggiungi un campo non chiave (dopo aver apportato modifiche in SE11, attiva la tabella utilizzando SE14)
- Non supportato:
- Aggiungere/eliminare il campo della chiave
- Eliminare un campo non chiave
- Modificare i tipi di dati
Requisiti SAP
Nel sistema SAP sono richiesti i seguenti elementi:
- È installata la versione 2011 SP17 o successiva di SLT Server sul sistema SAP di origine (incorporato) o come sistema hub SLT dedicato.
- Il sistema SAP di origine è SAP ECC o SAP S/4HANA, che supporta DMIS 2011 SP17 o versioni successive, ad esempio DMIS 2018, DMIS 2020.
- Il componente aggiuntivo dell'interfaccia utente SAP deve essere compatibile con la versione di SAP Netweaver.
Il tuo pacchetto di assistenza supporta la classe
/UI2/CL_JSONPL 12o versioni successive. In caso contrario, implementa la nota SAP più recente per la classe/UI2/CL_JSONcorrectionsin base alla versione del componente aggiuntivo dell'interfaccia utente, ad esempio la nota SAP 2798102 perPL12.Sono state adottate le seguenti misure di sicurezza:
Requisiti di Cloud Data Fusion
- È necessaria un'istanza Cloud Data Fusion, versione 6.4.0 o successive, di qualsiasi edizione.
- All'account di servizio assegnato all'istanza Cloud Data Fusion vengono assegnati i ruoli richiesti (vedi Concedere l'autorizzazione utente all'account di servizio).
- Per le istanze private di Cloud Data Fusion, è necessario il peering VPC.
Requisiti diGoogle Cloud
- Abilita l'API Cloud Storage nel tuo Google Cloud progetto.
- All'utente Cloud Data Fusion deve essere concessa l'autorizzazione per creare cartelle nel bucket Cloud Storage (consulta Ruoli IAM per Cloud Storage).
- (Facoltativo) Imposta il criterio di conservazione, se richiesto dalla tua organizzazione.
Crea il bucket di archiviazione
Prima di creare un job di replica SLT, crea il bucket Cloud Storage. Il job trasferisce i dati al bucket e aggiorna il bucket di staging ogni cinque minuti. Quando esegui il job, Cloud Data Fusion legge i dati nel bucket di archiviazione e li scrive in BigQuery.
Se SLT è installato su Google Cloud
Il server SLT deve disporre dell'autorizzazione per creare e modificare gli oggetti Cloud Storage nel bucket che hai creato.
Concedi almeno i seguenti ruoli all'account di servizio:
- Creatore token account di servizio (
roles/iam.serviceAccountTokenCreator) - Consumer utilizzo dei servizi (
roles/serviceusage.serviceUsageConsumer) - Storage Object Admin (
roles/storage.objectAdmin)
Se SLT non è installato su Google Cloud
Installa Cloud VPN o Cloud Interconnect tra la VM SAP eGoogle Cloud per consentire la connessione a un endpoint dei metadati interno (consulta Configurare l'accesso privato Google per gli host on-premise.
Se non è possibile mappare i metadati interni:
Installa Google Cloud CLI in base al sistema operativo dell'infrastruttura su cui è in esecuzione SLT.
Crea un account di servizio nel Google Cloud progetto in cui è attivato Cloud Storage.
Sul sistema operativo SLT, autorizza l'accesso a Google Cloud con un account di servizio.
Crea una chiave API per l'account di servizio e autorizza lo scopo relativo a Cloud Storage.
Importa la chiave API in gcloud CLI installata in precedenza utilizzando l'interfaccia a riga di comando.
Per attivare il comando gcloud CLI che stampa il token di accesso, configura il comando del sistema operativo SAP nello strumento di transazione SM69 nel sistema SLT.
Stampare un token di accesso
L'amministratore SAP configura il comando del sistema operativo SM69 che recupera un token di accesso da Google Cloud.
Crea uno script per stampare un token di accesso e configura un comando del sistema operativo SAP per chiamare lo script come utente <sid>adm dall'host SAP LT Replication Server.
Linux
Per creare un comando del sistema operativo:
Nell'host SAP LT Replication Server, in una directory accessibile a
<sid>adm, crea uno script bash contenente le seguenti righe:PATH_TO_GCLOUD_CLI/bin/gcloud auth print-access-token SERVICE_ACCOUNT_NAMEUtilizzando l'interfaccia utente di SAP, crea un comando del sistema operativo esterno:
- Inserisci la transazione
SM69. - Fai clic su Crea.
- Nella sezione Comando del riquadro Comando esterno, inserisci il nome del comando, ad esempio
ZGOOGLE_CDF_TOKEN. Nella sezione Definizione:
- Nel campo Comando del sistema operativo, inserisci
shcome estensione del file dello script. Nel campo Parametri per il comando del sistema operativo, inserisci:
/PATH_TO_SCRIPT/FILE_NAME.sh
- Nel campo Comando del sistema operativo, inserisci
Fai clic su Salva.
Per testare lo script, fai clic su Esegui.
Fai di nuovo clic su Esegui.
Un Google Cloud token viene restituito e visualizzato nella parte inferiore del riquadro dell'interfaccia utente di SAP.
- Inserisci la transazione
Windows
Utilizzando l'interfaccia utente SAP, crea un comando del sistema operativo esterno:
- Inserisci la transazione
SM69. - Fai clic su Crea.
- Nella sezione Comando del riquadro Comando esterno, inserisci il nome del comando, ad esempio
ZGOOGLE_CDF_TOKEN. Nella sezione Definizione:
- Nel campo Comando del sistema operativo, inserisci
cmd /c. Nel campo Parametri per il comando del sistema operativo, inserisci:
gcloud auth print-access-token SERVICE_ACCOUNT_NAME
- Nel campo Comando del sistema operativo, inserisci
Fai clic su Salva.
Per testare lo script, fai clic su Esegui.
