In dieser Anleitung wird beschrieben, wie Sie Datenpipelines bereitstellen, konfigurieren und ausführen, die das SAP OData-Plug-in verwenden.
Sie können SAP als Quelle für die Batch-basierte Datenextraktion in Cloud Data Fusion mithilfe des Open Data Protocol (OData) verwenden. Mit dem SAP OData-Plug-in können Sie Datenübertragungen aus SAP OData Catalog Services ohne Programmieren konfigurieren und ausführen.
Weitere Informationen zu den unterstützten SAP OData Catalog Services und DataSources finden Sie in den Supportdetails. Weitere Informationen zu SAP aufGoogle Cloudfinden Sie unter Übersicht über SAP auf Google Cloud.
Lernziele
- SAP-ERP-System konfigurieren (DataSources in SAP aktivieren)
- Stellen Sie das Plug-in in Ihrer Cloud Data Fusion-Umgebung bereit.
- Laden Sie den SAP-Transport aus Cloud Data Fusion herunter und installieren Sie ihn in SAP.
- Verwenden Sie Cloud Data Fusion und SAP OData, um Datenpipelines für die Integration von SAP-Daten zu erstellen.
Hinweis
Für die Verwendung dieses Plug-ins benötigen Sie Domainkenntnisse in folgenden Bereichen:
- Pipelines in Cloud Data Fusion erstellen
- Zugriffsverwaltung mit IAM
- SAP Cloud- und lokale ERP-Systeme (Enterprise Resource Planning) konfigurieren
Nutzerrollen
Die Aufgaben auf dieser Seite werden von Personen mit den folgenden Rollen in Google Cloud oder in ihrem SAP-System ausgeführt:
| Nutzertyp | Beschreibung |
|---|---|
| Google Cloud-Administrator | Nutzer, denen diese Rolle zugewiesen wurde, sind Administratoren von Google Cloud-Konten. |
| Cloud Data Fusion-Nutzer | Nutzer, denen diese Rolle zugewiesen wurde, sind berechtigt, Datenpipelines zu entwerfen und auszuführen. Ihnen wird mindestens die Rolle „Data Fusion-Betrachter“ (
roles/datafusion.viewer) zugewiesen. Wenn Sie die rollenbasierte Zugriffssteuerung verwenden, benötigen Sie möglicherweise zusätzliche Rollen.
|
| SAP-Administrator | Nutzer, denen diese Rolle zugewiesen wurde, sind Administratoren des SAP-Systems. Sie haben Zugriff auf den Download von Software von der SAP-Dienstwebsite. Dies ist keine IAM-Rolle. |
| SAP-Nutzer | Nutzer, denen diese Rolle zugewiesen wurde, sind berechtigt, eine Verbindung zu einem SAP-System herzustellen. Dies ist keine IAM-Rolle. |
Voraussetzungen für die OData-Extraktion
Der OData Catalog Service muss im SAP-System aktiviert sein.
Daten müssen im OData-Dienst eingefügt werden.
Voraussetzungen für Ihr SAP-System
In SAP NetWeaver 7.02 bis SAP NetWeaver 7.31 werden die OData- und SAP-Gateway-Funktionen mit den folgenden SAP-Softwarekomponenten bereitgestellt:
IW_FNDGW_COREIW_BEP
In SAP NetWeaver-Release 7.40 und höher sind alle Funktionen in der Komponente
SAP_GWFNDverfügbar, die in SAP NetWeaver bereitgestellt werden muss.
Optional: SAP-Transportdateien installieren
Die SAP-Komponenten, die für das Load Balancing von Aufrufen an SAP erforderlich sind, werden als SAP-Transportdateien bereitgestellt, die als ZIP-Datei archiviert werden (eine Transportanfrage, die aus einer Cofile und einer Datendatei besteht). Mit diesem Schritt können Sie mehrere parallele Aufrufe an SAP basierend auf den verfügbaren Arbeitsprozessen in SAP einschränken.
Der Download der ZIP-Datei ist verfügbar, wenn Sie das Plug-in im Cloud Data Fusion Hub bereitstellen.
Wenn Sie die Transportdateien in SAP importieren, werden die folgenden SAP-OData-Projekte erstellt:
OData-Projekte
/GOOG/GET_STATISTIC/GOOG/TH_WPINFO
ICF-Dienstknoten:
GOOG
So installieren Sie den SAP-Transport:
Schritt 1: Transportanfragedateien hochladen
- Melden Sie sich im Betriebssystem der SAP-Instanz an.
