En esta página se describe cómo habilitar la réplica de datos en tiempo real desde aplicaciones SAP a Google Cloud mediante SAP Landscape Transformation (SLT). El contenido se aplica a los complementos SAP SLT Replication y SAP SLT No RFC Replication, que están disponibles en el centro de Cloud Data Fusion. Muestra las configuraciones del sistema de origen de SAP, SLT, Cloud Storage y Cloud Data Fusion para hacer lo siguiente:
- Envía los metadatos y los datos de tabla de SAP a Google Cloud mediante SAP SLT.
- Crea una tarea de replicación de Cloud Data Fusion que lea los datos de un segmento de Cloud Storage.
SAP SLT Replication te permite replicar tus datos de forma continua y en tiempo real desde fuentes SAP en BigQuery. Puedes configurar y ejecutar transferencias de datos desde sistemas SAP sin necesidad de escribir código.
El proceso de replicación de SLT de Cloud Data Fusion es el siguiente:
- Los datos proceden de un sistema de origen SAP.
- SLT monitoriza y lee los datos, y los envía a Cloud Storage.
- Cloud Data Fusion extrae los datos del segmento de almacenamiento y los escribe en BigQuery.
Puedes transferir datos desde sistemas SAP compatibles, incluidos los sistemas SAP alojados en Google Cloud.
Para obtener más información, consulta la descripción general de SAP en Google Cloud y los detalles de asistencia.
Antes de empezar
Para usar este complemento, debes tener conocimientos sobre los siguientes temas:
- Crear flujos de procesamiento en Cloud Data Fusion
- Gestión de accesos con gestión de identidades y accesos
- Configurar sistemas de planificación de recursos empresariales (ERP) de SAP Cloud y locales
Administradores y usuarios que realizan las configuraciones
Las tareas de esta página las realizan usuarios con los siguientes roles en Google Cloud o en su sistema SAP:
| Tipo de usuario | Descripción |
|---|---|
| Administrador de Google Cloud | Los usuarios a los que se les asigna este rol son administradores de cuentas de Google Cloud. |
| Usuario de Cloud Data Fusion | Los usuarios a los que se les asigna este rol pueden diseñar y ejecutar flujos de procesamiento de datos. Como mínimo, se les asigna el rol Lector de Data Fusion
(
roles/datafusion.viewer). Si usas el control de acceso basado en roles, es posible que necesites roles adicionales.
|
| Administrador de SAP | Los usuarios a los que se les asigna este rol son administradores del sistema SAP. Tienen acceso para descargar software del sitio de servicios de SAP. No es un rol de gestión de identidades y accesos. |
| Usuario de SAP | Los usuarios a los que se les asigna este rol tienen autorización para conectarse a un sistema SAP. No es un rol de gestión de identidades y accesos. |
Operaciones de replicación admitidas
El complemento de replicación SLT de SAP admite las siguientes operaciones:
Modelado de datos: este complemento admite todas las operaciones de modelado de datos (registro insert, delete y update).
Definición de datos: tal como se describe en la nota de SAP 2055599 (se requiere iniciar sesión en el soporte de SAP para verla), hay limitaciones en cuanto a los cambios en la estructura de la tabla del sistema de origen que SLT replica automáticamente. Algunas operaciones de definición de datos no se admiten en el complemento (debes propagarlas manualmente).
- Compatible:
- Añadir un campo que no sea clave (después de hacer cambios en SE11, activa la tabla con SE14)
- No compatible:
- Añadir o eliminar un campo clave
- Eliminar campo sin clave
- Modificar tipos de datos
Requisitos de SAP
Los siguientes elementos son obligatorios en su sistema SAP:
- Tienes instalada la versión 2011 SP17 o posterior de SLT Server en el sistema SAP de origen (insertada) o como sistema de concentrador SLT dedicado.
- El sistema SAP de origen es SAP ECC o SAP S/4HANA, que admite DMIS 2011 SP17 o versiones posteriores, como DMIS 2018 o DMIS 2020.
- Tu complemento de interfaz de usuario de SAP debe ser compatible con tu versión de SAP Netweaver.
Tu paquete de asistencia admite la clase
/UI2/CL_JSONPL 12o versiones posteriores. De lo contrario, implementa la última nota de SAP para la clase/UI2/CL_JSONcorrectionssegún la versión de tu complemento de interfaz de usuario, como la nota de SAP 2798102 paraPL12.Se han implementado las siguientes medidas de seguridad:
Requisitos de Cloud Data Fusion
- Necesitas una instancia de Cloud Data Fusion con la versión 6.4.0 o posterior de cualquier edición.
- La cuenta de servicio asignada a la instancia de Cloud Data Fusion tiene los roles necesarios (consulta Conceder permiso de usuario de cuenta de servicio).
- En el caso de las instancias privadas de Cloud Data Fusion, se requiere el emparejamiento de VPC.
Google Cloud
- Habilita la API de Cloud Storage en tu Google Cloud proyecto.
- El usuario de Cloud Data Fusion debe tener permiso para crear carpetas en el segmento de Cloud Storage (consulta los roles de gestión de identidades y accesos de Cloud Storage).
- Opcional: Define la política de conservación si tu organización lo requiere.
Crea el segmento de almacenamiento
Antes de crear un trabajo de replicación de SLT, crea el segmento de Cloud Storage. La tarea transfiere datos al segmento y actualiza el segmento de almacenamiento provisional cada cinco minutos. Cuando ejecutas el trabajo, Cloud Data Fusion lee los datos del segmento de almacenamiento y los escribe en BigQuery.
Si SLT está instalado en Google Cloud
El servidor SLT debe tener permiso para crear y modificar objetos de Cloud Storage en el segmento que has creado.
Como mínimo, asigna los siguientes roles a la cuenta de servicio:
- Creador de tokens de cuenta de servicio (
roles/iam.serviceAccountTokenCreator) - Consumidor del uso del servicio (
roles/serviceusage.serviceUsageConsumer) - Administrador de objetos de Storage (
roles/storage.objectAdmin)
Si SLT no está instalado en Google Cloud
Instala Cloud VPN o Cloud Interconnect entre la VM de SAP yGoogle Cloud para permitir la conexión a un endpoint de metadatos interno (consulta Configurar el acceso privado de Google para hosts on-premise).
