Este guia descreve como implementar, configurar e executar pipelines de dados que usam o plugin SAP OData.
Pode usar o SAP como origem para a extração de dados baseada em lotes no Cloud Data Fusion através do Open Data Protocol (OData). O plug-in SAP OData ajuda a configurar e executar transferências de dados dos serviços de catálogo SAP OData sem programação.
Para mais informações acerca dos serviços de catálogo SAP OData e das origens de dados suportados, consulte os detalhes de apoio técnico. Para mais informações sobre o SAP no Google Cloud, consulte a vista geral do SAP no Google Cloud.
Objetivos
- Configure o sistema SAP ERP (ative as origens de dados no SAP).
- Implemente o plug-in no seu ambiente do Cloud Data Fusion.
- Transfira o transporte SAP do Cloud Data Fusion e instale-o no SAP.
- Use o Cloud Data Fusion e o SAP OData para criar pipelines de dados para integrar dados SAP.
Antes de começar
Para usar este plug-in, precisa de conhecimentos do domínio nas seguintes áreas:
- Criar pipelines no Cloud Data Fusion
- Gestão de acessos com o IAM
- Configurar sistemas de planeamento de recursos empresariais (ERP) locais e na nuvem da SAP
Funções do utilizador
As tarefas nesta página são realizadas por pessoas com as seguintes funções no Google Cloud ou no respetivo sistema SAP:
| Tipo de utilizador | Descrição |
|---|---|
| Administrador do Google Cloud | Os utilizadores aos quais esta função é atribuída são administradores de contas do Google Cloud. |
| Utilizador do Cloud Data Fusion | Os utilizadores aos quais esta função é atribuída estão autorizados a conceber e executar
Data pipelines. No mínimo, é-lhes concedida a função de visitante do Data Fusion
(
roles/datafusion.viewer). Se estiver a usar o controlo de acesso baseado em funções, pode precisar de funções adicionais.
|
| Administrador SAP | Os utilizadores aos quais esta função é atribuída são administradores do sistema SAP. Têm acesso à transferência de software a partir do site de serviços da SAP. Não é uma função de IAM. |
| Utilizador do SAP | Os utilizadores aos quais esta função é atribuída estão autorizados a estabelecer ligação a um sistema SAP. Não é uma função de IAM. |
Pré-requisitos para a extração de OData
O serviço de catálogo OData tem de ser ativado no sistema SAP.
Os dados têm de ser preenchidos no serviço OData.
Pré-requisitos para o seu sistema SAP
No SAP NetWeaver 7.02 até à versão 7.31 do SAP NetWeaver, as funcionalidades OData e SAP Gateway são fornecidas com os seguintes componentes de software SAP:
IW_FNDGW_COREIW_BEP
Na versão 7.40 e posteriores do SAP NetWeaver, todas as funcionalidades estão disponíveis no componente
SAP_GWFND, que tem de ser disponibilizado no SAP NetWeaver.
Opcional: instale ficheiros de transporte SAP
Os componentes SAP necessários para o equilíbrio de carga de chamadas para o SAP são fornecidos como ficheiros de transporte SAP arquivados como um ficheiro ZIP (um pedido de transporte, que consiste num cofile e num ficheiro de dados). Pode usar este passo para limitar várias chamadas paralelas ao SAP, com base nos processos de trabalho disponíveis no SAP.
A transferência do ficheiro ZIP está disponível quando implementa o plug-in no hub do Cloud Data Fusion.
Quando importa os ficheiros de transporte para o SAP, são criados os seguintes projetos SAP OData:
Projetos OData
/GOOG/GET_STATISTIC/GOOG/TH_WPINFO
Nó de serviço ICF:
GOOG
Para instalar o transporte SAP, siga estes passos:
Passo 1: carregue os ficheiros de pedido de transporte
- Inicie sessão no sistema operativo da instância SAP.
