En esta guía, se describe cómo implementar, configurar y ejecutar canalizaciones de datos que usan el complemento de SAP OData.
Puedes usar SAP como fuente para la extracción de datos por lotes en Cloud Data Fusion mediante el protocolo de datos abiertos (OData). El complemento SAP OData te ayuda a configurar y ejecutar transferencias de datos desde SAP OData Catalog Services sin ninguna codificación.
Para obtener más información sobre los servicios y las fuentes de datos del catálogo de SAP OData compatibles, consulta los detalles de asistencia. Para obtener más información sobre SAP enGoogle Cloud, consulta la descripción general de SAP en Google Cloud.
Objetivos
- Configura el sistema SAP ERP (activa DataSources en SAP).
- Implementa el complemento en tu entorno de Cloud Data Fusion.
- Descarga el transporte de SAP desde Cloud Data Fusion y, luego, instálalo en SAP.
- Usa Cloud Data Fusion y SAP OData para crear canalizaciones de datos que te permitan integrar datos de SAP.
Antes de comenzar
Para usar este complemento, necesitarás conocimientos de dominio en las siguientes áreas:
- Compila canalizaciones en Cloud Data Fusion
- Administración de acceso con IAM
- Configuración de sistemas de planificación de recursos empresariales (ERP) locales y en la nube de SAP
Funciones de usuario
Las tareas de esta página las realizan personas con los siguientes roles en Google Cloud o en su sistema SAP:
| Tipo de usuario | Descripción |
|---|---|
| Administrador de Google Cloud | Los usuarios con este rol son administradores de cuentas de Google Cloud. |
| Usuario de Cloud Data Fusion | Los usuarios a los que se les asignó este rol están autorizados para diseñar y ejecutar canalizaciones de datos. Se les otorga, como mínimo, el rol de Visualizador de Data Fusion (
roles/datafusion.viewer). Si usas el control de acceso basado en roles, es posible que necesites roles adicionales.
|
| Administrador de SAP | Los usuarios con este rol son administradores del sistema SAP. Tiene acceso para descargar software desde el sitio del servicio de SAP. No es un rol de IAM. |
| Usuario de SAP | Los usuarios con este rol están autorizados a conectarse a un sistema SAP. No es un rol de IAM. |
Requisitos previos para la extracción de OData
El servicio de catálogo de OData debe estar activado en el sistema SAP.
Los datos se deben propagar en el servicio de OData.
Requisitos previos para tu sistema SAP
En SAP NetWeaver 7.02 a la versión 7.31 de SAP NetWeaver, las funciones de OData y SAP Gateway se entregan con los siguientes componentes de software de SAP:
IW_FNDGW_COREIW_BEP
En la versión 7.40 de SAP NetWeaver y versiones posteriores, todas las funciones están disponibles en el componente
SAP_GWFND, que debe estar disponible en SAP NetWeaver.
Opcional: Instala archivos de transporte de SAP
Los componentes de SAP que se necesitan para las llamadas de balanceo de cargas a SAP se entregan como archivos de transporte de SAP que se archivan como un archivo ZIP (una solicitud de transporte, que consta de un archivo cofile y un archivo de datos). Puedes usar este paso para limitar varias llamadas simultáneas a SAP, según los procesos de trabajo disponibles en SAP.
La descarga del archivo ZIP está disponible cuando despliegas el complemento en el Centro de noticias de Cloud Data Fusion.
Cuando importas los archivos de transporte a SAP, se crean los siguientes proyectos de SAP OData:
Proyectos de OData
/GOOG/GET_STATISTIC/GOOG/TH_WPINFO
Nodo de servicio de ICF:
GOOG
Para instalar el transporte de SAP, sigue estos pasos:
Paso 1: Sube los archivos de solicitud de transporte
- Accede al sistema operativo de la instancia de SAP.
- Usa el código de transacción
AL11de SAP para obtener la ruta de acceso de la carpetaDIR_TRANS. Por lo general, la ruta es/usr/sap/trans/. - Copia los coarchivos a la carpeta
DIR_TRANS/cofiles. - Copia los archivos de datos a la carpeta
DIR_TRANS/data. - Establece el usuario y el grupo de datos y el archivo compartido en
<sid>admysapsys.