Si no se pueden asignar los metadatos internos:
Instala Google Cloud CLI en función del sistema operativo de la infraestructura en la que se ejecuta SLT.
Crea una cuenta de servicio en el Google Cloud proyecto donde esté habilitado Cloud Storage.
En el sistema operativo SLT, autoriza el acceso a Google Cloud con una cuenta de servicio.
Crea una clave de API para la cuenta de servicio y autoriza el ámbito relacionado con Cloud Storage.
Importa la clave de API a la CLI de gcloud que has instalado antes con la CLI.
Para habilitar el comando de gcloud CLI que imprime el token de acceso, configura el comando del sistema operativo SAP en la herramienta de transacción SM69 del sistema SLT.
Imprimir un token de acceso
El administrador de SAP configura el comando del sistema operativo, SM69, que obtiene un token de acceso de Google Cloud.
Crea una secuencia de comandos para imprimir un token de acceso y configura un comando del sistema operativo SAP para llamar a la secuencia de comandos como usuario <sid>adm desde el host de SAP LT Replication Server.
Linux
Para crear un comando del SO, sigue estos pasos:
En el host de SAP LT Replication Server, en un directorio al que pueda acceder
<sid>adm, crea un script bash que contenga las siguientes líneas:PATH_TO_GCLOUD_CLI/bin/gcloud auth print-access-token SERVICE_ACCOUNT_NAMEEn la interfaz de usuario de SAP, crea un comando de SO externo:
- Introduce la transacción
SM69. - Haz clic en Crear.
- En la sección Comando del panel Comando externo, introduce el nombre del comando, como
ZGOOGLE_CDF_TOKEN. En la sección Definición:
- En el campo Comando del sistema operativo, introduce
shcomo extensión del archivo de secuencia de comandos. En el campo Parámetros del comando del sistema operativo, introduce lo siguiente:
/PATH_TO_SCRIPT/FILE_NAME.sh
- En el campo Comando del sistema operativo, introduce
Haz clic en Guardar.
Para probar la secuencia de comandos, haz clic en Ejecutar.
Vuelve a hacer clic en Ejecutar.
Se devuelve un Google Cloud token y se muestra en la parte inferior del panel de la interfaz de usuario de SAP.
- Introduce la transacción
Windows
En la interfaz de usuario de SAP, crea un comando del sistema operativo externo:
- Introduce la transacción
SM69. - Haz clic en Crear.
- En la sección Comando del panel Comando externo, introduce el nombre del comando, como
ZGOOGLE_CDF_TOKEN. En la sección Definición:
- En el campo Operating System Command (Comando del sistema operativo), introduce
cmd /c. En el campo Parámetros del comando del sistema operativo, introduce lo siguiente:
gcloud auth print-access-token SERVICE_ACCOUNT_NAME
- En el campo Operating System Command (Comando del sistema operativo), introduce
Haz clic en Guardar.
Para probar la secuencia de comandos, haz clic en Ejecutar.
Vuelve a hacer clic en Ejecutar.
Se devuelve un token Google Cloud y se muestra en la parte inferior del panel de la interfaz de usuario de SAP.
Requisitos de SLT
El conector de SLT debe tener la siguiente configuración:
- El conector es compatible con SAP ECC NW 7.02, DMIS 2011 SP17 y versiones posteriores.
- Configure una conexión RFC o de base de datos entre SLT y el sistema Cloud Storage.
- Configura los certificados SSL:
- Descarga los siguientes certificados de AC del repositorio de Google Trust Services:
- GTS Root R1
- GTS CA 1C3
- En la interfaz de usuario de SAP, usa la transacción
STRUSTpara importar los certificados raíz y subordinado en la carpetaSSL Client (Standard) PSE.
- Descarga los siguientes certificados de AC del repositorio de Google Trust Services:
- Internet Communication Manager (ICM) debe configurarse para HTTPS. Asegúrate de que los puertos HTTP y HTTPS se mantengan y activen en el sistema SAP SLT.
Puedes comprobarlo con el código de transacción
SMICM > Services. - Habilita el acceso a las APIs en la VM en la que se aloja el sistema SAP SLT. Google Cloud De esta forma, los serviciosGoogle Cloud pueden comunicarse entre sí de forma privada sin tener que enrutar el tráfico a través de Internet.
- Asegúrate de que la red pueda admitir el volumen y la velocidad necesarios para la transferencia de datos entre la infraestructura de SAP y Cloud Storage. Para que la instalación se realice correctamente, se recomienda usar Cloud VPN o Cloud Interconnect. El rendimiento de la API de streaming depende de las cuotas de cliente que se hayan concedido a tu proyecto de Cloud Storage.
Configurar el servidor de replicación SLT
El usuario de SAP sigue estos pasos.
En los siguientes pasos, conectará el servidor SLT al sistema de origen y al segmento de Cloud Storage, especificando el sistema de origen, las tablas de datos que se van a replicar y el segmento de almacenamiento de destino.
Configurar el SDK de Google ABAP
Para configurar SLT para la replicación de datos (una vez por instancia de Cloud Data Fusion), sigue estos pasos:
Para configurar el conector SLT, el usuario de SAP introduce la siguiente información en la pantalla de configuración (transacción de SAP
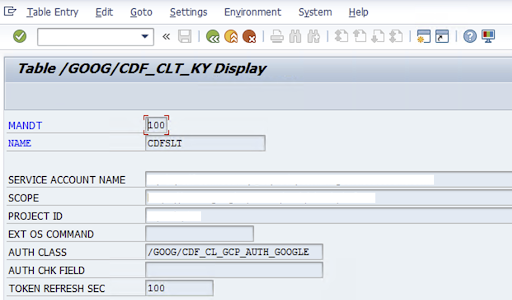
/GOOG/CDF_SETTINGS) sobre la clave de la cuenta de servicio de Google Cloud para transferir datos a Cloud Storage. Configura las siguientes propiedades en la tabla /GOOG/CDF_CLT_KY mediante la transacción SE16 y anota esta clave:- NAME el nombre de la clave de la cuenta de servicio (por ejemplo,
CDFSLT) - NOMBRE_CUENTA_SERVICIO: nombre de la cuenta de servicio de gestión de identidades y accesos.
- SCOPE: el ámbito de la cuenta de servicio.