Fai di nuovo clic su Esegui.
Viene restituito e visualizzato un Google Cloud token nella parte inferiore del riquadro dell'interfaccia utente SAP.
Requisiti SLT
Il connettore SLT deve avere la seguente configurazione:
- Il connettore supporta SAP ECC NW 7.02, DMIS 2011 SP17 e versioni successive.
- Configura una connessione RFC o di database tra SLT e il sistema Cloud Storage.
- Configura i certificati SSL:
- Scarica i seguenti certificati CA dal
repository di Google Trust Services:
- GTS Root R1
- GTS CA 1C3
- Nell'interfaccia utente di SAP, utilizza la transazione
STRUSTper importare i certificati principali e secondari nella cartellaSSL Client (Standard) PSE.
- Scarica i seguenti certificati CA dal
repository di Google Trust Services:
- Internet Communication Manager (ICM) deve essere configurato per HTTPS. Assicurati che le porte HTTP e HTTPS siano gestite e attivate nel sistema SAP SLT.
Questo può essere controllato tramite il codice transazione
SMICM > Services. - Abilita l'accesso alle Google Cloud API sulla VM in cui è ospitato il sistema SAP SLT. In questo modo, viene abilitata la comunicazione privata tra i Google Cloud servizi senza passare per la rete internet pubblica.
- Assicurati che la rete possa supportare il volume e la velocità richiesti per il trasferimento dei dati tra l'infrastruttura SAP e Cloud Storage. Per un'installazione riuscita, sono consigliati Cloud VPN e/o Cloud Interconnect. Il throughput dell'API di streaming dipende dalle quote del cliente che sono state concesse al tuo progetto Cloud Storage.
Configura il server di replica SLT
L'utente SAP esegue i seguenti passaggi.
Nei passaggi seguenti, connetterai il server SLT al sistema di origine e al bucket in Cloud Storage, specificando il sistema di origine, le tabelle di dati da replicare e il bucket di archiviazione di destinazione.
Configurare l'SDK Google ABAP
Per configurare SLT per la replica dei dati (una volta per istanza Cloud Data Fusion), segui questi passaggi:
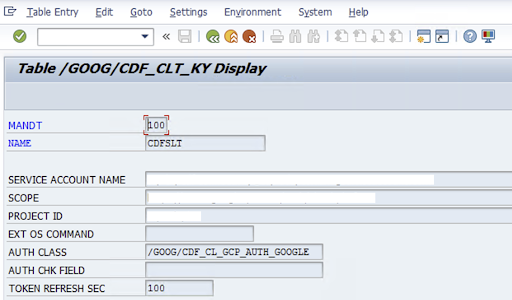
Per configurare il connettore SLT, l'utente SAP inserisce le seguenti informazioni nella schermata di configurazione (Transazione SAP
/GOOG/CDF_SETTINGS) relative alla chiave dell'account di servizio per il trasferimento dei dati in Cloud Storage. Google Cloud Configura le seguenti proprietà nella tabella /GOOG/CDF_CLT_KY utilizzando la transazione SE16 e prendi nota di questa chiave:- NAME: il nome della chiave dell'account di servizio (ad esempio
CDFSLT) - NOME ACCOUNT DI SERVIZIO: il nome dell'account di servizio IAM
- SCOPE: l'ambito dell'account di servizio
- PROJECT_ID: l'ID del tuo Google Cloud progetto
- (Facoltativo) Comando OS EXT: utilizza questo campo solo se SLT non è installato su Google Cloud
AUTH CLASS: se il comando del sistema operativo è configurato nella tabella
/GOOG/CDF_CLT_KY, utilizza il valore fisso/GOOG/CDF_CL_GCP_AUTH.TOKEN REFRESH SEC: durata per l'aggiornamento del token di autorizzazione
- NAME: il nome della chiave dell'account di servizio (ad esempio
Crea la configurazione della replica
Crea una configurazione di replica nel codice transazione: LTRC.
- Prima di procedere con la configurazione LTRC, assicurati che la connessione RFC tra il sistema SLT e il sistema SAP di origine sia stabilita.
- Per una configurazione SLT, potrebbero essere assegnate più tabelle SAP per la replica.
Vai al codice transazione
LTRCe fai clic su Nuova configurazione.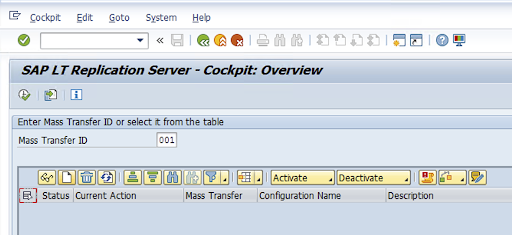
Inserisci il nome della configurazione e la descrizione, poi fai clic su Avanti.
Specifica la connessione RFC del sistema di origine SAP e fai clic su Avanti.
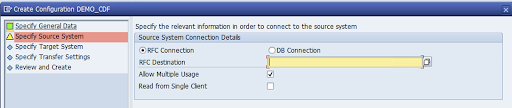
In Dettagli connessione del sistema di destinazione, seleziona Altro.
Espandi il campo Scenario per la comunicazione RFC, seleziona SDK SLT e fai clic su Avanti.
Vai alla finestra Specifica impostazioni trasferimento e inserisci il nome dell'applicazione:
ZGOOGLE_CDF.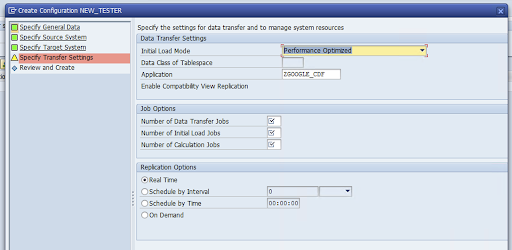
Inserisci il Numero di job di trasferimento dati, il Numero di job di caricamento iniziale e il Numero di job di calcolo. Per ulteriori informazioni sul rendimento, consulta la guida all'ottimizzazione del rendimento di SAP LT Replication Server.