Paso 2: Importa los archivos de solicitud de transporte
El administrador de SAP puede importar los archivos de solicitud de transporte con una de las siguientes opciones:
Opción 1: Importar los archivos de solicitud de transporte con el sistema de administración de transporte de SAP
- Accede al sistema SAP como administrador de SAP.
- Ingresa el STMS de la transacción.
- Haz clic en Resumen > Importaciones.
- En la columna Queue, haz doble clic en el SID actual.
- Haz clic en Adicionales > Otras solicitudes > Agregar.
- Selecciona el ID de la solicitud de transporte y haz clic en Continuar.
- Selecciona la solicitud de transporte en la cola de importación y, luego, haz clic en Solicitud > Importar.
- Ingresa el número de cliente.
En la pestaña Opciones, selecciona Reemplazar originales y Ignorar versión de componente no válida (si está disponible).
(Opcional) Para programar una nueva importación de los transportes más adelante, selecciona Dejar las solicitudes de transporte en la cola para una importación posterior y Volver a importar solicitudes de transporte. Esto es útil para las actualizaciones del sistema SAP y los restablecimientos de copias de seguridad.
Haga clic en Continuar.
Para verificar la importación, usa cualquier transacción, como
SE80ySU01.
Opción 2: Importa los archivos de solicitud de transporte a nivel del sistema operativo
- Accede al sistema SAP como administrador del sistema SAP.
Ejecuta el siguiente comando para agregar las solicitudes adecuadas al búfer de importación:
tp addtobuffer TRANSPORT_REQUEST_ID SIDPor ejemplo:
tp addtobuffer IB1K903958 DD1.Ejecuta el siguiente comando para importar las solicitudes de transporte:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238Reemplaza
NNNpor el número de cliente. Por ejemplo:tp import IB1K903958 DD1 client=800 U1238Verifica que el módulo de función y los roles de autorización se hayan importado de forma correcta mediante las transacciones adecuadas, como
SE80ySU01.
Obtén una lista de columnas filtrables para un servicio de catálogo de SAP
Solo se pueden usar algunas columnas de DataSource para las condiciones del filtro (esta es una limitación de SAP por diseño).
Para obtener una lista de columnas filtrables para un servicio de catálogo de SAP, sigue estos pasos:
- Accede al sistema SAP.
- Ve al código T
SEGW. Ingresa el nombre del proyecto de OData, que es una subcadena del nombre del servicio. Por ejemplo:
- Nombre del servicio:
MM_PUR_POITEMS_MONI_SRV - Nombre del proyecto:
MM_PUR_POITEMS_MONI
- Nombre del servicio:
Haz clic en Ingresar.
Ve a la entidad que deseas filtrar y selecciona Propiedades.
Puedes usar los campos que se muestran en Propiedades como filtros. Las operaciones compatibles son Igual y Entre (rango).

Para obtener una lista de los operadores compatibles con el lenguaje de expresiones, consulta la documentación de código abierto de OData: Convención de URI (OData versión 2.0).
Ejemplo de URI con filtros:
/sap/opu/odata/sap/MM_PUR_POITEMS_MONI_SRV/C_PurchaseOrderItemMoni(P_DisplayCurrency='USD')/Results/?$filter=(PurchaseOrder eq '4500000000')
Configura el sistema SAP ERP
El complemento SAP OData usa un servicio de OData que se activa en cada servidor SAP desde el que se extraen los datos. Este servicio de OData puede ser un servicio estándar que proporciona SAP o un servicio de OData personalizado desarrollado en tu sistema SAP.
Paso 1: Instala SAP Gateway 2.0
El administrador de SAP (Basis) debe verificar que los componentes de SAP Gateway 2.0 estén disponibles en el sistema de origen de SAP, según la versión de NetWeaver. Para obtener más información sobre la instalación de SAP Gateway 2.0, accede a SAP ONE Support Launchpad y consulta la Nota 1569624 (se requiere acceso) .
