Esta página descreve como ativar a replicação em tempo real de dados de aplicativos SAP para Google Cloud usando o SAP Landscape Transformation (SLT). O conteúdo se aplica aos plug-ins SAP SLT Replication e SAP SLT No RFC Replication, que estão disponíveis no Hub do Cloud Data Fusion. Ele mostra as configurações do sistema de origem do SAP, do SLT, do Cloud Storage e do Cloud Data Fusion para fazer o seguinte:
- Envie metadados e dados de tabela do SAP para Google Cloud usando o SAP SLT.
- Crie um job de replicação do Cloud Data Fusion que leia os dados de um bucket do Cloud Storage.
A replicação SAP SLT permite replicar seus dados continuamente e em tempo real de origens SAP no BigQuery. É possível configurar e executar transferências de dados de sistemas SAP sem programação.
O processo de replicação de SLT do Cloud Data Fusion é o seguinte:
- Os dados vêm de um sistema de origem do SAP.
- O SLT rastreia e lê os dados e os envia para o Cloud Storage.
- O Cloud Data Fusion extrai dados do bucket de armazenamento e os grava no BigQuery.
É possível transferir dados de sistemas SAP com suporte, incluindo sistemas SAP hospedados em Google Cloud.
Para mais informações, consulte a Visão geral do SAP no Google Cloud e os detalhes de suporte.
Antes de começar
Para usar esse plug-in, é necessário ter conhecimento dos domínios nas seguintes áreas:
- Criar pipelines no Cloud Data Fusion
- Gerenciamento de acesso com o IAM
- Como configurar sistemas de planejamento de recursos empresariais (ERP) locais e da SAP Cloud
Administradores e usuários que executam as configurações
As tarefas nesta página são realizadas por pessoas com as seguintes funções no Google Cloud ou no sistema SAP:
| Tipo de usuário | Descrição |
|---|---|
| Administrador do Google Cloud | Os usuários atribuídos a esse papel são administradores de contas do Google Cloud. |
| Usuário do Cloud Data Fusion | Os usuários atribuídos a esse papel estão autorizados a projetar e executar pipelines
de dados. Eles recebem, no mínimo, o papel de leitor do Data Fusion
(
roles/datafusion.viewer). Se você estiver usando o controle de acesso baseado em papéis, talvez seja necessário usar outros papéis.
|
| Administrador do SAP | Os usuários atribuídos a essa função são administradores do sistema SAP. Eles têm acesso para fazer o download de softwares do site de serviços da SAP. Não é um papel do IAM. |
| Usuário SAP | Os usuários atribuídos a esse papel estão autorizados a se conectar a um sistema SAP. Não é um papel do IAM. |
Operações de replicação com suporte
O plug-in SAP SLT Replication oferece suporte às seguintes operações:
Modelagem de dados: todas as operações de modelagem de dados (registro insert, delete e
update) são compatíveis com esse plug-in.
Definição de dados: conforme descrito na Nota SAP 2055599 (é necessário fazer login no suporte do SAP para visualizar), há limitações quanto às mudanças na estrutura da tabela do sistema de origem que são replicadas automaticamente pelo SLT. Algumas operações de definição de dados não são compatíveis com o plug-in. Você precisa propagá-las manualmente.
- Compatível:
- Adicionar campo sem chave (depois de fazer mudanças no SE11, ative a tabela usando o SE14)
- Não compatível:
- Adicionar/excluir campo de chave
- Excluir campo sem chave
- Modificar tipos de dados
Requisitos do SAP
Os itens a seguir são obrigatórios no sistema SAP:
- O servidor SLT Server versão 2011 SP17 ou posterior está instalado no sistema SAP de origem (incorporado) ou como um sistema de hub SLT dedicado.
- Seu sistema SAP de origem é SAP ECC ou SAP S/4HANA, que oferece suporte à DMIS 2011 SP17 ou mais recente, como DMIS 2018, DMIS 2020.
- O complemento da interface do usuário SAP precisa ser compatível com a versão do SAP NetWeaver.
Seu pacote de suporte é compatível com a classe
/UI2/CL_JSONPL 12ou mais recente. Caso contrário, implemente a última Nota SAP para a classe/UI2/CL_JSONcorrectionsde acordo com a versão do complemento da interface do usuário, como a Nota SAP 2798102 paraPL12.A seguinte segurança está em vigor:
Requisitos do Cloud Data Fusion
- Você precisa de uma instância do Cloud Data Fusion, versão 6.4.0 ou mais recente, qualquer edição.
- A conta de serviço atribuída à instância do Cloud Data Fusion recebe os papéis necessários (consulte Como conceder permissão de usuário à conta de serviço).
- Para instâncias particulares do Cloud Data Fusion, o peering de VPC é obrigatório.
Requisitos doGoogle Cloud
- Ative a API Cloud Storage no Google Cloud projeto.
- O usuário do Cloud Data Fusion precisa ter permissão para criar pastas no bucket do Cloud Storage. Consulte Papéis do IAM para o Cloud Storage.
- Opcional: defina a política de retenção, se exigido pela sua organização.
Criar o bucket de armazenamento
Antes de criar um job de replicação de SLT, crie o bucket do Cloud Storage. O job transfere dados para o bucket e atualiza o bucket de preparação a cada cinco minutos. Quando você executa o job, o Cloud Data Fusion lê os dados no bucket de armazenamento e os grava no BigQuery.
Se o SLT estiver instalado em Google Cloud
O servidor SLT precisa ter permissão para criar e modificar objetos do Cloud Storage no bucket que você criou.