Fai clic su In tempo reale > Avanti.
Rivedi la configurazione e fai clic su Salva. Prendi nota dell'ID trasferimento collettivo per i passaggi successivi.
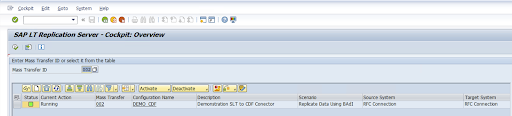
Per mantenere l'ID trasferimento collettivo e i dettagli della tabella SAP, esegui la transazione SAP:
/GOOG/CDF_SETTINGS.Fai clic su Esegui o premi
F8.Crea una nuova voce facendo clic sull'icona Aggiungi riga.
Inserisci l'ID trasferimento collettivo, la chiave di trasferimento collettivo, il nome della chiave Google Cloud e il bucket GCS di destinazione. Seleziona la casella di controllo È attivo e salva le modifiche.
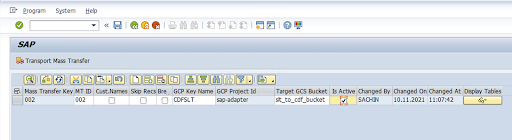
Seleziona la configurazione nella colonna Nome configurazione e fai clic su Provisioning dei dati.
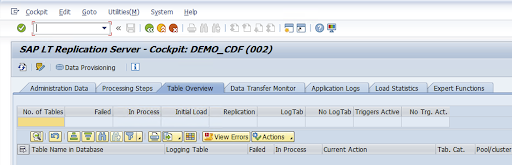
(Facoltativo) Personalizza i nomi delle tabelle e dei campi.
Fai clic su Nomi personalizzati e salva.
Fai clic su Display.
Crea una nuova voce facendo clic sui pulsanti Aggiungi riga o Crea.
Inserisci il nome della tabella SAP e il nome della tabella esterna da utilizzare in BigQuery e salva le modifiche.
Fai clic sul pulsante Visualizza nella colonna Mostra campi per mantenere la mappatura per i campi della tabella.
Viene visualizzata una pagina con le mappature suggerite. (Facoltativo) Modifica Nome campo temp e Descrizione campo, quindi salva le mappature.
Vai alla transazione LTRC.
Seleziona il valore nella colonna Nome configurazione e fai clic su Provisioning dei dati.
Inserisci il nome della tabella nel campo Nome tabella nel database e seleziona lo scenario di replica.
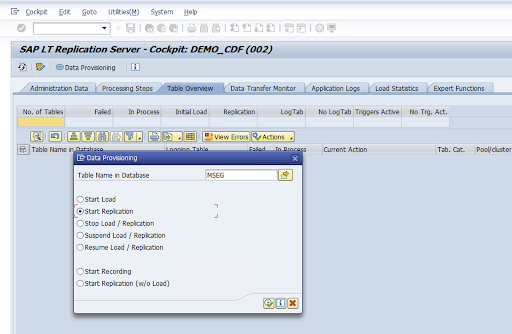
Fai clic su Esegui. Questo attiva l'implementazione dell'SDK SLT e avvia il trasferimento dei dati al bucket di destinazione in Cloud Storage.
Installa i file di trasporto SAP
Per progettare ed eseguire job di replica in Cloud Data Fusion, i componenti SAP vengono caricati come file di trasporto SAP archiviati in un file ZIP. Il download è disponibile quando esegui il deployment del plug-in in Cloud Data Fusion Hub.
Per installare i trasporti SAP:
Passaggio 1: carica i file delle richieste di trasporto
- Accedi al sistema operativo dell'istanza SAP.
- Utilizza il codice transazione SAP
AL11per ottenere il percorso della cartellaDIR_TRANS. In genere, il percorso è/usr/sap/trans/. - Copia i file co nella cartella
DIR_TRANS/cofiles. - Copia i file di dati nella
cartella
DIR_TRANS/data. - Imposta l'utente e il gruppo di dati e del cofile su
<sid>admesapsys.
Passaggio 2: importa i file delle richieste di trasporto
L'amministratore SAP può importare i file di richiesta di trasporto utilizzando il sistema di gestione del trasporto SAP o il sistema operativo:
Sistema di gestione del trasporto SAP
- Accedi al sistema SAP come amministratore SAP.
- Inserisci l'STMS della transazione.
- Fai clic su Panoramica > Importazioni.
- Nella colonna Coda, fai doppio clic sull'ID cliente corrente.
- Fai clic su Extra > Altre richieste > Aggiungi.
- Seleziona l'ID richiesta di trasporto e fai clic su Continua.
- Seleziona la richiesta di trasporto nella coda di importazione e poi fai clic su Richiedi > Importa.
- Inserisci il numero cliente.
Nella scheda Opzioni, seleziona Sostituisci originali e Ignora versione componente non valida (se disponibile).
(Facoltativo) Per importare di nuovo i trasporti in un secondo momento, fai clic su Lascia le richieste di trasporto in coda per l'importazione successiva e su Importa di nuovo le richieste di trasporto. Questa operazione è utile per gli upgrade del sistema SAP e i ripristini dei backup.
Fai clic su Continua.
Verifica che il modulo della funzione e i ruoli di autorizzazione siano stati importati correttamente utilizzando transazioni come
SE80ePFCG.
Sistema operativo
- Accedi al sistema SAP come amministratore SAP.
Aggiungi richieste al buffer di importazione:
tp addtobuffer TRANSPORT_REQUEST_ID SIDAd esempio:
tp addtobuffer IB1K903958 DD1Importa le richieste di trasporto:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238Sostituisci
NNNcon il numero del cliente. Ad esempio:tp import IB1K903958 DD1 client=800 U1238Verifica che il modulo di funzione e i ruoli di autorizzazione siano stati importati correttamente utilizzando le transazioni appropriate, ad esempio
SE80ePFCG.
