本页面介绍了如何针对现有 Dataproc 集群在 Cloud Data Fusion 中运行流水线。
默认情况下,Cloud Data Fusion 会为每个流水线创建临时集群:它会在流水线开始运行时创建集群,然后在流水线运行完成后将其删除。虽然此行为可确保只在需要时创建资源,从而节省费用,但可能在这种情况下并不需要以下默认行为:
如果为每个流水线创建新集群所需的时间对您的使用场景来说过多。
如果您的组织需要集中管理集群创建;例如,当您希望对所有 Dataproc 集群实施特定政策时。
针对这些场景,您需要按照以下步骤在现有集群上运行流水线。
准备工作
您需要具备以下几项:
Cloud Data Fusion 实例。
现有 Dataproc 集群。
如果您在 Cloud Data Fusion 6.2 版本中运行流水线,请使用旧版 Dataproc 映像,该映像会使用 Hadoop 2.x(例如 1.5-debian10)运行,或者升级到最新的 Cloud Data Fusion 版本。
连接到现有集群
在 Cloud Data Fusion 6.2.1 版及更高版本中,您可以在创建新的 Compute Engine 配置文件时连接到现有 Dataproc 集群。
前往您的实例:
在 Google Cloud 控制台中,前往 Cloud Data Fusion 页面。
如需在 Cloud Data Fusion Studio 中打开实例,请点击实例,然后点击查看实例。
点击系统管理员。
点击配置标签页。
依次点击 System compute profiles(系统计算配置文件)。
点击创建新的付款资料。系统随即会打开预配工具页面。
点击现有 Dataproc (Existing Dataproc)。
输入配置文件、集群和监控信息。
点击创建。
配置流水线以使用自定义配置文件
前往您的实例:
在 Google Cloud 控制台中,前往 Cloud Data Fusion 页面。
如需在 Cloud Data Fusion Studio 中打开实例,请点击实例,然后点击查看实例。
在 Studio 页面上前往您的流水线。
点击配置。
点击计算配置 (Compute config)。
点击您创建的配置文件。
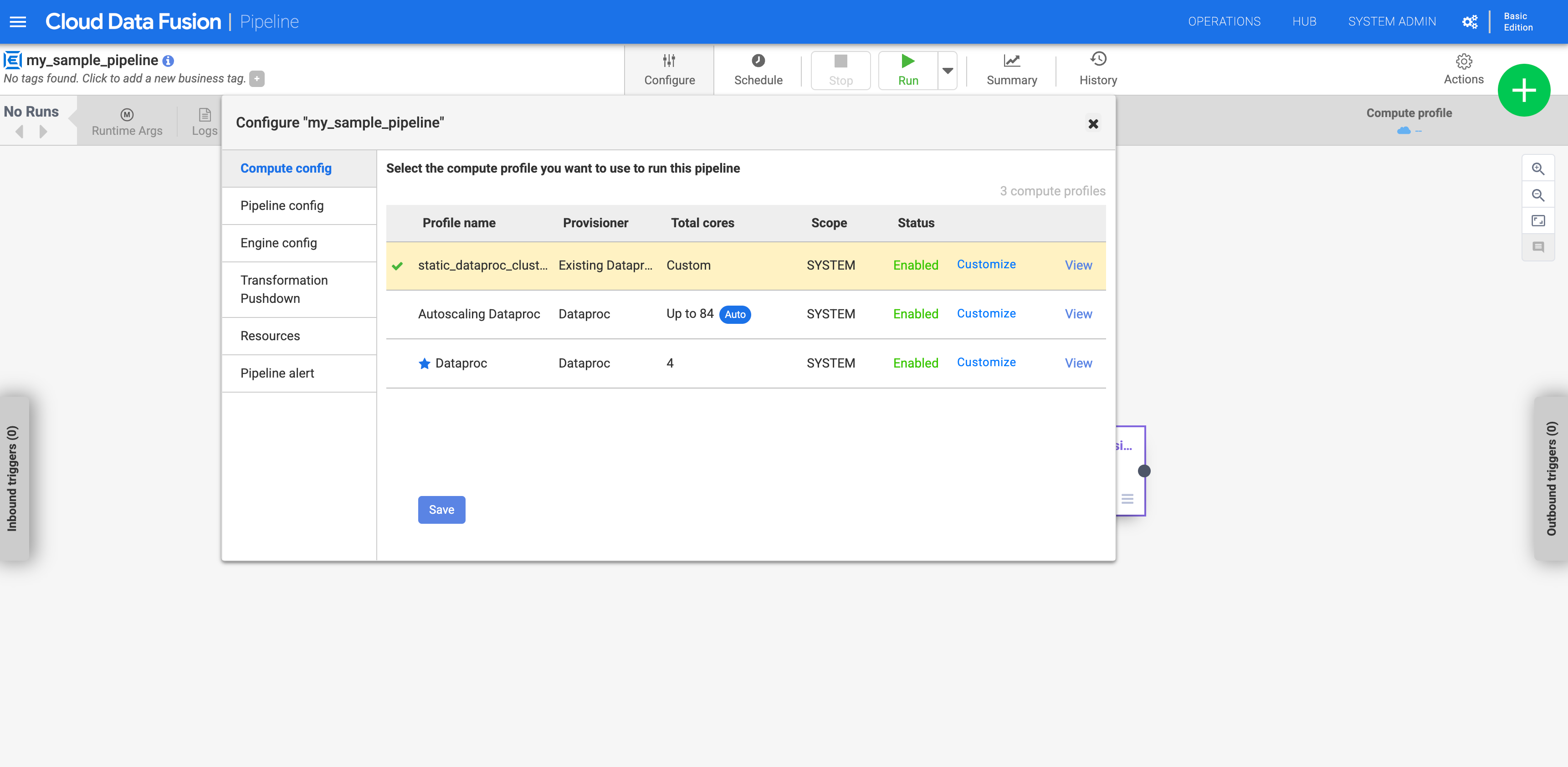
图 1:点击自定义配置文件 运行流水线。它会针对现有 Dataproc 集群运行。