- Use o código de transação SAP
AL11para obter o caminho da pastaDIR_TRANS. Normalmente, o caminho é/usr/sap/trans/. - Copie os ficheiros de configuração para a pasta
DIR_TRANS/cofiles. - Copie os ficheiros de dados para a pasta
DIR_TRANS/data. - Defina o utilizador e o grupo de dados e o cofile como
<sid>admesapsys.
Passo 2: importe os ficheiros de pedido de transporte
O administrador do SAP pode importar os ficheiros de pedido de transporte através de uma das seguintes opções:
Opção 1: importe os ficheiros de pedido de transporte através do sistema de gestão de transportes da SAP
- Inicie sessão no sistema SAP como administrador do SAP.
- Introduza o STMS da transação.
- Clique em Vista geral > Importações.
- Na coluna Fila, clique duas vezes no SID atual.
- Clique em Extras > Outros pedidos > Adicionar.
- Selecione o ID do pedido de transporte e clique em Continuar.
- Selecione o pedido de transporte na fila de importação e, de seguida, clique em Pedido > Importar.
- Introduza o número de cliente.
No separador Opções, selecione Substituir originais e Ignorar versão de componente inválida (se disponível).
(Opcional) Para agendar uma reimportação dos transportes para mais tarde, selecione Deixar pedidos de transporte na fila para importação posterior e Importar pedidos de transporte novamente. Isto é útil para atualizações do sistema SAP e restauros de cópias de segurança.
Clique em Continuar.
Para validar a importação, use quaisquer transações, como
SE80eSU01.
Opção 2: importe os ficheiros de pedido de transporte ao nível do sistema operativo
- Inicie sessão no sistema SAP como administrador do sistema SAP.
Adicione os pedidos adequados ao buffer de importação executando o seguinte comando:
tp addtobuffer TRANSPORT_REQUEST_ID SIDPor exemplo:
tp addtobuffer IB1K903958 DD1Importe os pedidos de transporte executando o seguinte comando:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238Substitua
NNNpelo número do cliente. Por exemplo:tp import IB1K903958 DD1 client=800 U1238Verifique se o módulo de função e as funções de autorização foram importados com êxito através de quaisquer transações adequadas, como
SE80eSU01.
Aceda a uma lista de colunas filtráveis para um serviço de catálogo SAP
Só é possível usar algumas colunas de origens de dados para condições de filtro (esta é uma limitação do SAP por predefinição).
Para obter uma lista de colunas filtráveis para um serviço de catálogo SAP, siga estes passos:
- Inicie sessão no sistema SAP.
- Aceda ao código de transação
SEGW. Introduza o nome do projeto OData, que é uma subcadeia do nome do serviço. Por exemplo:
- Nome do serviço:
MM_PUR_POITEMS_MONI_SRV - Nome do projeto:
MM_PUR_POITEMS_MONI
- Nome do serviço:
Clique em Enter.
Aceda à entidade que quer filtrar e selecione Propriedades.
Pode usar os campos apresentados em Propriedades como filtros. As operações suportadas são Igual a e Entre (intervalo).

Para ver uma lista de operadores suportados na linguagem de expressão, consulte a documentação de código aberto do OData: Convenções de URI (OData versão 2.0).
Exemplo de URI com filtros:
/sap/opu/odata/sap/MM_PUR_POITEMS_MONI_SRV/C_PurchaseOrderItemMoni(P_DisplayCurrency='USD')/Results/?$filter=(PurchaseOrder eq '4500000000')
Configure o sistema SAP ERP
O plug-in SAP OData usa um serviço OData que é ativado em cada servidor SAP a partir do qual os dados são extraídos. Este serviço OData pode ser um padrão fornecido pela SAP ou um serviço OData personalizado desenvolvido no seu sistema SAP.
