Auf dieser Seite wird beschrieben, wie Sie in Cloud Data Fusion eine Pipeline mit einem vorhandenen Dataproc-Cluster ausführen.
Cloud Data Fusion erstellt standardmäßig sitzungsspezifische Cluster für jede Pipeline: Der Cluster erstellt zu Beginn der Pipelineausführung einen Cluster und löscht ihn anschließend wieder. Bei diesem Verhalten können Sie Kosten sparen, da Ressourcen nur bei Bedarf erstellt werden. In den folgenden Szenarien ist dieses Standardverhalten jedoch möglicherweise nicht erwünscht:
Wenn die Zeit, die zum Erstellen eines neuen Clusters für jede Pipeline benötigt wird, für Ihren Anwendungsfall untragbar ist.
Wenn Ihre Organisation die Cluster-Verwaltung zentral verwalten muss, z. B. wenn Sie bestimmte Richtlinien für alle Dataproc-Cluster durchsetzen möchten.
In diesen Szenarien führen Sie mit den folgenden Schritten Pipelines für einen vorhandenen Cluster aus.
Hinweis
Sie benötigen Folgendes:
Eine Cloud Data Fusion-Instanz.
Einen vorhandenen Dataproc-Cluster.
Wenn Sie Ihre Pipelines in Cloud Data Fusion Version 6.2 ausführen, verwenden Sie ein älteres Dataproc-Image, das mit Hadoop 2.x ausgeführt wird (z. B. 1.5-debian10) oder führen Sie ein Upgrade auf die neueste Version von Cloud Data Fusion durch.
Verbindung zum vorhandenen Cluster herstellen
In Cloud Data Fusion Version 6.2.1 und höher können Sie eine Verbindung zu einem vorhandenen Dataproc-Cluster herstellen, wenn Sie ein neues Compute Engine-Profil erstellen.
Rufen Sie Ihre Instanz auf:
Rufen Sie in der Google Cloud Console die Seite „Cloud Data Fusion“ auf.
Wenn Sie die Instanz in Cloud Data Fusion Studio öffnen möchten, klicken Sie auf Instanzen und dann auf Instanz anzeigen.
Klicken Sie auf Systemadministrator.
Klicken Sie auf den Tab Konfiguration.
Klicken Sie auf System Compute-Profile.
Klicken Sie auf Neues Profil erstellen. Eine Seite mit Bereitstellern wird geöffnet.
Klicken Sie auf Vorhandener Dataproc.
Geben Sie das Profil, den Cluster und die Monitoring-Informationen ein.
Klicken Sie auf Erstellen.
Pipeline für die Verwendung des benutzerdefinierten Profils konfigurieren
Rufen Sie Ihre Instanz auf:
Rufen Sie in der Google Cloud Console die Seite „Cloud Data Fusion“ auf.
Wenn Sie die Instanz in Cloud Data Fusion Studio öffnen möchten, klicken Sie auf Instanzen und dann auf Instanz anzeigen.
Rufen Sie auf der Seite Studio Ihre Pipeline auf.
Klicken Sie auf Konfigurieren.
Klicken Sie auf Compute-Konfiguration.
Klicken Sie auf das Profil, das Sie erstellt haben.
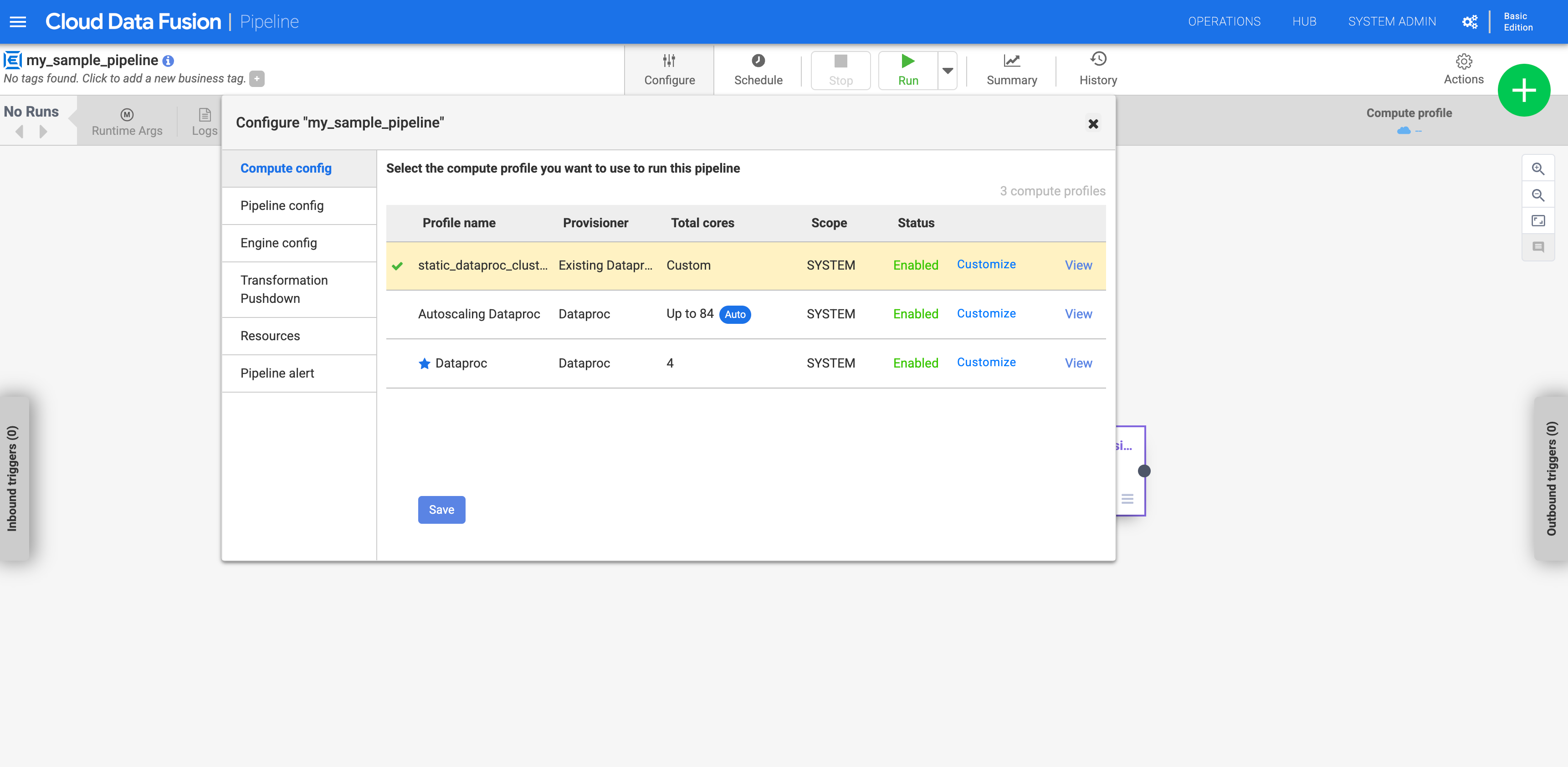
Abbildung 1: Klicken Sie auf das benutzerdefinierte Profil. Pipeline ausführen. Sie wird mit dem vorhandenen Dataproc-Cluster ausgeführt.