Conceda, no mínimo, os seguintes papéis à conta de serviço:
- Criador do token da conta de serviço (
roles/iam.serviceAccountTokenCreator) - Consumidor do Service Usage (
roles/serviceusage.serviceUsageConsumer) - Administrador de objetos do Storage (
roles/storage.objectAdmin)
Se o SLT não estiver instalado no Google Cloud
Instale o Cloud VPN ou o Cloud Interconnect entre a VM do SAP e Google Cloud para permitir a conexão com um endpoint de metadados interno. Consulte Configurar o Acesso privado do Google para hosts locais.
Se não for possível mapear os metadados internos:
Instale a Google Cloud CLI com base no sistema operacional da infraestrutura em que o SLT está sendo executado.
Crie uma conta de serviço no projeto Google Cloud em que o Cloud Storage está ativado.
No sistema operacional do SLT, autorize o acesso a Google Cloud com uma conta de serviço.
Crie uma chave de API para a conta de serviço e autorize o escopo relacionado ao Cloud Storage.
Importe a chave da API para a CLI gcloud instalada anteriormente usando a CLI.
Para ativar o comando da CLI do gcloud que imprime o token de acesso, configure o comando do sistema operacional SAP na ferramenta de transação SM69 no sistema SLT.
Imprimir um token de acesso
O administrador do SAP configura o comando do sistema operacional, SM69, que
recupera um token de acesso de Google Cloud.
Crie um script para imprimir um token de acesso e configure um comando do sistema operacional
SAP para chamar o script como usuário <sid>adm do host do SAP LT Replication Server.
Linux
Para criar um comando do SO:
No host do SAP LT Replication Server, em um diretório acessível a
<sid>adm, crie um script bash que contenha as seguintes linhas:PATH_TO_GCLOUD_CLI/bin/gcloud auth print-access-token SERVICE_ACCOUNT_NAMEUsando a interface do usuário do SAP, crie um comando de SO externo:
- Insira a transação
SM69. - Clique em Criar.
- Na seção Comando do painel Comando externo, insira
o nome do comando, como
ZGOOGLE_CDF_TOKEN. Na seção Definição:
- No campo Comando do sistema operacional, insira
shcomo a extensão do arquivo de script. No campo Parâmetros do comando do sistema operacional, digite:
/PATH_TO_SCRIPT/FILE_NAME.sh
- No campo Comando do sistema operacional, insira
Clique em Salvar.
Para testar o script, clique em Executar.
Clique em Executar novamente.
Um token Google Cloud é retornado e exibido na parte de baixo do painel da interface do usuário do SAP.
- Insira a transação
Windows
Use a interface do usuário do SAP e crie um comando de sistema operacional externo:
- Insira a transação
SM69. - Clique em Criar.
- Na seção Comando do painel Comando externo, insira o
nome do comando, como
ZGOOGLE_CDF_TOKEN. Na seção Definição:
- No campo Operating System Command, digite
cmd /c. No campo Parâmetros do comando do sistema operacional, digite:
gcloud auth print-access-token SERVICE_ACCOUNT_NAME
- No campo Operating System Command, digite
Clique em Salvar.
Para testar o script, clique em Executar.
Clique em Executar novamente.
Um token Google Cloud é retornado e exibido na parte de baixo do painel da interface do usuário SAP.
Requisitos de SLT
O conector SLT precisa ter a seguinte configuração:
- O conector oferece suporte ao SAP ECC NW 7.02, DMIS 2011 SP17 e versões mais recentes.
- Configure uma conexão RFC ou de banco de dados entre o SLT e o sistema do Cloud Storage.
- Configure os certificados SSL:
- Faça o download dos seguintes certificados de CA no
repositório Google Trust Services:
- GTS Root R1
- GTS CA 1C3
- Na interface do usuário do SAP, use a transação
STRUSTpara importar os certificados raiz e subordinados para a pastaSSL Client (Standard) PSE.
- Faça o download dos seguintes certificados de CA no
repositório Google Trust Services:
- O Gerenciador de comunicações da Internet (ICM, na sigla em inglês) precisa ser configurado para HTTPS. Verifique se
as portas HTTP e HTTPS são mantidas e ativadas no sistema SAP SLT.
Isso pode ser verificado pelo código da transação
SMICM > Services. - Ative o acesso às APIs Google Cloud na VM em que o sistema SAP SLT está hospedado. Isso permite a comunicação particular entre os serviçosGoogle Cloud sem roteamento pela Internet pública.
- Verifique se a rede pode oferecer suporte ao volume e à velocidade necessários da transferência de dados entre a infraestrutura da SAP e o Cloud Storage. Para uma instalação bem-sucedida, recomendamos o Cloud VPN e/ou o Cloud Interconnect. A taxa de transferência da API de streaming depende das cotas do cliente concedidas ao seu projeto do Cloud Storage.
Configurar o servidor de replicação do SLT
O usuário da SAP executa as etapas a seguir.
Nas etapas a seguir, você vai conectar o servidor do SLT ao sistema de origem e ao bucket no Cloud Storage, especificando o sistema de origem, as tabelas de dados a serem replicadas e o bucket de armazenamento de destino.
Configurar o SDK ABAP do Google
Para configurar o SLT para a replicação de dados (uma vez por instância do Cloud Data Fusion), siga estas etapas:
Para configurar o conector SLT, o SAP-User insere as seguintes informações na tela de configuração (transação SAP
/GOOG/CDF_SETTINGS) sobre a chave da conta de serviço Google Cloud para transferir dados para o Cloud Storage. Configure as seguintes propriedades na tabela /GOOG/CDF_CLT_KY usando a transação SE16 e observe esta chave:- NOME: o nome da chave da conta de serviço (por exemplo,
CDFSLT). - SERVICE ACCOUNT NAME: o nome da conta de serviço do IAM.