Paso 2: Activa el servicio de OData
Activa el servicio de OData requerido en el sistema de origen. Para obtener más información, consulta Servidor de frontend: Activa los servicios de OData.
Paso 3: Crea un rol de autorización
Para conectarte a la fuente de datos, crea un rol de autorización con las autorizaciones requeridas en SAP y, luego, ótórgalo al usuario de SAP.
Para crear el rol de autorización en SAP, sigue estos pasos:
- En la GUI de SAP, ingresa el código de transacción PFCG para abrir la ventana Mantenimiento de roles.
En el campo Rol, ingresa un nombre para el rol.
Por ejemplo:
ZODATA_AUTH.Haz clic en Rol único.
Se abre la ventana Crear roles.
En el campo Descripción, ingresa una descripción y haz clic en Guardar.
Por ejemplo:
Authorizations for SAP OData plugin.Haz clic en la pestaña Autorizaciones. El título de la ventana cambiará a Cambiar roles.
En Editar datos de autorización y generar perfiles, haz clic en Cambiar datos de autorización.
Se abrirá la ventana Choose Template.
Haz clic en No seleccionar plantillas.
Se abrirá la ventana Cambiar rol: autorizaciones.
Haz clic en Manualmente.
Proporciona las autorizaciones que se muestran en la siguiente tabla de autorizaciones de SAP.
Haz clic en Guardar.
Para activar el rol de autorización, haz clic en el ícono Generar.
Autorizaciones de SAP
| Clase de objeto | Texto de la clase de objeto | Objeto de autorización | Texto del objeto de autorización | Autorización | Texto | Valor |
|---|---|---|---|---|---|---|
| AAAB | Objetos de autorización entre aplicaciones | S_SERVICE | Verificación al inicio de los servicios externos | SRV_NAME | Nombre del módulo de programa, transacción o función | * |
| AAAB | Objetos de autorización entre aplicaciones | S_SERVICE | Verificación al inicio de los servicios externos | SRV_TYPE | Tipo de marca de verificación y valores predeterminados de autorización | HT |
| FI | Contabilidad financiera | F_UNI_HIER | Acceso a la jerarquía universal | ACTVT | Actividad | 03 |
| FI | Contabilidad financiera | F_UNI_HIER | Acceso a la jerarquía universal | HRYTYPE | Tipo de jerarquía | * |
| FI | Contabilidad financiera | F_UNI_HIER | Acceso a la jerarquía universal | HRYID | ID de jerarquía | * |
Para diseñar y ejecutar una canalización de datos en Cloud Data Fusion (como usuario de Cloud Data Fusion), necesitas credenciales de usuario de SAP (nombre de usuario y contraseña) para configurar el complemento y que se conecte a la fuente de datos.
El usuario de SAP debe ser de los tipos Communications o Dialog. Para evitar usar recursos de diálogo de SAP, se recomienda el tipo Communications. Los usuarios se pueden crear con el código de transacción SU01 de SAP.
Opcional: Paso 4: Protege la conexión
Puedes proteger la comunicación a través de la red entre tu instancia privada de Cloud Data Fusion y SAP.
Para proteger la conexión, sigue estos pasos:
- El administrador de SAP debe generar un certificado X509. Para generar el certificado, consulta Cómo crear un PSE de servidor SSL.
- El Google Cloud administrador debe copiar el archivo X509 en un bucket de Cloud Storage legible en el mismo proyecto que la instancia de Cloud Data Fusion y proporcionar la ruta de acceso del bucket al usuario de Cloud Data Fusion, que la ingresa cuando configura el complemento.
- El administrador de Google Cloud debe otorgar acceso de lectura al archivo X509 al usuario de Cloud Data Fusion que diseña y ejecuta canalizaciones.
Opcional: Paso 5: Crea servicios de OData personalizados
Puedes personalizar la forma en que se extraen los datos creando servicios de OData personalizados en SAP:
- Para crear servicios de OData personalizados, consulta Creación de servicios de OData para principiantes.
- Para crear servicios de OData personalizados con vistas de servicios de datos principales (CDS), consulta Cómo crear un servicio de OData y exponer vistas de CDS como un servicio de OData.