Autorizzazioni SAP richieste
Per eseguire una pipeline di dati in Cloud Data Fusion, devi avere un utente SAP. L'utente SAP deve essere di tipo Comunicazioni o Dialogo. Per impedire l'utilizzo delle risorse di dialogo SAP, è consigliato il tipo di comunicazione. Gli utenti possono essere creati dall'amministratore SAP utilizzando il codice transazione SAP SU01.
Le autorizzazioni SAP sono necessarie per gestire e configurare il connettore per SAP, una combinazione di oggetti di autorizzazione SAP standard e del nuovo connettore. Gestisci gli oggetti di autorizzazione in base ai criteri di sicurezza della tua organizzazione. Il seguente elenco descrive alcune autorizzazioni importanti necessarie per il connettore:
Oggetto autorizzazione: l'oggetto autorizzazione
ZGOOGCDFMTviene fornito come parte del ruolo Richiesta di trasporto.Creazione del ruolo: crea un ruolo utilizzando il codice transazione
PFCG.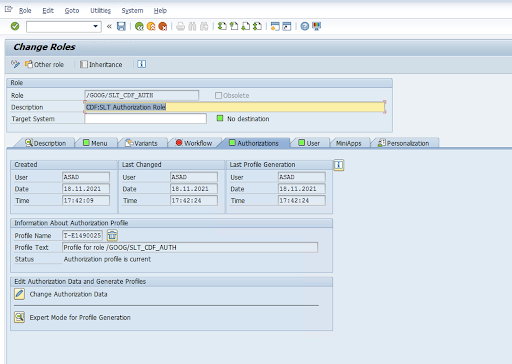
Per gli oggetti di autorizzazione SAP standard, la tua organizzazione gestisce le autorizzazioni con il proprio meccanismo di sicurezza.
Per gli oggetti di autorizzazione personalizzati, fornisci i valori nei campi di autorizzazione per gli oggetti di autorizzazione
ZGOOGCDFMT.Per il controllo granulare dell'accesso,
ZGOOGCDFMTfornisce l'autorizzazione basata su gruppi di autorizzazione. Agli utenti con accesso completo, parziale o nullo ai gruppi di autorizzazione viene fornito l'accesso in base al gruppo di autorizzazione assegnato al loro ruolo./GOOG/SLT_CDF_AUTH: ruolo con accesso a tutti i gruppi di autorizzazione. Per limitare l'accesso specifico a un determinato gruppo di autorizzazione, mantieni il gruppo di autorizzazione FICDF nella configurazione.
Crea una destinazione RFC per l'origine
Prima di iniziare la configurazione, assicurati che la connessione RFC sia stata stabilita tra l'origine e la destinazione.
Vai al codice transazione
SM59.Fai clic su Crea > Tipo di connessione 3 (connessione ABAP).
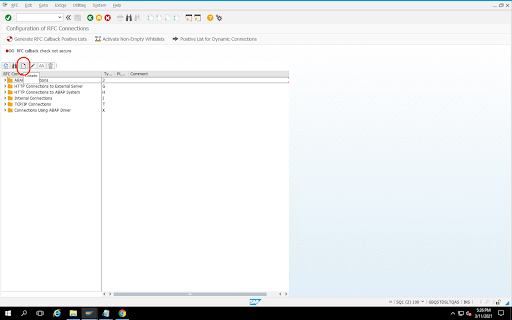
Nella finestra Impostazioni tecniche, inserisci i dettagli della destinazione RFC.
Fai clic sulla scheda Accesso e sicurezza per gestire le credenziali RFC (utente e password RFC).
Fai clic su Salva.
Fai clic su Test di connessione. Dopo aver superato il test, puoi procedere.
Verifica che il test di autorizzazione RFC sia andato a buon fine.
Fai clic su Utilità > Test > Test di autorizzazione.
Configura il plug-in
Per configurare il plug-in, esegui il deployment dall'hub, crea un job di replica e configura l'origine e la destinazione con i passaggi che seguono.
Esegui il deployment del plug-in in Cloud Data Fusion
L'utente di Cloud Data Fusion esegue i seguenti passaggi.
Prima di poter eseguire il job di replica di Cloud Data Fusion, esegui il deployment del plug-in di replica SAP SLT:
Vai all'istanza:
Nella Google Cloud console, vai alla pagina Istanze di Cloud Data Fusion.
Attiva la replica in un'istanza nuova o esistente:
- Per una nuova istanza, fai clic su Crea istanza, inserisci un nome dell'istanza, fai clic su Aggiungi acceleratori, seleziona la casella di controllo Replica e fai clic su Salva.
- Per un'istanza esistente, consulta Abilitare la replica su un'istanza esistente.
Fai clic su Visualizza istanza per aprire l'istanza nell'interfaccia web di Cloud Data Fusion.
Fai clic su Hub.
Vai alla scheda SAP, fai clic su SAP SLT e poi su SAP SLT Replication Plugin o SAP SLT No RFC Replication Plugin.
Fai clic su Esegui il deployment.
Crea un job di replica
Il plug-in SAP SLT Replication legge il contenuto delle tabelle SAP utilizzando un bucket temporaneo dell'API Cloud Storage.
Per creare un job di replica per il trasferimento dei dati:
Nell'istanza Cloud Data Fusion aperta, fai clic su Home > Replicazione > Crea un job di replica. Se non è presente l'opzione Replica, attiva la replica per l'istanza.
Inserisci un nome e una descrizione univoci per il job di replica.
Fai clic su Avanti.
Configura l'origine
Configura l'origine inserendo i valori nei seguenti campi:
- ID progetto: l'ID del tuo Google Cloud progetto (questo campo è precompilato)
Percorso GCS per la replica dei dati: il percorso Cloud Storage che contiene i dati per la replica. Deve essere lo stesso percorso configurato nei job SAP SLT. All'interno, il percorso fornito viene concatenato con
Mass Transfer IDeSource Table Name:Formato:
gs://<base-path>/<mass-transfer-id>/<source-table-name>Esempio:
gs://slt_bucket/012/MARAGUID: la GUID SLT, un identificatore univoco assegnato all'ID trasferimento collettivo SAP SLT.