- SCOPE: o escopo da conta de serviço
- ID DO PROJETO: o ID do seu Google Cloud projeto
- Opcional: EXT OS Command: use esse campo somente se o SLT não estiver instalado em Google Cloud
CLASSE AUTH: se o comando do SO estiver configurado na tabela
/GOOG/CDF_CLT_KY, use o valor fixo:/GOOG/CDF_CL_GCP_AUTH.TOKEN REFRESH SEC: duração da atualização do token de autorização
- NOME: o nome da chave da conta de serviço (por exemplo,

Crie a configuração de replicação
Crie uma configuração de replicação no código da transação: LTRC.
- Antes de prosseguir com a configuração do LTRC, verifique se a conexão RFC entre o SLT e o sistema SAP de origem está estabelecida.
- Para uma configuração de SLT, pode haver várias tabelas SAP atribuídas para replicação.
Acesse o código da transação
LTRCe clique em Nova configuração.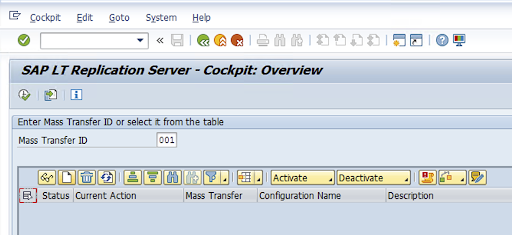
Insira o Nome da configuração e a Descrição e clique em Próxima.
Especifique a conexão RFC do sistema de origem SAP e clique em Próxima.
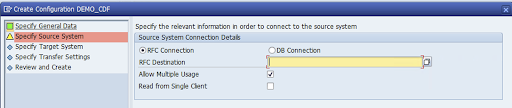
Em "Detalhes da conexão do sistema de destino", selecione Outro.
Expanda o campo Cenário para comunicação RFC, selecione SDK SLT e clique em Próxima.
Acesse a janela Specify Transfer Settings e insira o nome do aplicativo:
ZGOOGLE_CDF.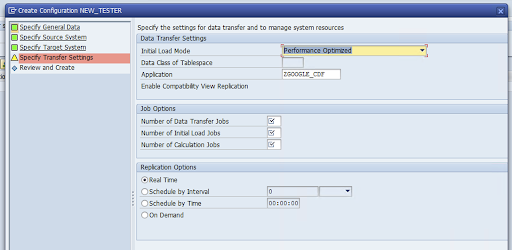
Insira o Número de jobs de transferência de dados, o Número de jobs de carregamento inicial e o Número de jobs de cálculo. Para mais informações sobre desempenho, consulte o Guia de otimização de desempenho do SAP LT Replication Server.
Clique em Tempo real > Próximo.
Revise a configuração e clique em Salvar. Anote o ID de transferência em massa para as próximas etapas.
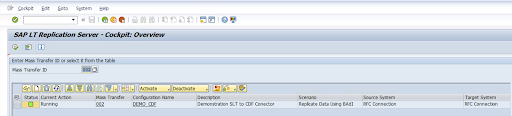
Para manter o ID de transferência em massa e os detalhes da tabela do SAP, execute a transação SAP:
/GOOG/CDF_SETTINGS.Clique em Executar ou pressione
F8.Crie uma nova entrada clicando no ícone de anexar linha.
Insira o ID da transferência em massa, a chave de transferência em massa, o nome da chave do GCP e o bucket do GCS de destino. Marque a caixa de seleção Is Active e salve as mudanças.
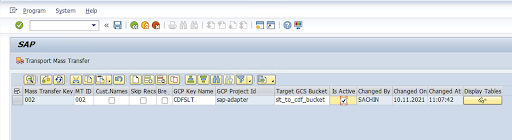
Selecione a configuração na coluna Nome da configuração e clique em Provisionamento de dados.
Opcional: personalize os nomes da tabela e dos campos.
Clique em Nomes personalizados e salve.
Clique em Tela.
Crie uma nova entrada clicando nos botões Anexar linha ou Criar.
Insira o nome da tabela SAP e da tabela externa para usar no BigQuery e salve as alterações.
Clique no botão Visualizar na coluna Campos de exibição para manter o mapeamento dos campos da tabela.
Uma página com mapeamentos sugeridos é aberta. Opcional: edite o Nome do campo temporário e a Descrição do campo e salve os mapeamentos.
Acesse a transação LTRC.
Selecione o valor na coluna Nome da configuração e clique em Provisionamento de dados.
Insira o nome da tabela no campo Nome da tabela no banco de dados e selecione o cenário de replicação.
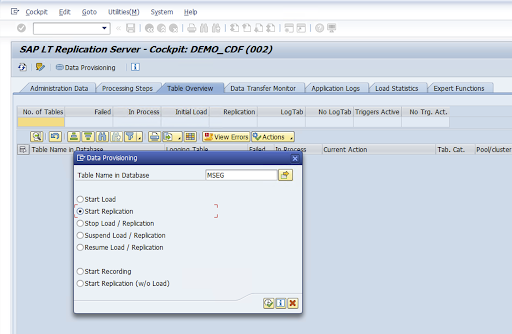
Clique em Executar. Isso aciona a implementação do SDK do SLT e começa a transferir os dados para o bucket de destino no Cloud Storage.
Instalar arquivos de transporte SAP
Para projetar e executar jobs de replicação no Cloud Data Fusion, os componentes da SAP são entregues como arquivos de transporte SAP arquivados em um arquivo ZIP. O download fica disponível quando você implanta o plug-in no Hub do Cloud Data Fusion.