- Cualquier servicio de OData personalizado debe admitir consultas
$top,$skipy$count. Estas consultas permiten que el complemento particione los datos para la extracción secuencial y en paralelo. Si se usan, las consultas$filter,$expando$selecttambién deben ser compatibles.
Configura Cloud Data Fusion
Asegúrate de que la comunicación esté habilitada entre la instancia de Cloud Data Fusion y el servidor de SAP. Para las instancias privadas, configura el intercambio de tráfico de red. Después de establecer el intercambio de tráfico de red con el proyecto en el que se alojan los sistemas SAP, no se requiere ninguna configuración adicional para conectarse a tu instancia de Cloud Data Fusion. Tanto el sistema SAP como la instancia de Cloud Data Fusion deben estar dentro del mismo proyecto.
Paso 1: Configura tu entorno de Cloud Data Fusion
Para configurar tu entorno de Cloud Data Fusion para el complemento, haz lo siguiente:
Ve a los detalles de la instancia:
En la Google Cloud consola, ve a la página de Cloud Data Fusion.
Haz clic en Instancias y, luego, en el nombre de la instancia para ir a la página Detalles de la instancia.
Verifica que la instancia se haya actualizado a la versión 6.4.0 o una posterior. Si la instancia está en una versión anterior, debes actualizarla.
Haz clic en Ver instancia. Cuando se abra la IU de Cloud Data Fusion, haz clic en Centro de noticias.
Selecciona la pestaña SAP > SAP OData.
Si no ves la pestaña SAP, consulta Cómo solucionar problemas de las integraciones de SAP.
Haz clic en Implementar complemento SAP OData.
El complemento ahora aparece en el menú Source de la página de Studio.
Paso 2: Configura el complemento
El complemento de SAP OData lee el contenido de una DataSource de SAP.
Para filtrar los registros, puedes configurar las siguientes propiedades en la página Propiedades de OData de SAP.
| Nombre de la propiedad | Descripción |
|---|---|
| Básica | |
| Nombre de referencia | Es el nombre que se usa para identificar de forma única esta fuente para el linaje o para anotar los metadatos. |
| URL base de SAP OData | URL base de OData de SAP Gateway (usa la ruta de URL completa, similar a https://ADDRESS:PORT/sap/opu/odata/sap/).
|
| Versión de OData | Versión compatible de SAP OData. |
| Nombre del servicio | Es el nombre del servicio de OData de SAP del que deseas extraer una entidad. |
| Nombre de la entidad | Es el nombre de la entidad que se extrae, como Results. Puedes usar un prefijo, como C_PurchaseOrderItemMoni/Results. Este campo admite los parámetros de categoría y entidad. Ejemplos:
|
| Credenciales* | |
| Tipo de SAP | Básico (a través de nombre de usuario y contraseña) |
| Nombre de usuario de inicio de sesión de SAP | Nombre de usuario de SAP Recomendado: Si el nombre de usuario de inicio de sesión de SAP cambia de forma periódica, usa una macro. |
| Contraseña de inicio de sesión de SAP | Contraseña de usuario de SAP Recomendación: Usa macros seguras para valores sensibles, como contraseñas. |
| Certificado de cliente X.509 de SAP (consulta Cómo usar certificados de cliente X.509 en el servidor de aplicaciones SAP NetWeaver para ABAP). |
|
| ID del proyecto de GCP | Un identificador único global para tu proyecto. Este campo es obligatorio si el campo X.509 Certificate Cloud Storage Path no contiene un valor de macro. |
| Ruta de acceso de GCS | La ruta de acceso del bucket de Cloud Storage que contiene el certificado X.509 que subió el usuario, que corresponde al servidor de aplicaciones de SAP para llamadas seguras según tus requisitos (consulta el paso Cómo proteger la conexión). |
| Frase de contraseña | La frase de contraseña correspondiente al certificado X.509 proporcionado |
| Botón Get Schema | Genera un esquema basado en los metadatos de SAP, con asignación automática de tipos de datos de SAP a tipos de datos de Cloud Data Fusion correspondientes (la misma funcionalidad que el botón Validar). |
| Aspectos avanzados | |
| Opciones de filtro | Indica el valor que debe tener un campo para que se lea. Usa esta condición de filtro para restringir el volumen de datos de salida. Por ejemplo, "Price Gt 200" selecciona los registros con un valor de campo "Price" superior a "200". (Consulta Obtén una lista de columnas filtrables para un servicio de catálogo de SAP). |