- Verwenden Sie den SAP-Transaktionscode
AL11, um den Pfad für den OrdnerDIR_TRANSabzurufen. Normalerweise ist der Pfad/usr/sap/trans/. - Kopieren Sie die Cofiles in den Ordner
DIR_TRANS/cofiles. - Kopieren Sie die Datendateien in den Ordner
DIR_TRANS/data. - Legen Sie für die Daten- und Cofile die Nutzer- und Gruppenzuordnung auf
<sid>admundsapsysfest.
Schritt 2: Transportanfragedateien importieren
Der SAP-Administrator kann die Transportanfragedateien mit einer der folgenden Optionen importieren:
Option 1: Transportanfragedateien mit dem SAP-Transport-Management-System importieren
- Melden Sie sich im SAP-System als SAP-Administrator an.
- Geben Sie die Transaktions-STMS ein.
- Klicken Sie auf Übersicht > Importe.
- Doppelklicken Sie in der Spalte Warteschlange auf die aktuelle SID.
- Klicken Sie auf Extras > Sonstige Anfragen > Hinzufügen.
- Wählen Sie die Transportanfrage-ID aus und klicken Sie auf Weiter.
- Wählen Sie die Transportanfrage in der Importwarteschlange aus und klicken Sie dann auf Anfrage > Importieren.
- Geben Sie die Clientnummer ein.
Wählen Sie auf dem Tab Optionen die Optionen Originale überschreiben und Ungültige Komponentenversion ignorieren aus (falls verfügbar).
Optional: Wenn Sie einen Reimport des Transports zu einem späteren Zeitpunkt planen möchten, wählen Sie Transportanfragen in der Warteschlange für einen späteren Import belassen und Transportanfragen noch einmal importieren aus. Dies ist nützlich für SAP-Systemupgrades und Sicherungswiederherstellungen.
Klicken Sie auf Weiter.
Verwenden Sie zum Prüfen des Imports Transaktionen wie
SE80oderSU01.
Option 2: Transportanfragedateien auf Betriebssystemebene importieren
- Melden Sie sich im SAP-System als SAP-Systemadministrator an.
Fügen Sie dem Importpuffer die entsprechenden Anfragen hinzu, indem Sie den folgenden Befehl ausführen:
tp addtobuffer TRANSPORT_REQUEST_ID SIDBeispiel:
tp addtobuffer IB1K903958 DD1Importieren Sie die Transportanfragen mit dem folgenden Befehl:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238Ersetzen Sie
NNNdurch die Clientnummer. Beispiel:tp import IB1K903958 DD1 client=800 U1238Prüfen Sie mit den entsprechenden Transaktionen wie
SE80undSU01, ob das Funktionsmodul und die Autorisierungsrollen erfolgreich importiert wurden.
Liste der filterbaren Spalten für einen SAP-Katalogdienst abrufen
Für das Filtern von Bedingungen können nur einige DataSource-Spalten verwendet werden. Dies ist eine SAP-Einschränkung.
So rufen Sie eine Liste der filterbaren Spalten für einen SAP-Katalogdienst ab:
- Melden Sie sich im SAP-System an.
- Rufen Sie den t-Code
SEGWauf. Geben Sie den Namen des OData-Projekts ein. Dieser ist ein Teilstring des Dienstnamens. Beispiel:
- Dienstname:
MM_PUR_POITEMS_MONI_SRV - Projektname:
MM_PUR_POITEMS_MONI
- Dienstname:
Drücken Sie die Eingabetaste.
Rufen Sie die Entität auf, die Sie filtern möchten, und wählen Sie Properties (Properties) aus.
Sie können die Felder unter Properties als Filter verwenden. Unterstützte Vorgänge sind Gleich und Zwischen (Bereich).

Eine Liste der in der Ausdruckssprache unterstützten Operatoren finden Sie in der Open-Source-Dokumentation von OData: URI-Konventionen (OData Version 2.0).
Beispiel-URI mit Filtern:
/sap/opu/odata/sap/MM_PUR_POITEMS_MONI_SRV/C_PurchaseOrderItemMoni(P_DisplayCurrency='USD')/Results/?$filter=(PurchaseOrder eq '4500000000')
SAP-ERP-System konfigurieren
Das SAP OData-Plug-in verwendet einen OData-Dienst, der auf jedem SAP-Server aktiviert ist, von dem die Daten extrahiert werden. Dieser OData-Dienst kann ein von SAP bereitgestellter Standard oder ein benutzerdefinierter OData-Dienst sein, der in Ihrem SAP-System entwickelt wurde.
Schritt 1: SAP Gateway 2.0 installieren
Der SAP-Administrator (Basis) muss prüfen, ob die SAP Gateway 2.0-Komponenten je nach NetWeaver-Release im SAP-Quellsystem verfügbar sind. Weitere Informationen zur Installation von SAP Gateway 2.0 finden Sie im SAP ONE Support Launchpad im Hinweis 1569624 (Anmeldung erforderlich) .