Para instalar os transportes SAP, siga estas etapas:
Etapa 1: fazer upload dos arquivos de solicitação de transporte
- Faça login no sistema operacional da instância do SAP.
- Use o código de transação
AL11do SAP para acessar o caminho da pastaDIR_TRANS. Normalmente, o caminho é/usr/sap/trans/. - Copie os cofiles para a pasta
DIR_TRANS/cofiles. - Copie os arquivos de dados para a pasta
DIR_TRANS/data. - Defina o usuário e o grupo de dados e o coarquivo como
<sid>admesapsys.
Etapa 2: importar os arquivos de solicitação de transporte
O administrador da SAP pode importar os arquivos de solicitação de transporte usando o sistema de gerenciamento de transporte SAP ou o sistema operacional:
Sistema de gerenciamento de transporte SAP
- Faça login no sistema SAP como administrador da SAP.
- Digite o STMS da transação.
- Clique em Visão geral > Importações.
- Na coluna "Fila", clique duas vezes no SID atual.
- Clique em Extras > Outras solicitações > Adicionar.
- Selecione o ID da solicitação de transporte e clique em Continuar.
- Selecione a solicitação de transporte na fila de importação e clique em Solicitar > Importar.
- Digite o número do cliente.
Na guia Opções, selecione Substituir originais e Ignorar a versão inválida do componente (se disponível).
Opcional: para reimportar os transportes mais tarde, clique em Deixar solicitações de transporte na fila para importação posterior e Importar solicitações de transporte novamente. Isso é útil para upgrades do sistema SAP e restaurações de backup.
Clique em Continuar.
Verifique se o módulo da função e os papéis de autorização foram importados com êxito usando transações, como
SE80ePFCG.
Sistema operacional
- Faça login no sistema SAP como administrador da SAP.
Adicione solicitações ao buffer de importação:
tp addtobuffer TRANSPORT_REQUEST_ID SIDPor exemplo:
tp addtobuffer IB1K903958 DD1Importe as solicitações de transporte:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238Substitua
NNNpelo número do cliente. Por exemplo:tp import IB1K903958 DD1 client=800 U1238Verifique se o módulo da função e os papéis de autorização foram importados com êxito usando as transações apropriadas, como
SE80ePFCG.
Autorizações SAP necessárias
Para executar um pipeline de dados no Cloud Data Fusion, você precisa de um usuário SAP. O usuário
SAP precisa ser do tipo "Comunicações" ou "Caixa de diálogo". Para evitar o uso de recursos de caixa de diálogo
do SAP, o tipo de comunicação é recomendado. Os usuários podem ser criados pelo administrador
do SAP usando o código de transação SU01.
As autorizações SAP são necessárias para manter e configurar o conector para SAP, uma combinação de objetos de autorização padrão e novos do conector SAP. Você mantém objetos de autorização com base nas políticas de segurança da sua organização. A lista a seguir descreve algumas autorizações importantes necessárias para o conector:
Objeto de autorização: o objeto de autorização
ZGOOGCDFMTé enviado como parte do papel de solicitação de transporte.Criação de função: crie uma função usando o código de transação
PFCG.
Para objetos de autorização SAP padrão, sua organização gerencia as permissões com o próprio mecanismo de segurança.
Para objetos de autorização personalizados, forneça valores nos campos de autorização para objetos de autorização
ZGOOGCDFMT.Para controle de acesso detalhado, o
ZGOOGCDFMToferece autorização com base em grupos de autorização. Os usuários com acesso total, parcial ou nenhum acesso a grupos de autorização recebem acesso com base no grupo de autorização atribuído à função./GOOG/SLT_CDF_AUTH: função com acesso a todos os grupos de autorização. Para restringir o acesso específico a um determinado grupo de autorização, mantenha o grupo de autorização FICDF na configuração.
Criar um destino RFC para a origem
Antes de começar a configuração, verifique se a conexão RFC está estabelecida entre a origem e o destino.
Acesse o código da transação
SM59.Clique em Criar > Tipo de conexão 3 (conexão ABAP).
Na janela Configurações técnicas, insira os detalhes sobre o destino do RFC.
Clique na guia Login e segurança para manter as credenciais do RFC (usuário e senha do RFC).
Clique em Salvar.
Clique em Teste de conexão. Depois de um teste bem-sucedido, você pode continuar.
Verifique se o teste de autorização de RFC foi concluído.
Clique em Utilities > Test > Authorization Test.
Configurar o plug-in
Para configurar o plug-in, implante-o no Hub, crie um job de replicação e configure a origem e o destino com as etapas a seguir.
Implantar o plug-in no Cloud Data Fusion
O usuário do Cloud Data Fusion segue as etapas abaixo.
Antes de executar o job de replicação do Cloud Data Fusion, implante o plug-in de replicação do SAP SLT:
Acesse sua instância:
No Google Cloud console, acesse a página Instâncias do Cloud Data Fusion.
Ative a replicação em uma instância nova ou atual:
- Para uma nova instância, clique em Criar instância, digite um nome de instância, clique em Adicionar aceleradores, selecione a caixa de seleção Replicação e clique em Salvar.
- Para uma instância atual, consulte Ativar a replicação em uma instância atual.
Clique em Visualizar instância para abrir a instância na interface da Web do Cloud Data Fusion.
Clique em Hub.
Acesse a guia SAP, clique em SAP SLT e em Plug-in SAP SLT Replication ou Plug-in SAP SLT No RFC Replication.
Clique em Implantar.
Criar um job de replicação
O plug-in de replicação SAP SLT lê o conteúdo das tabelas da SAP usando um bucket de preparação da API Cloud Storage.