| Selecciona campos | Son los campos que se conservarán en los datos extraídos (por ejemplo, Categoría, Precio, Nombre, Proveedor/Dirección). |
| Expandir campos | Es la lista de campos complejos que se expandirán en los datos de salida extraídos (por ejemplo, Productos/Proveedores). |
| Cantidad de filas que se omitirán | Es la cantidad total de filas que se deben omitir (por ejemplo, 10). |
| Cantidad de filas que se recuperarán | Es la cantidad total de filas que se extraerán. |
| Cantidad de divisiones que se generarán | Es la cantidad de divisiones que se usan para particionar los datos de entrada. Más particiones aumentan el nivel de paralelismo, pero requieren más recursos y sobrecarga. Si se deja en blanco, el complemento elige un valor óptimo (recomendado). |
| Tamaño del lote | Es la cantidad de filas que se recuperarán en cada llamada de red a SAP. Un tamaño pequeño provoca llamadas frecuentes de red que repiten la sobrecarga asociada. Un tamaño grande podría ralentizar la recuperación de datos y provocar un uso excesivo de recursos en SAP.
Si el valor se establece en 0, el valor predeterminado es 2500 y el límite de filas que se recuperan en cada lote es 5000. |
| Tiempo de espera de lectura | Es el tiempo, en segundos, que se debe esperar para el servicio de OData de SAP. El valor predeterminado es 300. Si no hay límite de tiempo, configúralo en 0. |
Tipos de OData admitidos
En la siguiente tabla, se muestra la asignación entre los tipos de datos de OData v2 que se usan en las aplicaciones de SAP y los tipos de datos de Cloud Data Fusion.
| Tipo de OData | Descripción (SAP) | Tipo de datos de Cloud Data Fusion |
|---|---|---|
| Numérico | ||
| SByte | Valor de número entero de 8 bits con firma | int |
| Byte | Valor de número entero de 8 bits sin signo | int |
| Int16 | Valor de número entero de 16 bits con firma | int |
| Int32 | Valor de número entero de 32 bits con firma | int |
| Int64 | Valor de número entero de 64 bits con firma agregado con el carácter "L" Ejemplos: 64L, -352L |
long |
| Único | Número de punto flotante con precisión de 7 dígitos que puede representar valores con un rango aproximado de ± 1.18e-38 a ± 3.40e+38, con el carácter "f" al final. Ejemplo: 2.0f |
float |
| Doble | Número de punto flotante con precisión de 15 dígitos que puede representar valores con rangos aproximados de ± 2.23e -308 a ± 1.79e +308, agregados con el carácter "d". Ejemplos: 1E+10d, 2.029d, 2.0d |
double |
| Decimal | Valores numéricos con precisión y escala fijas que describen un valor numérico que varía de -10^255 + 1 a 10^255 -1, con el carácter “M” o “m” agregado Ejemplo: 2.345M |
decimal |
| Regla | ||
| GUID | Un valor de identificador único de 16 bytes (128 bits), que comienza con el carácter "guid" Ejemplo: guid'12345678-aaaa-bbbb-cccc-ddddeeeeffff' |
string |
| String | Datos de caracteres de longitud fija o variable codificados en UTF-8 | string |
| Byte | ||
| Objeto binario | Datos binarios de longitud fija o variable que comienzan con "X" o "binary" (ambos distinguen mayúsculas de minúsculas) Ejemplo: X'23AB', binary'23ABFF' |
bytes |
| Lógicos | ||
| Booleano | Concepto matemático de lógica de valores binarios | boolean |
| Fecha/hora | ||
| Fecha/hora | Fecha y hora con valores que van desde las 12:00:00 a.m. del 1 de enero de 1753 hasta las 11:59:59 p.m. del 31 de diciembre de 9999 | timestamp |
| Hora | Hora del día con valores que van desde 0:00:00.x hasta 23:59:59.y, en los que "x" y "y" dependen de la precisión | time |
| DateTimeOffset | Es la fecha y la hora como un desfase, en minutos desde GMT, con valores que van desde las 12:00:00 a.m. del 1 de enero de 1753 hasta las 11:59:59 p.m. del 31 de diciembre de 9999. | timestamp |
| Complejo | ||
| Propiedades de navegación y no de navegación (multiplicidad = *) | Colecciones de un tipo, con una multiplicidad de uno a varios. | array,string,int. |
| Propiedades (multiplicidad = 0.1) | Referencias a otros tipos complejos con una multiplicidad de uno a uno | record |
Validación
Haz clic en Validar en la esquina superior derecha o en Obtener esquema.