- ID_PROYECTO: el ID de tu Google Cloud proyecto
- Opcional: Comando del SO EXT: usa este campo solo si SLT no está instalado en Google Cloud
AUTH CLASS: si el comando del SO está configurado en la tabla
/GOOG/CDF_CLT_KY, usa el valor fijo/GOOG/CDF_CL_GCP_AUTH.TOKEN_REFRESH_SEC: duración de la actualización del token de autorización
- NAME el nombre de la clave de la cuenta de servicio (por ejemplo,
Crear la configuración de replicación
Cree una configuración de replicación en el código de transacción LTRC.
- Antes de continuar con la configuración de LTRC, asegúrate de que se haya establecido la conexión RFC entre el sistema SAP de origen y SLT.
- En una configuración de SLT, puede haber varias tablas de SAP asignadas para la replicación.
Ve al código de transacción
LTRCy haz clic en Nueva configuración.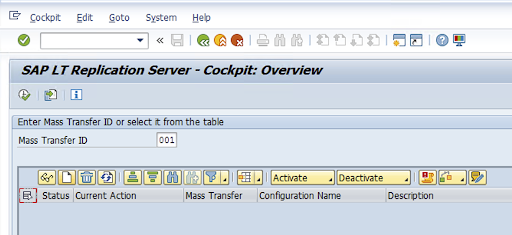
Introduce el Nombre de la configuración y la Descripción, y haz clic en Siguiente.
Especifica la conexión RFC del sistema de origen de SAP y haz clic en Siguiente.
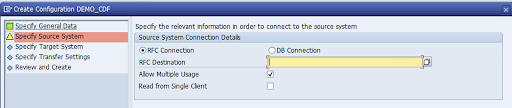
En Detalles de conexión del sistema de destino, selecciona Otro.
Despliega el campo Scenario for RFC Communication (Situación de comunicación RFC), selecciona SLT SDK y haz clic en Next (Siguiente).
Ve a la ventana Specify Transfer Settings (Especificar ajustes de transferencia) e introduce el nombre de la aplicación:
ZGOOGLE_CDF.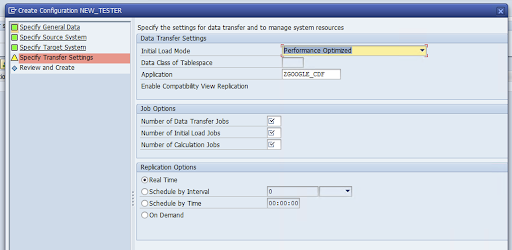
Introduce el número de tareas de transferencia de datos, el número de tareas de carga inicial y el número de tareas de cálculo. Para obtener más información sobre el rendimiento, consulta la guía de optimización del rendimiento de SAP LT Replication Server.
Haz clic en Tiempo real > Siguiente.
Revisa la configuración y haz clic en Guardar. Anota el ID de transferencia masiva para los pasos siguientes.
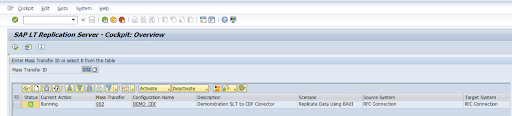
Para mantener el ID de transferencia masiva y los detalles de la tabla de SAP, ejecuta la transacción de SAP
/GOOG/CDF_SETTINGS.Haz clic en Ejecutar o pulsa
F8.Crea una entrada haciendo clic en el icono de añadir fila.
Introduce el ID de transferencia masiva, la clave de transferencia masiva, el nombre de la clave de GCP y el segmento de GCS de destino. Seleccione la casilla Está activo y guarde los cambios.
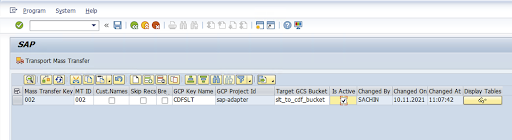
Seleccione la configuración en la columna Nombre de la configuración y haga clic en Aprovisionamiento de datos.
Opcional: Personaliza los nombres de las tablas y los campos.
Haz clic en Nombres personalizados y guarda los cambios.
Haz clic en Pantalla.
Para crear una entrada, haz clic en los botones Añadir fila o Crear.
Introduce el nombre de la tabla de SAP y el nombre de la tabla externa que quieras usar en BigQuery y guarda los cambios.
Haga clic en el botón Ver de la columna Mostrar campos para mantener la asignación de los campos de la tabla.
Se abrirá una página con las asignaciones sugeridas. Opcional: Edita el nombre del campo temporal y la descripción del campo y, a continuación, guarda las asignaciones.
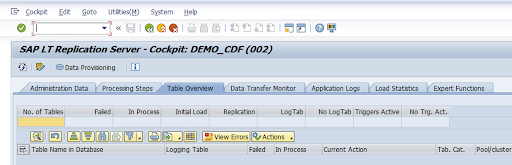
Ve a la transacción LTRC.
Seleccione el valor de la columna Nombre de configuración y haga clic en Aprovisionamiento de datos.
Escribe el nombre de la tabla en el campo Nombre de la tabla en la base de datos y selecciona el escenario de replicación.
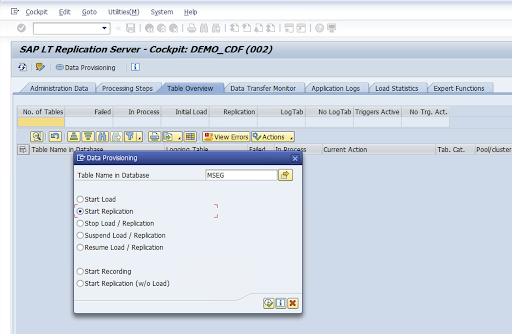
Haz clic en la opción para ejecutar. De esta forma, se activa la implementación del SDK de SLT y se inicia la transferencia de datos al segmento de destino en Cloud Storage.
Instalar archivos de transporte de SAP
Para diseñar y ejecutar tareas de replicación en Cloud Data Fusion, los componentes de SAP se proporcionan como archivos de transporte de SAP que se archivan en un archivo zip. La descarga está disponible cuando despliega el complemento en el centro de Cloud Data Fusion.
Para instalar los transportes de SAP, sigue estos pasos:
Paso 1: Sube los archivos de solicitud de transporte
- Inicia sesión en el sistema operativo de la instancia de SAP.