ID trasferimento collettivo: l'ID trasferimento collettivo SLT è un identificatore univoco assegnato alla configurazione in SAP SLT.
Percorso GCS della libreria JCo di SAP: il percorso di archiviazione contenente i file della libreria JCo di SAP caricati dall'utente. Le librerie JCo di SAP possono essere scaricate dal Portale di assistenza SAP. (Rimossa nella versione 0.10.0 del plug-in).
Host del server SLT: nome host o indirizzo IP del server SLT. (Rimossa nella versione 0.10.0 del plug-in.)
Numero di sistema SAP: numero di sistema di installazione fornito dall'amministratore di sistema (ad es.
00). (Rimosso nella versione 0.10.0 del plug-in).Client SAP: il client SAP da utilizzare (ad es.
100). (Rimosso nella versione 0.10.0 del plug-in).Lingua SAP: lingua di accesso SAP (ad es.
EN). (Rimosso nella versione del plug-in 0.10.0.)Nome utente di accesso SAP: nome utente SAP. (Rimossa nella versione 0.10.0 del plug-in).
- Consigliato: se il nome utente di accesso SAP cambia periodicamente, utilizza una macro.
SAP Logon Password (M): password utente SAP per l'autenticazione utente.
- Consigliato: utilizza macro sicure per i valori sensibili, come le password. (Rimossa nella versione 0.10.0 del plug-in).
Sospendi la replica SLT quando si interrompe il job CDF: tenta di interrompere il job di replica SLT (per le tabelle interessate) quando si interrompe il job di replica Cloud Data Fusion. Potrebbe non riuscire se il job in Cloud Data Fusion si arresta in modo imprevisto.
Replica i dati esistenti: indica se replicare i dati esistenti dalle tabelle di origine. Per impostazione predefinita, i job replicano i dati esistenti dalle tabelle di origine. Se impostato su
false, tutti i dati esistenti nelle tabelle di origine vengono ignorati e vengono replicate solo le modifiche che si verificano dopo l'avvio del job.Chiave dell'account di servizio: la chiave da utilizzare per interagire con Cloud Storage. L'account di servizio deve disporre dell'autorizzazione di scrittura in Cloud Storage. Quando viene eseguito su una Google Cloud VM, questo valore deve essere impostato su
auto-detectper utilizzare l'account di servizio associato alla VM.
Fai clic su Avanti.
Configura il target
Per scrivere dati in BigQuery, il plug-in richiede l'accesso in scrittura sia a BigQuery sia a un bucket di staging. Gli eventi di modifica vengono prima scritti in batch da SLT a Cloud Storage. Vengono poi caricati nelle tabelle di staging in BigQuery. Le modifiche apportate alla tabella intermedia vengono unite alla tabella di destinazione finale utilizzando una query di unione BigQuery.
La tabella di destinazione finale include tutte le colonne originali della tabella di origine più una colonna _sequence_num aggiuntiva. Il numero di sequenza garantisce che i dati non vengano duplicati o persi in scenari di errore del replicatore.
Configura l'origine inserendo i valori nei seguenti campi:
- ID progetto: progetto del set di dati BigQuery. Quando viene eseguito su un cluster Dataproc, questo campo può essere lasciato vuoto, in modo da utilizzare il progetto del cluster.
- Credenziali: consulta Credenziali.
- Chiave account di servizio: i contenuti della chiave dell'account di servizio da utilizzare quando interagisci con Cloud Storage e BigQuery. Quando viene eseguito su un cluster Dataproc, questo campo deve essere lasciato vuoto, poiché viene utilizzato l'account di servizio del cluster.
- Nome set di dati: il nome del set di dati da creare in BigQuery. È facoltativo e, per impostazione predefinita, il nome del set di dati è uguale al nome del database di origine. Un nome valido deve contenere solo lettere, numeri e trattini bassi e la lunghezza massima può essere di 1024 caratteri. I caratteri non validi verranno sostituiti con un trattino basso nel nome del set di dati finale e i caratteri che superano il limite di lunghezza verranno troncati.
- Nome chiave di crittografia: la chiave di crittografia gestita dal cliente (CMEK) utilizzata per proteggere le risorse create da questo target. Il nome della chiave di crittografia deve essere
del tipo
projects/<project-id>/locations/<key-location>/keyRings/<key-ring-name>/cryptoKeys/<key-name>. - Località: la posizione in cui vengono creati il set di dati BigQuery e il bucket di staging Cloud Storage. Ad esempio,
us-east1per i bucket regionali eusper i bucket multiregionali (consulta Località). Questo valore viene ignorato se si specifica un bucket esistente, poiché il bucket temporaneo e il set di dati BigQuery vengono creati nella stessa località del bucket. Bucket di staging: il bucket in cui vengono scritti gli eventi di modifica prima che vengano caricati nelle tabelle di staging. Le modifiche vengono scritte in una directory che contiene il nome e lo spazio dei nomi del replicatore. È possibile utilizzare lo stesso bucket su più replicatori all'interno della stessa istanza. Se viene condiviso da più replicatori in più istanze, assicurati che lo spazio dei nomi e il nome siano univoci, altrimenti il comportamento non è definito. Il bucket deve trovarsi nella stessa posizione del set di dati BigQuery. Se non viene fornito, per ogni job viene creato un nuovo bucket denominato
df-rbq-<namespace-name>-<job-name>-<deployment-timestamp>.Intervallo di caricamento (secondi): il numero di secondi da attendere prima di caricare un batch di dati in BigQuery.
Prefisso tabella di staging: le modifiche vengono prima scritte in una tabella di staging prima di essere unite alla tabella finale. I nomi delle tabelle di staging vengono generati anteponendo questo prefisso al nome della tabella di destinazione.
