Questa pagina descrive come eseguire una pipeline in Cloud Data Fusion su un cluster Dataproc esistente.
Per impostazione predefinita, Cloud Data Fusion crea cluster temporanei per ogni pipeline: crea un cluster all'inizio dell'esecuzione della pipeline, quindi lo elimina al termine dell'esecuzione della pipeline. Sebbene questo comportamento consenta di risparmiare sui costi garantendo che le risorse vengano create solo quando necessario, potrebbe non essere auspicabile nei seguenti scenari:
Se il tempo necessario per creare un nuovo cluster per ogni pipeline è proibitivo per il tuo caso d'uso.
Se la tua organizzazione richiede che la creazione dei cluster venga gestita centralmente, ad esempio quando vuoi applicare determinati criteri a tutti i cluster Dataproc.
Per questi scenari, esegui le pipeline su un cluster esistente con i passaggi che seguono.
Prima di iniziare
Ti occorrono:
Un'istanza Cloud Data Fusion.
Un cluster Dataproc esistente.
Se esegui le pipeline nella versione 6.2 di Cloud Data Fusion, utilizza un'immagine Dataproc precedente che funziona con Hadoop 2.x (ad esempio 1.5-debian10) o esegui l'upgrade alla versione più recente di Cloud Data Fusion.
Connettiti al cluster esistente
Nelle versioni 6.2.1 e successive di Cloud Data Fusion, puoi connetterti a un cluster Dataproc esistente quando crei un nuovo profilo Compute Engine.
Vai all'istanza:
Nella Google Cloud console, vai alla pagina Cloud Data Fusion.
Per aprire l'istanza in Cloud Data Fusion Studio, fai clic su Istanze e poi su Visualizza istanza.
Fai clic su Amministratore di sistema.
Fai clic sulla scheda Configuration (Configurazione).
Fai clic su Profili di calcolo di sistema.
Fai clic su Crea nuovo profilo. Si apre una pagina di fornitori.
Fai clic su Dataproc esistente.
Inserisci le informazioni sul profilo, sul cluster e sul monitoraggio.
Fai clic su Crea.
Configura la pipeline in modo da utilizzare il profilo personalizzato
Vai all'istanza:
Nella Google Cloud console, vai alla pagina Cloud Data Fusion.
Per aprire l'istanza in Cloud Data Fusion Studio, fai clic su Istanze e poi su Visualizza istanza.
Vai alla tua pipeline nella pagina Studio.
Fai clic su Configura.
Fai clic su Configurazione di calcolo.
Fai clic sul profilo che hai creato.
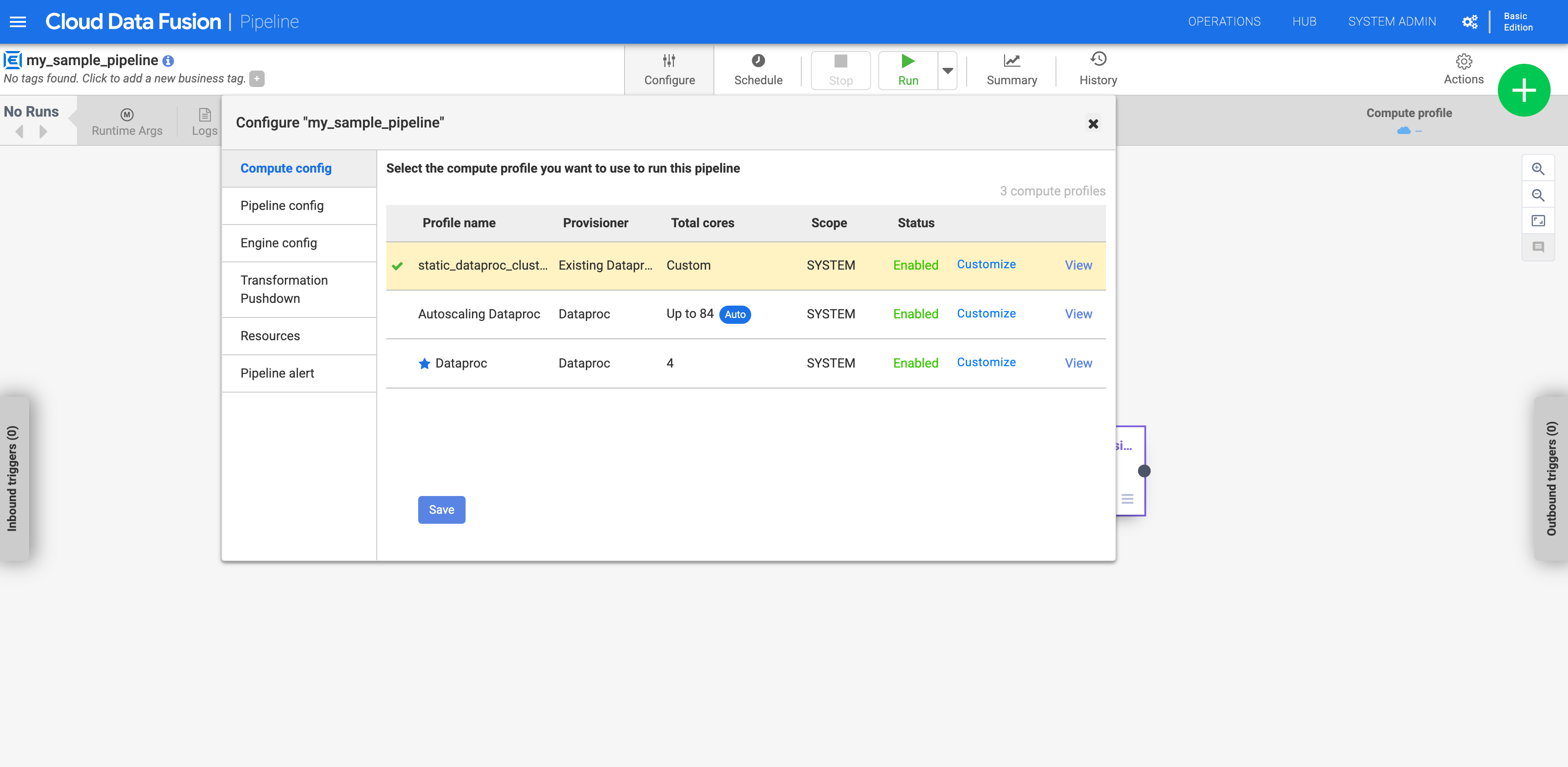
Figura 1: fai clic sul profilo personalizzato Esegui la pipeline. Viene eseguito sul cluster Dataproc esistente.
Passaggi successivi
- Scopri di più sulla configurazione dei cluster.
- Risolvi i problemi di eliminazione dei cluster.