- Usa el código de transacción de SAP
AL11para obtener la ruta de la carpetaDIR_TRANS. Normalmente, la ruta es/usr/sap/trans/. - Copia los archivos de co en la carpeta
DIR_TRANS/cofiles. - Copia los archivos de datos en la carpeta
DIR_TRANS/data. - Define el usuario y el grupo de datos y el coarchivo como
<sid>admysapsys.
Paso 2: Importa los archivos de solicitud de transporte
El administrador de SAP puede importar los archivos de solicitud de transporte mediante el sistema de gestión de transporte de SAP o el sistema operativo:
Sistema de gestión de transportes de SAP
- Inicia sesión en el sistema SAP como administrador de SAP.
- Introduce el STMS de la transacción.
- Haga clic en Resumen > Importaciones.
- En la columna Cola, haz doble clic en el SID actual.
- Haz clic en Extras > Otras solicitudes > Añadir.
- Selecciona el ID de solicitud de transporte y haz clic en Continuar.
- Seleccione la solicitud de transporte en la cola de importación y, a continuación, haga clic en Solicitud > Importar.
- Introduce el número de cliente.
En la pestaña Opciones, selecciona Sobrescribir originales e Ignorar versión de componente no válida (si está disponible).
Opcional: Si quieres volver a importar los transportes más adelante, haz clic en Dejar las solicitudes de transporte en la cola para importarlas más adelante y en Volver a importar solicitudes de transporte. Esto es útil para las actualizaciones del sistema SAP y las restauraciones de copias de seguridad.
Haz clic en Continuar.
Verifica que el módulo de funciones y los roles de autorización se han importado correctamente mediante transacciones como
SE80yPFCG.
Sistema operativo
- Inicia sesión en el sistema SAP como administrador de SAP.
Añadir solicitudes al búfer de importación:
tp addtobuffer TRANSPORT_REQUEST_ID SIDPor ejemplo:
tp addtobuffer IB1K903958 DD1Importa las solicitudes de transporte:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238Sustituye
NNNpor el número de cliente. Por ejemplo:tp import IB1K903958 DD1 client=800 U1238Verifica que el módulo de funciones y los roles de autorización se han importado correctamente mediante las transacciones adecuadas, como
SE80yPFCG.
Autorizaciones de SAP necesarias
Para ejecutar un flujo de procesamiento de datos en Cloud Data Fusion, necesita un usuario de SAP. El usuario de SAP debe ser de tipo Communications o Dialog. Para evitar el uso de recursos de diálogo de SAP, se recomienda el tipo de comunicación. El administrador de SAP puede crear usuarios mediante el código de transacción SU01 de SAP.
Se necesitan autorizaciones de SAP para mantener y configurar el conector para SAP, una combinación de objetos de autorización de conectores estándar y nuevos de SAP. Mantienes los objetos de autorización en función de las políticas de seguridad de tu organización. En la siguiente lista se describen algunas autorizaciones importantes que necesita el conector:
Objeto de autorización: el objeto de autorización
ZGOOGCDFMTse envía como parte del rol de solicitud de transporte.Creación de roles: crea un rol con el código de transacción
PFCG.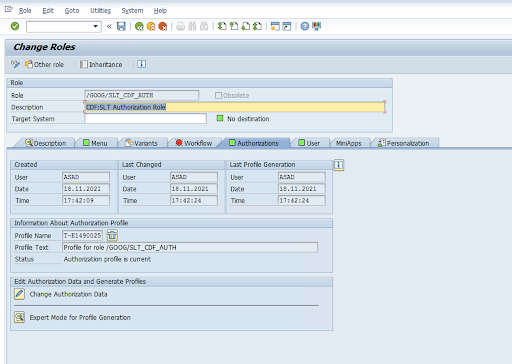
En el caso de los objetos de autorización de SAP estándar, tu organización gestiona los permisos con su propio mecanismo de seguridad.
En el caso de los objetos de autorización personalizados, proporcione valores en los campos de autorización de los objetos de autorización
ZGOOGCDFMT.Para el control de acceso pormenorizado,
ZGOOGCDFMTproporciona autorización basada en grupos de autorización. Los usuarios con acceso completo, parcial o nulo a los grupos de autorización tienen acceso en función del grupo de autorización asignado en su rol./GOOG/SLT_CDF_AUTH: rol con acceso a todos los grupos de autorización. Para restringir el acceso a un grupo de autorización concreto, mantén el FICDF del grupo de autorización en la configuración.
Crear un destino RFC para la fuente
Antes de empezar con la configuración, asegúrate de que la conexión RFC se haya establecido entre el origen y el destino.
Ve al código de transacción
SM59.Haga clic en Crear > Tipo de conexión 3 (conexión ABAP).
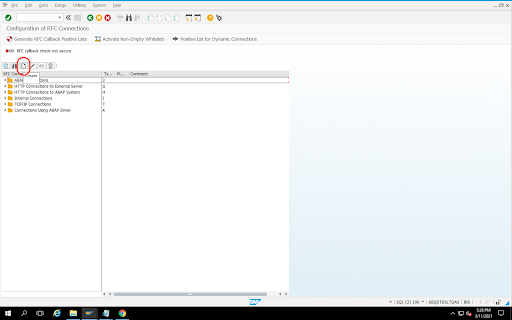
En la ventana Ajustes técnicos, introduce los detalles sobre el destino RFC.
Haga clic en la pestaña Inicio de sesión y seguridad para mantener las credenciales de RFC (usuario y contraseña de RFC).
Haz clic en Guardar.
Haz clic en Prueba de conexión. Si la prueba se realiza correctamente, puedes continuar.
Verifica que la prueba de autorización RFC se haya completado correctamente.
Haz clic en Utilidades > Prueba > Prueba de autorización.
Configurar el complemento
Para configurar el complemento, despliégalo desde el centro, crea un trabajo de replicación y configura el origen y el destino siguiendo estos pasos.
Desplegar el complemento en Cloud Data Fusion
El usuario de Cloud Data Fusion sigue estos pasos.
Antes de ejecutar el trabajo de replicación de Cloud Data Fusion, implementa el complemento de replicación de SAP SLT:
Ve a tu instancia:
En la Google Cloud consola, ve a la página Instancias de Cloud Data Fusion.
Habilita la replicación en una instancia nueva o ya creada:
- Para crear una instancia, haz clic en Crear instancia, introduce un nombre de instancia, haz clic en Añadir aceleradores, selecciona la casilla Replicación y haz clic en Guardar.