Passo 1: instale o SAP Gateway 2.0
O administrador do SAP (Basis) tem de verificar se os componentes do SAP Gateway 2.0 estão disponíveis no sistema de origem SAP, consoante a versão do NetWeaver. Para mais informações sobre a instalação do SAP Gateway 2.0, inicie sessão no SAP ONE Support Launchpad e consulte a nota 1569624 (início de sessão necessário) .
Passo 2: ative o serviço OData
Ative o serviço OData necessário no sistema de origem. Para mais informações, consulte o artigo Servidor de front-end: ative os serviços OData.
Passo 3: crie uma função de autorização
Para estabelecer ligação à origem de dados, crie uma função de autorização com as autorizações necessárias no SAP e, em seguida, conceda-a ao utilizador do SAP.
Para criar a função de autorização no SAP, siga estes passos:
- Na GUI do SAP, introduza o código de transação PFCG para abrir a janela Role Maintenance.
No campo Função, introduza um nome para a função.
Por exemplo:
ZODATA_AUTHClique em Função única.
É apresentada a janela Criar funções.
No campo Descrição, introduza uma descrição e clique em Guardar.
Por exemplo:
Authorizations for SAP OData plugin.Clique no separador Autorizações. O título da janela muda para Alterar funções.
Em Editar dados de autorização e gerar perfis, clique em Alterar dados de autorização.
É aberta a janela Escolher modelo.
Clique em Não selecionar modelos.
É aberta a janela Alterar função: autorizações.
Clique em Manualmente.
Faculte as autorizações apresentadas na seguinte tabela de autorizações da SAP.
Clique em Guardar.
Para ativar a função de autorização, clique no ícone Gerar.
Autorizações SAP
| Classe de objeto | Texto da classe de objeto | Objeto de autorização | Texto do objeto de autorização | Autorização | Texto | Valor |
|---|---|---|---|---|---|---|
| AAAB | Objetos de autorização entre aplicações | S_SERVICE | Verificação no início dos serviços externos | SRV_NAME | Nome do programa, da transação ou do módulo de função | * |
| AAAB | Objetos de autorização entre aplicações | S_SERVICE | Verificação no início dos serviços externos | SRV_TYPE | Tipo de autorização e valores predefinidos da flag de verificação | HT |
| FI | Contabilidade financeira | F_UNI_HIER | Acesso à hierarquia universal | ACTVT | Atividade | 03 |
| FI | Contabilidade financeira | F_UNI_HIER | Acesso à hierarquia universal | HRYTYPE | Tipo de hierarquia | * |
| FI | Contabilidade financeira | F_UNI_HIER | Acesso à hierarquia universal | HRYID | ID da hierarquia | * |
Para conceber e executar um pipeline de dados no Cloud Data Fusion (como utilizador do Cloud Data Fusion), precisa das credenciais de utilizador da SAP (nome de utilizador e palavra-passe) para configurar o plug-in de ligação à origem de dados.
O utilizador do SAP tem de ser dos tipos Communications ou Dialog. Para evitar a utilização de recursos de diálogo SAP, recomendamos o tipo Communications. Os utilizadores podem ser criados através do código de transação SU01 da SAP.
Opcional: passo 4: proteja a ligação
Pode proteger a comunicação através da rede entre a sua instância privada do Cloud Data Fusion e o SAP.
Para proteger a ligação, siga estes passos:
- O administrador do SAP tem de gerar um certificado X509. Para gerar o certificado, consulte o artigo Criar um PSE de servidor SSL.
- O Google Cloud administrador tem de copiar o ficheiro X509 para um contentor do Cloud Storage legível no mesmo projeto que a instância do Cloud Data Fusion e dar o caminho do contentor ao utilizador do Cloud Data Fusion, que o introduz quando configura o plug-in.
- O Google Cloud administrador tem de conceder acesso de leitura para o ficheiro X509 ao utilizador do Cloud Data Fusion que cria e executa pipelines.
Opcional: passo 5: crie serviços OData personalizados
Pode personalizar a forma como os dados são extraídos criando serviços OData personalizados no SAP:
- Para criar serviços OData personalizados, consulte o artigo Criação de serviços OData para principiantes.