Schritt 2: OData-Dienst aktivieren
Aktivieren Sie den erforderlichen OData-Dienst im Quellsystem. Weitere Informationen finden Sie unter Front-End-Server: OData-Dienste aktivieren.
Schritt 3: Autorisierungsrolle erstellen
Um eine Verbindung zur Datenquelle herzustellen, erstellen Sie in SAP eine Autorisierungsrolle mit den erforderlichen Autorisierungen und gewähren Sie sie dem SAP-Nutzer.
So erstellen Sie die Autorisierungsrolle in SAP:
- Geben Sie in der SAP-GUI den Transaktionscode PFCG ein, um das Fenster Rollenwartung zu öffnen.
Geben Sie im Feld Rolle einen Namen für die Rolle ein.
Beispiel:
ZODATA_AUTHKlicken Sie auf Einzelne Rolle.
Das Fenster Rollen erstellen wird geöffnet.
Geben Sie eine Beschreibung in das Feld Beschreibung ein und klicken Sie auf Speichern.
Beispiel:
Authorizations for SAP OData plugin.Klicken Sie auf den Tab Autorisierungen. Der Titel des Fensters ändert sich in Rollen ändern.
Klicken Sie unter Autorisierungsdaten bearbeiten und Profile generieren auf Autorisierungsdaten ändern.
Das Fenster Vorlage auswählen wird geöffnet.
Klicken Sie auf Vorlagen nicht auswählen.
Das Fenster Rolle ändern: Autorisierungen wird geöffnet.
Klicken Sie auf Manuell.
Geben Sie die Berechtigungen in der folgenden SAP-Autorisierungstabelle an.
Klicken Sie auf Speichern.
Klicken Sie auf das Symbol Generieren, um die Autorisierungsrolle zu aktivieren.
SAP-Autorisierungen
| Objektklasse | Text der Objektklasse | Autorisierungsobjekt | Text des Autorisierungsobjekts | Autorisierung | Text | Wert |
|---|---|---|---|---|---|---|
| AAAB | Anwendungsübergreifende Autorisierungsobjekte | S_SERVICE | Beim Start externer Dienste prüfen | SRV_NAME | Name des Programm-, Transaktions- oder Funktionsmoduls | * |
| AAAB | Anwendungsübergreifende Autorisierungsobjekte | S_SERVICE | Beim Start externer Dienste prüfen | SRV_TYPE | Standardwerte für den Typ des Prüf-Flags und der Autorisierung | HT |
| FI | Finanzbuchhaltung | F_UNI_HIER | Universal Hierarchy Access | ACTVT | Aktivität | 03 |
| FI | Finanzbuchhaltung | F_UNI_HIER | Universal Hierarchy Access | HRYTYPE | Hierarchietyp | * |
| FI | Finanzbuchhaltung | F_UNI_HIER | Universal Hierarchy Access | HRYID | Hierarchie-ID | * |
Wenn Sie als Cloud Data Fusion-Nutzer eine Datenpipeline in Cloud Data Fusion entwerfen und ausführen möchten, benötigen Sie SAP-Nutzeranmeldedaten (Nutzername und Passwort), um das Plug-in für die Verbindung zur Datenquelle zu konfigurieren.
Der SAP-Nutzer muss vom Typ Communications oder Dialog sein. Damit SAP-Dialogressourcen nicht verwendet werden, wird der Typ Communications empfohlen. Nutzer können mit dem SAP-Transaktionscode SU01 erstellt werden.
Optional: Schritt 4: Verbindung sichern
Sie können die Kommunikation über das Netzwerk zwischen Ihrer privaten Cloud Data Fusion-Instanz und SAP schützen.
So sichern Sie die Verbindung:
- Der SAP-Administrator muss ein X509-Zertifikat generieren. Informationen zum Generieren des Zertifikats finden Sie unter SSL-Server-PSE erstellen.
- Der Google Cloud Administrator muss die X509-Datei in einen lesbaren Cloud Storage-Bucket im selben Projekt wie die Cloud Data Fusion-Instanz kopieren und den Bucket-Pfad an den Cloud Data Fusion-Nutzer weitergeben, der ihn beim Konfigurieren des Plug-ins eingibt.
- Der Google Cloud -Administrator muss dem Cloud Data Fusion-Nutzer, der Pipelines entwirft und ausführt, Lesezugriff auf die X509-Datei gewähren.
Optional: Schritt 5: Benutzerdefinierte OData-Dienste erstellen
Sie können die Datenextraktion anpassen, indem Sie in SAP benutzerdefinierte OData-Dienste erstellen:
- Informationen zum Erstellen benutzerdefinierter OData-Dienste finden Sie unter OData-Dienste für Anfänger erstellen.