- Si se trata de una instancia, consulta Habilitar la replicación en una instancia.
Haz clic en Ver instancia para abrir la instancia en la interfaz web de Cloud Data Fusion.
Haz clic en Concentrador.
Ve a la pestaña SAP, haz clic en SAP SLT y, a continuación, en Complemento de replicación SLT de SAP o Complemento de replicación SLT de SAP sin RFC.
.Haz clic en Desplegar.
Crear una tarea de replicación
El complemento de replicación de SAP SLT lee el contenido de las tablas de SAP mediante un bucket de almacenamiento provisional de la API Cloud Storage.
Para crear un trabajo de replicación para la transferencia de datos, sigue estos pasos:
En la instancia de Cloud Data Fusion que has abierto, haz clic en Inicio > Replicación > Crear una tarea de replicación. Si no aparece la opción Replicación, habilita la replicación en la instancia.
Escriba un nombre y una descripción únicos para el trabajo de replicación.
Haz clic en Siguiente.
Configurar la fuente
Configure la fuente introduciendo valores en los siguientes campos:
- ID de proyecto: el ID de tu Google Cloud proyecto (este campo se rellena automáticamente)
Ruta de GCS de replicación de datos: ruta de Cloud Storage que contiene los datos de replicación. Debe ser la misma ruta que se haya configurado en los trabajos de SAP SLT. Internamente, la ruta proporcionada se concatena con
Mass Transfer IDySource Table Name:Formato:
gs://<base-path>/<mass-transfer-id>/<source-table-name>Ejemplo:
gs://slt_bucket/012/MARAGUID el GUID de SLT, un identificador único asignado al ID de transferencia masiva de SAP SLT.
ID de transferencia masiva: el ID de transferencia masiva de SLT es un identificador único asignado a la configuración en SAP SLT.
Ruta de GCS de la biblioteca SAP JCo: ruta de almacenamiento que contiene los archivos de la biblioteca SAP JCo que ha subido el usuario. Las bibliotecas de SAP JCo se pueden descargar desde el portal de asistencia de SAP. (Se ha quitado en la versión 0.10.0 del complemento).
Host del servidor SLT: nombre de host o dirección IP del servidor SLT. (Se ha quitado en la versión 0.10.0 del complemento).
Número de sistema SAP: número de sistema de instalación proporcionado por el administrador del sistema (por ejemplo,
00). (Se ha quitado en la versión 0.10.0 del complemento).Cliente de SAP: el cliente de SAP que se va a usar (por ejemplo,
100). (Se ha quitado en la versión 0.10.0 del complemento).Idioma de SAP: idioma de inicio de sesión de SAP (por ejemplo,
EN). (Se ha eliminado en la versión 0.10.0 del complemento).Nombre de usuario de inicio de sesión de SAP: nombre de usuario de SAP. (Se ha quitado en la versión 0.10.0 del complemento).
- Recomendación: Si el nombre de usuario de inicio de sesión de SAP cambia periódicamente, usa una macro.
Contraseña de inicio de sesión de SAP (M): contraseña de usuario de SAP para la autenticación de usuarios.
- Recomendación: Usa macros seguras para los valores sensibles, como las contraseñas. (Se ha quitado en la versión 0.10.0 del complemento).
Suspender la replicación de SLT cuando se detenga la tarea de CDF: intenta detener la tarea de replicación de SLT (de las tablas implicadas) cuando se detiene la tarea de replicación de Cloud Data Fusion. Puede fallar si la tarea de Cloud Data Fusion se detiene de forma inesperada.
Replicar datos: indica si se deben replicar los datos de las tablas de origen. De forma predeterminada, las tareas replican los datos de las tablas de origen. Si se define como
false, se ignoran los datos que ya existan en las tablas de origen y solo se replican los cambios que se produzcan después de que se inicie el trabajo.Clave de cuenta de servicio: la clave que se debe usar al interactuar con Cloud Storage. La cuenta de servicio debe tener permiso para escribir en Cloud Storage. Cuando se ejecuta en una VM de Google Cloud , este valor debe ser
auto-detectpara usar la cuenta de servicio asociada a la VM.
Haz clic en Siguiente.
Configurar el objetivo
Para escribir datos en BigQuery, el complemento requiere acceso de escritura tanto a BigQuery como a un contenedor de almacenamiento provisional. Los eventos de cambio se escriben primero en lotes desde SLT en Cloud Storage. Después, se cargan en tablas de almacenamiento provisional en BigQuery. Los cambios de la tabla de almacenamiento provisional se combinan en la tabla de destino final mediante una consulta de combinación de BigQuery.
La tabla de destino final incluye todas las columnas originales de la tabla de origen, además de una columna _sequence_num adicional. El número de secuencia asegura que los datos no se dupliquen ni se pierdan en situaciones de fallo del replicador.
Configure la fuente introduciendo valores en los siguientes campos:
- ID de proyecto: proyecto del conjunto de datos de BigQuery. Si se ejecuta en un clúster de Dataproc, se puede dejar en blanco para usar el proyecto del clúster.
- Credenciales: consulta Credenciales.
- Clave de cuenta de servicio: el contenido de la clave de cuenta de servicio que se va a usar al interactuar con Cloud Storage y BigQuery. Cuando se ejecuta en un clúster de Dataproc, este campo debe dejarse en blanco, ya que se usa la cuenta de servicio del clúster.
- Nombre del conjunto de datos: nombre del conjunto de datos que se va a crear en BigQuery. Es opcional y, de forma predeterminada, el nombre del conjunto de datos es el mismo que el de la base de datos de origen. Un nombre válido solo puede contener letras, números y guiones bajos, y su longitud máxima es de 1024 caracteres. Los caracteres no válidos se sustituirán por guiones bajos en el nombre del conjunto de datos final y los caracteres que superen el límite de longitud se truncarán.