- Para criar serviços OData personalizados através de vistas de serviços de dados principais (CDS), consulte o artigo Como criar um serviço OData e expor vistas CDS como um serviço OData.
- Qualquer serviço OData personalizado tem de suportar consultas
$top,$skipe$count. Estas consultas permitem que o plug-in particione os dados para extração sequencial e paralela. Se forem usadas, as consultas$filter,$expandou$selecttambém têm de ser suportadas.
Configure o Cloud Data Fusion
Certifique-se de que a comunicação está ativada entre a instância do Cloud Data Fusion e o servidor SAP. Para instâncias privadas, configure o intercâmbio de redes. Depois de estabelecer a interligação de redes com o projeto onde os sistemas SAP estão alojados, não é necessária nenhuma configuração adicional para se ligar à sua instância do Cloud Data Fusion. O sistema SAP e a instância do Cloud Data Fusion têm de estar no mesmo projeto.
Passo 1: configure o ambiente do Cloud Data Fusion
Para configurar o ambiente do Cloud Data Fusion para o plug-in:
Aceda aos detalhes da instância:
Na Google Cloud consola, aceda à página do Cloud Data Fusion.
Clique em Instâncias e, de seguida, clique no nome da instância para aceder à página Detalhes da instância.
Verifique se a instância foi atualizada para a versão 6.4.0 ou posterior. Se a instância estiver numa versão anterior, tem de a atualizar.
Clique em Ver instância. Quando a IU do Cloud Data Fusion abrir, clique em Hub.
Selecione o separador SAP > SAP OData.
Se o separador SAP não estiver visível, consulte o artigo Resolução de problemas de integrações SAP.
Clique em Implementar plug-in SAP OData.
O plug-in aparece agora no menu Origem na página do Studio.
Passo 2: configure o plug-in
O plug-in SAP OData lê o conteúdo de uma origem de dados SAP.
Para filtrar os registos, pode configurar as seguintes propriedades na página de propriedades OData do SAP.
| Nome de propriedade | Descrição |
|---|---|
| Básico | |
| Nome de referência | Nome usado para identificar de forma exclusiva esta origem para a linhagem ou anotação de metadados. |
| URL base do SAP OData | URL de base OData do SAP Gateway (use o caminho do URL completo, semelhante a
https://ADDRESS:PORT/sap/opu/odata/sap/).
|
| Versão do OData | Versão do SAP OData suportada. |
| Nome do serviço | Nome do serviço SAP OData a partir do qual quer extrair uma entidade. |
| Nome da entidade | Nome da entidade que está a ser extraída, como Results. Pode usar um prefixo, como C_PurchaseOrderItemMoni/Results. Este campo suporta parâmetros de categoria e entidade. Exemplos:
|
| Credenciais* | |
| Tipo de SAP | Básica (através do nome de utilizador e da palavra-passe). |
| Nome de utilizador de início de sessão da SAP | Nome de utilizador do SAP Recomendado: se o nome de utilizador do SAP Logon mudar periodicamente, use uma macro. |
| Palavra-passe de início de sessão da SAP | Palavra-passe do utilizador do SAP Recomendado: use macros seguras para valores confidenciais, como palavras-passe. |
| Certificado de cliente X.509 da SAP (consulte Usar certificados de cliente X.509 no servidor de aplicações SAP NetWeaver para ABAP. |
|
| ID do projeto da GCP | Um identificador global exclusivo para o seu projeto. Este campo é obrigatório se o campo Caminho do Cloud Storage do certificado X.509 não contiver um valor de macro. |
| Caminho do GCS | O caminho do contentor do Cloud Storage que contém o certificado X.509 carregado pelo utilizador, que corresponde ao servidor de aplicações SAP para chamadas seguras com base nos seus requisitos (consulte o passo Proteger a ligação). |
| Frase de acesso | Palavra-passe correspondente ao certificado X.509 fornecido. |
| Botão Obter esquema | Gera um esquema com base nos metadados do SAP, com mapeamento automático dos tipos de dados do SAP para os tipos de dados do Cloud Data Fusion correspondentes (a mesma funcionalidade que o botão Validar). |
| Avançadas | |