- Informationen zum Erstellen benutzerdefinierter OData-Dienste mit CDS-Ansichten (Core Data Services) finden Sie unter OData-Dienst erstellen und CDS-Ansichten als OData-Dienst freigeben.
- Jeder benutzerdefinierte OData-Dienst muss
$top-,$skip- und$count-Abfragen unterstützen. Mit diesen Abfragen kann das Plug-in die Daten für die sequenzielle und parallele Extraktion partitionieren. Wenn sie verwendet werden, müssen auch die Abfragen$filter,$expandoder$selectunterstützt werden.
Cloud Data Fusion einrichten
Achten Sie darauf, dass die Kommunikation zwischen der Cloud Data Fusion-Instanz und dem SAP-Server aktiviert ist. Richten Sie für private Instanzen Netzwerk-Peering ein. Nachdem das Netzwerk-Peering mit dem Projekt eingerichtet wurde, in dem die SAP-Systeme gehostet werden, ist keine weitere Konfiguration erforderlich, um eine Verbindung zu Ihrer Cloud Data Fusion-Instanz herzustellen. Sowohl das SAP-System als auch die Cloud Data Fusion-Instanz müssen sich im selben Projekt befinden.
Schritt 1: Cloud Data Fusion-Umgebung einrichten
So konfigurieren Sie Ihre Cloud Data Fusion-Umgebung für das Plug-in:
Rufen Sie die Instanzdetails auf:
Rufen Sie in der Google Cloud Console die Seite „Cloud Data Fusion“ auf.
Klicken Sie auf Instanzen und dann auf den Namen der Instanz, um die Seite Instanzdetails aufzurufen.
Prüfen Sie, ob die Instanz auf Version 6.4.0 oder höher aktualisiert wurde. Wenn die Instanz eine ältere Version hat, müssen Sie ein Upgrade ausführen.
Klicken Sie auf Instanz ansehen. Klicken Sie beim Öffnen der Cloud Data Fusion-UI auf Hub.
Wählen Sie den Tab SAP > SAP OData aus.
Wenn der SAP-Tab nicht sichtbar ist, finden Sie weitere Informationen unter Fehlerbehebung bei SAP-Integrationen.
Klicken Sie auf SAP OData-Plug-in bereitstellen.
Das Plug-in wird jetzt auf der Studio-Seite im Menü Quelle angezeigt.
Schritt 2: Plug-in konfigurieren
Das SAP OData-Plug-in liest den Inhalt einer SAP-Datenquelle.
Zum Filtern der Einträge können Sie die folgenden Attribute auf der Seite „SAP OData-Properties“ konfigurieren.
| Attributname | Beschreibung |
|---|---|
| Basic | |
| Referenzname | Name, der dazu dient, diese Quelle eindeutig für die Datenverlaufskontrolle oder das Annotieren von Metadaten zu identifizieren. |
| SAP OData-Basis-URL | OData-Basis-URL des SAP-Gateways (verwenden Sie den vollständigen URL-Pfad, ähnlich wie https://ADDRESS:PORT/sap/opu/odata/sap/).
|
| OData-Version | Unterstützte SAP OData-Version. |
| Dienstname | Name des SAP OData-Dienstes, aus dem Sie eine Entität extrahieren möchten. |
| Name der Entität | Name der zu extrahierenden Entität, z. B. Results. Sie können ein Präfix wie C_PurchaseOrderItemMoni/Results verwenden. Dieses Feld unterstützt Kategorie- und Entitätsparameter. Beispiele:
|
| Anmeldedaten* | |
| SAP-Typ | Einfach (über Nutzername und Passwort) |
| Nutzername für SAP-Anmeldung | SAP-Nutzername Empfohlen: Wenn sich der SAP-Anmeldename regelmäßig ändert, verwenden Sie ein Makro. |
| SAP-Anmeldepasswort | SAP-Nutzerpasswort Empfohlen: Verwenden Sie sichere Makros für sensible Werte wie Passwörter. |
| SAP X.509-Clientzertifikat (siehe X.509-Clientzertifikate auf dem SAP NetWeaver Application Server für ABAP verwenden) |
|
| GCP-Projekt-ID | Eine global eindeutige Kennung für Ihr Projekt. Dieses Feld ist obligatorisch, wenn das Feld X.509-Zertifikat – Cloud Storage-Pfad keinen Makrowert enthält. |
| GCS-Pfad | Der Cloud Storage-Bucket-Pfad, der das vom Nutzer hochgeladene X.509-Zertifikat enthält, das dem SAP-Anwendungsserver für sichere Aufrufe entspricht, die auf Ihren Anforderungen basieren (siehe Schritt Verbindung sichern). |
| Passphrase | Passphrase, die dem angegebenen X.509-Zertifikat entspricht. |
| Schaltfläche Schema abrufen | Generiert ein Schema anhand der Metadaten von SAP mit automatischer Zuordnung der SAP-Datentypen zu den entsprechenden Cloud Data Fusion-Datentypen (gleiche Funktionalität wie die Option Validieren). |
| Erweitert | |
| Filteroptionen | Gibt an, welchen Wert ein Feld haben muss, damit es gelesen werden kann. Mit dieser Filterbedingung können Sie das Ausgabedatenvolumen einschränken. Beispiel: Mit „Preis > 200“ werden die Einträge mit einem Feldwert „Preis“ größer als „200“ ausgewählt. Weitere Informationen finden Sie unter Liste der filterbaren Spalten für einen SAP-Katalogdienst abrufen. |
