Halaman ini menjelaskan cara menjalankan pipeline di Cloud Data Fusion terhadap cluster Dataproc yang ada.
Secara default, Cloud Data Fusion membuat cluster sementara untuk setiap pipeline: Cloud Data Fusion membuat cluster di awal operasi pipeline, lalu menghapusnya setelah operasi pipeline selesai. Meskipun perilaku ini menghemat biaya dengan memastikan bahwa resource hanya dibuat saat diperlukan, perilaku default ini mungkin tidak diinginkan dalam skenario berikut:
Jika waktu yang diperlukan untuk membuat cluster baru untuk setiap pipeline terlalu lama untuk kasus penggunaan Anda.
Jika organisasi Anda mewajibkan pembuatan cluster dikelola secara terpusat; misalnya, saat Anda ingin menerapkan kebijakan tertentu untuk semua cluster Dataproc.
Untuk skenario ini, Anda akan menjalankan pipeline terhadap cluster yang ada dengan langkah-langkah berikut.
Sebelum memulai
Anda memerlukan hal berikut:
Instance Cloud Data Fusion.
Cluster Dataproc yang ada.
Jika Anda menjalankan pipeline di Cloud Data Fusion versi 6.2, gunakan image Dataproc lama yang berjalan dengan Hadoop 2.x (misalnya, 1.5-debian10), atau upgrade ke versi Cloud Data Fusion terbaru.
Menghubungkan ke cluster yang ada
Di Cloud Data Fusion versi 6.2.1 dan yang lebih baru, Anda dapat terhubung ke kluster Dataproc yang ada saat membuat profil Compute Engine baru.
Buka instance Anda:
Di konsol Google Cloud , buka halaman Cloud Data Fusion.
Untuk membuka instance di Cloud Data Fusion Studio, klik Instance, lalu klik View instance.
Klik System admin.
Klik tab Configuration.
Klik Profil komputasi sistem.
Klik Buat profil baru. Halaman penyedia akan terbuka.
Klik Existing Dataproc.
Masukkan informasi profil, cluster, dan pemantauan.
Klik Create.
Mengonfigurasi pipeline Anda untuk menggunakan profil kustom
Buka instance Anda:
Di konsol Google Cloud , buka halaman Cloud Data Fusion.
Untuk membuka instance di Cloud Data Fusion Studio, klik Instance, lalu klik View instance.
Buka pipeline di halaman Studio.
Klik Configure.
Klik Compute config.
Klik profil yang Anda buat.
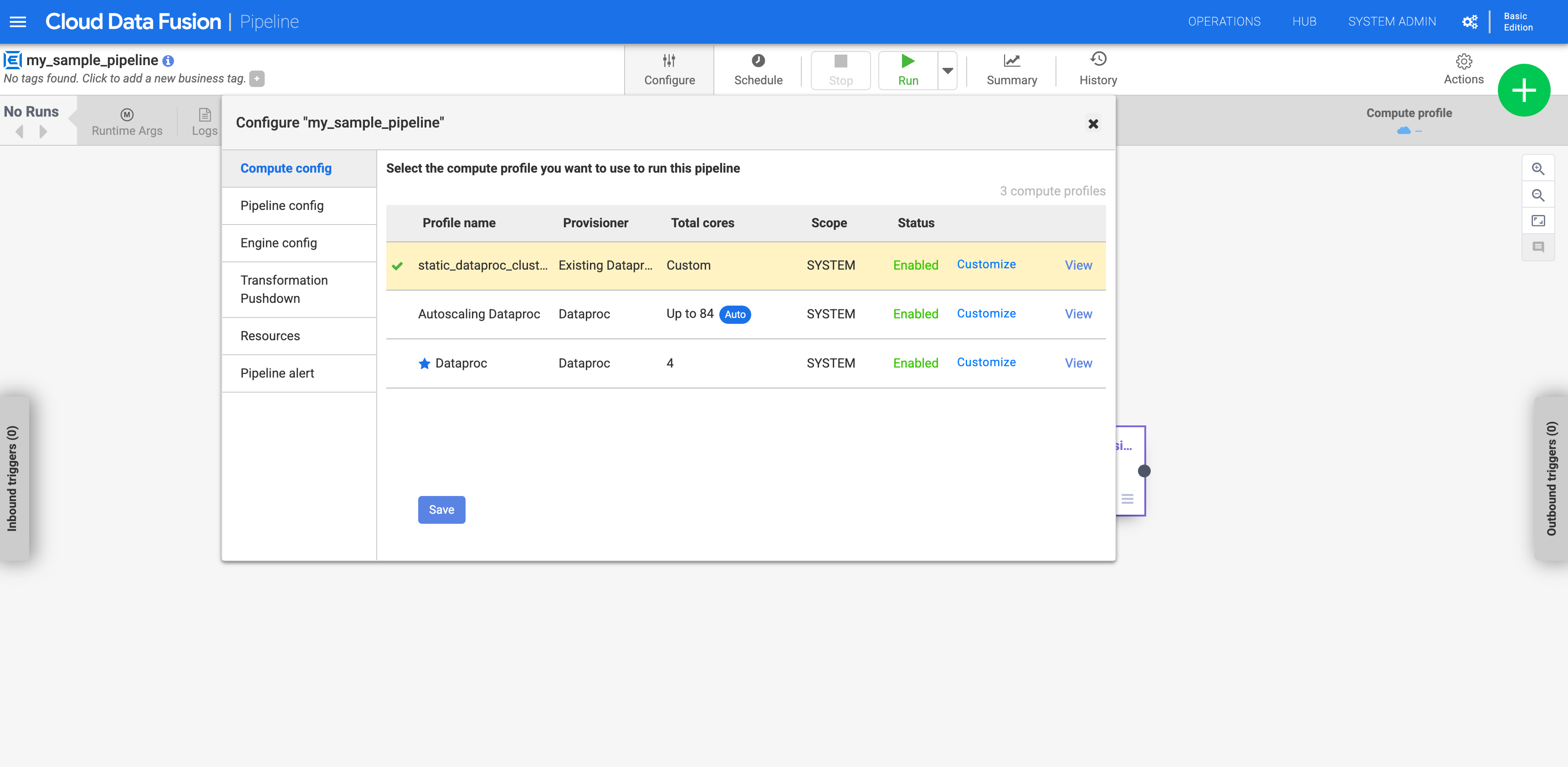
Gambar 1: Klik profil kustom Jalankan pipeline. Aplikasi ini berjalan pada cluster Dataproc yang ada.
Langkah selanjutnya
- Pelajari lebih lanjut cara mengonfigurasi cluster.
- Memecahkan masalah penghapusan cluster.