Para criar um job de replicação para a transferência de dados, siga estas etapas:
Na instância aberta do Cloud Data Fusion, clique em Início > Replicação > Criar um job de replicação. Se não houver a opção Replicação, ative a replicação para a instância.
Insira um Nome e uma Descrição exclusivos para o job de replicação.
Clique em Próxima.
Configurar a origem
Configure a fonte inserindo valores nos seguintes campos:
- ID do projeto: o ID do projeto Google Cloud (este campo é preenchido automaticamente).
Caminho do GCS da replicação de dados: o caminho do Cloud Storage que contém dados para replicação. Ele precisa ser o mesmo caminho configurado nos jobs da SAP SLT. Internamente, o caminho fornecido é concatenado com
Mass Transfer IDeSource Table Name:Formato:
gs://<base-path>/<mass-transfer-id>/<source-table-name>Exemplo:
gs://slt_bucket/012/MARAGUID: o GUID do SLT, um identificador exclusivo atribuído ao ID de transferência em massa do SLT da SAP.
ID de transferência em massa: o ID de transferência em massa do SLT é um identificador exclusivo atribuído à configuração no SAP SLT.
Caminho do GCS da biblioteca SAP JCo: o caminho de armazenamento que contém os arquivos da biblioteca SAP JCo enviados pelo usuário. As bibliotecas JCo da SAP podem ser baixadas no Portal de suporte da SAP. (Removida na versão 0.10.0 do plug-in.)
Host do servidor SLT: nome do host ou endereço IP do servidor SLT. (Removido na versão 0.10.0 do plug-in.)
Número do sistema SAP: número do sistema de instalação fornecido pelo administrador do sistema (por exemplo,
00). (Removido na versão 0.10.0 do plug-in).Cliente SAP: o cliente SAP a ser usado (por exemplo,
100). Removido na versão 0.10.0 do plug-in.Idioma SAP: linguagem de logon SAP (por exemplo,
EN). Removido na versão 0.10.0 do plug-in.Nome de usuário de logon SAP: nome de usuário SAP. (Removida na versão 0.10.0 do plug-in.)
- Recomendado: se o nome de usuário do SAP Logon mudar periodicamente, use uma macro.
Senha de logon SAP (M): senha de usuário SAP para autenticação do usuário.
- Recomendado: use macros seguras para valores sensíveis, como senhas. (Removido na versão 0.10.0 do plug-in.)
Suspender a replicação do SLT quando o job do CDF for interrompido: tenta interromper o job de replicação do SLT (para as tabelas envolvidas) quando o job de replicação do Cloud Data Fusion for interrompido. Pode falhar se o job no Cloud Data Fusion for interrompido inesperadamente.
Replicar dados atuais: indica se os dados atuais das tabelas de origem serão replicados. Por padrão, os jobs replicam os dados atuais das tabelas de origem. Se definido como
false, todos os dados existentes nas tabelas de origem são ignorados, e apenas as mudanças que acontecem após o início do job são replicadas.Chave da conta de serviço: a chave a ser usada ao interagir com o Cloud Storage. A conta de serviço precisa ter permissão para gravar no Cloud Storage. Quando executado em uma Google Cloud VM, ele precisa ser definido como
auto-detectpara usar a conta de serviço anexada à VM.
Clique em Próxima.
Configurar o destino
Para gravar dados no BigQuery, o plug-in precisa de acesso de gravação ao BigQuery e a um bucket de estágio. Os eventos de mudança são gravados primeiro em lotes do SLT para o Cloud Storage. Em seguida, eles são carregados em tabelas de preparação no BigQuery. As mudanças da tabela de preparação são mescladas na tabela de destino final usando uma consulta de mesclagem do BigQuery.
A tabela de destino final inclui todas as colunas originais da tabela de origem
e mais uma coluna _sequence_num. O número de sequência garante que
os dados não sejam duplicados ou perdidos em cenários de falha do replicador.
Configure a fonte inserindo valores nos seguintes campos:
- ID do projeto: projeto do conjunto de dados do BigQuery. Quando executado em um cluster do Dataproc, esse campo pode ser deixado em branco, o que vai usar o projeto do cluster.
- Credenciais: consulte Credenciais.
- Chave da conta de serviço: o conteúdo da chave da conta de serviço a ser usado ao interagir com o Cloud Storage e o BigQuery. Quando executada em um cluster do Dataproc, ela precisa ficar em branco, usando a conta de serviço do cluster.
- Nome do conjunto de dados: nome do conjunto de dados a ser criado no BigQuery. É opcional e, por padrão, o nome do conjunto de dados é o mesmo que o nome do banco de dados de origem. Um nome válido só pode conter letras, números e sublinhados, e o comprimento máximo é de 1.024 caracteres. Todos os caracteres inválidos são substituídos por sublinhados no nome do conjunto de dados final, e todos os caracteres que excedem o limite de comprimento são truncados.