- Nombre de la clave de cifrado: clave de cifrado gestionada por el cliente (CMEK) que se usa para proteger los recursos creados por este destino. El nombre de la clave de cifrado debe tener el formato
projects/<project-id>/locations/<key-location>/keyRings/<key-ring-name>/cryptoKeys/<key-name>. - Ubicación: la ubicación en la que se crean el conjunto de datos de BigQuery y el segmento de almacenamiento provisional de Cloud Storage. Por ejemplo,
us-east1para los segmentos regionales yuspara los segmentos multirregionales (consulta Ubicaciones). Este valor se ignora si se especifica un segmento ya disponible, ya que el segmento de almacenamiento provisional y el conjunto de datos de BigQuery se crean en la misma ubicación que ese segmento. Contenedor de almacenamiento provisional: el contenedor en el que se escriben los eventos de cambio antes de cargarse en las tablas de almacenamiento provisional. Los cambios se escriben en un directorio que contiene el nombre y el espacio de nombres del replicador. Puedes usar el mismo contenedor de forma segura en varios replicadores de la misma instancia. Si los replicadores lo comparten en varias instancias, asegúrate de que el espacio de nombres y el nombre sean únicos. De lo contrario, el comportamiento no estará definido. El segmento debe estar en la misma ubicación que el conjunto de datos de BigQuery. Si no se proporciona, se crea un nuevo contenedor para cada trabajo con el nombre
df-rbq-<namespace-name>-<job-name>-<deployment-timestamp>.Intervalo de carga (segundos): número de segundos que se deben esperar antes de cargar un lote de datos en BigQuery.
Prefijo de tabla de almacenamiento provisional: los cambios se escriben primero en una tabla de almacenamiento provisional antes de combinarse en la tabla final. Los nombres de las tablas de almacenamiento provisional se generan añadiendo este prefijo al nombre de la tabla de destino.
Require Manual Drop Intervention: indica si se requiere una acción administrativa manual para eliminar tablas y conjuntos de datos cuando se detecta un evento de eliminación de tabla o de base de datos. Si se define como true, el replicador no elimina una tabla ni un conjunto de datos. En su lugar, falla y vuelve a intentarlo hasta que la tabla o el conjunto de datos no existan. Si el conjunto de datos o la tabla no existen, no es necesario hacer nada. El evento se omite como de costumbre.
Habilitar eliminaciones lógicas: si se le asigna el valor true, cuando el destino recibe un evento de eliminación, la columna
_is_deleteddel registro se establece entrue. De lo contrario, el registro se elimina de la tabla de BigQuery. Esta configuración no tiene ningún efecto en una fuente que genera eventos desordenados y los registros siempre se eliminan de forma lógica de la tabla de BigQuery.
Haz clic en Siguiente.
Credenciales
Si el complemento se ejecuta en un clúster de Dataproc, la clave de la cuenta de servicio debe configurarse para que se detecte automáticamente. Las credenciales se leen automáticamente del entorno del clúster.
Si el complemento no se ejecuta en un clúster de Dataproc, se debe proporcionar la ruta a una clave de cuenta de servicio. La clave de cuenta de servicio se encuentra en la página IAM de la Google Cloud consola. Asegúrate de que la clave de la cuenta tiene permiso para acceder a BigQuery. El archivo de claves de la cuenta de servicio debe estar disponible en todos los nodos del clúster y todos los usuarios que ejecuten el trabajo deben poder leerlo.
Limitaciones
- Las tablas deben tener una clave principal para poder replicarse.
- No se admiten operaciones de cambio de nombre de tablas.
- Las modificaciones de tablas se admiten parcialmente.
- Una columna no anulable ya creada se puede convertir en una columna anulable.
- Se pueden añadir columnas que admitan valores nulos a una tabla ya creada.
- Si se intenta modificar el esquema de la tabla de cualquier otra forma, se producirá un error.
- Los cambios en la clave principal no fallarán, pero los datos no se reescribirán para que cumplan la unicidad de la nueva clave principal.
Seleccionar tablas y transformaciones
En el paso Seleccionar tablas y transformaciones, aparece una lista de tablas seleccionadas para la replicación en el sistema SLT.
- Selecciona las tablas que quieras replicar.
- Opcional: Seleccione operaciones de esquema adicionales, como Inserciones, Actualizaciones o Eliminaciones.
- Para ver el esquema de una tabla, haga clic en Columnas que se van a replicar.
Opcional: Para cambiar el nombre de las columnas del esquema, sigue estos pasos:
- Mientras ves el esquema, haz clic en Transformar > Cambiar nombre.
- En el campo Cambiar nombre, introduce un nombre y haz clic en Aplicar.
- Para guardar el nuevo nombre, haz clic en Actualizar y Guardar.
Haz clic en Siguiente.
Opcional: Configurar propiedades avanzadas
Si sabes cuántos datos vas a replicar en una hora, puedes seleccionar la opción adecuada.
Revisar la evaluación
En el paso Revisar evaluación se analizan los problemas de esquema, las funciones que faltan o los problemas de conectividad que se producen durante la replicación.
En la página Revisar evaluación, haga clic en Ver asignaciones.
Si se produce algún problema, debe resolverse antes de continuar.
Opcional: Si has cambiado el nombre de las columnas al seleccionar las tablas y las transformaciones, comprueba que los nombres nuevos sean correctos en este paso.
Haz clic en Siguiente.
Ver el resumen y desplegar el trabajo de replicación
En la página Revisar detalles del trabajo de replicación, compruebe la configuración y haga clic en Implementar trabajo de replicación.
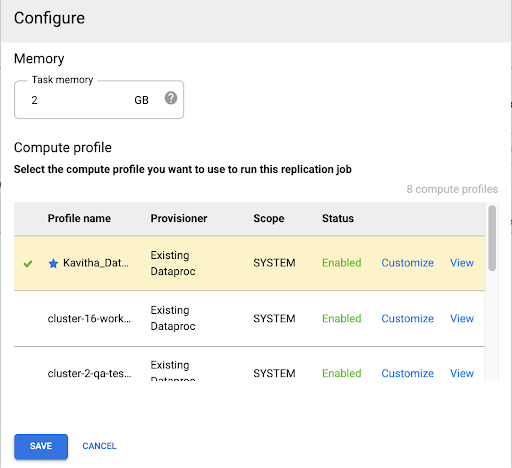
Selecciona un perfil de Compute Engine
Después de implementar la tarea de replicación, haga clic en Configurar en cualquier página de la interfaz web de Cloud Data Fusion.
Selecciona el perfil de Compute Engine que quieras usar para ejecutar este trabajo de replicación.
Haz clic en Guardar.