| Felder auswählen | Felder, die in den extrahierten Daten beibehalten werden sollen (z. B. Kategorie, Preis, Name, Lieferant/Adresse). |
| Felder maximieren | Liste der komplexen Felder, die in den extrahierten Ausgabedaten erweitert werden sollen (z. B. „Produkte“/„Lieferanten“). |
| Anzahl der zu überspringenden Zeilen | Gesamtzahl der zu überspringenden Zeilen (z. B. 10). |
| Anzahl der abzurufenden Zeilen | Gesamtzahl der zu extrahierenden Zeilen. |
| Anzahl der zu generierenden Splits | Die Anzahl der Aufteilungen, die zum Partitionieren der Eingabedaten verwendet werden. Mehr Partitionen erhöhen den Parallelisierungsgrad, erfordern aber mehr Ressourcen und Overhead. Wenn Sie dieses Feld leer lassen, wählt das Plug-in einen optimalen Wert aus (empfohlen). |
| Batch-Größe | Anzahl der Zeilen, die bei jedem Netzwerkaufruf an SAP abgerufen werden sollen. Eine kleine Größe führt dazu, dass häufige Netzwerkaufrufe wiederholt werden. Eine große Größe kann den Datenabruf verlangsamen und zu einer übermäßigen Ressourcennutzung in SAP führen.
Wenn der Wert auf 0 festgelegt ist, ist der Standardwert 2500 und die Anzahl der Zeilen, die in jedem Batch abgerufen werden, ist 5000. |
| Lesezeitüberschreitung | Die Zeit in Sekunden, die auf den SAP OData-Dienst gewartet werden soll. Der Standardwert ist 300. Wenn kein Zeitlimit festgelegt werden soll, geben Sie 0 ein. |
Unterstützte OData-Typen
Die folgende Tabelle zeigt die Zuordnung zwischen OData v2-Datentypen, die in SAP-Anwendungen verwendet werden, und Cloud Data Fusion-Datentypen.
| OData-Typ | Beschreibung (SAP) | Cloud Data Fusion-Datentyp |
|---|---|---|
| Numerisch | ||
| SByte | Vorzeichenbehafteter 8-Bit-Ganzzahlwert | int |
| Byte | Vorzeichenloser 8-Bit-Ganzzahlwert | int |
| Int16 | Vorzeichenbehafteter 16-Bit-Ganzzahlwert | int |
| Int32 | Vorzeichenbehafteter 32-Bit-Ganzzahlwert | int |
| INT64 | Vorzeichenbehafteter 64-Bit-Ganzzahlwert, an den das Zeichen „L“ angehängt ist Beispiele: 64L, -352L |
long |
| Einzelner | Gleitkommazahl mit 7-stelliger Genauigkeit, die Werte mit einem ungefähren Bereich von ± 1,18 E−38 bis ± 3,40 E+38 darstellen kann, mit dem Zeichen „f“ angehängt Beispiel: 2.0f |
float |
| Doppelt | Gleitkommazahl mit 15-stelliger Genauigkeit, die Werte mit ungefähren Bereichen von ± 2,23 e−308 bis ± 1,79 e+308 darstellen kann, gefolgt vom Zeichen „d“. Beispiele: 1E+10d, 2.029d, 2.0d |
double |
| Dezimalzahl | Numerische Werte mit fester Genauigkeit und Skalierung, die einen numerischen Wert im Bereich von negativen 10^255 + 1 bis positiven 10^255 − 1 beschreiben, mit dem Zeichen „M“ oder „m“ angehängt Beispiel: 2.345M |
decimal |
| Zeichen | ||
| GUID | Ein eindeutiger 16-Byte-Wert (128 Bit), der mit dem Zeichen „guid“ beginnt. Beispiel: guid'12345678-aaaa-bbbb-cccc-ddddeeeeffff' |
string |
| String | In UTF-8 codierte Zeichendaten mit fester oder variabler Länge | string |
| Byte | ||
| Binär | Binärdaten mit fester oder variabler Länge, die mit „X“ oder „binary“ beginnen (beides ist groß- und kleinschreibungsempfindlich) Beispiel: X'23AB', binary'23ABFF' |
bytes |
| Logisch | ||
| Boolesch | Mathematisches Konzept der binären Logik | boolean |
| Datum/Uhrzeit | ||
| Datum/Uhrzeit | Datum und Uhrzeit mit Werten von 00:00:00 Uhr am 1. Januar 1753 bis 23:59:59 Uhr am 31. Dezember 9999 | timestamp |
| Zeit | Die Uhrzeit mit Werten von 0:00:00.x bis 23:59:59.y, wobei „x“ und „y“ von der Genauigkeit abhängen | time |
| DateTimeOffset | Datum und Uhrzeit als Zeitoffset in Minuten von GMT, mit Werten von 00:00:00 Uhr am 1. Januar 1753 bis 23:59:59 Uhr am 31. Dezember 9999 | timestamp |
| Komplex | ||
| Navigations- und Nichtnavigationseigenschaften (Multiplicity = *) | Sammlungen eines Typs mit einer Vielzahl von 1:n-Beziehungen. | array,string,int. |
| Unterkünfte (Multiplizität = 0,1) | Verweise auf andere komplexe Typen mit einer Vielzahl von Eins-zu-Eins-Beziehungen | record |
Validierung
Klicken Sie oben rechts auf Validieren oder Schema abrufen.