El complemento valida las propiedades y genera un esquema basado en los metadatos de SAP. Asigna automáticamente los tipos de datos de SAP a los tipos de datos de Cloud Data Fusion correspondientes.
Ejecuta una canalización de datos
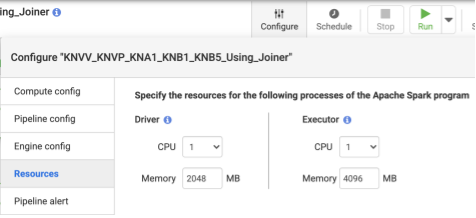
- Después de implementar la canalización, haz clic en Configurar, en el panel superior central.
- Selecciona Recursos.
- Si es necesario, cambia la CPU del ejecutor y la memoria según el tamaño general de los datos y la cantidad de transformaciones usadas en la canalización.
- Haz clic en Guardar.
- Para iniciar la canalización de datos, haz clic en Run.
Rendimiento
El complemento usa las capacidades de paralelización de Cloud Data Fusion. Los siguientes lineamientos pueden ayudarte a configurar el entorno de ejecución para que proporciones recursos suficientes al motor de ejecución y logres el grado de paralelismo y rendimiento deseados.
Cómo optimizar la configuración del complemento
Recomendación: A menos que estés familiarizado con la configuración de memoria de tu sistema SAP, deja la Cantidad de divisiones que se generarán y el Tamaño del lote en blanco (sin especificar).
Para obtener un mejor rendimiento cuando ejecutes tu canalización, usa la siguiente configuración:
Cantidad de divisiones que se deben generar: Se recomiendan valores entre
8y16. Sin embargo, pueden aumentar a32o incluso a64con la configuración adecuada en SAP (asignando los recursos de memoria adecuados para los procesos de trabajo en SAP). Esta configuración mejora el paralelismo en el lado de Cloud Data Fusion. El motor de tiempo de ejecución crea la cantidad especificada de particiones (y conexiones de SAP) mientras extrae los registros.Si el servicio de configuración (que se incluye con el complemento cuando importas el archivo de transporte de SAP) está disponible, el complemento usará de forma predeterminada la configuración del sistema SAP. Las divisiones son el 50% de los procesos de trabajo de diálogo disponibles en SAP. Nota: El servicio de configuración solo se puede importar desde sistemas S4HANA.
Si el servicio de configuración no está disponible, el valor predeterminado es
7divisiones.En cualquier caso, si especificas un valor diferente, el valor que proporciones prevalecerá sobre el valor de división predeterminado,excepto que estará limitado por los procesos de diálogo disponibles en SAP, menos dos divisiones.
Si la cantidad de registros que se deben extraer es menor que
2500, la cantidad de divisiones es1.
Tamaño del lote: Es el recuento de registros que se recuperarán en cada llamada de red a SAP. Un tamaño de lote más pequeño provoca llamadas frecuentes de red que repiten la sobrecarga asociada. De forma predeterminada, el recuento mínimo es
1000y el máximo es50000.
Para obtener más información, consulta Límites de entidades de OData.
Configuración de recursos de Cloud Data Fusion
Recomendado: Usa 1 CPU y 4 GB de memoria por ejecutor (este valor se aplica a cada proceso de ejecutor). Establece estos valores en el diálogo Configurar > Recursos.