| Opções de filtro | Indica o valor que um campo tem de ter para ser lido. Use esta condição de filtro para restringir o volume de dados de saída. Por exemplo: `Price Gt 200` seleciona os registos com um valor do campo `Price` superior a `200`. (Consulte Obtenha uma lista de colunas filtráveis para um serviço de catálogo SAP.) |
| Selecionar campos | Campos a preservar nos dados extraídos (por exemplo: categoria, preço, nome, fornecedor/morada). |
| Expandir campos | Lista de campos complexos a expandir nos dados de saída extraídos (por exemplo: Products/Suppliers). |
| Número de linhas a ignorar | Número total de linhas a ignorar (por exemplo: 10). |
| Número de linhas a obter | O número total de linhas a extrair. |
| Número de divisões a gerar | O número de divisões usadas para particionar os dados de entrada. Mais partições
aumentam o nível de paralelismo, mas requerem mais recursos e
sobrecarga. Se deixar em branco, o plug-in escolhe um valor ideal (recomendado). |
| Tamanho do lote | Número de linhas a obter em cada chamada de rede para o SAP. Um tamanho pequeno provoca chamadas de rede frequentes que repetem a sobrecarga associada. Um tamanho grande
pode tornar a obtenção de dados mais lenta e causar uma utilização excessiva de recursos no SAP.
Se o valor estiver definido como 0, o valor predefinido é
2500 e o limite de linhas a obter em cada lote é
5000. |
| Limite de tempo de leitura | O tempo, em segundos, a aguardar pelo serviço SAP OData. O valor
predefinido é 300. Para não ter um limite de tempo, defina a opção 0. |
Tipos OData suportados
A tabela seguinte mostra o mapeamento entre os tipos de dados OData v2 usados em aplicações SAP e tipos de dados do Cloud Data Fusion.
| Tipo de OData | Descrição (SAP) | Tipo de dados do Cloud Data Fusion |
|---|---|---|
| Numérico | ||
| SByte | Valor de número inteiro de 8 bits com sinal | int |
| Byte | Valor inteiro de 8 bits não assinado | int |
| Int16 | Valor inteiro de 16 bits com sinal | int |
| Int32 | Valor de número inteiro de 32 bits com sinal | int |
| Int64 | Valor de número inteiro de 64 bits com sinal anexado ao caráter: "L" Exemplos: 64L, -352L |
long |
| Único | Número de vírgula flutuante com uma precisão de 7 dígitos que pode representar valores
com um intervalo aproximado de ± 1,18e -38 a ± 3,40e +38, anexado
com o caráter: "f" Exemplo: 2.0f |
float |
| Duplo | Número de vírgula flutuante com uma precisão de 15 dígitos que pode representar valores
com intervalos aproximados de ± 2,23e -308 a ± 1,79e +308, anexado
com o caráter: "d" Exemplos: 1E+10d, 2.029d, 2.0d |
double |
| Decimal | Valores numéricos com precisão e escala fixas que descrevem um valor numérico
que varia de -10^255 + 1 a 10^255 -1, anexado com o caráter: 'M' ou 'm' Exemplo: 2.345M |
decimal |
| Caráter | ||
| Guid | Um valor de identificador exclusivo de 16 bytes (128 bits), que começa pelo caráter: 'guid' Exemplo: guid'12345678-aaaa-bbbb-cccc-ddddeeeeffff' |
string |
| String | Dados de carateres de comprimento fixo ou variável codificados em UTF-8 | string |
| Byte | ||
| Binário | Dados binários de comprimento fixo ou variável, que começam por "X" ou
"binary" (ambos são sensíveis a maiúsculas e minúsculas) Exemplo: X'23AB', binary'23ABFF' |
bytes |
| Lógico | ||
| Booleano | Conceito matemático de lógica binária | boolean |
| Data/hora | ||
| Data/Hora | Data e hora com valores que variam entre as 00:00:00 de 1 de janeiro de 1753 e as 23:59:59 de 31 de dezembro de 9999 | timestamp |
| Hora | Hora do dia com valores entre 0:00:00.x e 23:59:59.y, em que "x" e "y" dependem da precisão | time |
| DateTimeOffset | Data e hora como um desvio, em minutos a partir de GMT, com valores que variam das 00:00:00 de 1 de janeiro de 1753 às 23:59:59 de 31 de dezembro de 9999 | timestamp |
| Complexo | ||
| Propriedades de navegação e não de navegação (multiplicidade = *) | Coleções de um tipo, com uma multiplicidade de um para muitos. | array,string,int. |
| Propriedades (multiplicidade = 0,1) | Referências a outros tipos complexos com uma multiplicidade de um para um | record |
Validação
Clique em Validar na parte superior direita ou em Obter esquema.