Das Plug-in validiert die Attribute und generiert ein Schema anhand der Metadaten von SAP. SAP-Datentypen werden den entsprechenden Cloud Data Fusion-Datentypen automatisch zugeordnet.
Datenpipeline ausführen
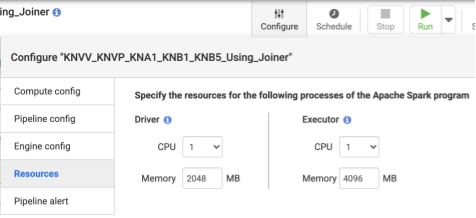
- Nachdem Sie die Pipeline bereitgestellt haben, klicken Sie im oberen Bereich der Seitenleiste auf Konfigurieren.
- Wählen Sie Ressourcen aus.
- Ändern Sie bei Bedarf die Executor-CPU und den Arbeitsspeicher entsprechend der Gesamtdatengröße und der Anzahl der in der Pipeline verwendeten Transformationen.
- Klicken Sie auf Speichern.
- Klicken Sie zum Starten der Datenpipeline auf Ausführen.
Leistung
Das Plug-in verwendet die Parallelisierungsfunktionen von Cloud Data Fusion. Die folgenden Richtlinien können dabei helfen, die Laufzeitumgebung zu konfigurieren, damit die Laufzeit-Engine genügend Ressourcen bereitstellt, um den gewünschten Grad an Parallelität und Leistung zu erreichen.
Plug-in-Konfiguration optimieren
Empfohlen:Lassen Sie die Felder Anzahl der zu generierenden Splits und Batch-Größe leer, sofern Sie nicht mit den Speichereinstellungen Ihres SAP-Systems vertraut sind.
Verwenden Sie die folgenden Konfigurationen, um die Leistung beim Ausführen der Pipeline zu verbessern:
Anzahl der zu generierenden Aufteilungen: Wir empfehlen Werte zwischen
8und16. Sie können jedoch mit der entsprechenden Konfiguration auf SAP-Seite auf32oder sogar64erhöht werden, wobei geeignete Speicherressourcen für die Arbeitsprozesse in SAP zugewiesen werden. Diese Konfiguration verbessert den Parallelismus auf der Cloud Data Fusion-Seite. Die Laufzeit-Engine erstellt die angegebene Anzahl von Partitionen (und SAP-Verbindungen) beim Extrahieren der Einträge.Wenn der Konfigurationsservice verfügbar ist (im Plug-in enthalten, wenn Sie die SAP-Transportdatei importieren): Das Plug-in verwendet standardmäßig die Konfiguration des SAP-Systems. Die Aufteilungen entsprechen 50% der verfügbaren Dialogarbeitsprozesse in SAP. Hinweis: Der Konfigurationsservice kann nur aus S4HANA-Systemen importiert werden.
Wenn der Konfigurationsservice nicht verfügbar ist, ist standardmäßig
7Splits festgelegt.In beiden Fällen gilt: Wenn Sie einen anderen Wert angeben, hat dieser Vorrang vor dem Standardwert für die Aufteilung. Er wird jedoch auf die Anzahl der verfügbaren Dialogprozesse in SAP minus zwei Splits begrenzt.
Wenn die Anzahl der zu extrahierenden Einträge kleiner als
2500ist, ist die Anzahl der Teilungen1.