Configuración del clúster de Dataproc
Recomendado: Como mínimo, asigna un total de CPUs (en todos los trabajadores) superior a la cantidad prevista de divisiones (consulta la configuración del complemento).
Cada trabajador debe tener 6.5 GB o más de memoria asignada por CPU en la configuración de Dataproc (esto se traduce en 4 GB o más disponibles por ejecutor de Cloud Data Fusion). El resto de la configuración se puede mantener en los valores predeterminados.
Recomendado: Usa un clúster de Dataproc persistente para reducir el tiempo de ejecución de la canalización de datos (esto elimina el paso de aprovisionamiento, que puede tardar unos minutos o más). Establece esta opción en la sección de configuración de Compute Engine.
Configuraciones y rendimiento de muestra
En las siguientes secciones, se describen ejemplos de configuraciones y rendimiento de desarrollo y producción.
Ejemplos de configuraciones de desarrollo y prueba
- Clúster de Dataproc con 8 trabajadores, cada uno con 4 CPU y 26 GB de memoria Genera hasta 28 divisiones.
- Clúster de Dataproc con 2 trabajadores, cada uno con 8 CPUs y 52 GB de memoria Genera hasta 12 divisiones.
Ejemplos de configuraciones de producción y rendimiento
- Clúster de Dataproc con 8 trabajadores, cada uno con 8 CPU y 32 GB de memoria Genera hasta 32 divisiones (la mitad de las CPUs disponibles).
- Clúster de Dataproc con 16 trabajadores, cada uno con 8 CPU y 32 GB de memoria Genera hasta 64 divisiones (la mitad de las CPUs disponibles).
Tasa de transferencia de muestra para un sistema de origen de producción de SAP S4HANA 1909
En la siguiente tabla, se muestra una muestra de la capacidad de procesamiento. La capacidad de procesamiento que se muestra no incluye opciones de filtro, a menos que se especifique lo contrario. Cuando se usan opciones de filtro, se reduce la capacidad de procesamiento.
| Tamaño del lote | División | Servicio de OData | Total de filas | Filas extraídas | Capacidad de procesamiento (filas por segundo) |
|---|---|---|---|---|---|
| 1000 | 4 | ZACDOCA_CDS | 5.37 M | 5.37 M | 1069 |
| 2,500 | 10 | ZACDOCA_CDS | 5.37 M | 5.37 M | 3384 |
| 5000 | 8 | ZACDOCA_CDS | 5.37 M | 5.37 M | 4630 |
| 5000 | 9 | ZACDOCA_CDS | 5.37 M | 5.37 M | 4817 |
Tasa de transferencia de muestra para un sistema de origen de producción en la nube de SAP S4HANA
| Tamaño del lote | División | Servicio de OData | Total de filas | Filas extraídas | Capacidad de procesamiento (GB/hora) |
|---|---|---|---|---|---|
| 2,500 | 40 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 M | 25.48 |
| 5000 | 50 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 M | 26.78 |
Detalles de la asistencia
El complemento admite los siguientes casos de uso.
Productos y versiones de SAP compatibles
Entre las fuentes admitidas, se incluyen SAP S4/HANA 1909 y versiones posteriores, S4/HANA en la nube de SAP y cualquier aplicación de SAP capaz de exponer servicios de OData.
El archivo de transporte que contiene el servicio de OData personalizado para el balanceo de cargas de las llamadas a SAP se debe importar en S4/HANA 1909 y versiones posteriores. El servicio ayuda a calcular la cantidad de divisiones (particiones de datos) que el complemento puede leer en paralelo (consulta cantidad de divisiones).
Se admite la versión 2 de OData.
El complemento se probó con servidores SAP S/4HANA implementados en Google Cloud.
SAP OData Catalog Services es compatible con la extracción
El complemento admite los siguientes tipos de DataSource:
- Datos de transacciones
- Vistas de CDS expuestas a través de OData
Datos maestros
- Atributos
- Textos
- Jerarquías
Notas de SAP
No se requieren notas de SAP antes de la extracción, pero el sistema SAP debe tener disponible la puerta de enlace de SAP. Para obtener más información, consulta la nota 1560585 (este sitio externo requiere un acceso de SAP).