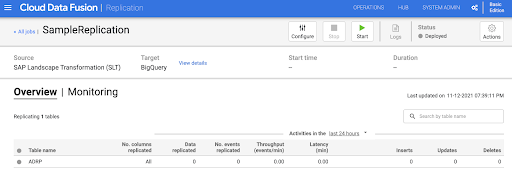
Iniciar la tarea de replicación
- Para ejecutar el trabajo de replicación, haz clic en Iniciar.
Opcional: Optimizar el rendimiento
De forma predeterminada, el complemento está configurado para ofrecer un rendimiento óptimo. Para ver otras optimizaciones, consulta Argumentos de tiempo de ejecución.
El rendimiento de la comunicación entre SLT y Cloud Data Fusion depende de los siguientes factores:
- SLT en el sistema de origen frente a un sistema SLT central dedicado (opción preferida)
- Procesamiento de trabajos en segundo plano en el sistema SLT
- Procesos de trabajo de diálogo en el sistema SAP de origen
- Número de procesos de trabajos en segundo plano asignados a cada ID de transferencia masiva en la pestaña Administración de LTRC
- Configuración de LTRS
- Hardware (CPU y memoria) del sistema SLT
- La base de datos utilizada (por ejemplo, HANA, Sybase o DB2)
- El ancho de banda de Internet (conectividad entre el sistema SAP yGoogle Cloud a través de Internet)
- Utilización (carga) preexistente en el sistema
- Número de columnas de la tabla. Si hay más columnas, la replicación se ralentiza y la latencia puede aumentar.
Se recomiendan los siguientes tipos de lectura en la configuración de LTRS para las cargas iniciales:
| Sistema SLT | Sistema de origen | Tipo de tabla | Tipo de lectura recomendado [carga inicial] |
|---|---|---|---|
| SLT 3.0 independiente [DMIS 2018_1_752 SP 2] |
S/4 HANA 1909 | Transparente (pequeño/mediano) Transparente (grande) Tabla de clústeres |
1 cálculo de intervalo 1 cálculo de intervalo 4 colas de envío |
| SLT integrado [S4CORE 104 HANA 1909] |
N/A | Transparente (pequeño/mediano) Transparente (grande) Tabla de clústeres |
1 cálculo de intervalo 1 cálculo de intervalo 4 colas de envío |
| SLT 2.0 independiente [DMIS 2011_1_731 SP 17] |
ECC NW 7.02 | Transparente (pequeño/mediano) Transparente (grande) Tabla de clústeres |
5 cola de envío 5 cola de envío 4 cola de envío |
| SLT insertado [DMIS 2011_1_700 SP 17] |
N/A | Transparente (pequeño/mediano) Transparente (grande) Tabla de clústeres |
5 cola de envío 5 cola de envío 4 cola de envío |
- Para la replicación, usa "Sin intervalos" para mejorar el rendimiento:
- Los intervalos solo se deben usar cuando se generen registros pendientes en una tabla de registro con una latencia alta.
- Usar un cálculo de intervalo: no se recomienda el tipo de lectura para la carga inicial en el caso de los sistemas SLT 2.0 y no HANA.
- Usar un cálculo de intervalo: el tipo de lectura de la carga inicial puede dar lugar a registros duplicados en BigQuery.
- El rendimiento siempre es mejor cuando se usa un sistema SLT independiente.
- Siempre se recomienda un sistema SLT independiente si la utilización de recursos del sistema de origen ya es alta.
Argumentos de tiempo de ejecución
snapshot.thread.count: transfiere el número de subprocesos que se van a iniciar para realizar la carga de datos deSNAPSHOT/INITIALen paralelo. De forma predeterminada, utiliza el número de vCPUs disponibles en el clúster de Dataproc en el que se ejecuta el trabajo de replicación.Recomendación: defina este parámetro solo en los casos en los que necesite controlar con precisión el número de subprocesos paralelos (por ejemplo, para reducir el uso en un clúster).
poll.file.count: transfiere el número de archivos que se van a sondear desde la ruta de Cloud Storage proporcionada en el campo Ruta de GCS de replicación de datos de la interfaz web. De forma predeterminada, el valor es500por sondeo, pero, en función de la configuración del clúster, se puede aumentar o reducir.Recomendación: Solo debe definir este parámetro si tiene requisitos estrictos en cuanto a la latencia de replicación. Los valores más bajos pueden reducir el retraso. Puedes usarlo para mejorar el rendimiento (si no responde, usa valores superiores al predeterminado).
bad.files.base.path: transfiere la ruta base de Cloud Storage en la que se copian todos los archivos de datos erróneos o defectuosos que se han encontrado durante la replicación. Esto resulta útil cuando hay requisitos estrictos para la auditoría de datos y se debe usar una ubicación específica para registrar las transferencias fallidas.De forma predeterminada, todos los archivos defectuosos se copian de la ruta de Cloud Storage proporcionada en el campo Ruta de Cloud Storage de replicación de datos de la interfaz web.
Patrón de ruta final de archivos de datos incorrectos:
gs://BASE_FILE_PATH/MASS_TRANSFER_ID/SOURCE_TABLE_NAME/bad_files/REPLICATION_JOB_NAME/REPLICATION_JOB_ID/BAD_FILE_NAME
Ejemplo:
gs://slt_to_cdf_bucket/001/MARA/bad_files/MaraRepl/05f97349-7398-11ec-9443-8 ac0640fc83c/20220205_1901205168830_DATA_INIT.xml
Los criterios para determinar si un archivo es incorrecto son que el archivo XML esté dañado o no sea válido, que falten valores de clave principal o que haya un problema de incompatibilidad de tipos de datos de campo.
Información de asistencia
Productos y versiones de SAP compatibles
- Versión 702 de SAP_BASIS, nivel de SP 0016 y versiones posteriores.
- Versión 702 de SAP_ABA, nivel de SP 0016 y posteriores.
- Versión 2011_1_700 de DMIS, SP-Level 0017 y versiones posteriores.
Versiones de SLT admitidas
Se admiten las versiones 2 y 3 de SLT.
Modelos de despliegue de SAP admitidos
SLT como sistema independiente o insertado en el sistema de origen.
Notas de SAP que deben implementarse antes de empezar a usar SLT
Si tu paquete de asistencia no incluye correcciones de clase /UI2/CL_JSON para PL12 o versiones posteriores, implementa la última nota SAP para correcciones de clase /UI2/CL_JSON, como la nota SAP 2798102 para PL12.
