En esta página se describe cómo ejecutar un flujo de procesamiento en Cloud Data Fusion en un clúster de Dataproc ya creado.
De forma predeterminada, Cloud Data Fusion crea clústeres efímeros para cada flujo de procesamiento: crea un clúster al principio de la ejecución del flujo de procesamiento y, a continuación, lo elimina cuando finaliza la ejecución. Aunque este comportamiento permite ahorrar costes, ya que los recursos solo se crean cuando es necesario, puede que no sea adecuado en los siguientes casos:
Si el tiempo que se tarda en crear un clúster nuevo para cada canalización es excesivo para tu caso práctico.
Si tu organización requiere que la creación de clústeres se gestione de forma centralizada, por ejemplo, si quieres aplicar determinadas políticas a todos los clústeres de Dataproc.
En estos casos, puedes ejecutar flujos de procesamiento en un clúster ya creado siguiendo estos pasos.
Antes de empezar
Necesitarás lo siguiente:
Una instancia de Cloud Data Fusion.
Un clúster de Dataproc.
Si ejecutas tus flujos de procesamiento en Cloud Data Fusion 6.2, usa una imagen de Dataproc anterior que se ejecute con Hadoop 2.x (por ejemplo, 1.5-debian10) o actualiza a la versión más reciente de Cloud Data Fusion.
Conectarse al clúster
En las versiones 6.2.1 y posteriores de Cloud Data Fusion, puedes conectarte a un clúster de Dataproc que ya tengas al crear un perfil de Compute Engine.
Ve a tu instancia:
En la Google Cloud consola, ve a la página de Cloud Data Fusion.
Para abrir la instancia en Cloud Data Fusion Studio, haga clic en Instancias y, a continuación, en Ver instancia.
Haz clic en Administrador del sistema.
Haz clic en la pestaña Configuration (Configuración).
Haz clic en Perfiles de cálculo del sistema.
Haz clic en Crear perfil. Se abrirá una página de proveedores.
Haz clic en Dataproc existente.
Introduce la información del perfil, el clúster y la monitorización.
Haz clic en Crear.
Configurar el flujo de procesamiento para usar el perfil personalizado
Ve a tu instancia:
En la Google Cloud consola, ve a la página de Cloud Data Fusion.
Para abrir la instancia en Cloud Data Fusion Studio, haga clic en Instancias y, a continuación, en Ver instancia.
Ve a tu canal en la página Studio.
Haz clic en Configurar.
Haz clic en Configuración de Compute.
Haz clic en el perfil que has creado.
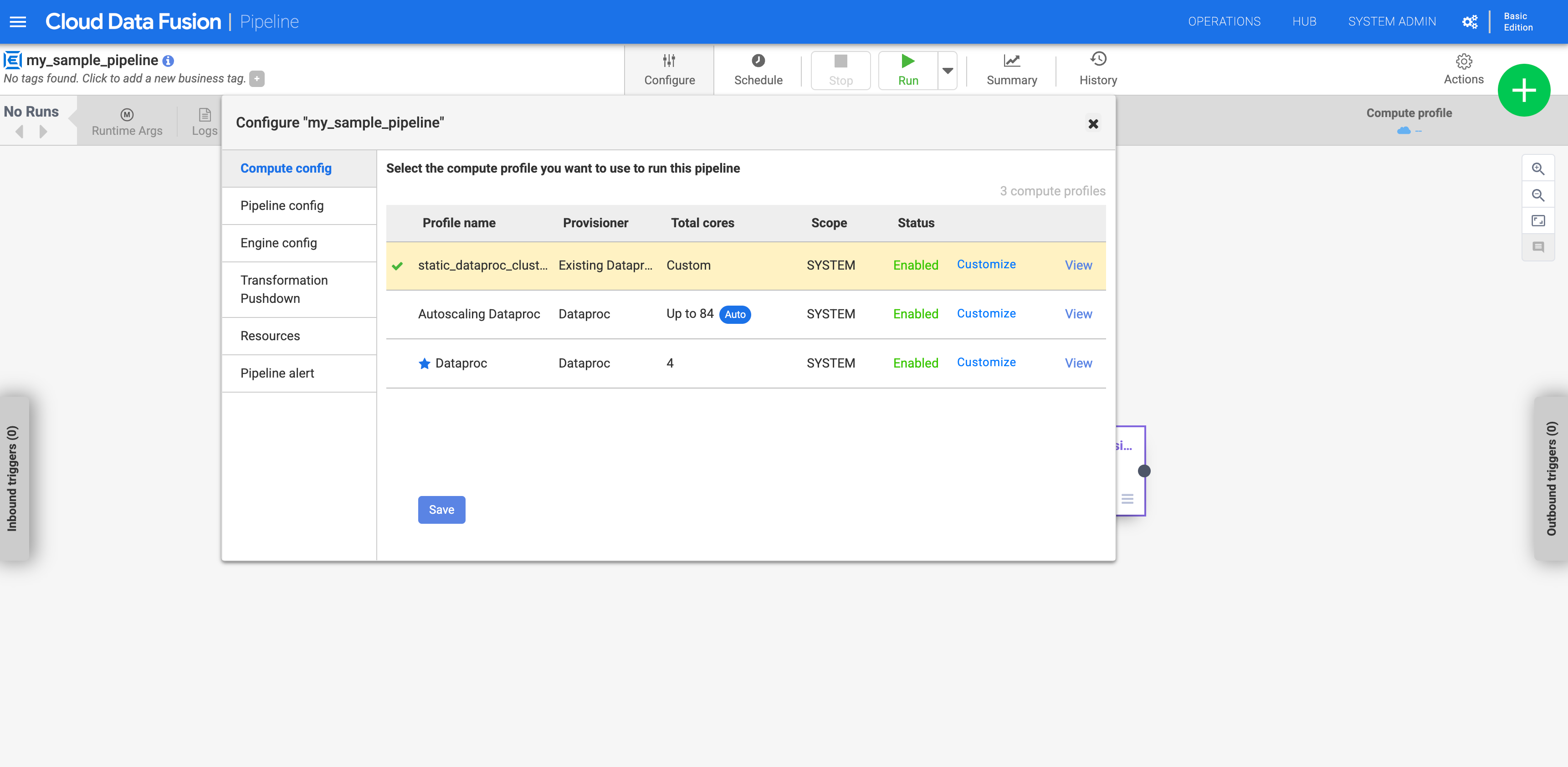
Figura 1: Haz clic en el perfil personalizado Ejecuta el flujo de procesamiento. Se ejecuta en el clúster de Dataproc que ya existe.
Siguientes pasos
- Consulta más información sobre cómo configurar clústeres.
- Consulta cómo eliminar clústeres.