O plug-in valida as propriedades e gera um esquema com base nos metadados do SAP. Mapeia automaticamente os tipos de dados SAP para os tipos de dados do Cloud Data Fusion correspondentes.
Execute um pipeline de dados
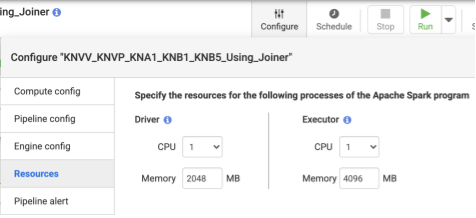
- Após implementar o pipeline, clique em Configurar no painel central superior.
- Selecione Recursos.
- Se necessário, altere o Executor CPU e a Memória com base no tamanho geral dos dados e no número de transformações usadas no pipeline.
- Clique em Guardar.
- Para iniciar o pipeline de dados, clique em Executar.
Desempenho
O plug-in usa as capacidades de paralelização do Cloud Data Fusion. As diretrizes seguintes podem ajudar a configurar o ambiente de tempo de execução para que forneça recursos suficientes ao motor de tempo de execução para alcançar o grau de paralelismo e desempenho pretendido.
Otimize a configuração do plugin
Recomendado: a menos que conheça as definições de memória do seu sistema SAP, deixe os campos Número de divisões a gerar e Tamanho do lote em branco (não especificado).
Para um melhor desempenho quando executa o pipeline, use as seguintes configurações:
Número de divisões a gerar: recomenda-se usar valores entre
8e16. No entanto, podem aumentar para32ou até64com as configurações adequadas no lado do SAP (atribuindo recursos de memória adequados para os processos de trabalho no SAP). Esta configuração melhora o paralelismo no lado do Cloud Data Fusion. O motor de tempo de execução cria o número especificado de partições (e ligações SAP) enquanto extrai os registos.Se o serviço de configuração (fornecido com o plugin quando importa o ficheiro de transporte SAP) estiver disponível: o plugin usa por predefinição a configuração do sistema SAP. As divisões correspondem a 50% dos processos de trabalho de diálogo disponíveis no SAP. Nota: o serviço de configuração só pode ser importado de sistemas S4HANA.
Se o serviço de configuração não estiver disponível, a predefinição são
7divisões.Em qualquer dos casos, se especificar um valor diferente, o valor que fornecer prevalece sobre o valor de divisão predefinido,exceto se for limitado pelos processos de diálogo disponíveis no SAP, menos duas divisões.
Se o número de registos a extrair for inferior a
2500, o número de divisões é1.
Tamanho do lote: esta é a contagem de registos a obter em cada chamada de rede para a SAP. Um tamanho do lote mais pequeno provoca chamadas de rede frequentes, repetindo a sobrecarga associada. Por predefinição, o número mínimo é
1000e o máximo é50000.