Límites en el volumen de datos o el ancho del registro
No hay un límite definido para el volumen de datos extraídos. Realizamos pruebas con hasta 6 millones de filas extraídas en una llamada, con un ancho de registro de 1 KB. En el caso de SAP S4/HANA en la nube, realizamos pruebas con hasta 10 millones de filas extraídas en una llamada, con un ancho de registro de 1 KB.
Capacidad de procesamiento del complemento esperada
Para un entorno configurado de acuerdo con los lineamientos de la sección Rendimiento, el complemento puede extraer alrededor de 38 GB por hora. El rendimiento real puede variar con las cargas del sistema de Cloud Data Fusion y SAP, o el tráfico de red.
Extracción delta (datos modificados)
No se admite la extracción de delta.
Situaciones de error
Durante el tiempo de ejecución, el complemento escribe entradas de registro en el registro de la canalización de datos de Cloud Data Fusion. Estas entradas tienen el prefijo CDF_SAP para su identificación.
En el momento del diseño, cuando validas la configuración del complemento, los mensajes se muestran en la pestaña Properties y se destacan en rojo.
En la siguiente lista, se describen algunos de los errores:
| ID de mensaje | Mensaje | Acción recomendada |
|---|---|---|
| Ninguno | Required property 'CONNECTION_PROPERTY' for connection
type 'CONNECTION_PROPERTY_SETTING'. |
Ingresa un valor real o una variable de macro. |
| Ninguno | Invalid value for property 'PROPERTY_NAME'. |
Ingresa un número entero no negativo (0 o más, sin decimal) o una variable de macro. |
| CDF_SAP_ODATA_01505 | Failed to prepare the Cloud Data Fusion output schema. Please
check the provided runtime macros value. |
Asegúrate de que los valores de macro proporcionados sean correctos. |
| N/A | SAP X509 certificated 'STORAGE_PATH' is missing. Please
make sure the required X509 certificate is uploaded to your specified
Cloud Storage bucket 'BUCKET_NAME'. |
Asegúrate de que la ruta de acceso de Cloud Storage proporcionada sea correcta. |
| CDF_SAP_ODATA_01532 | Código de error genérico relacionado con problemas de conectividad de SAP ODataFailed to call given SAP OData service. Root Cause:
MESSAGE. |
Verifica la causa raíz que se muestra en el mensaje y toma las medidas adecuadas. |
| CDF_SAP_ODATA_01534 | Código de error genérico relacionado con un error del servicio de OData de SAP.Service validation failed. Root Cause: MESSAGE. |
Verifica la causa raíz que se muestra en el mensaje y toma las medidas adecuadas. |
| CDF_SAP_ODATA_01503 | Failed to fetch total available record count from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause: MESSAGE.
|
Verifica la causa raíz que se muestra en el mensaje y toma las medidas adecuadas. |
| CDF_SAP_ODATA_01506 | No records found to extract in
SAP_ODATA_SERVICE_ENTITY_NAME.
Please ensure that the provided entity contains records. |
Verifica la causa raíz que se muestra en el mensaje y toma las medidas adecuadas. |
| CDF_SAP_ODATA_01537 | Failed to process records for
SAP_ODATA_SERVICE_ENTITY_NAME.
Root Cause: MESSAGE. |
Verifica la causa raíz que se muestra en el mensaje y toma las medidas adecuadas. |
| CDF_SAP_ODATA_01536 | Failed to pull records from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause:
MESSAGE. |
Verifica la causa raíz que se muestra en el mensaje y toma las medidas adecuadas. |
| CDF_SAP_ODATA_01504 | Failed to generate the encoded metadata string for the given OData
service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Verifica la causa raíz que se muestra en el mensaje y toma las medidas adecuadas. |
| CDF_SAP_ODATA_01533 | Failed to decode the metadata from the given encoded metadata
string for service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Verifica la causa raíz que se muestra en el mensaje y toma las medidas adecuadas. |
¿Qué sigue?
- Obtén más información sobre Cloud Data Fusion.
- Obtén más información sobre SAP en Google Cloud.