Neste guia, descrevemos como implantar, configurar e executar pipelines de dados que usam o plug-in SAP OData.
É possível usar o SAP como uma fonte de extração de dados baseada em lote no Cloud Data Fusion usando o Open Data Protocol (OData). O plug-in SAP OData ajuda a configurar e executar transferências de dados do SAP OData Catalog Services sem programação.
Para mais informações sobre os serviços e os DataSources do catálogo SAP OData compatíveis, consulte os detalhes de suporte. Para mais informações sobre o SAP no Google Cloud, consulte a Visão geral do SAP no Google Cloud.
Objetivos
- Configurar o sistema SAP ERP (ativar DataSources no SAP).
- Implante o plug-in no ambiente do Cloud Data Fusion.
- Faça o download do transporte SAP do Cloud Data Fusion e instale-o no SAP.
- Use o Cloud Data Fusion e o SAP OData para criar pipelines de dados e integrar dados do SAP.
Antes de começar
Para usar esse plug-in, é necessário ter conhecimento dos domínios nas seguintes áreas:
- Criar pipelines no Cloud Data Fusion
- Gerenciamento de acesso com o IAM
- Como configurar sistemas de planejamento de recursos empresariais (ERP) locais e da SAP Cloud
Papéis do usuário
As tarefas nesta página são realizadas por pessoas com as seguintes funções no Google Cloud ou no sistema SAP:
| Tipo de usuário | Descrição |
|---|---|
| Administrador do Google Cloud | Os usuários atribuídos a esse papel são administradores de contas do Google Cloud. |
| Usuário do Cloud Data Fusion | Os usuários atribuídos a esse papel estão autorizados a projetar e executar pipelines
de dados. Eles recebem, no mínimo, o papel de leitor do Data Fusion
(
roles/datafusion.viewer). Se você estiver usando o controle de acesso baseado em papéis, talvez seja necessário usar outros papéis.
|
| Administrador do SAP | Os usuários atribuídos a essa função são administradores do sistema SAP. Eles têm acesso para fazer o download de softwares do site de serviços da SAP. Não é um papel do IAM. |
| Usuário SAP | Os usuários atribuídos a esse papel estão autorizados a se conectar a um sistema SAP. Não é um papel do IAM. |
Pré-requisitos para extração de OData
O serviço OData Catalog precisa ser ativado no sistema SAP.
Os dados precisam ser preenchidos no serviço OData.
Pré-requisitos para seu sistema SAP
No SAP NetWeaver 7.02 até a versão 7.31 do SAP NetWeaver, as funcionalidades do OData e do SAP Gateway são fornecidas com os seguintes componentes de software SAP:
IW_FNDGW_COREIW_BEP
Na versão 7.40 e mais recentes do SAP NetWeaver, todas as funcionalidades estão disponíveis no componente
SAP_GWFND, que precisa ser disponibilizado no SAP NetWeaver.
Opcional: instalar arquivos de transporte SAP
Os componentes da SAP necessários para o balanceamento de carga de chamadas para a SAP são entregues como arquivos de transporte SAP arquivados como um arquivo ZIP (uma solicitação de transporte, que consiste em um cofile e um arquivo de dados). Use essa etapa para limitar várias chamadas paralelas ao SAP com base nos processos de trabalho disponíveis no SAP.
O download do arquivo ZIP fica disponível quando você implanta o plug-in no Hub do Cloud Data Fusion.
Quando você importa os arquivos de transporte para o SAP, os seguintes projetos SAP OData são criados:
Projetos OData
/GOOG/GET_STATISTIC/GOOG/TH_WPINFO
Nó de serviço do ICF:
GOOG
Para instalar o transporte SAP, siga estas etapas:
Etapa 1: fazer upload dos arquivos de solicitação de transporte
- Faça login no sistema operacional da instância do SAP.
- Use o código de transação
AL11do SAP para acessar o caminho da pastaDIR_TRANS. Normalmente, o caminho é/usr/sap/trans/. - Copie os cofiles para a pasta
DIR_TRANS/cofiles. - Copie os arquivos de dados para a pasta
DIR_TRANS/data. - Defina o usuário e o grupo de dados e o coarquivo como
<sid>admesapsys.
Etapa 2: importar os arquivos de solicitação de transporte
O administrador da SAP pode importar os arquivos de solicitação de transporte usando uma das seguintes opções:
Opção 1: importar os arquivos de solicitação de transporte usando o sistema de gerenciamento de transporte SAP
- Faça login no sistema SAP como administrador da SAP.