Para mais informações, consulte os limites de entidades OData.
Definições de recursos do Cloud Data Fusion
Recomendado: use 1 CPU e 4 GB de memória por Executor (este valor aplica-se a cada processo do Executor). Defina-as na caixa de diálogo Configurar > Recursos.
Definições do cluster do Dataproc
Recomendado: no mínimo, atribua um total de CPUs (entre os trabalhadores) superior ao número de divisões pretendido (consulte a configuração do plug-in).
Cada trabalhador tem de ter 6,5 GB ou mais de memória alocada por CPU nas definições do Dataproc (isto traduz-se em 4 GB ou mais disponíveis por executor do Cloud Data Fusion). Pode manter as outras definições nos valores predefinidos.
Recomendado: use um cluster do Dataproc persistente para reduzir o tempo de execução do pipeline de dados (isto elimina o passo de aprovisionamento, que pode demorar alguns minutos ou mais). Defina esta opção na secção de configuração do Compute Engine.
Exemplos de configurações e débito
As secções seguintes descrevem exemplos de configurações de desenvolvimento e produção, bem como o débito.
Configurações de teste e desenvolvimento de amostra
- Cluster do Dataproc com 8 trabalhadores, cada um com 4 CPUs e 26 GB de memória. Gere até 28 divisões.
- Cluster do Dataproc com 2 trabalhadores, cada um com 8 CPUs e 52 GB de memória. Gere até 12 divisões.
Exemplos de configurações de produção e taxa de transferência
- Cluster do Dataproc com 8 trabalhadores, cada um com 8 CPUs e 32 GB de memória. Gere até 32 divisões (metade dos CPUs disponíveis).
- Cluster do Dataproc com 16 trabalhadores, cada um com 8 CPUs e 32 GB de memória. Gere até 64 divisões (metade dos CPUs disponíveis).
Exemplo de taxa de transferência para um sistema de origem de produção SAP S4HANA 1909
A tabela seguinte tem um exemplo de débito. A taxa de transferência apresentada não tem opções de filtro, salvo indicação em contrário. Quando usa opções de filtro, o débito é reduzido.
| Tamanho do lote | Tempos parciais | Serviço OData | Total de linhas | Linhas extraídas | Débito (linhas por segundo) |
|---|---|---|---|---|---|
| 1000 | 4 | ZACDOCA_CDS | 5,37 M | 5,37 M | 1069 |
| 2500 | 10 | ZACDOCA_CDS | 5,37 M | 5,37 M | 3384 |
| 5000 | 8 | ZACDOCA_CDS | 5,37 M | 5,37 M | 4630 |
| 5000 | 9 | ZACDOCA_CDS | 5,37 M | 5,37 M | 4817 |
Exemplo de taxa de transferência para um sistema de origem de produção na nuvem do SAP S4HANA
| Tamanho do lote | Tempos parciais | Serviço OData | Total de linhas | Linhas extraídas | Débito (GB/hora) |
|---|---|---|---|---|---|
| 2500 | 40 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 M | 25,48 |
| 5000 | 50 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 M | 26,78 |
Detalhes do apoio técnico
O plug-in suporta os seguintes exemplos de utilização.
Produtos e versões SAP compatíveis
As origens suportadas incluem o SAP S4/HANA 1909 e posterior, o S4/HANA na nuvem SAP e qualquer aplicação SAP capaz de expor serviços OData.
O ficheiro de transporte que contém o serviço OData personalizado para o equilíbrio de carga das chamadas para o SAP tem de ser importado no S4/HANA 1909 e posterior. O serviço ajuda a calcular o número de divisões (partições de dados) que o plug-in pode ler em paralelo (consulte o número de divisões).
A versão 2 do OData é suportada.
O plug-in foi testado com servidores SAP S/4HANA implementados no Google Cloud.