Batchgröße: Die Anzahl der Datensätze, die bei jedem Netzwerkaufruf an SAP abgerufen werden. Eine kleinere Batchgröße führt zu häufigen Netzwerkaufrufen, wodurch der entsprechende Overhead wiederholt wird. Standardmäßig ist die Mindestanzahl
1000und die maximale Anzahl50000.
Weitere Informationen finden Sie unter OData-Entitätslimits.
Cloud Data Fusion-Ressourceneinstellungen
Empfohlen:Verwenden Sie 1 CPU und 4 GB Arbeitsspeicher pro Executor. Dieser Wert gilt für jeden Executor-Prozess. Legen Sie diese im Dialogfeld > Ressourcen konfigurieren fest.
Dataproc-Clustereinstellungen
Empfohlen:Weisen Sie mindestens eine Gesamtzahl von CPUs (über Worker) zu, die größer als die vorgesehene Anzahl von Splits ist (siehe Plug-in-Konfiguration).
Jedem Worker muss in den Dataproc-Einstellungen mindestens 6,5 GB Arbeitsspeicher pro CPU zugewiesen sein.Das entspricht mindestens 4 GB pro Cloud Data Fusion-Executor. Die anderen Einstellungen können bei den Standardwerten belassen werden.
Empfohlen:Verwenden Sie einen nichtflüchtigen Dataproc-Cluster, um die Datenpipeline-Laufzeit zu reduzieren. Dadurch wird der Bereitstellungsschritt entfernt, der einige Minuten oder länger dauern kann. Legen Sie dies im Abschnitt zur Compute Engine-Konfiguration fest.
Beispielkonfigurationen und Durchsatz
In den folgenden Abschnitten werden Beispielkonfigurationen für die Entwicklung und Produktion sowie der Durchsatz beschrieben.
Beispielkonfigurationen für Entwicklung und Tests
- Dataproc-Cluster mit 8 Workern, jeweils mit 4 CPUs und 26 GB Arbeitsspeicher Sie können bis zu 28 Splits generieren.
- Dataproc-Cluster mit 2 Workern, jeweils mit 8 CPUs und 52 GB Arbeitsspeicher Sie können bis zu 12 Splits generieren.
Beispielkonfigurationen und -durchsatz für die Produktion
- Dataproc-Cluster mit 8 Workern, jeweils mit 8 CPUs und 32 GB Arbeitsspeicher Bis zu 32 Splits generieren (die Hälfte der verfügbaren CPUs).
- Dataproc-Cluster mit 16 Workern, jeweils mit 8 CPUs und 32 GB Arbeitsspeicher Bis zu 64 Splits generieren (die Hälfte der verfügbaren CPUs).
Beispiel für den Durchsatz eines SAP S/4HANA 1909-Produktions-Quellsystems
Die folgende Tabelle enthält Beispieldurchsätze. Der angezeigte Durchsatz bezieht sich, sofern nicht anders angegeben, auf die Daten ohne Filteroptionen. Wenn Sie Filteroptionen verwenden, wird der Durchsatz reduziert.
| Batchgröße | Splits | OData-Dienst | Zeilen insgesamt | Extrahierte Zeilen | Durchsatz (Zeilen pro Sekunde) |
|---|---|---|---|---|---|
| 1000 | 4 | ZACDOCA_CDS | 5,37 Mio. | 5,37 Mio. | 1069 |
| 2.500 | 10 | ZACDOCA_CDS | 5,37 Mio. | 5,37 Mio. | 3384 |
| 5.000 | 8 | ZACDOCA_CDS | 5,37 Mio. | 5,37 Mio. | 4.630 |
| 5.000 | 9 | ZACDOCA_CDS | 5,37 Mio. | 5,37 Mio. | 4817 |
Beispiel für den Durchsatz eines SAP S/4HANA-Produktions-Quellsystems in der Cloud
| Batchgröße | Splits | OData-Dienst | Zeilen insgesamt | Extrahierte Zeilen | Durchsatz (GB/Stunde) |
|---|---|---|---|---|---|
| 2.500 | 40 | TEST_04_UOM_ODATA_CDS/ | 201 Mio. | 10 Mio. | 25,48 |
| 5.000 | 50 | TEST_04_UOM_ODATA_CDS/ | 201 Mio. | 10 Mio. | 26.78 |
Supportdetails
Das Plug-in unterstützt die folgenden Anwendungsfälle.
Unterstützte SAP-Produkte und ‑Versionen
Zu den unterstützten Quellen gehören SAP S4/HANA 1909 und höher, S4/HANA in der SAP-Cloud und jede SAP-Anwendung, die OData-Dienste bereitstellen kann.