- Digite o STMS da transação.
- Clique em Visão geral > Importações.
- Na coluna Fila, clique duas vezes no SID atual.
- Clique em Extras > Outras solicitações > Adicionar.
- Selecione o ID da solicitação de transporte e clique em Continuar.
- Selecione a solicitação de transporte na fila de importação e clique em Solicitar > Importar.
- Digite o número do cliente.
Na guia Opções, selecione Substituir originais e Ignorar a versão inválida do componente (se disponível).
(Opcional) Para programar uma reimportação de transportes para um momento posterior, selecione Deixar solicitações de transporte na fila para importação posterior e Importar solicitações de transporte novamente. Isso é útil para upgrades do sistema SAP e restaurações de backup.
Clique em Continuar.
Para verificar a importação, use transações, como
SE80eSU01.
Opção 2: importar os arquivos de solicitações de transporte no nível do sistema operacional
- Faça login no sistema SAP como administrador do sistema.
Adicione as solicitações apropriadas ao buffer de importação executando o seguinte comando:
tp addtobuffer TRANSPORT_REQUEST_ID SIDPor exemplo:
tp addtobuffer IB1K903958 DD1Importe as solicitações de transporte executando o seguinte comando:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238Substitua
NNNpelo número do cliente. Por exemplo:tp import IB1K903958 DD1 client=800 U1238Verifique se o módulo da função e os papéis de autorização foram importados com êxito usando as transações apropriadas, como
SE80eSU01.
Receber uma lista de colunas filtráveis para um serviço de catálogo da SAP
Somente algumas colunas da DataSource podem ser usadas para condições de filtro. Essa é uma limitação do SAP por padrão.
Para conferir uma lista de colunas filtráveis para um serviço de catálogo da SAP, siga estas etapas:
- Faça login no sistema SAP.
- Acesse o t-code
SEGW. Digite o nome do projeto OData, que é uma substring do nome do serviço. Exemplo:
- Nome do serviço:
MM_PUR_POITEMS_MONI_SRV - Nome do projeto:
MM_PUR_POITEMS_MONI
- Nome do serviço:
Clique em Enter.
Acesse a entidade que você quer filtrar e selecione Propriedades.
Use os campos mostrados em Propriedades como filtros. As operações aceitas são Igual e Entre (intervalo).

Para conferir uma lista de operadores com suporte no idioma de expressão, consulte a documentação de código aberto do OData: Convenção de URI (OData versão 2.0).
Exemplo de URI com filtros:
/sap/opu/odata/sap/MM_PUR_POITEMS_MONI_SRV/C_PurchaseOrderItemMoni(P_DisplayCurrency='USD')/Results/?$filter=(PurchaseOrder eq '4500000000')
Configurar o sistema ERP da SAP
O plug-in SAP OData usa um serviço OData que é ativado em cada servidor SAP de onde os dados são extraídos. Esse serviço OData pode ser um padrão fornecido pela SAP ou um serviço OData personalizado desenvolvido no seu sistema SAP.
Etapa 1: instalar o SAP Gateway 2.0
O administrador do SAP (Basis) precisa verificar se os componentes do SAP Gateway 2.0 estão disponíveis no sistema de origem do SAP, dependendo da versão do NetWeaver. Para mais informações sobre a instalação do SAP Gateway 2.0, faça login no SAP ONE Support Launchpad e consulte a Nota 1569624 (login necessário) .
Etapa 2: ativar o serviço OData
Ative o serviço OData necessário no sistema de origem. Para mais informações, consulte Servidor front-end: ativar os serviços OData.
Etapa 3: criar uma função de autorização
Para se conectar à DataSource, crie uma função de autorização com as autorizações necessárias no SAP e conceda-a ao usuário do SAP.
Para criar o papel de autorização no SAP, siga estas etapas:
- Na GUI do SAP, digite o código da transação PFCG para abrir a janela Manutenção de papéis.
No campo Papel, insira um nome para o papel.
Por exemplo:
ZODATA_AUTHClique em Papel único.
A janela Criar papéis é aberta.
No campo Descrição, insira uma descrição e clique em Salvar.
Por exemplo,
Authorizations for SAP OData plugin.Clique na guia Autorizações. O título da janela muda para Alterar papéis.