Richiedi intervento manuale per l'eliminazione: indica se è richiesta un'azione amministrativa manuale per eliminare tabelle e set di dati quando viene rilevato un evento di eliminazione della tabella o del database. Se impostato su true, il replicatore non elimina una tabella o un set di dati. ma non riesce e riprova finché la tabella o il set di dati non esiste. Se il set di dati o la tabella non esiste, non è necessario alcun intervento manuale. L'evento viene ignorato normalmente.
Attiva le eliminazioni soft: se impostato su true, quando un evento di eliminazione viene ricevuto dal target, la colonna
_is_deletedper il record viene impostata sutrue. In caso contrario, il record viene eliminato dalla tabella BigQuery. Questa configurazione non è operativa per un'origine che genera eventi fuori sequenza e i record vengono sempre eliminati definitivamente dalla tabella BigQuery.
Fai clic su Avanti.
Credenziali
Se il plug-in viene eseguito su un cluster Dataproc, la chiave dell'account di servizio deve essere impostata su rilevamento automatico. Le credenziali vengono lette automaticamente dall'ambiente del cluster.
Se il plug-in non viene eseguito su un cluster Dataproc, deve essere fornito il percorso di una chiave dell'account di servizio. La chiave dell'account di servizio si trova nella pagina IAM della Google Cloud console. Assicurati che la chiave dell'account abbia l'autorizzazione per accedere a BigQuery. Il file della chiave dell'account di servizio deve essere disponibile su ogni nodo del cluster e deve essere leggibile da tutti gli utenti che eseguono il job.
Limitazioni
- Le tabelle devono avere una chiave primaria per essere replicate.
- Le operazioni di rinominazione delle tabelle non sono supportate.
- Le alterazioni delle tabelle sono supportate parzialmente.
- Una colonna non nullable esistente può essere modificata in una colonna nullable.
- È possibile aggiungere nuove colonne con valori null a una tabella esistente.
- Qualsiasi altro tipo di alterazione dello schema della tabella non andrà a buon fine.
- Le modifiche alla chiave primaria non andranno a buon fine, ma i dati esistenti non vengono riscritti per rispettare l'unicità della nuova chiave primaria.
Seleziona tabelle e trasformazioni
Nel passaggio Seleziona tabelle e trasformazioni viene visualizzato un elenco di tabelle selezionate per la replica nel sistema SLT.
- Seleziona le tabelle da replicare.
- (Facoltativo) Seleziona altre operazioni dello schema, ad esempio Insert, Updates o Deletes.
- Per visualizzare lo schema, fai clic su Colonne da replicare per una tabella.
(Facoltativo) Per rinominare le colonne nello schema:
- Mentre visualizzi lo schema, fai clic su Trasforma > Rinomina.
- Nel campo Rinomina, inserisci un nuovo nome e fai clic su Applica.
- Per salvare il nuovo nome, fai clic su Aggiorna e Salva.
Fai clic su Avanti.
(Facoltativo) Configura le proprietà avanzate
Se sai quanti dati stai replicando in un'ora, puoi selezionare l'opzione appropriata.
Rivedi la valutazione
Il passaggio Esamina la valutazione rileva problemi di schema, funzionalità mancanti o di connettività che si verificano durante la replica.
Nella pagina Esamina valutazione, fai clic su Visualizza mappature.
Eventuali problemi devono essere risolti prima di poter procedere.
(Facoltativo) Se hai rinominato le colonne quando hai selezionato le tabelle e le trasformazioni, verifica che i nuovi nomi siano corretti in questo passaggio.
Fai clic su Avanti.
Visualizza il riepilogo ed esegui il deployment del job di replica
Nella pagina Esamina i dettagli del job di replica, controlla le impostazioni e fai clic su Esegui il deployment del job di replica.
Seleziona un profilo Compute Engine
Dopo aver eseguito il deployment del job di replica, fai clic su Configura da qualsiasi pagina dell'interfaccia web di Cloud Data Fusion.
Seleziona il profilo Compute Engine che vuoi utilizzare per eseguire questo job di replica.
Fai clic su Salva.
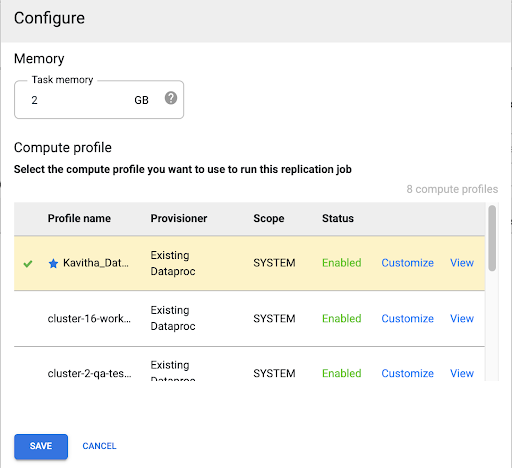
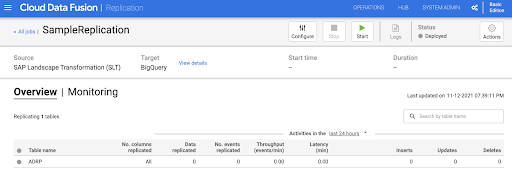
Avvia il job di replica
- Per eseguire il job di replica, fai clic su Avvia.
(Facoltativo) Ottimizza il rendimento
Per impostazione predefinita, il plug-in è configurato per prestazioni ottimali. Per ulteriori ottimizzazioni, consulta la sezione Argomenti di runtime.
