Nesta página, descrevemos como executar um pipeline no Cloud Data Fusion em um cluster atual do Dataproc.
Por padrão, o Cloud Data Fusion cria clusters efêmeros para cada pipeline: cria um cluster no início da execução do pipeline e o exclui após a conclusão da execução do pipeline. Embora esse comportamento economize custos, garantindo que os recursos sejam criados somente quando necessário, esse comportamento padrão pode não ser desejável nos seguintes cenários:
Se o tempo necessário para criar um novo cluster para cada pipeline for adequado para seu caso de uso.
Se a organização exigir que a criação de cluster seja gerenciada centralmente; por exemplo, quando você quiser aplicar políticas específicas a todos os clusters do Dataproc.
Para esses cenários, execute pipelines em um cluster atual seguindo as etapas a seguir.
Antes de começar
Você precisará do seguinte:
Uma instância do Cloud Data Fusion.
Um cluster atual do Dataproc
Se você executar seus pipelines no Cloud Data Fusion versão 6.2, use uma imagem do Dataproc mais antiga que seja executada com o Hadoop 2.x (por exemplo, 1.5-debian10) ou faça upgrade para a versão mais recente do Cloud Data Fusion.
Conectar ao cluster
Nas versões 6.2.1 e posteriores do Cloud Data Fusion, é possível se conectar a um cluster atual do Dataproc quando você cria um novo perfil do Compute Engine.
Acesse sua instância:
No console Google Cloud , acesse a página do Cloud Data Fusion.
Para abrir a instância no Cloud Data Fusion Studio, clique em Instâncias e em Ver instância.
Clique em Administrador do sistema.
Clique na guia Configuração.
Clique em Perfis de computação do sistema.
Clique em Criar novo perfil. Uma página de provisionadores será aberta.
Clique em Dataproc atual.
Insira as informações do perfil, do cluster e de monitoramento.
Clique em Criar.
Configurar o pipeline para usar o perfil personalizado
Acesse sua instância:
No console Google Cloud , acesse a página do Cloud Data Fusion.
Para abrir a instância no Cloud Data Fusion Studio, clique em Instâncias e em Ver instância.
Acesse o pipeline na página Studio.
Clique em Configurar.
Clique em Compute config.
Clique no perfil que você criou.
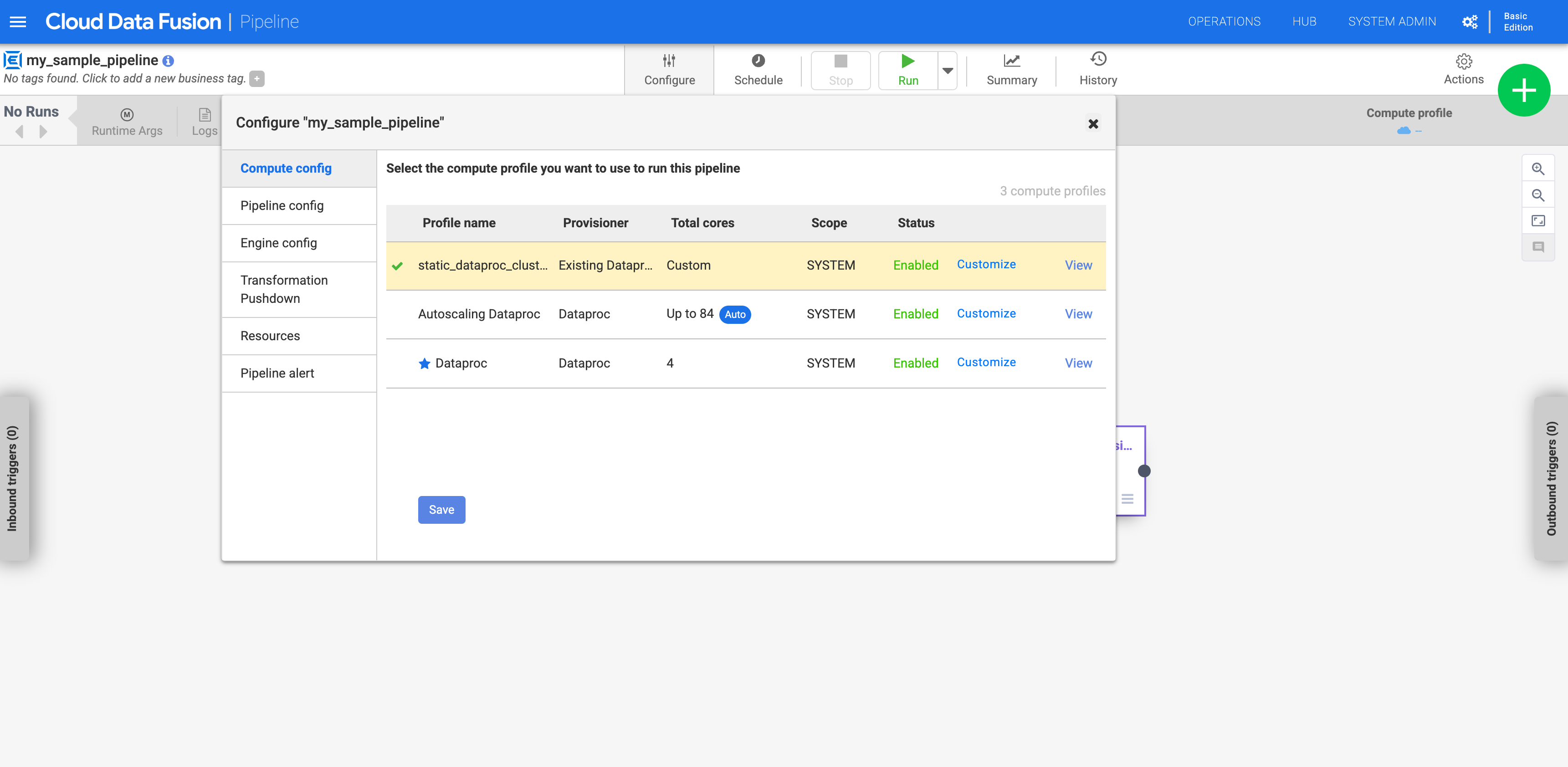
Figura 1: clique no perfil personalizado Executar o pipeline. Ele é executado no cluster atual do Dataproc.
A seguir
- Saiba mais sobre como configurar clusters.
- Resolver problemas de exclusão de clusters.