Em Editar dados de autorização e gerar perfis, clique em Alterar dados de autorização.
A janela Choose Template será aberta.
Clique em Não selecionar modelos.
A janela Alterar papel: autorizações é aberta.
Clique em Manualmente.
Forneça as autorizações mostradas na tabela de autorização da SAP a seguir.
Clique em Save.
Para ativar o papel de autorização, clique no ícone Gerar.
Autorizações da SAP
| Classe de objeto | Texto de classe do objeto | Objeto de autorização | Texto do objeto de autorização | Autorização | Texto | Valor |
|---|---|---|---|---|---|---|
| AAAB | Objetos de autorização entre aplicativos | S_SERVICE | Verificar na inicialização dos serviços externos | SRV_NAME | Nome do programa, da transação ou do módulo de função | * |
| AAAB | Objetos de autorização entre aplicativos | S_SERVICE | Verificar na inicialização dos serviços externos | SRV_TYPE | Tipo de flag de verificação e valores padrão de autorização | HT |
| FI | Contabilidade financeira | F_UNI_HIER | Acesso universal à hierarquia | ACTVT. | Atividade | 03 |
| FI | Contabilidade financeira | F_UNI_HIER | Acesso universal à hierarquia | HRYTYPE | Tipo de hierarquia | * |
| FI | Contabilidade financeira | F_UNI_HIER | Acesso universal à hierarquia | HRYID | ID da hierarquia | * |
Para projetar e executar um pipeline de dados no Cloud Data Fusion (como usuário do Cloud Data Fusion), você precisa de credenciais de usuário SAP (nome de usuário e senha) para configurar o plug-in para se conectar à fonte de dados.
O usuário SAP precisa ser do tipo Communications ou Dialog. Para evitar o uso de
recursos da caixa de diálogo do SAP, o tipo Communications é recomendado. Os usuários podem ser
criados usando o código de transação SU01 do SAP.
Opcional: etapa 4: proteger a conexão
É possível proteger a comunicação pela rede entre sua instância privada do Cloud Data Fusion e a SAP.
Para proteger a conexão, siga estas etapas:
- O administrador do SAP precisa gerar um certificado X509. Para gerar o certificado, consulte Como criar um PSE de servidor SSL.
- O Google Cloud administrador precisa copiar o arquivo X509 para um bucket do Cloud Storage legível no mesmo projeto da instância do Cloud Data Fusion e fornecer o caminho do bucket ao usuário do Cloud Data Fusion, que vai inseri-lo ao configurar o plug-in.
- O administrador do Google Cloud precisa conceder acesso de leitura para o arquivo X509 ao usuário do Cloud Data Fusion que projeta e executa pipelines.
Opcional: etapa 5: criar serviços OData personalizados
É possível personalizar a extração de dados criando serviços OData personalizados na SAP:
- Para criar serviços OData personalizados, consulte Criação de serviços OData para iniciantes.
- Para criar serviços OData personalizados usando visualizações de serviços de dados principais (CDS), consulte Como criar um serviço OData e expor visualizações de CDS como um serviço OData.
- Qualquer serviço OData personalizado precisa oferecer suporte a consultas
$top,$skipe$count. Essas consultas permitem que o plug-in particione os dados para extração sequencial e paralela. Se usado, as consultas$filter,$expandou$selecttambém precisam ser compatíveis.
Configurar o Cloud Data Fusion
Verifique se a comunicação está ativada entre a instância do Cloud Data Fusion e o servidor SAP. Para instâncias particulares, configure o peering de rede. Depois que o peering de rede é estabelecido com o projeto em que os sistemas SAP estão hospedados, nenhuma configuração adicional é necessária para se conectar à instância do Cloud Data Fusion. O sistema SAP e a instância do Cloud Data Fusion precisam estar dentro do mesmo projeto.
Etapa 1: configurar o ambiente do Cloud Data Fusion
Para configurar o ambiente do Cloud Data Fusion para o plug-in, siga estas etapas:
Acesse os detalhes da instância:
No console Google Cloud , acesse a página do Cloud Data Fusion.
Clique em Instâncias e, depois, no nome da instância para acessar a página Detalhes da instância.
Verifique se a instância foi atualizada para a versão 6.4.0 ou mais recente. Se a instância estiver em uma versão anterior, será necessário fazer upgrade dela.
Clique em Visualizar instância. Quando a interface do Cloud Data Fusion abrir, clique em Hub.