Recomendación: Implemente las notas de SAP recomendadas por el informe CNV_NOTE_ANALYZER_SLT en función de la condición del sistema central o de origen. Para obtener más información, consulta la nota de SAP 3016862 (se requiere inicio de sesión en SAP).
Si SAP ya está configurado, no es necesario implementar ninguna nota adicional. Si tienes algún error o problema específico, consulta la nota de SAP central de tu versión de SLT.
Límites del volumen de datos o de la anchura de los registros
No hay ningún límite definido para el volumen de datos extraídos ni para la anchura de los registros.
Rendimiento esperado del complemento de replicación SLT de SAP
En un entorno configurado según las directrices de Optimizar el rendimiento, el complemento puede extraer unos 13 GB por hora para la carga inicial y 3 GB por hora para la replicación (CDC). El rendimiento real puede variar en función de la carga del sistema de Cloud Data Fusion y SAP, o del tráfico de red.
Compatibilidad con la extracción de deltas de SAP (datos modificados)
Se admite la extracción delta de SAP.
Obligatorio: emparejamiento de tenants para instancias de Cloud Data Fusion
El peering de tenants es obligatorio cuando la instancia de Cloud Data Fusion se crea con una dirección IP interna. Para obtener más información sobre el emparejamiento de tenants, consulta Crear una instancia privada.
Solucionar problemas
La tarea de replicación se reinicia continuamente
Si el trabajo de replicación se reinicia automáticamente, aumenta la memoria del clúster del trabajo de replicación y vuelve a ejecutarlo.
Duplicados en el receptor de BigQuery
Si defines el número de trabajos paralelos en la configuración avanzada del complemento de replicación de SAP SLT, cuando las tablas sean grandes, se producirá un error que provocará que haya columnas duplicadas en el receptor de BigQuery.
Para evitar este problema, elimina las tareas paralelas para cargar datos.
Situaciones de error
En la siguiente tabla se muestran algunos mensajes de error habituales (el texto entre comillas se sustituirá por los valores reales en el tiempo de ejecución):
| ID de mensaje | Mensaje | Acción recomendada |
|---|---|---|
CDF_SAP_SLT_01402 |
Service account type is not defined for
SERVICE_ACCT_NAME_FROM_UI. |
Asegúrate de que la ruta de Cloud Storage proporcionada sea correcta. |
CDF_SAP_SLT_01403 |
Service account key provided is not valid due to error:
ROOT_CAUSE. Please provide a valid service account key for
service account type : SERVICE_ACCT_NAME_FROM_UI. |
Consulta la causa raíz que se muestra en el mensaje y toma las medidas oportunas. |
CDF_SAP_SLT_01404 |
Mass Transfer ID could not be found. Please ensure that it exists
in given GCS Bucket. |
Comprueba que el ID de transferencia masiva proporcionado tenga el formato correcto. |
CDF_SAP_SLT_01502 |
The specified data replication GCS path 'slt_to_cdf_bucket_1' or
Mass Transfer ID '05C' could not be found. Please ensure that it exists in
GCS. |
Asegúrate de que la ruta de Cloud Storage proporcionada sea correcta. |
CDF_SAP_SLT_01400 |
Metadata file not found. The META_INIT.json file is not present or
file is present with invalid format. |
Consulta la causa raíz que se muestra en el mensaje y toma las medidas oportunas. |
CDF_SAP_SLT_03408 |
Failed to start the event reader. |
Consulta la causa raíz que se muestra en el mensaje y toma las medidas oportunas. |
CDF_SAP_SLT_03409 |
Error while processing TABLE_NAME file for source table
gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/TABLE_NAME
/FILE_NAME. Root cause: ROOT_CAUSE. |
Consulta la causa raíz que se muestra en el mensaje y toma las medidas oportunas. |
CDF_SAP_SLT_03410 |
Failed to replicate data for source table TABLE_NAME
from file: gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/
TABLE_NAME/FILE_NAME. Root cause:
ROOT_CAUSE. |
Consulta la causa raíz que se muestra en el mensaje y toma las medidas oportunas. |
CDF_SAP_SLT_03411 |
Failed data replication for source table TABLE_NAME.
Root cause: ROOT_CAUSE. |
Consulta la causa raíz que se muestra en el mensaje y toma las medidas oportunas. |
CDF_SAP_SLT_03412 |
Failed to create target table for source table
TABLE_NAME. Root cause: ROOT_CAUSE. |
Consulta la causa raíz que se muestra en el mensaje y toma las medidas oportunas. |
Asignación de tipos de datos
En la siguiente tabla se muestra la asignación entre los tipos de datos que se usan en las aplicaciones SAP y Cloud Data Fusion.
| Tipo de datos de SAP | Tipo ABAP | Descripción (SAP) | Tipo de datos de Cloud Data Fusion |
|---|---|---|---|
| Numérico | |||
| INT1 | b | Entero de 1 byte | int |
| INT2 | s | Entero de 2 bytes | int |
| INT4 | i | Entero de 4 bytes | int |
| INT8 | 8 | Entero de 8 bytes | long |
| DIC | p | Número empaquetado en formato BCD (DEC) | decimal |
| DF16_DEC DF16_RAW |
a | Punto flotante decimal de 8 bytes IEEE 754r | decimal |
| DF34_DEC DF34_RAW |
e | Punto flotante decimal IEEE 754r de 16 bytes | decimal |
| FLTP | f | Número de punto flotante binario. | double |
| Carácter | |||
| CHAR LCHR |
c | Cadena de caracteres | string |
| SSTRING GEOM_EWKB |
cadena | Cadena de caracteres | string |
| STRING GEOM_EWKB |
cadena | CLOB de cadena de caracteres | bytes |
| NUMC ACCP |
n | Texto numérico | string |
| Byte | |||
| RAW LRAW |
x | Datos binarios | bytes |
| RAWSTRING | xstring | BLOB de cadena de bytes | bytes |
| Fecha y hora | |||
| DATS | d | Fecha | date |
| Tims | t | Hora | time |
| TIMESTAMP | utcl | ( Utclong ) Marca de tiempo |
timestamp |
Siguientes pasos
- Consulta más información sobre Cloud Data Fusion.
- Consulta más información sobre SAP en Google Cloud.