Die Transportdatei mit dem benutzerdefinierten OData-Dienst für das Load Balancing der Aufrufe an SAP muss in S4/HANA 1909 oder höher importiert werden. Der Dienst hilft dabei, die Anzahl der Splits (Datenpartitionen) zu berechnen, die das Plug-in parallel lesen kann (siehe Anzahl der Splits).
OData-Version 2 wird unterstützt.
Das Plug-in wurde mit SAP S/4HANA-Servern getestet, die auf Google Cloudbereitgestellt werden.
SAP OData Catalog Services werden für die Extraktion unterstützt
Das Plug-in unterstützt die folgenden DataSource-Typen:
- Transaktionsdaten
- Über OData bereitgestellte CDS-Ansichten
Masterdaten
- Attribute
- Texte
- Hierarchien
SAP-Hinweise
Vor der Extraktion sind keine SAP-Hinweise erforderlich. Das SAP-System muss jedoch SAP Gateway verfügbar haben. Weitere Informationen finden Sie im Hinweis 1560585 (für diese externe Website ist eine SAP-Anmeldung erforderlich).
Beschränkungen für das Datenvolumen oder die Datensatzbreite
Es gibt kein definiertes Limit für die Menge der extrahierten Daten. Wir haben mit bis zu 6 Millionen Zeilen getestet, die in einem Aufruf mit einer Datensatzbreite von 1 KB extrahiert wurden. Bei SAP S4/HANA in der Cloud haben wir mit bis zu 10 Millionen Zeilen getestet, die in einem Aufruf mit einer Datensatzbreite von 1 KB extrahiert wurden.
Erwarteter Plug-in-Durchsatz
Für eine Umgebung, die gemäß den Richtlinien im Abschnitt Leistung konfiguriert ist, kann das Plug-in ca. 38 GB/Stunde extrahieren. Die tatsächliche Leistung kann je nach Cloud Data Fusion- und SAP-Systemlast oder Netzwerkverkehr variieren.
Delta-Extraktion (geänderte Daten)
Die Deltaextraktion wird nicht unterstützt.
Fehlerszenarien
Zur Laufzeit schreibt das Plug-in Logeinträge in das Log der Cloud Data Fusion-Datenpipeline. Diese Einträge haben das Präfix CDF_SAP, um sie leicht zu identifizieren.
Wenn Sie während der Entwicklung die Plug-in-Einstellungen validieren, werden die Nachrichten auf dem Tab Eigenschaften angezeigt und rot hervorgehoben.
In der folgenden Liste werden einige der Fehler beschrieben:
| Nachrichten-ID | Nachricht | Empfohlene Maßnahmen |
|---|---|---|
| Keine | Required property 'CONNECTION_PROPERTY' for connection
type 'CONNECTION_PROPERTY_SETTING'. |
Geben Sie einen tatsächlichen Wert oder eine Makrovariable ein. |
| Keine | Invalid value for property 'PROPERTY_NAME'. |
Geben Sie eine nicht negative ganze Zahl (0 oder höher ohne Dezimalzahl) oder eine Makrovariable ein. |
| CDF_SAP_ODATA_01505 | Failed to prepare the Cloud Data Fusion output schema. Please
check the provided runtime macros value. |
Prüfen Sie, ob die angegebenen Makrowerte korrekt sind. |
| – | SAP X509 certificated 'STORAGE_PATH' is missing. Please
make sure the required X509 certificate is uploaded to your specified
Cloud Storage bucket 'BUCKET_NAME'. |
Prüfen Sie, ob der angegebene Cloud Storage-Pfad korrekt ist. |
| CDF_SAP_ODATA_01532 | Generischer Fehlercode, der sich auf Probleme mit der SAP-OData-Verbindung beziehtFailed to call given SAP OData service. Root Cause:
MESSAGE. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
| CDF_SAP_ODATA_01534 | Allgemeiner Fehlercode, der sich auf einen SAP OData-Dienstfehler bezieht.Service validation failed. Root Cause: MESSAGE. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
| CDF_SAP_ODATA_01503 | Failed to fetch total available record count from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause: MESSAGE.
|
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
| CDF_SAP_ODATA_01506 | No records found to extract in
SAP_ODATA_SERVICE_ENTITY_NAME.
Please ensure that the provided entity contains records. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
| CDF_SAP_ODATA_01537 | Failed to process records for
SAP_ODATA_SERVICE_ENTITY_NAME.
Root Cause: MESSAGE. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
| CDF_SAP_ODATA_01536 | Failed to pull records from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause:
MESSAGE. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
| CDF_SAP_ODATA_01504 | Failed to generate the encoded metadata string for the given OData
service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
| CDF_SAP_ODATA_01533 | Failed to decode the metadata from the given encoded metadata
string for service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
Nächste Schritte
- Weitere Informationen zu Cloud Data Fusion
- Weitere Informationen zu SAP auf Google Cloud