Selecione a guia SAP > SAP OData.
Se a guia "SAP" não for exibida, consulte Solução de problemas de integrações do SAP.
Clique em Implantar plug-in SAP OData.
O plug-in agora será exibido no menu Origem na página do Studio.
Etapa 2: configurar o plug-in
O plug-in SAP OData lê o conteúdo de um DataSource do SAP.
Para filtrar os registros, configure as seguintes propriedades na página "Propriedades do SAP OData".
| Nome da propriedade | Descrição |
|---|---|
| Basic | |
| Nome de referência | Nome usado para identificar exclusivamente essa origem para linhagem ou anotação de metadados. |
| URL de base do SAP OData | URL de base do OData do SAP Gateway (use o caminho do URL completo, semelhante a
https://ADDRESS:PORT/sap/opu/odata/sap/).
|
| Versão do OData | Versão do SAP OData com suporte. |
| Nome do serviço | Nome do serviço SAP OData de onde você quer extrair uma entidade. |
| Nome da entidade | Nome da entidade que está sendo extraída, como Results. Você pode usar um prefixo, como C_PurchaseOrderItemMoni/Results. Esse campo aceita parâmetros de categoria e entidade. Exemplos:
|
| Credenciais* | |
| Tipo SAP | Básica (por nome de usuário e senha). |
| Nome de usuário de logon SAP | Nome de usuário do SAP Recomendado: se o nome de usuário do SAP Authentication mudar periodicamente, use uma macro. |
| Senha de logon SAP | Senha do usuário do SAP Recomendado: use macros seguras para valores sensíveis, como senhas. |
| Certificado de cliente X.509 da SAP (consulte Como usar certificados de cliente X.509 no SAP NetWeaver Application Server para ABAP. |
|
| ID do projeto do GCP | Um identificador globalmente exclusivo para seu projeto. Esse campo é obrigatório se o campo X.509 Certificate Cloud Storage Path não contiver um valor de macro. |
| Caminho do GCS | O caminho do bucket do Cloud Storage que contém o certificado X.509 enviado pelo usuário, que corresponde ao servidor de aplicativos da SAP para chamadas seguras com base nos seus requisitos (consulte a etapa Proteger a conexão). |
| Senha longa | Senha correspondente ao certificado X.509 fornecido. |
| Botão Acessar esquema | Gera um esquema com base nos metadados da SAP, com mapeamento automático dos tipos de dados da SAP para os tipos de dados correspondentes do Cloud Data Fusion (mesma funcionalidade do botão Validar). |
| Avançado | |
| Opções de filtro | Indica o valor que um campo precisa ter para ser lido. Use essa condição de filtro para restringir o volume de dados de saída. Por exemplo: "Price Gt 200" seleciona os registros com um valor de campo "Price" maior que "200". Consulte Conferir uma lista de colunas filtráveis para um serviço de catálogo SAP. |
| Selecionar campos | Campos a serem preservados nos dados extraídos (por exemplo: categoria, preço, nome, fornecedor/endereço). |
| Abrir campos | Lista de campos complexos a serem expandidos nos dados de saída extraídos (por exemplo, "Produtos/Fornecedores"). |
| Número de linhas a pular | Número total de linhas a serem ignoradas (por exemplo, 10). |
| Número de linhas a serem buscadas | Número total de linhas a serem extraídas. |
| Número de divisões a serem geradas | O número de divisões usadas para particionar os dados de entrada. Mais partições
aumentam o nível de paralelismo, mas exigem mais recursos e
sobrecarga. Se deixado em branco, o plug-in escolhe um valor ideal (recomendado). |
| Tamanho do lote | Número de linhas a serem buscadas em cada chamada de rede para a SAP. Um tamanho pequeno faz com que
chamadas de rede frequentes repitam a sobrecarga associada. Um tamanho grande
pode retardar a recuperação de dados e causar o uso excessivo de recursos no SAP.