Le prestazioni della comunicazione SLT e Cloud Data Fusion dipendono da questi fattori:
- SLT sul sistema di origine rispetto a un sistema SLT centrale dedicato (opzione preferita)
- Elaborazione dei job in background sul sistema SLT
- Processi di lavoro della conversazione nel sistema SAP di origine
- Il numero di processi di job in background allocati a ogni ID trasferimento collettivo nella scheda Amministrazione LTRC
- Impostazioni LTRS
- Hardware (CPU e memoria) del sistema SLT
- Il database utilizzato (ad esempio HANA, Sybase o DB2)
- La larghezza di banda internet (connettività tra il sistema SAP e internet)Google Cloud
- Utilizzo (carico) preesistente sul sistema
- Il numero di colonne nella tabella. Con un numero maggiore di colonne, la replica diventa lenta e la latenza può aumentare.
Per i caricamenti iniziali sono consigliati i seguenti tipi di lettura nelle impostazioni LTRS:
| Sistema SLT | Sistema di origine | Tipo di tabella | Tipo di lettura consigliato [caricamento iniziale] |
|---|---|---|---|
| SLT 3.0 autonoma [DMIS 2018_1_752 SP 2] |
S/4 HANA 1909 | Trasparente (piccole/medie) Trasparente (grandi) Tabella cluster |
1 calcolo dell'intervallo 1 calcolo dell'intervallo 4 coda del mittente |
| SLT incorporato [S4CORE 104 HANA 1909] |
N/D | Trasparente (piccole/medie) Trasparente (grandi) Tabella cluster |
1 calcolo dell'intervallo 1 calcolo dell'intervallo 4 coda del mittente |
| SLT 2.0 autonomo [DMIS 2011_1_731 SP 17] |
ECC NW 7.02 | Trasparente (piccole/medie) Trasparente (grandi) Tabella cluster |
Coda di 5 mittenti Coda di 5 mittenti Coda di 4 mittenti |
| SLT incorporato [DMIS 2011_1_700 SP 17] |
N/D | Trasparente (piccole/medie) Trasparente (grandi) Tabella cluster |
Coda di 5 mittenti Coda di 5 mittenti Coda di 4 mittenti |
- Per la replica, utilizza Nessun intervallo per migliorare il rendimento:
- Gli intervalli devono essere utilizzati solo quando i backlog vengono generati in una tabella di registrazione con latenza elevata.
- Utilizzo di un calcolo dell'intervallo: il tipo di lettura per il caricamento iniziale non è consigliato nel caso di sistemi SLT 2.0 e non HANA.
- Utilizzo di un calcolo dell'intervallo: il tipo di lettura per il caricamento iniziale potrebbe comportare la presenza di record duplicati in BigQuery.
- Le prestazioni sono sempre migliori quando viene utilizzato un sistema SLT autonomo.
- È sempre consigliabile un sistema SLT autonomo se l'utilizzo delle risorse del sistema di origine è già elevato.
Argomenti di runtime
snapshot.thread.count: passa il numero di thread da avviare per eseguire il caricamento dei datiSNAPSHOT/INITIALin parallelo. Per impostazione predefinita, utilizza il numero di vCPU disponibili nel cluster Dataproc in cui viene eseguito il job di replica.Consigliato: imposta questo parametro solo nei casi in cui hai bisogno di un controllo preciso sul numero di thread paralleli (ad esempio per ridurre l'utilizzo del cluster).
poll.file.count: passa il numero di file da sottoporre a polling dal percorso Cloud Storage fornito nel campo Percorso GCS di replica dei dati nell'interfaccia web. Per impostazione predefinita, il valore è500per sondaggio, ma può essere aumentato o diminuito in base alla configurazione del cluster.Consigliato: imposta questo parametro solo se hai requisiti rigorosi per il ritardo di replica. Valori più bassi potrebbero ridurre il ritardo. Puoi utilizzarlo per migliorare il throughput (se non risponde, utilizza valori superiori a quello predefinito).
bad.files.base.path: passa il percorso di Cloud Storage di base in cui vengono copiati tutti i file di dati con errori o con problemi rilevati durante la replica. Questa operazione è utile quando esistono requisiti rigorosi per il controllo dei dati e deve essere utilizzata una posizione specifica per registrare i trasferimenti non riusciti.Per impostazione predefinita, tutti i file con errori vengono copiati dal percorso Cloud Storage fornito nel campo Percorso Cloud Storage per la replica dei dati nell'interfaccia web.
Pattern del percorso finale dei file di dati con errori:
gs://BASE_FILE_PATH/MASS_TRANSFER_ID/SOURCE_TABLE_NAME/bad_files/REPLICATION_JOB_NAME/REPLICATION_JOB_ID/BAD_FILE_NAME
Esempio:
gs://slt_to_cdf_bucket/001/MARA/bad_files/MaraRepl/05f97349-7398-11ec-9443-8 ac0640fc83c/20220205_1901205168830_DATA_INIT.xml
I criteri per un file non valido sono un file XML danneggiato o non valido, valori PK mancanti o un problema di mancata corrispondenza del tipo di dati di campo.
Dettagli dell'assistenza
Prodotti e versioni SAP supportati
- Release SAP_BASIS 702, livello SP 0016 e versioni successive.
- Release SAP_ABA 702, livello SP 0016 e versioni successive.
- Release DMIS 2011_1_700, livello SP 0017 e versioni successive.
Versioni di SLT supportate
Sono supportate le versioni 2 e 3 di SLT.
Modelli di deployment SAP supportati
SLT come sistema autonomo o incorporato nel sistema di origine.
Note SAP che devono essere implementate prima di iniziare a utilizzare SLT
Se il tuo pacchetto di assistenza non include correzioni di classi /UI2/CL_JSON per PL
12 o versioni successive, implementa la nota SAP più recente per le correzioni di classi /UI2/CL_JSON,
ad esempio la nota SAP 2798102 per PL12.
(Consigliato) Implementa le note SAP consigliate dal reportCNV_NOTE_ANALYZER_SLT in base alla condizione del sistema di origine o centrale. Per maggiori informazioni, consulta la nota SAP 3016862 (è necessario accedere a SAP).
Se SAP è già configurato, non è necessario implementare altre note. Per eventuali errori o problemi specifici, consulta la nota SAP centrale per la release SLT.