Os serviços de catálogo OData da SAP são suportados para extração
O plug-in suporta os seguintes tipos de origens de dados:
- Dados da transação
- Vistas de CDS expostas através de OData
Dados principais
- Atributos
- Textos
- Hierarquias
Notas SAP
Não são necessárias notas do SAP antes da extração, mas o sistema SAP tem de ter o SAP Gateway disponível. Para mais informações, consulte a nota 1560585 (este site externo requer um início de sessão na SAP).
Limites no volume de dados ou na largura dos registos
Não existe um limite definido para o volume de dados extraídos. Testámos com até 6 milhões de linhas extraídas numa chamada, com uma largura de registo de 1 KB. Para o SAP S4/HANA na nuvem, testámos até 10 milhões de linhas extraídas numa chamada, com uma largura de registo de 1 KB.
Débito esperado do plug-in
Para um ambiente configurado de acordo com as diretrizes na secção Desempenho, o plug-in pode extrair cerca de 38 GB por hora. O desempenho real pode variar com as cargas do sistema SAP e do Cloud Data Fusion ou o tráfego de rede.
Extração delta (dados alterados)
A extração delta não é suportada.
Cenários de erro
Em tempo de execução, o plug-in escreve entradas de registo no registo do pipeline de dados do Cloud Data Fusion. Estas entradas têm o prefixo CDF_SAP para identificação.
Em tempo de conceção, quando valida as definições do plug-in, as mensagens são apresentadas no separador Propriedades e são realçadas a vermelho.
A lista seguinte descreve alguns dos erros:
| ID da mensagem | Mensagem | Ação recomendada |
|---|---|---|
| Nenhum | Required property 'CONNECTION_PROPERTY' for connection
type 'CONNECTION_PROPERTY_SETTING'. |
Introduza um valor real ou uma variável de macro. |
| Nenhum | Invalid value for property 'PROPERTY_NAME'. |
Introduza um número inteiro não negativo (0 ou superior, sem um decimal) ou uma variável de macro. |
| CDF_SAP_ODATA_01505 | Failed to prepare the Cloud Data Fusion output schema. Please
check the provided runtime macros value. |
Certifique-se de que os valores das macros fornecidos estão corretos. |
| N/A | SAP X509 certificated 'STORAGE_PATH' is missing. Please
make sure the required X509 certificate is uploaded to your specified
Cloud Storage bucket 'BUCKET_NAME'. |
Certifique-se de que o caminho do armazenamento na nuvem fornecido está correto. |
| CDF_SAP_ODATA_01532 | Código de erro genérico relacionado com problemas de conetividade do SAP ODataFailed to call given SAP OData service. Root Cause:
MESSAGE. |
Verifique a causa principal apresentada na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01534 | Código de erro genérico relacionado com o erro do serviço SAP OData.Service validation failed. Root Cause: MESSAGE. |
Verifique a causa principal apresentada na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01503 | Failed to fetch total available record count from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause: MESSAGE.
|
Verifique a causa principal apresentada na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01506 | No records found to extract in
SAP_ODATA_SERVICE_ENTITY_NAME.
Please ensure that the provided entity contains records. |
Verifique a causa principal apresentada na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01537 | Failed to process records for
SAP_ODATA_SERVICE_ENTITY_NAME.
Root Cause: MESSAGE. |
Verifique a causa principal apresentada na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01536 | Failed to pull records from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause:
MESSAGE. |
Verifique a causa principal apresentada na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01504 | Failed to generate the encoded metadata string for the given OData
service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Verifique a causa principal apresentada na mensagem e tome as medidas adequadas. |
| CDF_SAP_ODATA_01533 | Failed to decode the metadata from the given encoded metadata
string for service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Verifique a causa principal apresentada na mensagem e tome as medidas adequadas. |
O que se segue?
- Saiba mais sobre o Cloud Data Fusion.
- Saiba mais sobre o SAP no Google Cloud.