Se o valor for definido como 0, o valor padrão será
2500, e o limite de linhas a serem buscadas em cada lote será
5000. |
| Tempo limite de leitura | O tempo, em segundos, de espera para o serviço SAP OData. O valor
padrão é 300. Para não ter limite de tempo, defina como 0. |
Tipos de OData aceitos
A tabela a seguir mostra o mapeamento entre os tipos de dados do OData v2 usados em aplicativos SAP e os tipos de dados do Cloud Data Fusion.
| Tipo OData | Descrição (SAP) | Tipo de dados do Cloud Data Fusion |
|---|---|---|
| Numérico | ||
| SByte | Valor inteiro de 8 bits assinado | int |
| Byte | Valor inteiro de 8 bits sem assinatura | int |
| Int16 | Valor inteiro de 16 bits assinado | int |
| Int32 | Valor inteiro de 32 bits assinado | int |
| Int64 | Valor inteiro assinado de 64 bits anexado ao caractere: 'L' Exemplos: 64L, -352L |
long |
| Cluster único | Número de ponto flutuante com precisão de 7 dígitos que pode representar valores
com um intervalo aproximado de ± 1,18e -38 a ± 3,40e +38, anexado
com o caractere: 'f' Exemplo: 2.0f |
float |
| Duplo | Número de ponto flutuante com precisão de 15 dígitos que pode representar valores
com intervalos aproximados de ± 2,23e -308 a ± 1,79e +308, anexados
com o caractere: 'd' Exemplos: 1E+10d, 2.029d, 2.0d |
double |
| Decimal | Valores numéricos com precisão e escala fixas que descrevem um valor numérico
variando de 10^255 -1 a 10^255 + 1, anexado com o
caractere: 'M' ou 'm' Exemplo: 2.345M |
decimal |
| Caractere | ||
| GUID | Um valor de identificador exclusivo de 16 bytes (128 bits), começando com o
caractere: 'guid' Exemplo: guid'12345678-aaaa-bbbb-cccc-ddddeeeeffff' |
string |
| String | Dados de caracteres de comprimento fixo ou variável codificados em UTF-8 | string |
| Byte | ||
| Binário | Dados binários de comprimento fixo ou variável, começando com "X" ou
'binary' (ambos diferenciam maiúsculas de minúsculas) Exemplo: X'23AB', binary'23ABFF' |
bytes |
| Lógica | ||
| Booleano | Conceito matemático de lógica de valor binário | boolean |
| Data/hora | ||
| Data/hora | Data e hora com valores que variam de 12:00:00 AM em 1º de janeiro de 1753 a 23:59:59 PM em 31 de dezembro de 9999 | timestamp |
| Hora | Hora do dia com valores que variam de 0:00:00.x a 23:59:59.y, em que "x" e "y" dependem da precisão | time |
| DateTimeOffset | Data e hora como um deslocamento, em minutos a partir do GMT, com valores que variam de 12:00:00 de 1º de janeiro de 1753 a 23:59:59 de 31 de dezembro de 9999 | timestamp |
| Complexo | ||
| Propriedades de navegação e não navegação (multiplicidade = *) | Coleções de um tipo, com uma multiplicidade de um para muitos. | array,string,int. |
| Propriedades (multiplicidade = 0,1) | Referências a outros tipos complexos com uma multiplicidade de um para um | record |
Validação
Clique em Validate no canto superior direito ou em Get Schema.
O plug-in valida as propriedades e gera um esquema com base nos metadados da SAP. Ele mapeia automaticamente os tipos de dados da SAP para os tipos de dados correspondentes do Cloud Data Fusion.
Executar um pipeline de dados
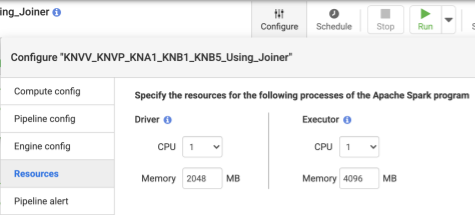
- Depois de implantar o pipeline, clique em Configurar no painel central superior.
- Selecione Recursos.
- Se necessário, altere a CPU do Executor e a Memória com base no tamanho geral dos dados e no número de transformações usadas no pipeline.
- Clique em Save.
- Para iniciar o pipeline de dados, clique em Executar.
Desempenho
Os plug-ins usam os recursos de carregamento em paralelo do Cloud Data Fusion. As diretrizes a seguir ajudarão a configurar o ambiente de execução para que você forneça recursos suficientes ao mecanismo para atingir o grau de paralelismo e desempenho desejado.
Otimizar a configuração do plug-in
Recomendado:a menos que você conheça as configurações de memória do sistema SAP, deixe o Número de divisões a serem geradas e o Tamanho do lote em branco (não especificado).