- Nome da chave de criptografia: a chave de criptografia gerenciada pelo cliente (CMEK, na sigla em inglês) usada para
proteger os recursos criados por esse destino. O nome da chave de criptografia precisa estar
no formato
projects/<project-id>/locations/<key-location>/keyRings/<key-ring-name>/cryptoKeys/<key-name>. - Local: o local em que o conjunto de dados do BigQuery e o bucket de preparação do Cloud Storage são criados. Por exemplo,
us-east1para buckets regionais,uspara buckets multirregionais (consulte Locais). Esse valor será ignorado se um bucket existente for especificado, já que o bucket de preparação e o conjunto de dados do BigQuery são criados no mesmo local que esse bucket. Bucket de preparação: o bucket em que os eventos de alteração são gravados antes de serem carregados nas tabelas de preparação. As mudanças são gravadas em um diretório que contém o nome e o namespace do replicador. É seguro usar o mesmo bucket em vários replicadores na mesma instância. Se ele for compartilhado por replicadores em várias instâncias, verifique se o namespace e o nome são exclusivos. Caso contrário, o comportamento será indefinido. O bucket precisa estar no mesmo local que o conjunto de dados do BigQuery. Se não for fornecido, um novo bucket será criado para cada job com o nome
df-rbq-<namespace-name>-<job-name>-<deployment-timestamp>.Intervalo de carregamento (segundos): número de segundos a serem aguardados antes de carregar um lote de dados no BigQuery.
Prefixo da tabela de preparação: as mudanças são gravadas primeiro em uma tabela de preparação antes de serem mescladas à tabela final. Os nomes das tabelas de preparação são gerados preenchendo esse prefixo ao nome da tabela de destino.
Exigir intervenção manual de exclusão: define se é necessário realizar uma ação administrativa manual para excluir tabelas e conjuntos de dados quando um evento de exclusão de tabela ou de banco de dados é encontrado. Quando definido como "true", o replicador não exclui uma tabela ou um conjunto de dados. Em vez disso, ele falha e tenta novamente até que a tabela ou o conjunto de dados não exista. Se o conjunto de dados ou a tabela não existir, nenhuma intervenção manual será necessária. O evento é pulado normalmente.
Ativar exclusões suaves: se definido como verdadeiro, quando um evento de exclusão for recebido pelo destino, a coluna
_is_deleteddo registro será definida comotrue. Caso contrário, o registro será excluído da tabela do BigQuery. Essa configuração não é executada para uma origem que gera eventos fora de ordem, e os registros são sempre excluídos temporariamente da tabela do BigQuery.
Clique em Próxima.
Credenciais
Se o plug-in for executado em um cluster do Dataproc, a chave da conta de serviço precisa ser definida como detecção automática. As credenciais são lidas automaticamente no ambiente do cluster.
Se o plug-in não for executado em um cluster do Dataproc, o caminho para uma chave de conta de serviço precisará ser fornecido. A chave da conta de serviço pode ser encontrada na página do IAM no console Google Cloud . Verifique se a chave da conta tem permissão para acessar o BigQuery. O arquivo de chave da conta de serviço precisa estar disponível em todos os nós do cluster e ser legível por todos os usuários que executam o job.
Limitações
- As tabelas precisam ter uma chave primária para serem replicadas.
- Não é possível renomear tabelas.
- As alterações de tabela têm suporte parcial.
- Uma coluna não nula atual pode ser alterada para uma coluna anulável.
- Novas colunas com valor nulo podem ser adicionadas a uma tabela existente.
- Qualquer outro tipo de alteração no esquema da tabela vai falhar.
- As mudanças na chave primária não falharão, mas os dados atuais não serão reescritos para obedecer à exclusividade na nova chave primária.
Selecionar tabelas e transformações
Na etapa Selecionar tabelas e transformações, uma lista de tabelas selecionadas para replicação no sistema SLT aparece.
- Selecione as tabelas a serem replicadas.
- Opcional: selecione outras operações de esquema, como Inserções, Atualizações ou Exclusões.
- Para conferir o esquema, clique em Colunas a replicar em uma tabela.
Opcional: para renomear colunas no esquema, siga estas etapas:
- Ao visualizar o esquema, clique em Transformar > Renomear.
- No campo Rename, insira um novo nome e clique em Apply.
- Para salvar o novo nome, clique em Atualizar e Salvar.
Clique em Próxima.
Opcional: configurar propriedades avançadas
Se você souber quantos dados está replicando em uma hora, poderá selecionar a opção adequada.
Revisar avaliação
A etapa Analisar avaliação verifica problemas de esquema, recursos ausentes ou problemas de conectividade que ocorrem durante a replicação.
Na página Avaliar avaliação, clique em Conferir mapeamentos.
Se ocorrer algum problema, ele precisará ser resolvido antes de continuar.
Opcional: se você renomeou colunas ao selecionar as tabelas e as transformações, verifique se os novos nomes estão corretos nesta etapa.
Clique em Próxima.
Conferir o resumo e implantar o job de replicação
Na página Revisão dos detalhes do job de replicação, revise as configurações e clique em Implantar job de replicação.
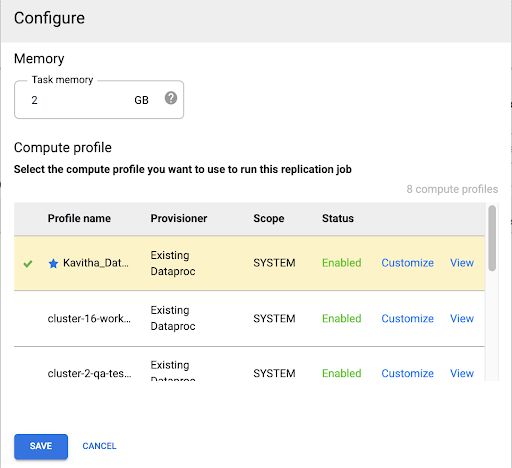
Selecionar um perfil do Compute Engine
Depois de implantar o job de replicação, clique em Configurar em qualquer página da interface da Web do Cloud Data Fusion.
Selecione o perfil do Compute Engine que você quer usar para executar esse job de replicação.
Clique em Salvar.
Iniciar o job de replicação
- Para executar o job de replicação, clique em Iniciar.