Limiti per il volume di dati o la larghezza dei record
Non è definito alcun limite per il volume di dati estratti e la larghezza dei record.
Velocità effettiva prevista per il plug-in SAP SLT Replication
Per un ambiente configurato in base alle linee guida riportate in Ottimizzare il rendimento, il plug-in può estrarre circa 13 GB all'ora per il caricamento iniziale e 3 GB all'ora per la replica (CDC). Le prestazioni effettive potrebbero variare in base al carico del sistema Cloud Data Fusion e SAP o al traffico di rete.
Supporto per l'estrazione dei dati delta (modificati) di SAP
L'estrazione delta di SAP è supportata.
Obbligatorio: peering del tenant per le istanze Cloud Data Fusion
Il peering del tenant è obbligatorio quando l'istanza Cloud Data Fusion viene creata con un indirizzo IP interno. Per ulteriori informazioni sul peering dei tenant, consulta Creare un'istanza privata.
Risoluzione dei problemi
Il job di replica continua a riavviarsi
Se il job di replica continua a riavviarsi automaticamente, aumenta la memoria del cluster del job di replica ed esegui nuovamente il job di replica.
Duplicati nell'esegui in BigQuery
Se definisci il numero di job paralleli nelle impostazioni avanzate del plug-in SAP SLT Replication, quando le tabelle sono di grandi dimensioni si verifica un errore che causa colonne duplicate nell'area di destinazione BigQuery.
Per evitare il problema, rimuovi i job paralleli per il caricamento dei dati.
Scenari di errore
La seguente tabella elenca alcuni messaggi di errore comuni (il testo tra virgolette verrà sostituito dai valori effettivi in fase di esecuzione):
| ID messaggio | Messaggio | Azione consigliata |
|---|---|---|
CDF_SAP_SLT_01402 |
Service account type is not defined for
SERVICE_ACCT_NAME_FROM_UI. |
Assicurati che il percorso Cloud Storage fornito sia corretto. |
CDF_SAP_SLT_01403 |
Service account key provided is not valid due to error:
ROOT_CAUSE. Please provide a valid service account key for
service account type : SERVICE_ACCT_NAME_FROM_UI. |
Controlla la causa principale visualizzata nel messaggio e intervieni in modo appropriato. |
CDF_SAP_SLT_01404 |
Mass Transfer ID could not be found. Please ensure that it exists
in given GCS Bucket. |
Verifica che l'ID trasferimento collettivo specificato sia nel formato corretto. |
CDF_SAP_SLT_01502 |
The specified data replication GCS path 'slt_to_cdf_bucket_1' or
Mass Transfer ID '05C' could not be found. Please ensure that it exists in
GCS. |
Assicurati che il percorso Cloud Storage fornito sia corretto. |
CDF_SAP_SLT_01400 |
Metadata file not found. The META_INIT.json file is not present or
file is present with invalid format. |
Controlla la causa principale visualizzata nel messaggio e intervieni in modo appropriato. |
CDF_SAP_SLT_03408 |
Failed to start the event reader. |
Controlla la causa principale visualizzata nel messaggio e intervieni in modo appropriato. |
CDF_SAP_SLT_03409 |
Error while processing TABLE_NAME file for source table
gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/TABLE_NAME
/FILE_NAME. Root cause: ROOT_CAUSE. |
Controlla la causa principale visualizzata nel messaggio e intervieni in modo appropriato. |
CDF_SAP_SLT_03410 |
Failed to replicate data for source table TABLE_NAME
from file: gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/
TABLE_NAME/FILE_NAME. Root cause:
ROOT_CAUSE. |
Controlla la causa principale visualizzata nel messaggio e intervieni in modo appropriato. |
CDF_SAP_SLT_03411 |
Failed data replication for source table TABLE_NAME.
Root cause: ROOT_CAUSE. |
Controlla la causa principale visualizzata nel messaggio e intervieni in modo appropriato. |
CDF_SAP_SLT_03412 |
Failed to create target table for source table
TABLE_NAME. Root cause: ROOT_CAUSE. |
Controlla la causa principale visualizzata nel messaggio e intervieni di conseguenza. |
Mappatura dei tipi di dati
La tabella seguente mostra la mappatura tra i tipi di dati utilizzati nelle applicazioni SAP e Cloud Data Fusion.
| Tipo di dati SAP | Tipo ABAP | Descrizione (SAP) | Tipo di dati di Cloud Data Fusion |
|---|---|---|---|
| Numerico | |||
| INT1 | b | Numero intero di 1 byte | int |
| INT2 | s | Numero intero a 2 byte | int |
| INT4 | i | Numero intero a 4 byte | int |
| INT8 | 8 | Intero a 8 byte | long |
| DIC | p | Numero pacchettizzato in formato BCD (DEC) | decimal |
| DF16_DEC DF16_RAW |
a | IEEE 754r a virgola mobile decimale a 8 byte | decimal |
| DF34_DEC DF34_RAW |
e | IEEE 754r a virgola mobile decimale a 16 byte | decimal |
| FLTP | f | Numero in virgola mobile binario | double |
| Carattere | |||
| CHAR LCHR |
c | Stringa di caratteri | string |
| SSTRING GEOM_EWKB |
string | Stringa di caratteri | string |
| STRINGA GEOM_EWKB |
string | Stringa di caratteri CLOB | bytes |
| NUMC ACCP |
n | Testo numerico | string |
| Byte | |||
| RAW LRAW |
x | Dati binari | bytes |
| RAWSTRING | xstring | BLOB di stringhe di byte | bytes |
| Data/ora | |||
| DATS | g | Data | date |
| Tim | t | Ora | time |
| TIMESTAMP | utcl | ( Utclong ) Timestamp |
timestamp |
Passaggi successivi
- Scopri di più su Cloud Data Fusion.
- Scopri di più su SAP su Google Cloud.