Para ter um desempenho melhor ao executar o pipeline, use as seguintes configurações:
Número de divisões a serem geradas: recomendamos valores entre
8e16. No entanto, é possível aumentar para32ou até64com configurações adequadas no lado do SAP (alocando recursos de memória apropriados para os processos de trabalho no SAP). Essa configuração melhora o paralelismo no Cloud Data Fusion. O mecanismo do ambiente de execução cria o número especificado de partições (e conexões SAP) enquanto extrai os registros.Se o serviço de configuração (que vem com o plug-in quando você importa o arquivo de transporte da SAP) estiver disponível: o plug-in vai usar a configuração padrão do sistema SAP. As divisões são 50% dos processos de trabalho de caixa de diálogo disponíveis no SAP. Observação: o serviço de configuração só pode ser importado de sistemas S/4HANA.
Se o serviço de configuração não estiver disponível, o padrão será divisões
7.Em qualquer caso, se você especificar um valor diferente, o valor fornecido prevalecerá sobre o valor de divisão padrão,exceto se for limitado pelos processos de diálogo disponíveis no SAP, menos duas divisões.
Se o número de registros a serem extraídos for menor que
2500, o número de divisões será1.
Tamanho do lote: é a contagem de registros a serem buscados em todas as chamadas de rede para SAP. Um tamanho de lote menor causa chamadas de rede frequentes, repetindo a sobrecarga associada. Por padrão, a contagem mínima é
1000, e a máxima é50000.
Para mais informações, consulte Limites de entidade do OData.
Configurações de recursos do Cloud Data Fusion
Recomendado:use 1 CPU e 4 GB de memória por Executor. Esse valor se aplica a cada processo de Executor. Faça isso na caixa de diálogo Configurar > Recursos.
Configurações de cluster do Dataproc
Recomendado:no mínimo, aloque um total de CPUs (entre workers) maior que o número pretendido de divisões. Consulte a seção Configuração de plug-ins.
Cada worker precisa ter 6,5 GB ou mais de memória alocada por CPU nas configurações do Dataproc, o que significa 4 GB ou mais disponíveis por Executor do Cloud Data Fusion. Outras configurações podem ser mantidas nos valores padrão.
Recomendado:use um cluster permanente do Dataproc para reduzir o ambiente de execução do pipeline de dados. Isso elimina a etapa de provisionamento, que pode levar alguns minutos ou mais. Faça isso na seção de configuração do Compute Engine.
Exemplos de configurações e taxa de transferência
As seções a seguir descrevem exemplos de configurações de desenvolvimento e produção e de taxa de transferência.
Exemplos de configurações de desenvolvimento e teste
- Cluster do Dataproc com 8 workers, cada um com 4 CPUs e 26 GB de memória. Gere até 28 divisões.
- Cluster do Dataproc com dois workers, cada um com 8 CPUs e 52 GB de memória. Gere até 12 divisões.
Exemplos de configurações de produção e taxa de transferência
- Cluster do Dataproc com 8 workers, cada um com 8 CPUs e 32 GB de memória. Gera até 32 divisões (metade das CPUs disponíveis).
- Cluster do Dataproc com 16 workers, cada um com 8 CPUs e 32 GB de memória. Gere até 64 divisões (metade das CPUs disponíveis).
Exemplo de taxa de transferência para um sistema de origem de produção do SAP S/4HANA 1909
A tabela a seguir tem um exemplo de capacidade de processamento. A taxa de transferência mostrada não tem opções de filtro, a menos que seja especificado o contrário. Ao usar opções de filtro, a taxa de transferência é reduzida.
| Tamanho do lote | Divisões | Serviço OData | Total de linhas | Linhas extraídas | Capacidade (linhas por segundo) |
|---|---|---|---|---|---|
| 1000 | 4 | ZACDOCA_CDS | 5,37 milhões | 5,37 milhões | 1069 |
| 2500 | 10 | ZACDOCA_CDS | 5,37 milhões | 5,37 milhões | 3384 |
| 5000 | 8 | ZACDOCA_CDS | 5,37 milhões | 5,37 milhões | 4.630 |
| 5000 | 9 | ZACDOCA_CDS | 5,37 milhões | 5,37 milhões | 4817 |
Exemplo de taxa de transferência para um sistema de origem de produção em nuvem do SAP S/4HANA
| Tamanho do lote | Divisões | Serviço OData | Total de linhas | Linhas extraídas | Capacidade de processamento (GB/hora) |
|---|---|---|---|---|---|
| 2500 | 40 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 M | 25,48 |
| 5000 | 50 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 M | 26,78 |
Detalhes do suporte
O plug-in oferece suporte aos seguintes casos de uso:
Produtos e versões do SAP compatíveis
As fontes compatíveis incluem SAP S4/HANA 1909 e versões mais recentes, S4/HANA no SAP Cloud e qualquer aplicativo SAP capaz de expor serviços OData.