Opcional: otimizar o desempenho
Por padrão, o plug-in é configurado para desempenho ideal. Para mais otimizações, consulte Argumentos de ambiente de execução.
O desempenho da comunicação entre o SLT e o Cloud Data Fusion depende dos seguintes fatores:
- SLT no sistema de origem em comparação com um sistema SLT central dedicado (opção preferencial)
- Processamento de jobs em segundo plano no sistema SLT
- Processos de trabalho de caixa de diálogo no sistema SAP de origem
- O número de processos de jobs em segundo plano alocados para cada ID de transferência em massa na guia Administração do LTRC
- Configurações de LTRS
- Hardware (CPU e memória) do sistema de SLT
- O banco de dados usado (por exemplo, HANA, Sybase ou DB2)
- A largura de banda da Internet (conectividade entre o sistema SAP e Google Cloud pela Internet)
- Utilização (carga) preexistente no sistema
- O número de colunas na tabela. Com mais colunas, a replicação fica lenta e a latência pode aumentar.
Os seguintes tipos de leitura nas configurações de LTRS são recomendados para cargas iniciais:
| Sistema de SLT | Sistema de origem | Tipo de tabela | Tipo de leitura recomendado [carga inicial] |
|---|---|---|---|
| SLT 3.0 autônomo [DMIS 2018_1_752 SP 2] |
S/4 HANA 1909 | Transparente (pequena/média) Transparente (grande) Tabela de clusters |
1 cálculo de intervalo 1 cálculo de intervalo 4 filas de remetentes |
| SLT incorporado [S4CORE 104 HANA 1909] |
N/A | Transparente (pequena/média) Transparente (grande) Tabela de clusters |
1 cálculo de intervalo 1 cálculo de intervalo 4 filas de remetentes |
| SLT 2.0 autônomo [DMIS 2011_1_731 SP 17] |
ECC NW 7.02 | Transparente (pequena/média) Transparente (grande) Tabela de clusters |
Fila de 5 remetentes Fila de 5 remetentes Fila de 4 remetentes |
| SLT incorporado [DMIS 2011_1_700 SP 17] |
N/A | Transparente (pequena/média) Transparente (grande) Tabela de clusters |
Fila de 5 remetentes Fila de 5 remetentes Fila de 4 remetentes |
- Para a replicação, use "Sem intervalos" para melhorar a performance:
- Os intervalos só devem ser usados quando os backlogs são gerados em uma tabela de registro com alta latência.
- Usando um cálculo de intervalo: o tipo de leitura para carga inicial não é recomendado no caso de sistemas SLT 2.0 e não HANA.
- Usar um cálculo de intervalo: o tipo de leitura para o carregamento inicial pode resultar em registros duplicados no BigQuery.
- O desempenho é sempre melhor quando um sistema SLT independente é usado.
- Um sistema SLT independente é sempre recomendado se a utilização de recursos do sistema de origem já for alta.
Argumentos de ambiente de execução
snapshot.thread.count: transmite o número de linhas de execução para começar a realizar a carga de dadosSNAPSHOT/INITIALem paralelo. Por padrão, ele usa o número de vCPUs disponíveis no cluster do Dataproc em que o job de replicação é executado.Recomendado: defina esse parâmetro apenas nos casos em que você precisa de controle preciso sobre o número de linhas de execução paralelas (por exemplo, para diminuir o uso no cluster).
poll.file.count: transmite o número de arquivos a serem consultados do caminho do Cloud Storage fornecido no campo Caminho do GCS de replicação de dados na interface da Web. Por padrão, o valor é500por pesquisa. No entanto, com base na configuração do cluster, ele pode ser aumentado ou diminuído.Recomendado: defina esse parâmetro somente se você tiver requisitos rígidos para atraso de replicação. Valores mais baixos podem reduzir o atraso. Ele pode ser usado para melhorar a capacidade (se não responder, use valores maiores que o padrão).
bad.files.base.path: transmite o caminho de base do Cloud Storage em que todos os arquivos de dados com erros ou com falhas encontrados durante a replicação são copiados. Isso é útil quando há requisitos rígidos para a auditoria de dados e um local específico precisa ser usado para registrar transferências falhadas.Por padrão, todos os arquivos com falha são copiados do caminho do Cloud Storage fornecido no campo Data Replication Cloud Storage Path na interface da Web.
Padrão de caminho final de arquivos de dados com falha:
gs://BASE_FILE_PATH/MASS_TRANSFER_ID/SOURCE_TABLE_NAME/bad_files/REPLICATION_JOB_NAME/REPLICATION_JOB_ID/BAD_FILE_NAME
Exemplo:
gs://slt_to_cdf_bucket/001/MARA/bad_files/MaraRepl/05f97349-7398-11ec-9443-8 ac0640fc83c/20220205_1901205168830_DATA_INIT.xml
Os critérios para um arquivo inválido são um arquivo XML corrompido ou inválido, valores de PK ausentes ou um problema de incompatibilidade do tipo de dados do campo.
Detalhes do suporte
Produtos e versões do SAP compatíveis
- Versão SAP_BASIS 702, nível SP 0016 e mais recente.
- Versão SAP_ABA 702, nível SP 0016 e mais recente.
- Versão DMIS 2011_1_700, nível de SP 0017 e mais recente.
Versões de SLT compatíveis
As versões 2 e 3 do SLT são compatíveis.
Modelos de implantação SAP compatíveis
SLT como um sistema independente ou incorporado ao sistema de origem.
Notas do SAP que precisam ser implementadas antes de começar a usar o SLT
Se o pacote de suporte não incluir correções de classe /UI2/CL_JSON para PL
12 ou mais recente, implemente a última Nota da SAP para correções de classe /UI2/CL_JSON,
por exemplo, a Nota da SAP 2798102 para PL12.