O arquivo de transporte que contém o serviço OData personalizado para balanceamento de carga das chamadas para a SAP precisa ser importado no S4/HANA 1909 e versões mais recentes. O serviço ajuda a calcular o número de divisões (partições de dados) que o plug-in pode ler em paralelo (consulte número de divisões).
OData versão 2 é compatível.
O plug-in foi testado com servidores SAP S/4HANA implantados em Google Cloud.
O SAP OData Catalog Services tem suporte para extração
O plug-in é compatível com os seguintes tipos de DataSource:
- Dados de transações
- Visualizações de CDS expostas pelo OData
Dados principais
- Atributos
- Textos
- hierarquias
Notas do SAP
Não são necessárias notas do SAP antes da extração, mas o sistema SAP precisa ter o SAP Gateway disponível. Para mais informações, consulte a nota 1560585 (este site externo requer um login do SAP).
Limites no volume de dados ou na largura do registro
Não há limite definido para o volume de dados extraídos. Testamos até 6 milhões de linhas extraídas em uma chamada, com uma largura de registro de 1 KB. Para o SAP S/4HANA na nuvem, testamos até 10 milhões de linhas extraídas em uma chamada, com uma largura de registro de 1 KB.
Capacidade esperada do plug-in
Para um ambiente configurado de acordo com as diretrizes da seção Performance, o plug-in pode extrair cerca de 38 GB/hora. O desempenho real pode variar de acordo com a carga do sistema do Cloud Data Fusion e do SAP ou tráfego de rede.
Extração de delta (dados alterados)
A extração delta não é compatível.
Cenários de erro
No ambiente de execução, o plug-in grava entradas de registro no registro do pipeline de dados do Cloud Data Fusion. Essas entradas têm o prefixo CDF_SAP para identificação.
No momento do design, quando você valida as configurações do plug-in, as mensagens são exibidas na guia Propriedades e destacadas em vermelho.
A lista a seguir descreve alguns dos erros:
| ID da mensagem | Mensagem | Ação recomendada |
|---|---|---|
| Nenhum | Required property 'CONNECTION_PROPERTY' for connection
type 'CONNECTION_PROPERTY_SETTING'. |
Insira um valor real ou uma variável de macro. |
| Nenhum | Invalid value for property 'PROPERTY_NAME'. |
Insira um número inteiro não negativo (0 ou maior, sem um decimal) ou uma variável de macro. |
| CDF_SAP_ODATA_01505 | Failed to prepare the Cloud Data Fusion output schema. Please
check the provided runtime macros value. |
Verifique se os valores de macro fornecidos estão corretos. |
| N/A | SAP X509 certificated 'STORAGE_PATH' is missing. Please
make sure the required X509 certificate is uploaded to your specified
Cloud Storage bucket 'BUCKET_NAME'. |
Verifique se o caminho do Cloud Storage fornecido está correto. |
| CDF_SAP_ODATA_01532 | Código de erro genérico relacionado a problemas de conectividade do SAP ODataFailed to call given SAP OData service. Root Cause:
MESSAGE. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01534 | Código de erro genérico relacionado a um erro do serviço OData do SAP.Service validation failed. Root Cause: MESSAGE. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01503 | Failed to fetch total available record count from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause: MESSAGE.
|
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01506 | No records found to extract in
SAP_ODATA_SERVICE_ENTITY_NAME.
Please ensure that the provided entity contains records. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01537 | Failed to process records for
SAP_ODATA_SERVICE_ENTITY_NAME.
Root Cause: MESSAGE. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01536 | Failed to pull records from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause:
MESSAGE. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01504 | Failed to generate the encoded metadata string for the given OData
service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01533 | Failed to decode the metadata from the given encoded metadata
string for service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Verifique a causa raiz exibida na mensagem e tome as medidas adequadas. |
A seguir
- Saiba mais sobre o Cloud Data Fusion.
- Saiba mais sobre o SAP no Google Cloud.