Recomendado: implemente as notas do SAP recomendadas pelo relatório
CNV_NOTE_ANALYZER_SLT com base na condição do sistema central ou de origem. Para
mais informações, consulte a
Nota SAP 3016862
(é necessário fazer login no SAP).
Se o SAP já estiver configurado, nenhuma nota adicional precisa ser implementada. Para erros ou problemas específicos, consulte a nota central do SAP para sua versão do SLT.
Limites para o volume de dados ou a largura do registro
Não há limite definido para o volume de dados extraídos e a largura do registro.
Capacidade esperada do plug-in SAP SLT Replication
Para um ambiente configurado de acordo com as diretrizes em Otimizar o desempenho, o plug-in pode extrair cerca de 13 GB por hora para a carga inicial e 3 GB por hora para a replicação (CDC). O desempenho real pode variar de acordo com a carga do sistema do Cloud Data Fusion e do SAP ou tráfego de rede.
Suporte para extração de deltas SAP (dados alterados)
A extração delta da SAP é compatível.
Obrigatório: peering de locatário para instâncias do Cloud Data Fusion
O peering do locatário é necessário quando a instância do Cloud Data Fusion é criada com um endereço IP interno. Para mais informações sobre o peering de locatário, consulte Como criar uma instância particular.
Resolver problemas
O job de replicação continua sendo reiniciado
Se o job de replicação continuar reiniciando automaticamente, aumente a memória do cluster do job de replicação e execute-o novamente.
Duplicados no coletor do BigQuery
Se você definir o número de jobs paralelos nas configurações avançadas do plug-in de replicação do SAP SLT, quando as tabelas forem grandes, um erro vai ocorrer, causando a duplicação de colunas no coletor do BigQuery.
Para evitar o problema, remova os jobs paralelos ao carregar dados.
Cenários de erro
A tabela a seguir lista algumas mensagens de erro comuns (o texto entre aspas será substituído por valores reais no momento da execução):
| ID da mensagem | Mensagem | Ação recomendada |
|---|---|---|
CDF_SAP_SLT_01402 |
Service account type is not defined for
SERVICE_ACCT_NAME_FROM_UI. |
Verifique se o caminho do Cloud Storage fornecido está correto. |
CDF_SAP_SLT_01403 |
Service account key provided is not valid due to error:
ROOT_CAUSE. Please provide a valid service account key for
service account type : SERVICE_ACCT_NAME_FROM_UI. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
CDF_SAP_SLT_01404 |
Mass Transfer ID could not be found. Please ensure that it exists
in given GCS Bucket. |
Verifique se o ID de transferência em massa fornecido está no formato correto. |
CDF_SAP_SLT_01502 |
The specified data replication GCS path 'slt_to_cdf_bucket_1' or
Mass Transfer ID '05C' could not be found. Please ensure that it exists in
GCS. |
Verifique se o caminho do Cloud Storage fornecido está correto. |
CDF_SAP_SLT_01400 |
Metadata file not found. The META_INIT.json file is not present or
file is present with invalid format. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
CDF_SAP_SLT_03408 |
Failed to start the event reader. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
CDF_SAP_SLT_03409 |
Error while processing TABLE_NAME file for source table
gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/TABLE_NAME
/FILE_NAME. Root cause: ROOT_CAUSE. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
CDF_SAP_SLT_03410 |
Failed to replicate data for source table TABLE_NAME
from file: gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/
TABLE_NAME/FILE_NAME. Root cause:
ROOT_CAUSE. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
CDF_SAP_SLT_03411 |
Failed data replication for source table TABLE_NAME.
Root cause: ROOT_CAUSE. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
CDF_SAP_SLT_03412 |
Failed to create target table for source table
TABLE_NAME. Root cause: ROOT_CAUSE. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
Mapeamento de tipo de dados
A tabela a seguir mostra o mapeamento entre os tipos de dados usados nos aplicativos SAP e o Cloud Data Fusion.
| Tipo de dados do SAP | Tipo ABAP | Descrição (SAP) | Tipo de dados do Cloud Data Fusion |
|---|---|---|---|
| Numérico | |||
| INT1 | b | Inteiro de 1 byte | int |
| INT2 | s | Inteiro de 2 bytes | int |
| INT4 | i | Inteiro de 4 bytes | int |
| INT8 | 8 | Inteiro de 8 bytes | long |
| DEZ | p | Número no pacote no formato BCD (DEC) | decimal |
| DF16_DEC DF16_RAW |
a | Ponto flutuante decimal de 8 bytes IEEE 754r | decimal |
| DF34_DEC DF34_RAW |
e | Ponto flutuante decimal de 16 bytes IEEE 754r | decimal |
| FLTP | f | Número de ponto flutuante binário | double |
| Caractere | |||
| CHAR LCHR |
c | String de caracteres | string |
| SSTRING GEOM_EWKB |
string | String de caracteres | string |
| STRING GEOM_EWKB |
string | CLOB de string de caracteres | bytes |
| NUMC ACCP |
n | Texto numérico | string |
| Byte | |||
| RAW LRAW |
x | Dados binários | bytes |
| RAWSTRING | xstring | String de bytes BLOB | bytes |
| Data/hora | |||
| DATS | d | Data | date |
| Tims | t | Hora | time |
| TIMESTAMP | utcl | ( Utclong ) Carimbo de data/hora |
timestamp |
A seguir
- Saiba mais sobre o Cloud Data Fusion.
- Saiba mais sobre o SAP no Google Cloud.